python语言用于深度学习较为广泛,R语言用于机器学习领域中的数据预测和数据处理算法较多,后续将更多分享机器学习数据预测相关知识的分享,有需要的朋友可持续关注,有疑问可以关注后私信留言。
文章目录
一、小提琴图
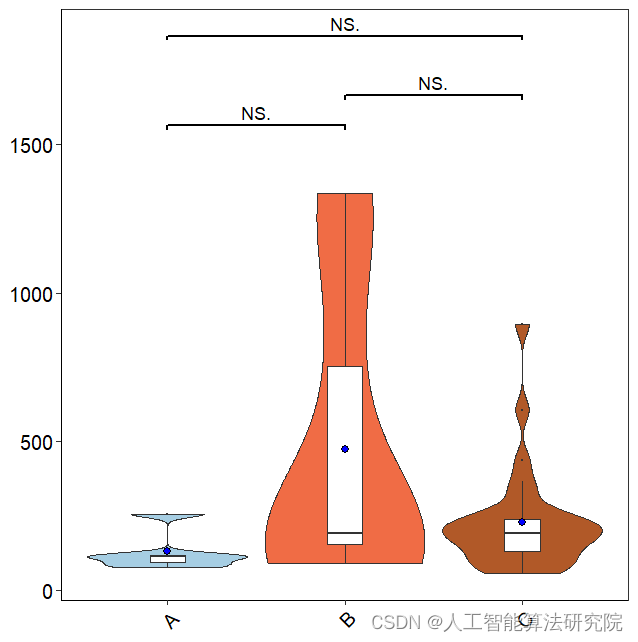
小提琴图(violin plot)是一种用于可视化数值数据分布情况的图表类型,它结合了箱线图和核密度图的优点。小提琴图通常用于比较多个组之间的分布差异,或者显示一个变量在不同类别下的分布情况。小提琴图的外形类似于小提琴,中间部分是数据的密度估计曲线,两侧是箱线图或者散点图。 小提琴图的横轴通常表示变量或者组别,纵轴表示数值变量的取值范围。每个小提琴图的宽度相同,高度表示数据的密度分布情况。小提琴图中的箱线图表示数据的五数概括(最小值、下四分位数、中位数、上四分位数、最大值),箱线图两侧的线条表示数据的范围。如果需要比较多个组之间的分布差异,可以将它们放在同一个小提琴图上进行比较。如果需要显示一个变量在不同类别下的分布情况,可以将它们分别画在不同的小提琴图中进行比较。
二、相关代码
# 导入所需的包
library(ggplot2)
# 读取数据
df <- read.csv("data.csv")
# 绘制小提琴图
ggplot(df, aes(x = Group, y = Value, fill = Group)) +
geom_violin(trim = TRUE, scale = "width") +
geom_boxplot(width = 0.1, fill = "white", alpha = 0.5) +
labs(x = "Group", y = "Value") +
theme_bw()其中,df为数据框,包含两列数据:Group表示分组名称,Value表示数值变量。使用ggplot()函数创建绘图对象,指定x轴为Group,y轴为Value,填充颜色为Group。使用geom_violin()函数绘制小提琴图,使用geom_boxplot()函数绘制箱线图。使用labs()函数添加图的标题。使用theme_bw()函数设置图的主题为黑白主题。
当需要设置18种颜色时,可以使用类似如下的代码:
col = c("#F8766D", "#7CAE00", "#00BFC4", "#C77CFF", "#F0E442", "#0072B2",
"#D55E00", "#CC79A7", "#56B4E9", "#009E73", "#E69F00", "#999999",
"#8C8C8C", "#BEBEBE", "#FB8072", "#80B1D3", "#FDB462", "#B3DE69")这里定义了一个长度为18的颜色向量,其中每个元素都是一个16进制颜色代码,可以使用不同的颜色代码替换掉其中的元素,例如:
col = c("red", "green", "blue", "yellow", "purple", "orange",
"pink", "gray", "brown", "cyan", "magenta", "black",
"darkred", "darkgreen", "darkblue", "darkorange", "lightgray", "navy")这里使用了18种不同的颜色名称,可以根据需要调整颜色名称。需要注意的是,颜色的选择应该遵循一定的规则,例如避免使用对比度过高的颜色,以免影响数据可视化效果。
三、小提琴图怎么看
小提琴图是一种用于展示数据分布情况的图表,它可以帮助我们更好地理解数据的中心趋势、离散程度以及异常值情况。小提琴图的主要组成部分有:

- 小提琴主体:类似于一个拉长的梨形,代表了数据的分布情况,中间的白点表示中位数。
- 箱线图:标识了数据的四分位数(Q1、Q2、Q3)、中位数和异常值。
- 数据点:通过散点图或抖动图的方式展示了原始数据的分布情况。 通过观察小提琴图,我们可以了解数据的分布情况和偏态程度。例如,如果小提琴主体左侧比右侧更宽,那么数据就呈现左偏态分布;如果两侧对称,那么数据就呈现正态分布;如果右侧比左侧更宽,那么数据就呈现右偏态分布。此外,我们还可以通过观察箱线图来了解数据的四分位数、中位数和异常值情况,以及通过散点图或抖动图来了解数据的密度分布情况。 总之,小提琴图可以帮助我们更好地理解数据的分布情况,同时也可以用于比较不同分组的数据分布情况。需要注意的是,小提琴图并不适合展示大量数据,因为它会对数据进行平滑处理,可能会掩盖数据的细节。在这种情况下,我们应该使用直方图、密度图等其他图表来展示数据的分布情况。
后续将持续分享决策树、随机森林、回归网络等用R语言来实现的机器学习算法的讲解,有需要的朋友请持续关注,有疑问可以关注后私信留言。