目录
在VMD--变分模态分解的使用中,他的k和alpha对分解结果影响很大,大量文章对这两个参数进行 了优化选择,比如通过分析模态的fft频谱,有通过优化算法的优化选择,网上也有少量matlab案例,但python的基本上没有,针对这个,本人写了一个python版本的。
1 原理
时间序列越复杂,样本熵SE的计算值越大,反之亦然。因此,应用VMD对信号进行分解后,计算每个子序列的SE值,SE最小的序列为所分解序列的趋势项。
当分解数K较小时,可能导致信号分解不足,趋势项中混入其他干扰项,导致SE值变大。当取适当的K值时,趋势项的SE变小。因此,将分解出的IMF中的最小的那个熵SE(局部样本熵)最小化时,VMD分解为最佳
当然样本熵有其局限性,所以目前又有很多方法,比如最小化包络熵、最小化谱相关峭度等,本文依旧以最小化局部样本熵为出发点编程
'''适应度函数,最小化各VMD分量的局部样本熵'''
def fitness(pop,data):
np.random.seed(0)
K = int(pop[0])
alpha = int(pop[1])
#print(K,alpha)
tau = 0
DC = 0
init = 1
tol = 1e-7
imf,res,u_hat,omega=VMD(data, alpha, tau, K, DC, init, tol)
comp=np.vstack([imf,res.reshape(1,-1)])
SE = 0
se_imf=[]
for i in range(comp.shape[0]):
temp= sampEn(comp[i,:], np.std(comp[i,:]),2, 0.15)
SE +=temp
se_imf.append(temp)
# fit = SE
# fit = SE/K
fit = min(se_imf)
np.random.seed(int(time.time()))
return fit
2 实战
2.1 原始时间序列

2.2 直接设置参数进行VMD分解

2.3 WOA优化VMD超参数
由于我们是最小化局部样本熵,所以适应度曲线是一条下降的曲线

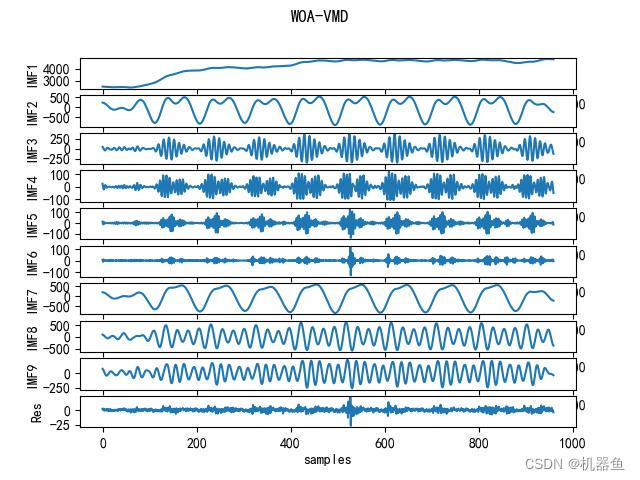
最优的k和alpha为9和65
iteration 1 = 0.03475234914892587 [6, 715]
iteration 2 = 0.03474872927521434 [6, 721]
iteration 3 = 0.03423725134060173 [8, 882]
iteration 4 = 0.034142069286057515 [9, 920]
iteration 5 = 0.015960969553223837 [9, 65]
iteration 6 = 0.015960969553223837 [9, 65]
iteration 7 = 0.015960969553223837 [9, 65]
iteration 8 = 0.015960969553223837 [9, 65]
iteration 9 = 0.015960969553223837 [9, 65]
iteration 10 = 0.015960969553223837 [9, 65]2.4 利用优化的参数进行VMD分解
3 代码
看我的博客评论区