现代深度神经网络在部署到现实世界应用时,往往难以传递知识并在不同领域中实现泛化。
目前,引入领域泛化(DG)来从多个领域学习通用表示,以提高网络在未见领域中的泛化能力。然而,以往的DG方法只关注数据级别的一致性方案,而未考虑不同一致性方案之间的协同正则化。
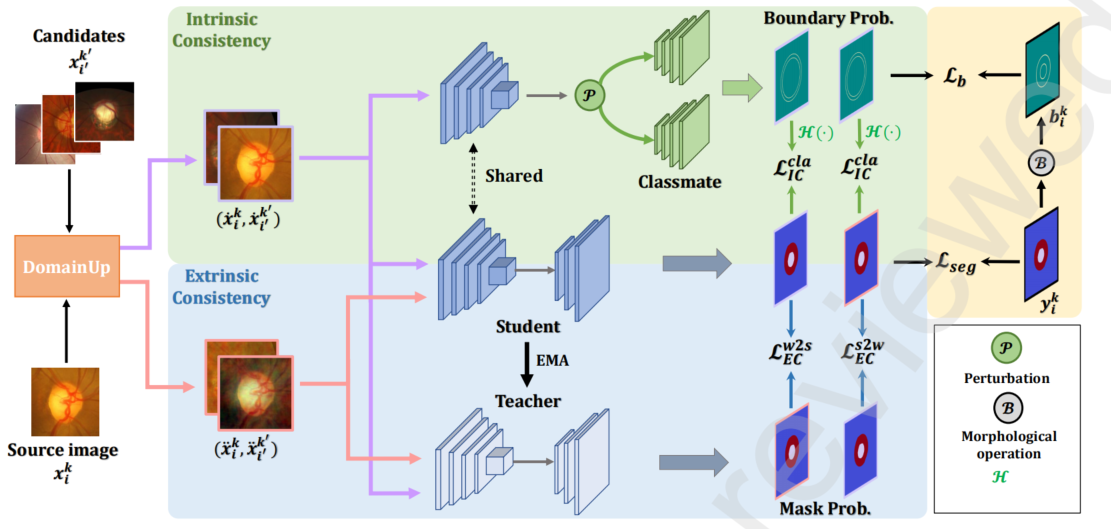
本文提出了一种新的分层一致性领域泛化框架(HCDG),通过协同集成外在一致性和内在一致性来实现。
- 对于外在一致性,我们利用多个源领域之间的知识来强制实现数据级别的一致性。为了更好地增强这种一致性,我们设计了一种基于傅里叶变换的数据增强方法,称为DomainUp,其中包括一个新颖的振幅高斯混合策略。
- 对于内在一致性,我们在双任务场景下对同一实例执行任务级别的一致性。
我们在两个医学图像分割任务上评估了所提出的HCDG框架,即眼底图像中的视杯/盘分割和前列腺MRI分割。广泛的实验结果表明了我们的HCDG框架的有效性和通用性。
详细解释
因此,我们提出了一种新颖的Hierarchical Consistency领域泛化框架(HCDG),同时利用外在一致性和内在一致性。
据我们所知,我们是首次将任务级扰动引入到DG中,并将多种一致性正则化集成到分层队列中,将平滑性假设应用于输入空间和输出空间。对于外在一致性,我们利用多个源领域之间的知识来实现数据级别的一致性。
受到观察到信号傅里叶频谱中的相位和振幅分量保留高级语义(例如结构)和低级统计(例如外观)的启发,我们引入了一种改进的基于傅里叶变换的振幅高斯混合(AG)方法,称为DomainUp,与以前的振幅混合(AM)方案[14]相比,可以生成具有更丰富变异性的增强域。对于内在一致性,我们在两个相关任务下对同一实例执行任务级别的一致性:图像分割和边界回归。外在一致性和内在一致性进一步集成到类似于师生的队列中,以促进网络学习。
The main contributions are summarized as follows.
- (i) We develop an effective HCDG framework for generalizable medical image segmentation by simultaneously integrating Extrinsic and Intrinsic Consistency.
- (ii) We design a novel Amplitude Gaussian-mixing strategy
for Fourier-based data augmentation by introducing pixelwise perturbation in the amplitude spectrum to highlight
core semantic structures. - (iii) Extensive experiments on two medical image segmentation benchmark datasets validate the efficacy and universality of the framework and HCDG clearly outperforms
many state-of-the-art DG methods. Code is in https://github.com/scott-yjyang/HCDG.
Background
深度神经网络(DNNs)在各种医学图像分析任务上展示了先进的进展[1,2,3]。这些成就大多依赖于网络在从相同分布或领域中绘制的样本上进行训练和测试的特殊要求。一旦这种要求失败,即存在领域转移[4],由于有限的泛化能力,网络很可能会生成不满意的性能。通常,在真实的临床环境中,医学图像通常由不同的机构使用各种类型的扫描仪供应商、患者群体、视野和外观差异[5]进行捕获,这使得学习模型难以在这些机构之间传递知识并实现泛化。由于为每个医疗中心训练特定模型是不现实和费力的,因此有必要提高深度模型在不同甚至新的临床现场的泛化能力。
目前,社区主要从两个方向攻击领域转移瓶颈。
- 首先,
无监督领域自适应(UDA)利用从未标记的目标领域图像中提取的先验知识来实现模型适应。尽管基于UDA的方法可以避免来自目标领域的耗时注释,但提前收集目标图像在实践中很难满足(数据问题)。
DNNs已经在医学图像分割任务中得到了广泛应用,例如从MRI中进行心脏分割[15]、从CT中进行器官分割[16,17]以及从皮肤镜像中进行皮肤病变分割[18]。在本文中,我们主要关注两个医学任务,即眼底图像中的OC/OD分割[19]和T2加权MRI中的前列腺分割[20]。之前,[21]和[22]在联合分割OC/OD方面展示了竞争结果,而[23]和[24]成功地提高了前列腺分割的性能。然而,大多数方法缺乏泛化能力,并且往往在未见目标数据集上产生高测试误差。因此,需要一种更具泛化能力的方法来减轻性能下降。
- 这启发了另一条路,
领域泛化(DG),旨在从多个源领域中学习通用表示,而不需要任何目标领域信息。(迁移学习)
领域泛化旨在从多个源领域中学习通用模型,使得该模型可以直接推广到任意未见目标领域
最近,许多DG方法取得了显著的成果。早期的DG工作主要遵循基于内核方法[8,25]、领域对抗学习[9,26]、不变风险最小化[10,27]、多组件分析[28]和生成建模[29]的表示学习思想。
- 数据操作是解决训练数据不足并通过两种流行技术增强模型泛化能力的最便宜的方法之一:数据生成和数据增强。例如,域随机化[6]、对抗训练的变换网络[7]和Mixup[30]被用于生成更多的训练样本。
- 同时,[14]引入了基于傅里叶变换的数据增强方法,通过线性失真幅度信息来进行领域泛化。DG也在通用机器学习范式中进行了研究。[11]设计了一种模型无关的训练过程,该过程源于元学习。
一致性正则化
一致性正则化在监督学习和半监督学习中被广泛使用,但在领域泛化方面尚未发挥重要作用。[34]首先引入了一致性损失来利用数据增强的随机性,并最小化通过网络训练样本的多次传递预测之间的差异。[35]设计了一个师生模型来提供更好的一致性对齐。此外,[13]提出了金字塔一致性来通过域随机化学习具有高通用性的模型,但仍然依赖于数据级别的扰动。最近,任务级别的一致性已被用于半监督学习[36]。据我们所知,还没有研究探索任务级别的一致性来解决领域泛化问题。
- 加入高斯噪声
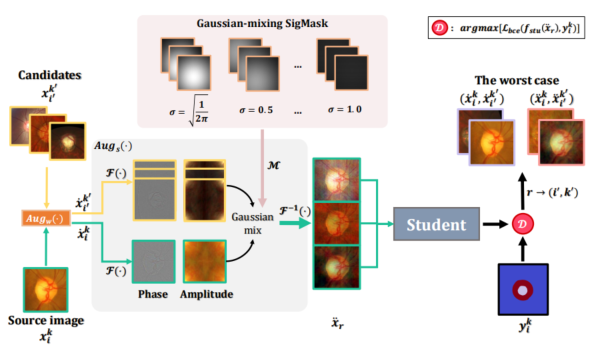
以往的基于傅里叶变换的数据增强工作[14]线性混合整个图像的频谱振幅,并保持相位信息不变以合成插值域。这可以保证对象的结构不变,而振幅扰动可以使模型更加鲁棒,而不影响分割结果。
然而,这种策略在混合过程中平等地处理每个像素,很难区分中心和边缘区域的语义结构的大小。
因此,我们设计了一种新颖的基于傅里叶变换的振幅高斯混合(AG)策略,通过引入一个显著性掩码SigMask M来进行线性插值,其中高斯状的M用于控制每个像素的扰动大小。
具体来说,我们首先提取频域空间的振幅信息,并使用SigMask M来确定每个像素的重要性。然后,我们将高斯噪声添加到每个像素的振幅上,以产生不同的图像样本。这种策略可以更好地保留中心和边缘区域的语义结构,从而提高模型的泛化能力。
classmate module
Classmate模块
为了进行双任务,我们将一个新的Classmate模块与Q个解码器纳入学生模型中。然后,在转换后的两个任务的预测之间实现任务级别的约束。为了进一步增强两个任务输出之间的差异性,我们还在特征图z,k,i上应用特征级扰动P(·)(例如特征丢失或噪声)。
在实践中,我们将边界回归定义为第二个任务,以捕捉几何结构。具体来说,每个Classmate由四个卷积层组成,后跟ReLU和批归一化层,并接收弱增强图像˙x,k,i的扰动特征图。为了生成边界的真实值b,k,i,我们按照[19]的方法对掩码真实值进行形态学操作。
- 监督边界损失采用均方误差(MSE)进行计算,其中N是标记样本的数量,gj(·)是Classmate j的预测。我们将Classmate的数量Q设置为2,以平衡准确性和效率。请注意,每个Classmate接收不同版本的扰动特征图以使它们的输出多样化。
MulGT: Multi-Task Graph-Transformer with Task-Aware Knowledge Injection and Domain Knowledge-Driven Pooling for Whole Slide Image Analysis
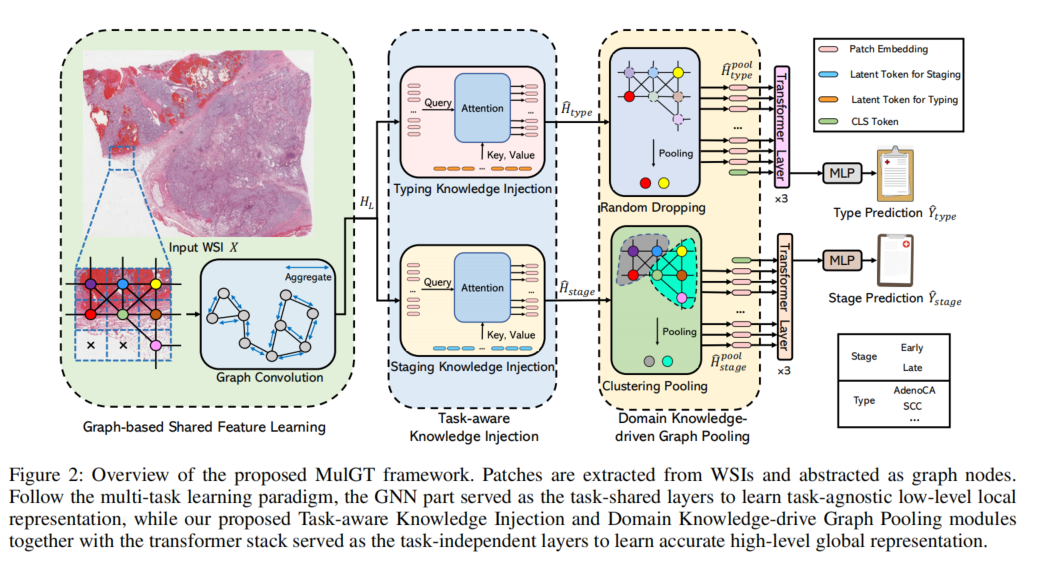
全扫描图像(WSI)已广泛用于在深度学习领域下协助自动诊断。然而,大多数以前的工作仅讨论单一任务设置,这与真实的临床设置不一致,在那里病理学家经常同时进行多个诊断任务。此外,众所周知,多任务学习范式可以通过利用多个任务之间的共性和差异来提高学习效率。为此,我们提出了一个新颖的多任务框架(即MulGT)用于WSI分析,该框架配备了特别设计的Graph-Transformer、Task-aware Knowledge Injection和Domain Knowledge-driven Graph Pooling模块。
基本上,我们的框架使用图神经网络和Transformer作为构建共同点,能够学习任务不可知的低级局部信息以及任务特定的高级全局表示。考虑到WSI分析中的不同任务依赖于不同的特征和属性,我们还设计了一个新颖的Task-aware Knowledge Injection模块,将任务共享的图嵌入传输到任务特定的特征空间中,以学习更准确的不同任务的表示。
此外,我们还精心设计了一个新颖的Domain Knowledge-driven Graph Pooling模块,用于每个任务,通过利用多个任务的不同诊断模式来提高不同任务的准确性和鲁棒性。我们在来自TCGA项目的两个公共WSI数据集上评估了我们的方法,即食管癌和肾癌。实验结果表明,我们的方法在肿瘤分型和分期任务上优于单一任务对应方法和最先进的方法。
我们的主要贡献可以总结如下。
• 我们设计了一个新颖的多任务Graph-Transformer用于幻灯片级别的WSI分析。与其他方法不同,我们的框架同时进行多个诊断任务,从而受益于学习多个任务的共性和差异。对两个公共WSI数据集的广泛实验表明,我们设计的框架具有良好的效果。
• 为了学习任务特定的特征,我们设计了一个新颖的Task-aware Knowledge Injection模块,通过交叉注意机制和包含任务特定知识的潜在令牌将任务共享特征传输到任务特定特征空间中。
• 为了导入不同任务的不同诊断模式的先验知识,我们精心设计了一个新颖的Domain Knowledge-driven Graph Pooling模块,以更适当地表示整个图的信息,从而为不同任务提供便利的预测过程并减少计算成本。
多实例学习用于WSI。多实例学习(MIL)方法被广泛用于WSI分析,并可分为两种范式:
- (1)实例级方法
- (2)嵌入级方法(Amores 2013)。
通常,实例级方法更注重局部信息,而嵌入级方法强调全局表示。最近的一些工作采用了注意机制来进行WSI的MIL,以进行实例聚合。特别是,基于注意力的方法能够在全局聚合过程中识别不同实例的贡献,如ABMIL(Ilse,Tomczak和Welling 2018)、DeepAttnMIL(Yao等人2020)和CLAM(Lu等人2021)。最近,基于图和Transformer的方法也已被用于计算病理学中,因为WSI实例可以抽象为图的节点或Transformer体系结构的标记。例如,H2Graph(Hou等人2022)使用不同分辨率的WSI构建异构图以学习分层表示,而HIPT(Chen等人2022)引入了一种新的ViT体系结构,以从WSI中学习到天然的内在的层级结构。
多任务学习。多任务学习(Caruana 1997)通过硬或软参数共享共同优化一组任务。众所周知,同时学习多个任务可以提供几个优势,包括通过多个任务之间的正则化改善数据效率和减少过拟合(Crawshaw 2020)。一些先前的文献以明确的方式利用多个任务之间的关系。例如,ML-GCN(Chen等人2019)在不同的对象标签上建立了一个有向图,以促进多标签图像识别,其中每个节点是一个特定的对象(即任务),边是对象之间的相关性。同时,一些工作(Kendall,Gal和Cipolla 2018;Chen等人2018)采用自适应权重来平衡训练过程,而刘等人(2021)引入了基于梯度的方法来缓解任务之间的负面转移。
特别是,RotoGrad(Javaloy和Valera 2021)使用一组旋转矩阵将任务共享特征旋转到不同的特征空间中,然后转移到任务特定的分支,以避免任务之间的梯度冲突。部分灵感来自于将任务共享特征转移到不同的任务特定特征空间可能有益于模型学习,本文设计了一个任务感知知识注入模块,以区分不同任务分支中的特征。
结合图和Transformer。最近,Transformer模型已经被引入来处理图结构数据。根据GNN和Transformer层的相对位置,当前的工作可以分为三种体系结构(Min等人2022):
- (1)在GNN块之上构建Transformer块;
- (2)交替堆叠GNN和Transformer块(2021);
- (3)并行化GNN和Transformer块(2020)。
大多数工作(Rong等人2020a; Mialon等人2021)采用了第一种架构。特别是,GraphTrans(Wu等人2021)在标准GNN模块之后应用了一个置换不变的Transformer模块,以学习高级别和长程关系。Graph-Transformer架构也被引入来处理WSI分析任务(Zheng等人2021)。然而,现有研究局限于单任务设置,并没有关注利用病理学家的领域知识来更好地设计模型。
Graph-based Shared Feature Learning
Task-aware Knowledge Injection
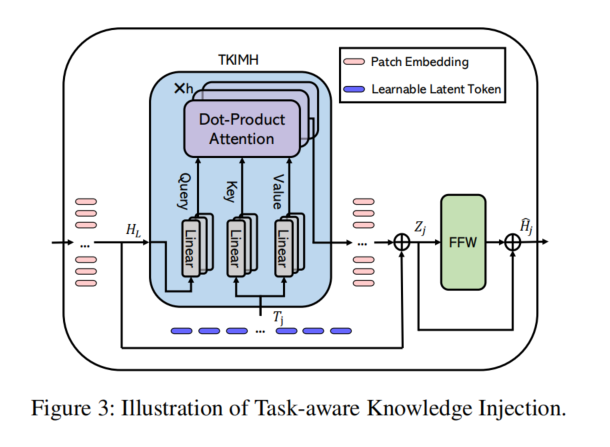
为了更准确地表示不同任务的表示学习,我们提出了一个任务感知知识注入模块,将任务特定的知识存储在不同的任务分支中,因此从任务共享的GCN中传输任务共享特征到任务特定的特征空间。该模块基于多头注意力机制,计算任务共享特征与任务特定知识之间的相关性。为了将任务共享特征转移到任务特定的空间中,我们设计了一个新颖的任务感知知识注入多头交叉注意力(TKIMH)块,如图3所示。
- 具体而言,我们将任务共享的隐藏表示HL作为查询(Q),将任务特定的可训练潜在标记Tj作为交叉多头注意力计算的键(K)和值(V)。
每个任务分支都有一个独立的可训练潜在标记集,能够在训练过程中存储从数据集中学习到的任务感知知识。

-
Domain Knowledge-driven Graph Pooling
-
Node Drop Pooling for Typing
节点丢弃池化用于分类。在临床诊断过程中,病理学家首先检查WSI以定位肿瘤区域,然后确定肿瘤类型。我们的节点丢弃池化方法旨在利用临床过程(如图4上部所示)。模型决策高度依赖于具有鉴别力的节点(即肿瘤亚型A/B节点),而不是整个图中不同类型节点的比例或形状。因此,只要保留其中一个肿瘤节点,节点丢弃方法就足以用于肿瘤分类任务。正如先前的工作(Papp等人2021)也指出,随机丢弃会增加GNN的表达能力,我们在每次训练中实现了随机和独立的节点丢弃,以生成用于肿瘤分类任务的任务感知池化表示ˆH
pool type。与基于排名的丢弃方法相比,我们的方案将使任务更具挑战性,并作为数据增强方法,使相应的分支更加健壮和强大,以检测具有鉴别力的图像区域。
- Node Clustering Pooling for Staging
节点聚类池化用于分期。病理学家的肿瘤分期诊断结果受到多种因素的影响,包括异常细胞、肿瘤区域的存在和大小以及转移性肿瘤。通常,整个图中肿瘤组织节点的比例和形状对于切片级别的肿瘤分期诊断至关重要,如图4底部所示。节点聚类池化方法更适合于分期任务,以保留整个图信息,而节点丢弃方法在丢弃过程中可能会丢失上述信息。受到GM-Pool(2021)的启发,我们设计了GCMinCut,这是MinCut Pooling(Bianchi,Grattarola和Alippi 2020)的改进版本,其中我们用额外的GC层替换了池化过程中的MLP,以导入图的邻域信息。