消息队列的定义,以及引入消息队列可解决的问题
1. 消息队列中的“消息”即指同一台计算机的进程间,或不同计算机的进程间传送的数据;
“消息队列”是在消息的传输过程中保存消息的容器。
消息被发送到队列中,消息队列充当中间人,将消息从它的源中继到它的目标。
2. 传统的进程通信模式如图1左所示:client调用service,等待service的响应。但是这种模式有很多弊端:
-网络情况不好时,client到Service的调用可能会丢失;
-或者service如果处理时间较长,那么client需要一直hold,甚至调用超时而失败;
-或者service的些许改动会带来client的代码修改等等。
3. 引入消息队列则可以避免这种传统模式的弊端,如图1右所示: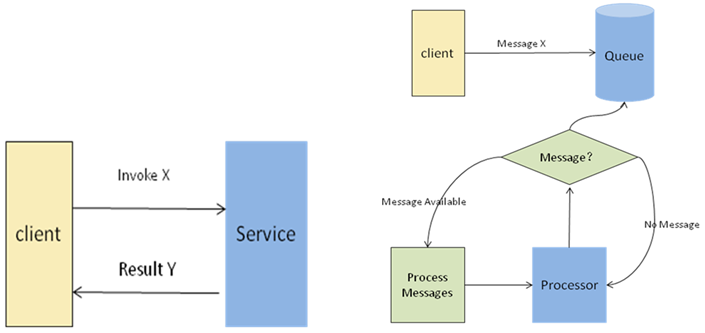
图1(左) 典型的Invoke/Respond模型 图1(右) 典型的消息队列处理流程
4. 消息队列可以带来如下好处:
(1)保证消息的传递。
如果发送消息时接收者不可用,消息队列会保留消息,直到成功地传递它;
(2)提供异步的通信协议。
消息的发送者将消息发送到消息队列后可以立即返回,不用等待接收者的响应,消息会被保存在队列中,直到接收者取出它;
(3)解耦,降低两个进程间的耦合度。
只要消息格式不变,即使接收者的接口、位置、或者配置改变,也不会给发送者带来任何改变;
而且,消息发送者无需知道消息接收者是谁,使得系统设计更清晰;
相反的,例如,远程过程调用(RPC)或者服务间通过socket建立连接,如果对方接口改变了或者对方ip、端口改变了,那么另一方需要改写代码或者改写配置;
(4)提供路由。
发送者无需与接收者建立连接,双方通过消息队列保证消息能够从发送者路由到接收者,甚至对于本来相互网络不通的两个服务,也可以提供消息路由。
为什么需要分布式消息队列
可靠
分布式消息队列提供更好的可靠性,主要体现在:
1. 消息会被持久化到分布式存储中。这样避免了单台机器存储的消息由于机器问题导致消息的丢失;
2. 不佳的网络环境中,保证只有当消息的接收者确实收到消息时才从队列中删除消息。
可扩展
可扩展性体现在访问量和数据量两个方面:
访问量:分布式消息队列服务,会随着访问量的增减而自动增减逻辑处理服务器;
数据量:当数据量扩大时,后端分布式存储会自动扩容。
安全
安全体现在以下两个方面:
1. 同时使用消息队列的业务之间不会互相干扰
如果有多个业务同时在使用消息队列,对于单机的消息队列服务,一个业务的消息操作可能会影响其他业务的正常运行。
比如,一个业务的消息操作特别频繁,占据了消息队列的绝大部分服务时间,也占据了这台服务器的绝大部分网络IO,导致其他业务无法正常地与消息队列通信。
而且甚至可能由于服务控制不当,导致机器崩溃,服务停止,业务也跟着停止。
分布式消息队列则不会出现这个问题:
(1)监控措施完善,系统性能指数会控制在一定范围之内,而且有任何异常也会报警;
(2)当访问量和数据量增大时,分布式消息队列服务可以自动扩展。
2. 各业务的消息内容是安全存储的,其他业务不能访问到非自身业务的数据。
一方面是业务需要密钥来访问消息队列;另一方面,消息是被加密存储的。
简单实用
简单实用体现在:
1.透明:接收者和发送者无需知道具体的消息队列的服务器地址,服务器的增减对接收者和发送者透明。
2. 实用:对于两个服务之间不能通信的网络情况,消息队列为他们提供了恰到好处的桥梁。
适用场景:
异步通信
对于BS(Browser-Server 浏览器)架构,很多情景下server的处理时间较长。
如果浏览器发送请求后,保持跟server的连接,等待server响应,那么一方面会对用户的体验有负面影响;
另一方面,很有可能会由于超时,提示用户服务请求失败。
对于这种情景,消息队列提供了一个较好的解决方案,如图2所示: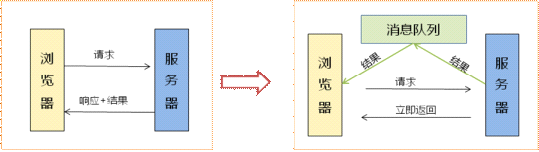
图2 BS通信模型的优化方案
工作流程如下:
(1)浏览器向服务器发送请求后,服务器接到响应后立即返回;
(2)之后,服务器向消息队列发送已经完成的结果信息;
(3)浏览器端用js等技术循环请求该消息队列,检查是否有新的结果信息,如果有则获取消息,并将结果渲染到浏览器界面上。
命令下发/分布式处理模型
在分布式的应用系统中,经常会有master-worker的模型(Map-Reduce就是一个典型的例子)。
有任务到达时,master会将任务直接分配给worker或者切成子任务分配给worker,但是有一个原则就是一个任务或者子任务只希望被一个worker执行。
传统的处理方式是:
(1)master要维护worker的心跳,知道有哪些worker可以接受任务,然后master挑选一个worker,与其建立连接,并发送数据包(即命令);
(2)worker收到数据包(命令)后,如果能够正常解析并执行,则反馈master;
(3)如果worker许久没有反馈,则master会做一系列工作,包括check该worker状态、确保死掉了之后再挑选一个worker分配任务。
这样的处理方式对master压力过大,也过于复杂。使用消息队列则可对master和worker进行有效解耦,如图3所示: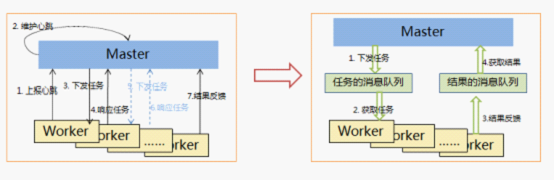
图3 master-worker命令下发模型的优化方案
CMQ中,master和worker的配置中都事先配置好两个队列名:1任务下发队列名,结果反馈队列名。
master有任务下发时,就向该“任务下发”队列中发送消息;
worker定期检查“任务下发”队列,发现队列有消息则获取(因为CMQ的特性保证了一条消息只会被一个接收者接收,所以一个任务只会被一个worker执行)。
之后worker执行的结果都发送到“结果反馈”队列中,master定期检查“结果反馈”队列,汇总执行结果。
所有这种一对多的通信,并且只希望这个“多”中只有一个真正接收到消息,则都可采用上述的解决方案。
数据上报模型
凡是多对一的通信都可以采用CMQ来解耦合,如下面例子所示:
1. 上文“命令下发/分布式处理模型”中给出的master-worker模型解决方案中,多个worker向同一个队列发送消息,master从该队列接收消息,就是一个典型的数据上报模型,即图3中的结果反馈的过程。
2. 监控服务中各个机器有后台进程定期汇报机器状态,中心服务收集各机器状态,进行计算和统计。也是一个典型的数据上报模型。
监控服务的后台进程可以将状态汇报到一个消息队列,中心服务从这个队列中接收消息,如图4所示: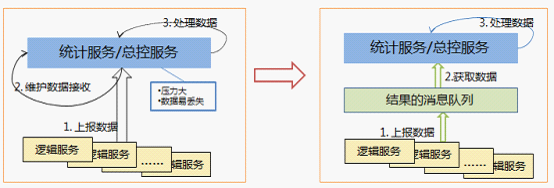
图4 数据上报模型的优化方案
3. 在线游戏中,需要一个可以实时显示当前各团队比赛战况的界面,或者任何需要汇总信息的需求。
这些都可以从各个机器汇报状态到消息队列,汇总服务从队列获取数据、处理数据并显示。