自从ChatGPT发布以来,它的“三步走方案”就好比《九阴真经》流落到AI江湖中,各大门派练法不一,有人像郭靖一样正着练,循序渐进;有人像欧阳锋一样反着练,守正出奇;也有像梅超风一样仅练就半部《九阴真经》,凭借九阴白骨爪横行江湖的。这也说明,“三步走方案”并非终局,在复现的基础上,多做些思考,像斗酒僧一样,认识到《九阴真经》的不足之处,加以修复,方能得到阴阳调和、刚柔互济的《九阳真经》。
这个系列希望通过介绍现有的类ChatGPT工作,提供一个鸟瞰的视角,方便读者了解他们的异同,如果能有所启发那是最好了。受限于个人能力,其间可能会有疏漏错误,欢迎一同讨论。
Part1三步走方案
抱着self-contained的原则,简要介绍一下ChatGPT的三步走技术方案[1],更详细的介绍可在互联网上找到:
SFT Model:通过人工标注的问答数据,对强大的GPT预训练模型进行supervised fine-tuning,即得到SFT模型,这个过程又可以称为Instruction tuning。
Reward Model:SFT模型在同一个问题上会得到的多个回答,对其进行好坏程度标注,然后将标注数据训练一个GPT模型,使模型能够判别回答的好坏,这便得到了Reward Model。
PPO Model:使用Proximal Policy Optimization算法,让Reward Model引导SFT模型进行符合人类意图的回答,便得到了PPO Model,即ChatGPT模型。

Part2Moss
让我们从中文的工作开始讲起,复旦大学的Moss在23年2月20日晚便打响了中文版ChatGPT的第一枪,但当晚我却一直无法打开官方主页。近日MOSS团队兑现了他们的诺言,将预训练模型、SFT模型(包括插件版)和训练数据一并开源出来,这应该是目前开源得最彻底的中文ChatGPT工作了,接下来从几个方面来展开看看:
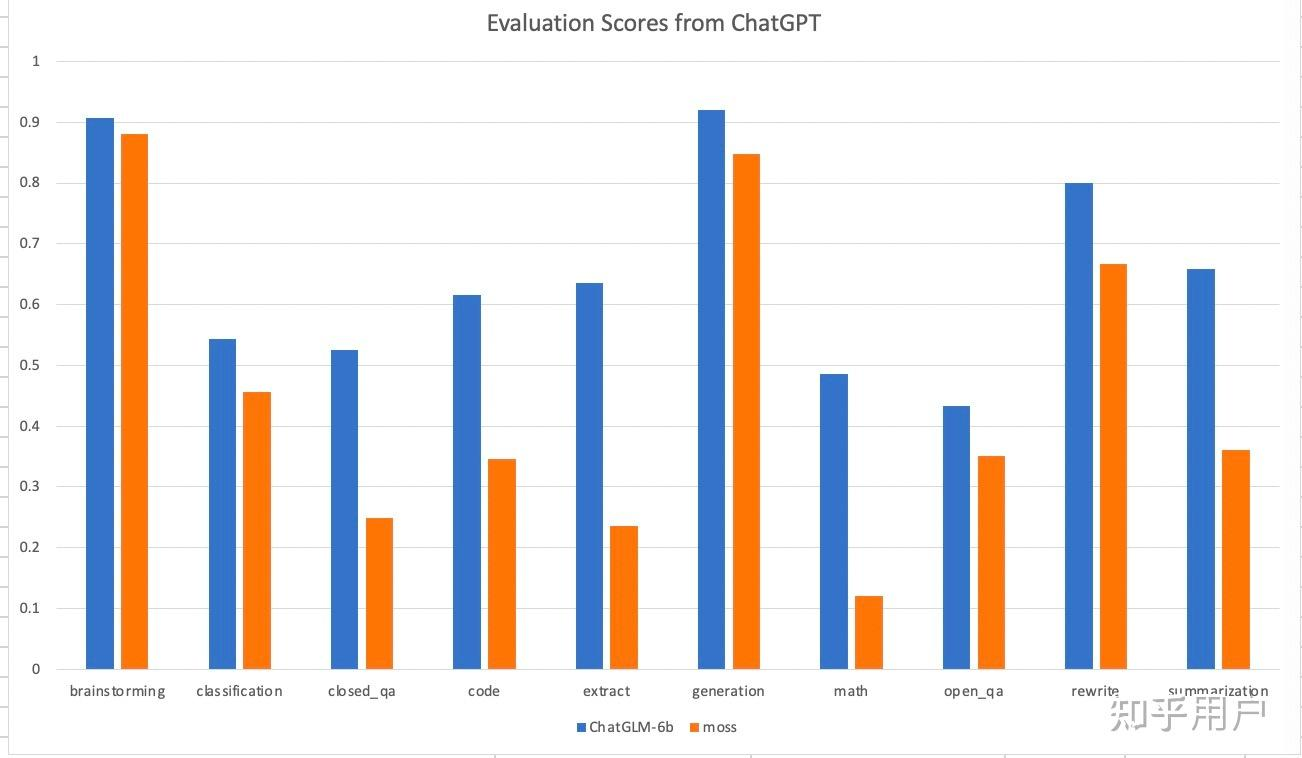
整体效果
MOSS目前开源了moss-moon-003-sft,这并不是最终版,但主要的能力基本已具备,知乎上有网友对其进行了评估,结论为:MOSS的性能基本达到了ChatGLM-6b的78%。官方称后续会公布他们的评估结果,但就我个人的使用moss-moon-003-sft的主观体验来看,的确是ChatGLM-6b略胜一筹。
预训练模型
虽然相关的论文还没放出来,但根据参与者的介绍[2]:
基座是codegen初始化,它的训练语料包括pile bigquery bigpython,我们又在100B中文+20B英文和代码上继续预训练的
codegen作为一个代码生成模型,将其作用来初始化基座模型,难免有些违背直觉。但细想下:
放眼国内,大模型之风从18年底Bert发布开始,decoder-only的结构始终不如encoder-only和encoder-decoder盛行,导致学校和企业自研的decoder-only模型并不多,大规模的更是少之又少。
扫描二维码关注公众号,回复: 15831761 查看本文章
当时Bert的large版本不过3亿参数,如果要做百亿模型不仅需要魄力,更需要资源,能入局的玩家凤毛麟角,所以人家训练好的百亿模型也不会轻易开源。
大模型写代码现在来看已经是标配,但将代码作为预训练数据的开源中文大模型却不多。
所以,一个开源可用的中文decoder-only大模型几乎不存在,这么一来,如果没有自研的大模型,那在一个代码生成模型上做继续预训练也不失为一种曲线救国的方案。但估计是受限于计算资源,MOSS团队进行了120B的继续预训练,这个数量和现在受欢迎的LLaMA(1T+ tokens)相比,还是一段差距的。

SFT
SFT部分的核心在于标注数据的质量,MOSS所用的SFT数据一大亮点是来自于真实用户的提问,同时他们也引入了3H(helpfulness, honesty, harmlessness)数据,这样即使是SFT模型,也能够具备初步的有助、无害、诚实的能力。目前开源了moss-002的标注数据,这部分的数据回复偏短,可能是由于使用Self-Instruct生成的缘故。SFT对数据质量的要求非常高,所谓“garbage in, garbage out”,Alpaca使用了self-instruct生成的数据,而Vicuna使用了shareGPT上用户真实的数据,效果上Vicuna明显胜出,中文方面目前很缺少像shareGPT这样的高质量数据。
SFT-plugin
MOSS团队同时还放出了会使用工具(即plugin)的版本——moss-moon-003-sft-plugin。大模型让人惊艳的能力之一便是它的推理能力,所谓推理,是指将复杂问题拆分为多个简单子问题的能力,通过逐个解决这些简单子问题,便能得到最终的正确答案。但在实际中,即使强如ChatGPT,在解决简单子问题的时候仍然容易出错,比如4位数的乘除法,一旦其中一个子问题出错,便会导致最终结果的错误。自然而然地,我们可以想到:让模型在解决简单子问题时通过使用外部工具以保证答案的正确性。
换一个角度,将模型比作大脑,而一个个工具则相当于是模型能与外部世界交互的手脚,这是一个令人激动的方向。近期这方面有不少亮眼的工作,如:ToolFormer[3]、ReAct[4]、HuggingGPT[5]、TaskMatrix.AI[6]、AutoGPT[7]……open AI自己也相应推出了ChatGPT plugins。
让ChatGPT使用工具,仅仅需要在Prompt里说明每个工具即可,借助于ChatGPT强大的zero-shot推理能力,即使ChatGPT从未在训练过程中用过这些工具,它也能使用这个工具较好地完成任务。但对于像MOSS一样的百亿模型也可以吗?MOSS选择的方案是为每个工具构造对应的训练数据,然后用于训练模型,通过这种方式教会模型使用特定的工具。

“使用搜索工具”的训练数据
“使用搜索工具”的训练数据
这种方案优点是能够确保模型能够深刻理解每个工具的用处,但缺点也很明显:
每次添加新工具,需要对应构造训练数据,重新训练模型
从给出的样例来看,用户的问题仅需一个工具就被解决了,但实际中,用户的要求可能需要调用多个工具才能达成,比如:姚明比奥尼尔高多少?
总之,让模型自己分解任务,组合使用工具完成任务,被认为是“自主智能体”,这个方向这近期将会有大量的工作涌现。
Reward Model+PPO
MOSS repo的README中提到其最终版是经过偏好模型训练得来的,这里的偏好模型即Reward Model。目前能在PPO上取得收益的开源工作好像不多,所以很多类Chatgpt的工作也只是做了第一步SFT。目前MOSS还未开源这部分的工作,很期待看他们的实现细节。
——2023.04.24
Reference
[1] Introducing ChatGPT
[2] 复旦团队大模型 MOSS 开源了,有哪些技术亮点值得关注? - 孙天祥的回答 - 知乎
[3] Language Models Can Teach Themselves to Use Tools
[4] REACT : SYNERGIZING REASONING AND ACTING INLANGUAGE MODELS
[5] HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
[6] TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs
[7] Auto-GPT: An Autonomous GPT-4 Experiment https://github.com/Significant-Gravitas/Auto-GPT