【论文介绍】
提出了第一个基于物理的单图像无监督学习用于本征图像分解网络USI3D(Unsupervised Single Image Decomposition)
本征图像,是指将一幅图像分解成两个部分——反射图和照射图(或称本色图和高光图),这两幅分解得到图像就是原图像的本征图像。
【题目】:Unsupervised Learning for Intrinsic Image Decomposition From a Single Image
【DOI】:10.1109/cvpr42600.2020.00331
【会议】:2020-CVPR
【作者】:Yunfei Liu(北京航空航天大学), Yu Li(腾讯), Shaodi You(阿姆斯特丹大学), Feng Lu(鹏程实验室)
【Paper】: https://arxiv.org/abs/1911.09930
【Project】: https://liuyunfei.net/publication/cvpr2020_usi3d/external_pages/index.html
【Code】: https://github.com/DreamtaleCore/USI3D
【video】:https://www.youtube.com/watch?v=qGszWVyDF9c
【提出问题】
- 监督学习:数据集要么太小,要么离自然图像太远,限制了监督学习的性能。
- 传统方法:引入了各种先验来约束反射率和照度,但性能有限。
【解决方案】
自然图像、反射系数和明暗处理都共享相同的内容,这些内容反映了场景中目标对象的性质。自然图像中估计反射率和照度是传递图像风格而保留图像内容。为每个集合收集三个未标记且不相关的样本。然后,应用自动编码器和生成对抗性网络将自然图像转换为所需的风格,同时保留底层内容。
【怎么做】
可视化过程
假设收集未标记的和不相关的样本,学习每个集合的风格。例如,可以通过提供一组未标记的反射率图像来学习反射率的样式,即边缘分布 p(Rj): {Rj∈R};通过提供一组无标记的照度图像来学习照度样式,边缘分布p(Sk): {Sk∈S};通过提供一组未标记的自然图像 p(Ii ): {Ii ∈I} 来学习自然图像的样式,边缘分布 p(Ii )。然后,从边缘分布推断出 Ii 的 R(Ii ), S(Ii )。
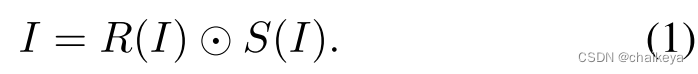
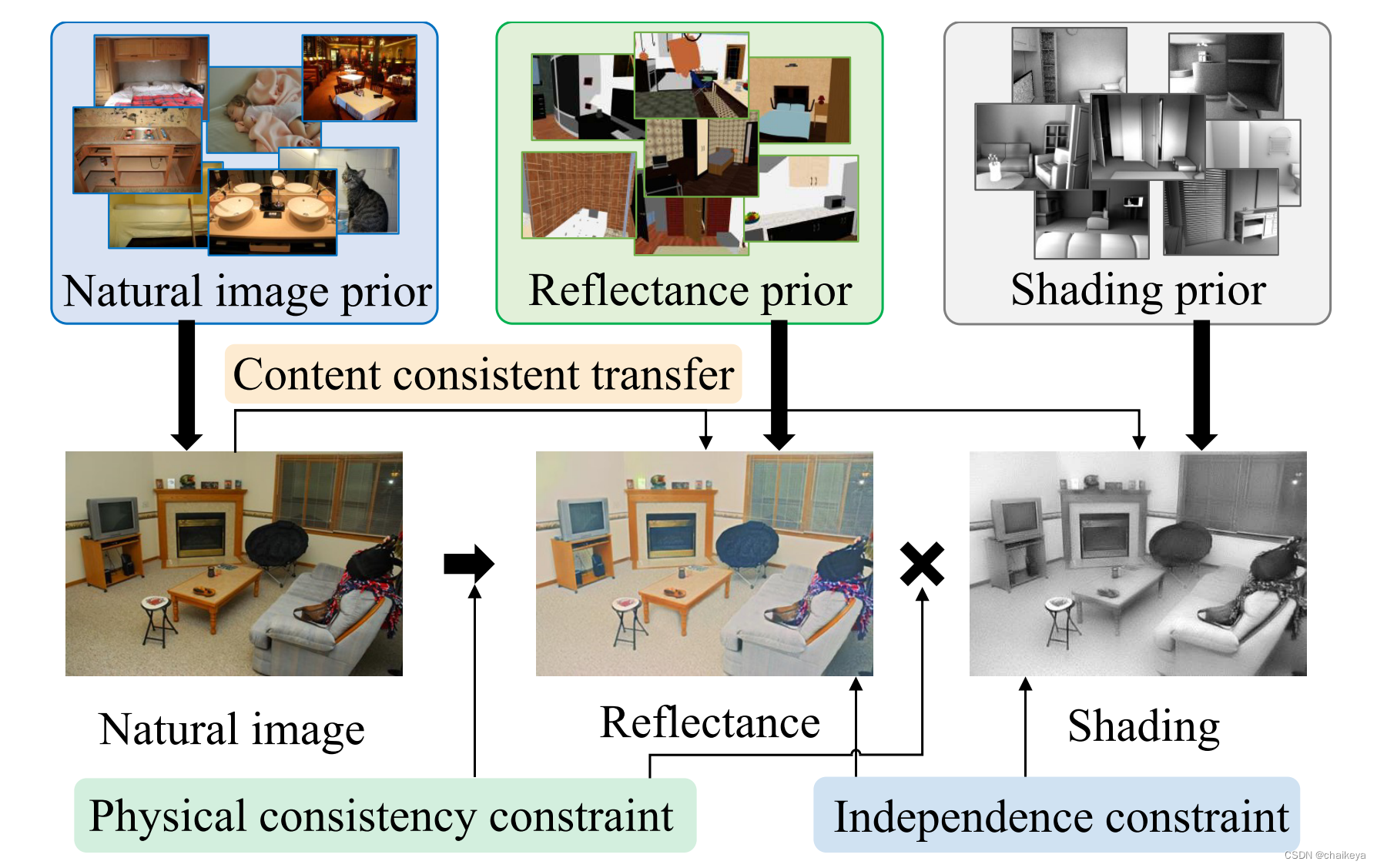
图1.以无监督的方式学习本征图像分解
- 其中真实配对的 R 和 S 在训练数据中不可用。
- 从 I 、R 和 S 的未标记和不相关的集合中学习分布先验。
- 通过具有独立性约束和物理一致性约束的内容保持图像转换来执行本征图像分解。
理论过程
I I I 是自然图像域,S是照度域,R是反射域。
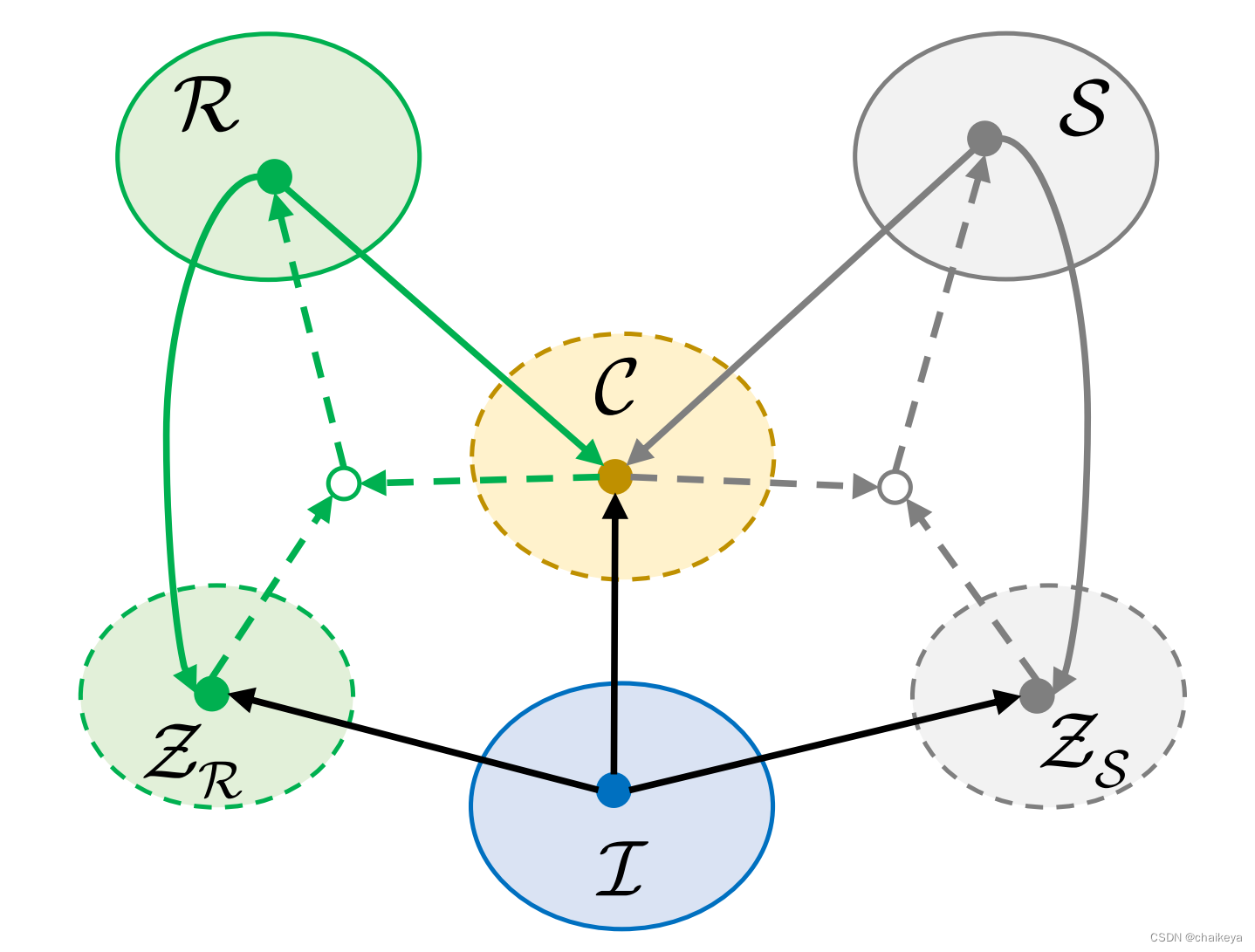
图2.域之间的内容保持转换
- 内容共享架构:学习一组编码器,这些编码器将每个域的外观编码到
域不变潜在空间C。- M模块:学习编码器依赖于域的先验空间将外观编码到相应的 z R z_{R} zR 和 z S z_{S} zS。
- 自动编码器:将图像样式从编码器(实线箭头)转移到生成器(虚线箭头)。
【创新点】
- 提出了第一个基于物理的单图像无监督学习用于本征图像分解。
- 采用了三个物理约束:物理一致性约束、域不变内容约束和反射率-照度独立性。
物理一致约束,如方程:I = R(I) * S(I),
域不变内容约束,即自然图像及其分解层共享相同的对象、布局和几何结构,
物理独立约束,即反射R是光照不变的,而照度S是光照可变的。
【网络结构】

内容共享架构
目的:学习一组编码器,这些编码器将每个域的外观编码到域不变潜在空间C。
假设1:域的内容不变。物理上,自然的外观,反射率和照度都是给定物体的外观。如图2所示,假设这样的对象属性可以是潜在编码和共享的数量域。根据样式转换术语,将这样的共享属性称为内容,表示为c ∈ C 。此外,假定内容可以从所有三个域编码。


- 首先,使用编码器 E I C E_{I}^{C} EIC 来提取输入图像 I i I_{i} Ii 的内容码 C C C,
- 然后,使用 C C C 分别通过生成器 G R G_{R} GR 和 G S G_{S} GS 生成分解层 R ( I i ) R(I_{i}) R(Ii) 和 S ( I i ) S(I_{i}) S(Ii)。
- 最后,使用 E R C E_{R}^{C} ERC 提取 R ( I i ) R(I_{i}) R(Ii) 的内容代码 C R ( I i ) C_{R(I_{i})} CR(Ii) , E S C E_{S}^{C} ESC 提取 S ( I i ) S(I_{i}) S(Ii) 的内容代码 C S ( I i ) C_{S(I_{i})} CS(Ii)。
应用内容一致性损失来使内容编码器 E I C E_{I}^{C} EIC、 E R C E_{R}^{C} ERC 和 E S C E_{S}^{C} ESC 正常工作。 具体来说,使用内容一致性损失 L c n t L^{cnt} Lcnt 来约束输入图像 I i I_{i} Ii 及其预测 R ( I i ) R(I_{i}) R(Ii) 和 S ( I i ) S(I_{i}) S(Ii) 之间的内容代码。

匹配模块(M 模块)
目的:学习编码器依赖于域的先验空间将外观编码到相应的 z R z_{R} zR 和 z S z_{S} zS。
假设2:反射率和照度独立。物理上,反射率是对照度和方向的不变性,而照度是方差。因此,为了分解反射率和照度这两个成分,假设它们的条件先验是独立的,可以分别学习。反射率的潜在先验表示为zR∈ZR,可以从反射率域和自然像域进行编码。照度的潜在先验表示为zS∈ZS,可以从照度域和自然像域进行编码。图中红色箭头表示的部分。

按照Assumption-2,反射率和照度的先验代码是域变的并且相互独立。设计了Mapping模块(M模块),从 I i I_{i} Ii 中推断出先验码 Z R ( I i ) Z_{R(I_{i})} ZR(Ii) 和 Z S ( I i ) Z_{S(I_{i})} ZS(Ii),如图3所示。

- 首先,通过编码器 E I p E_{I}^{p} EIp 提取自然图像 I i I_{i} Ii 的先验 Z I i Z_{I_{i}} ZIi,
- 然后,设计了一个
分解映射f d c p f_{dcp} fdcp 来推断先验 Z R ( I i ) Z_{R(I_{i})} ZR(Ii) 和 Z S ( I i ) Z_{S(I_{i})} ZS(Ii)。

为了在反射率先验域 z R z_{R} zR 中约束 Z R ( I i ) Z_{R(I_{i})} ZR(Ii),使用 Kullback-Leibler Divergence (KLD) 和从(非配对的数据集) z R z_{R} zR 采样的实际先验 Z R j Z_{R_{j}} ZRj。 Z S ( I i ) Z_{S(I_{i})} ZS(Ii) 以类似的方式生成和约束。KLD损失的定义:

其中,从M模块中提取先验代码 z ^ \hat{z} z^,从其真实图像中提取其真实先验代码 z z z。
有两个先验域 z R z_{R} zR 和 z S z_{S} zS,因此总KLD损失:

KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy)。它衡量的是相同事件空间里的两个概率分布的差异情况。并不是一种距离度量方式,其物理意义是:在相同事件空间里,概率分布P(x)对应的每个事件,若用概率分布 Q(x)编码时,平均每个基本事件(符号)编码长度增加了多少比特。我们用D(P||Q)表示KL距离,计算公式如下:

由公式可以知道:
- 当P(x)=Q(x)时,D(P||Q)=0,即其相对熵为零。
- 当P(x)和Q(x)相似度越高时,KL距离越小
- D(P||Q)非负(非负性)
- 不满足对称性,即D(P||Q)≠D(Q||P)
- 不满足三角不等式
KL距离的几个用途:
- 衡量两个概率分布的差异。
- 衡量利用概率分布Q 拟合概率分布P 时的能量损耗,也就是说拟合以后丢失了多少的信息。
- 衡量两个概率分布的相似度,在运动捕捉里面可以衡量未添加标签的运动与已添加标签的运动,进而进行运动的分类。
参考博客:https://blog.csdn.net/wangshun_410/article/details/84956539
自动编码器
目的:将图像样式从编码器(实线箭头)转移到生成器(虚线箭头)。
假设3:潜在代码编码器是可逆的。这种假设被广泛应用于图像到图像的转换中[12,17]。具体来说,该算法假设一幅图像可以被编码成潜码,潜码可以同时解码成图像。这允许我们在域之间传递样式和内容。特别是,这让我们可以把自然图像转换成反射率和照度。

根据假设3,实现了三个自动编码器 E E E。
图4左边示出了实现用于自然图像流的自动编码器的细节。(用于反射和照度的自动编码器以类似的方式实现)
遵循图像到图像转换方法[12,17],并使用双向重建约束,该双向重建约束能够在图像 I i I_{i} Ii→隐码 c I i c_{I_{i}} cIi→图像 I i ^ \hat{I_{i}} Ii^ 和 隐码 z I i z_{I_{i}} zIi→图像 I i ^ \hat{I_{i}} Ii^→隐码 z I i ^ z_{\hat{I_{i}} } zIi^ 两个方向上进行重建。
图4右边是生成器 G I G_{I} GI 的生成细节。

图像重建损失
给定从数据分布中采样的图像,可以在编码和解码后重建它。

先验的编码重建损失
给定在分解时从潜在分布中采样的先验编码,我们应该能够在解码和编码后对其进行重构。与公式 (3) 不同,公式 (3) 适用于约束两个样本的分布,图像先验编码重建 和 图像重建的约束应相同。这里我们用L1损失来表示 L p r i L^{pri} Lpri。

为了使分解后的固有图像在目标域中与真实图像无法区分,使用 GANs 将生成的图像的分布与目标数据分布进行匹配。对抗性损失的定义:

总对抗性损失

物理损失
I = R ( I ) ∗ S ( I ) I=R(I)*S(I) I=R(I)∗S(I), 意味着图像 I I I 等于其类似的 R ( I ) R(I) R(I) 和 S ( I ) S(I) S(I) 的像素乘积,因此可以使用这种物理损失来规范我们的方法:

其中, I i I_{i} Ii 表示原始输入, R ( I i ) R(I_{i}) R(Ii) 和 S ( I i ) S(I_{i}) S(Ii) 是非配对数据集上能构成与原图类似的分量。
总体损耗
通过使用 GAN 方案,联合训练编码器 E、解码器 G、映射函数 f 和鉴别器 D,以优化不同损失项的加权和。

【评价指标】
MSE:均方误差,越小越好。
LMSE:最小均方误差,越小越好。
DSSIM:相异结构相似性指数,越小越好。
【数据集 & 实验结果】
ShapeNet intrinsic 数据集
We use 8979 input images, 8978 reflectance images and 8978 shadings to train USI3D , each set is shuffled before training. We use the other 2245 images for evaluation.
用 8979 输入图像、8978 反射图像和 8978 照度图像对 USI3D 进行训练,训练前对每组图像进行洗牌。使用其他 2245 张图像进行评估。洗牌的目的就是为了不配对,做到无监督。
表1:ShapeNet intrinsic 数据集的数值比较。

图 5 是本文在ShapeNet intrinsic 数据集上的一个消融实验对比,并且和 WH18 这个方法做了对比。

MPI-Sintel benchmark
MPI-Sintel 基准[4]是一个合成数据集,包括来自18个场景的 890 幅图像,每幅 50 帧(除了一个包含40幅图像)。我们遵循 FY18[8] 进行数据扩增,生成 8900 个图像 patch。然后,采用双交叉验证得到所有的 890 个检验结果。在训练集中,我们随机选取一半的输入图像作为输入样本,保留文件名的反射率和照度图像分别作为我们的反射率样本和照度样本。
表2:MPI Sintel 数据集的数值比较。
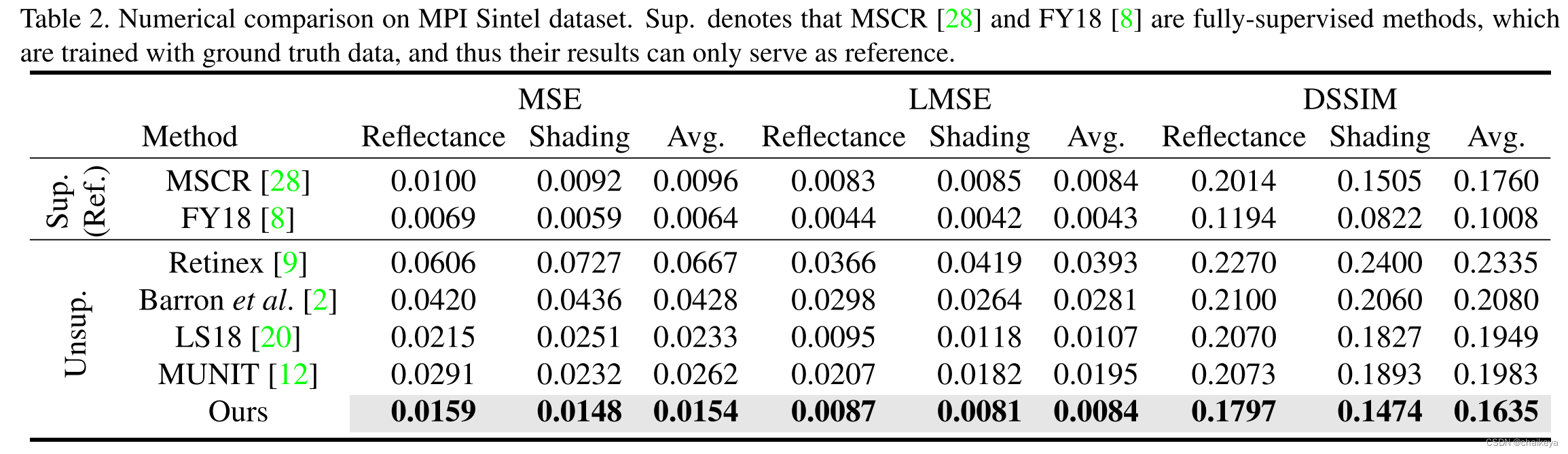
图7是在MPI-Sintel benchmark的实验对比,其中MSCR [28] 和 FY18 [8] 是有监督的方法。

MIT intrinsic dataset
为了测试在真实图像上的性能,使用了 MIT 本征数据集[32]中的 220 幅图像。这个数据只包含 20 个不同的对象,每个对象有 11 张图像。为了与以前的方法进行比较,我们通过[8]的分割使用 10 个对象来微调我们的模型,并使用剩下的对象来评估结果。
表3:麻省理工学院 MIT intrinsic 数据集的数值比较。

图8是在MIT intrinsic dataset的实验对比,其中MSCR [28] 和 FY18 [8] 是有监督的方法。

IIW benchmark + CGIntrinsics Dataset
IIW benchmark : http://opensurfaces.cs.cornell.edu/publications/intrinsic/
CGIntrinsics Dataset: http://www.cs.cornell.edu/projects/cgintrinsics/
IIW 基准[31]包含 5230 幅主要为室内场景的真实图像,并结合人类对图像中稀疏选择的点对之间的相对反射率的判断共 872,161 幅。我们将 IIW 的输入图像分割为训练集 (4184) 和测试集,方法与[8,19]相同。因为 IIW 数据集不包含反射率和照度图像,所以我们使用了渲染数据集 CGIntrinsics[19] 中未配对的反射率和照度。为了进行公平的训练,我们选择了按照图像 ID 排序的前 4000 张连续反射率和后 4000 张照度图像进行训练。训练集的样本如图7所示。

最后是一个使用加权人类不同意率 (WHDR) [29] 对 IIW 基准数据集进行数值比较。越低越好。
