遮挡目标检测持续汇总
常常将遮挡分为目标与目标间的遮挡(Crowd)、目标与背景间的遮挡(Occlusion)
文章目录
-
遮挡目标检测持续汇总 -
- Double Anchor R-CNN for Human Detection in a Crowd
- Bi-box Regression for Pedestrian Detection and Occlusion Estimation
- Detection in Crowded Scenes: One Proposal, Multiple Predictions
- Adaptive NMS: Refining Pedestrian Detection in a Crowd
- NMS by Representative Region: Towards Crowded Pedestrian Detection by Proposal Pairing
- Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd
- PSC-Net: Learning Part Spatial Co-occurrence for Occluded Pedestrian Detection
- Repulsion Loss: Detecting Pedestrians in a Crowd
- Tracking Pedestrian Heads in Dense Crowd
Double Anchor R-CNN for Human Detection in a Crowd
Abstract: Detecting human in a crowd is a challenging problem due to the uncertainties of occlusion patterns. In this paper, we propose to handle the crowd occlusion problem in human detection by leveraging the head part. Double Anchor RPN is developed to capture body and head parts in pairs. A proposal crossover strategy is introduced to generate highquality proposals for both parts as a training augmentation. Features of coupled proposals are then aggregated efficiently to exploit the inherent relationship. Finally, a Joint NMS module is developed for robust post-processing. The proposed framework, called Double Anchor R-CNN, is able to detect the body and head for each person simultaneously in crowded scenarios. State-of-the-art results are reported on challenging human detection datasets. Our model yields log-average miss rates (MR) of 51.79pp on CrowdHuman, 55.01pp on COCOPersons (crowded sub-dataset) and 40.02pp on CrowdPose (crowded sub-dataset), which outperforms previous baseline detectors by 3.57pp, 3.82pp, and 4.24pp, respectively. We hope our simple and effective approach will serve as a solid baseline and help ease future research in crowded human detection.
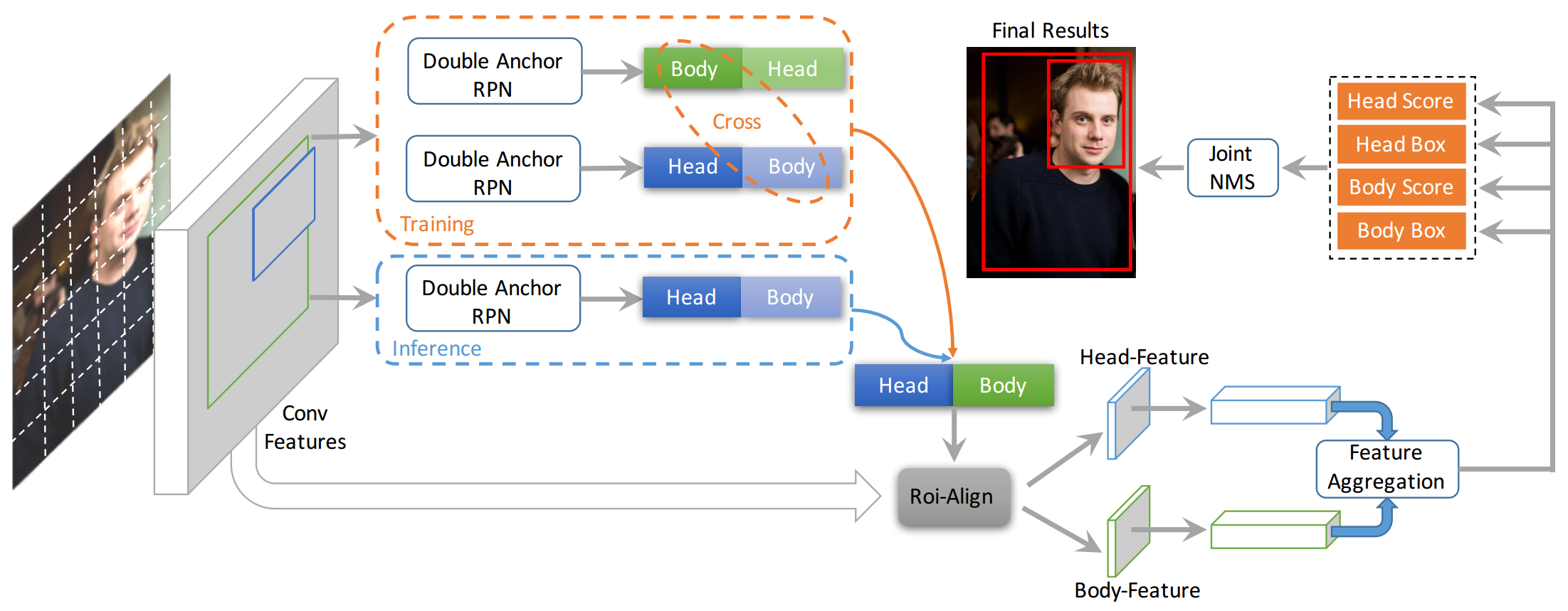
动机:
- 在密集目标场景下,有大量的尺度、比例、姿态上的形变,如何使检测更加鲁棒
- 当行人互相之间的重叠面很大,不同实例间语义特征也会相互影响,从而使检测器难以框出目标,因此检测器将Crowd时的目标看作一个整体,或偏移BBOX远离错误目标
- 尽管目标检测器能很成功地检测出目标,由于NMS的后处理,NMS的高阈值使高度重叠的实例引入了更多的误检(FP, false positive)
通常的做法是,在遮挡场景下关注实例的其中一部分,当整个身体不能在遮挡行人中检测时,其可见的部分能够给出高分并指导检测器。
创新点:
- 提出利用头部来处理人体检测中的人群遮挡问题
方法:
- 基于FasterRCNN结构,在RPN结构中同时输出Body offsets和Head offsets,加入了Body和Head两种检测目标
- 后续的预测头、非极大值抑制会对此做相应改进
Bi-box Regression for Pedestrian Detection and Occlusion Estimation
Abstract: Occlusions present a great challenge for pedestrian detection in practical applications. In this paper, we propose a novel approach to simultaneous pedestrian detection and occlusion estimation by regressing two bounding boxes to localize the full body as well as the visible part of a pedestrian respectively. For this purpose, we learn a deep convolutional neural network (CNN) consisting of two branches, one for full body estimation and the other for visible part estimation. The two branches are treated differently during training such that they are learned to produce complementary outputs which can be further fused to improve detection performance. The full body estimation branch is trained to regress full body regions for positive pedestrian proposals, while the visible part estimation branch is trained to regress visible part regions for both positive and negative pedestrian proposals. The visible part region of a negative pedestrian proposal is forced to shrink to its center. In addition, we introduce a new criterion for selecting positive training examples, which contributes largely to heavily occluded pedestrian detection. We validate the effectiveness of the proposed bi-box regression approach on the Caltech and CityPersons datasets. Experimental results show that our approach achieves promising performance for detecting both non-occluded and occluded pedestrians, especially heavily occluded ones.

创新点:
提出检测器预测身体的可见部分和不可见部分,针对文章提出的预测可见部分、不可见部分的出发点,提出了训练策略和loss function,
方法:
- 基于FasterRCNN结构,在预测头部分加入两个分支,一个分支用于预测可见部分,一个分支用于预测整个身体
- 改进训练策略,由于需要预测可见和不可见部分,因此训练时,两部分单独训练
- 提出了新的loss function适应此网络结构
Detection in Crowded Scenes: One Proposal, Multiple Predictions
Abstract: We propose a simple yet effective proposal-based object detector, aiming at detecting highly-overlapped instances in crowded scenes. The key of our approach is to let each proposal predict a set of correlated instances rather than a single one in previous proposal-based frameworks. Equipped with new techniques such as EMD Loss and Set NMS, our detector can effectively handle the difficulty of detecting highly overlapped objects. On a FPN-Res50 baseline, our detector can obtain 4.9% AP gains on challenging CrowdHuman dataset and 1.0% MR−2 improvements on CityPersons dataset, without bells and whistles. Moreover, on less crowed datasets like COCO, our approach can still achieve moderate improvement, suggesting the proposed method is robust to crowdedness.
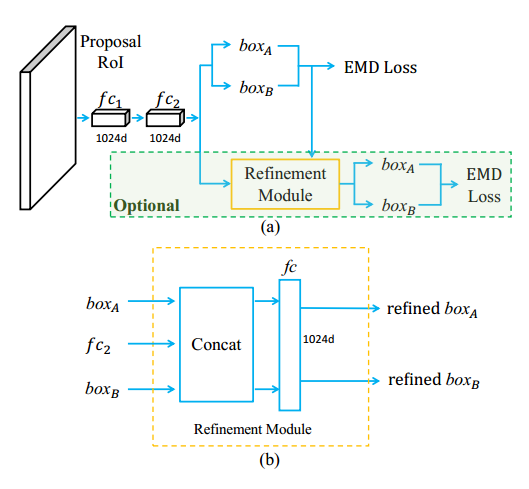
创新点:
以往的目标检测算法,对于一个grid或者提议框,只对应预测一个目标,可是当两者目标大小相似,且高度重叠时,检测器无法检测或检测器能检测但NMS要被过滤掉,因此选择针对高度重叠目标入手,每个位置可以预测最多k个目标,同时对NMS和loss function做相应改进
方法:
- 对于每一个提议框 b i {b_i} bi,我们去预测一个集合 G ( b i ) G(b_i) G(bi)而不是单个目标
- 针对预测多个目标的提议框,采用EMD loss
- 提出Set NMS,针对同一个grid预测出来的多个目标,不对其进行抑制
Adaptive NMS: Refining Pedestrian Detection in a Crowd
Abstract: Pedestrian detection in a crowd is a very challenging issue. This paper addresses this problem by a novel NonMaximum Suppression (NMS) algorithm to better refine the bounding boxes given by detectors. The contributions are threefold: (1) we propose adaptive-NMS, which applies a dynamic suppression threshold to an instance, according to the target density; (2) we design an efficient subnetwork to learn density scores, which can be conveniently embedded into both the single-stage and two-stage detectors; and (3) we achieve state of the art results on the CityPersons and CrowdHuman benchmarks.
创新点:
基于Soft-NMS,针对crowd中的行人检测场景,优化soft-NMS,即,密集场景中的行人不是处处拥挤的,希望使得在人群密集的地方NMS阈值设置得大,人群稀疏的地方NMS阈值较小
方法:
- 作者在Soft-NMS中加入密度估计,通过密集程度设定NMS阈值,若密集程度很高,则阈值更高,若密集程度低,则阈值为正常的阈值。
soft-nms阈值方法
KaTeX parse error: Unknown column alignment: * at position 28: … \begin{array}{*̲*lr**} s_i, \qu…
其中 N t N_t Nt表示设定的阈值
Adaptive-NMS阈值方法
N m : = m a x ( N t , d M ) N_m:=max(N_t,d_M) Nm:=max(Nt,dM)
KaTeX parse error: Unknown column alignment: * at position 27: …{\begin{array}{*̲*lr**}s_i, \qua…
其中 N M N_M NM表示设定的阈值,是在普通阈值 N t N_t Nt和密度估计 d M d_M dM之间选择的最大值
- 密度估计由CNN产生,如下图所示,是结合了两阶段和单阶段算法的集成的目标检测算法
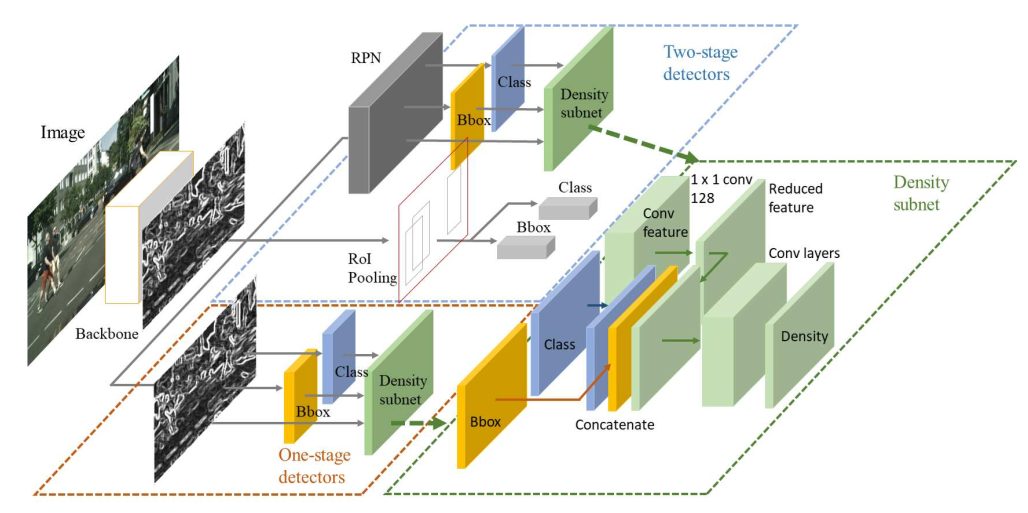
NMS by Representative Region: Towards Crowded Pedestrian Detection by Proposal Pairing
Abstract: Although significant progress has been made in pedestrian detection recently, pedestrian detection in crowded scenes is still challenging. The heavy occlusion between pedestrians imposes great challenges to the standard NonMaximum Suppression (NMS). A relative low threshold of intersection over union (IoU) leads to missing highly overlapped pedestrians, while a higher one brings in plenty of false positives. To avoid such a dilemma, this paper proposes a novel Representative Region NMS (R2NMS) approach leveraging the less occluded visible parts, effectively removing the redundant boxes without bringing in many false positives. To acquire the visible parts, a novel PairedBox Model (PBM) is proposed to simultaneously predict the full and visible boxes of a pedestrian. The full and visible boxes constitute a pair serving as the sample unit of the model, thus guaranteeing a strong correspondence between the two boxes throughout the detection pipeline. Moreover, convenient feature integration of the two boxes is allowed for the better performance on both full and visible pedestrian detection tasks. Experiments on the challenging CrowdHuman [20] and CityPersons [25] benchmarks sufficiently validate the effectiveness of the proposed approach on pedestrian detection in the crowded situation.
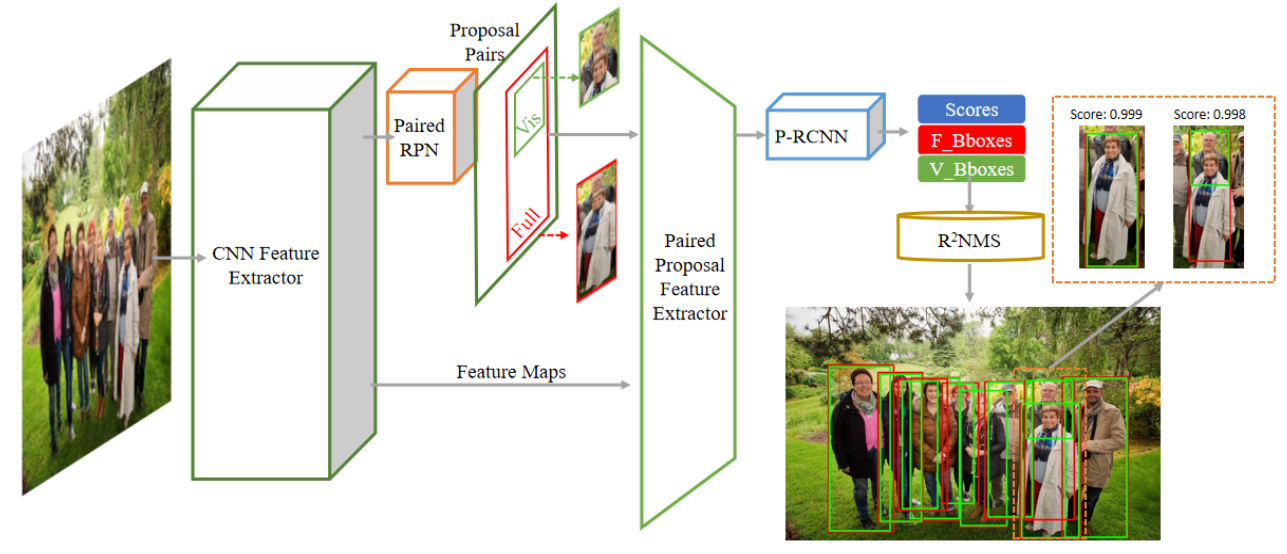
创新点:
基于Bi-box Regression这一篇工作,检测器输出可见和不可见部分,改进了NMS方法,命名为 R 2 N M S R^2NMS R2NMS
方法:
文中提到,可见区域BBOX之间的IOU是一个更好地显示两个全身BBOX是否属于同一个行人的评判标准,即若两个人前后被遮挡,前方的人可见区域很大,而后面的人可见区域很小,则两个BBOX大小相差很大,NMS会保留两个BBOX;若两个人前后被遮挡,采用全身的BBOX进行NMS,则两个BBOX的大小相似,且IOU重叠度高,NMS的IOU过大,会被滤除。
普通的NMS方法,只不过NMS的输入为可见区域的BBOX,最后与可见区域BBOX对应的全身BBOX作为输出结果。
Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd
Abstract: Pedestrian detection in crowded scenes is a challenging problem since the pedestrians often gather together and occlude each other. In this paper, we propose a new occlusion-aware R-CNN (OR-CNN) to improve the detection accuracy in the crowd. Specifically, we design a new aggregation loss to enforce proposals to be close and locate compactly to the corresponding objects. Meanwhile, we use a new part occlusion aware region of interest (PORoI) pooling unit to replace the RoI pooling layer in order to integrate the prior structure information of human body with visibility prediction into the network to handle occlusion. Our detector is trained in an end-to-end fashion, which achieves state-of-the-art results on three pedestrian detection datasets, i.e., CityPersons, ETH, and INRIA, and performs on-pair with the state-of-the-arts on Caltech.

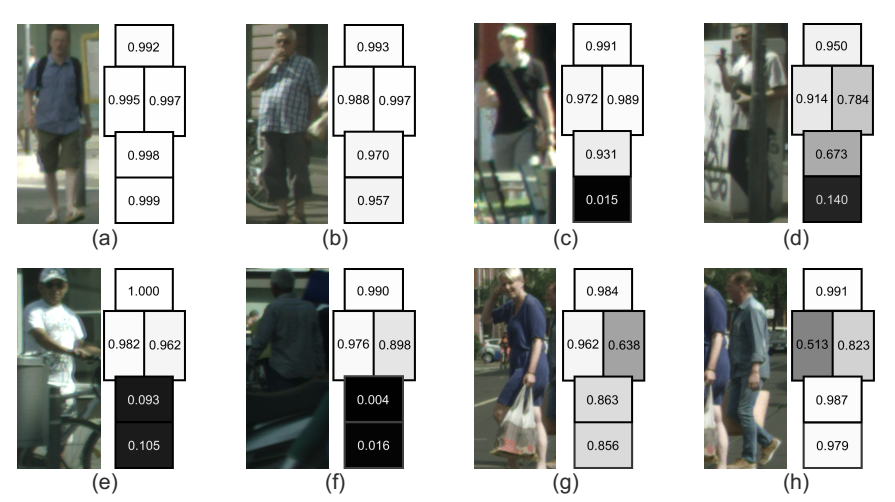
创新点:
- 在解决遮挡问题上,提出了aggrrgation loss和身体多部位可见性预测
方法:
- 将人体分成5个部分预测每个部分的遮挡情况,若遮挡比例大于0.5,则GT设为1,否则设为0
- 针对每个部分单独做ROI pooling,预测其可见性
- 提出aggrrgation loss使得anchor赋值到相同目标的proposal尽可能近
PSC-Net: Learning Part Spatial Co-occurrence for Occluded Pedestrian Detection
Abstract: Detecting pedestrians, especially under heavy occlusions, is a challenging computer vision problem with numerous real-world applications. This paper introduces a novel approach, termed as PSC-Net, for occluded pedestrian detection. The proposed PSC-Net contains a dedicated module that is designed to explicitly capture both inter and intra-part co-occurrence information of different pedestrian body parts through a Graph Convolutional Network (GCN). Both inter and intra-part cooccurrence information contribute towards improving the feature representation for handling varying level of occlusions, ranging from partial to severe occlusions. Our PSC-Net exploits the topological structure of pedestrian and does not require partbased annotations or additional visible bounding-box (VBB) information to learn part spatial co-occurrence. Comprehensive experiments are performed on two challenging datasets: CityPersons and Caltech datasets. The proposed PSC-Net achieves stateof the-art detection performance on both. On the heavy occluded (HO) set of CityPerosns test set, our PSC-Net obtains an absolute gain of 4.0% in terms of log-average miss rate over the state-ofthe-art [34] with same backbone, input scale and without using additional VBB supervision. Further, PSC-Net improves the stateof-the-art [54] from 37.9 to 34.8 in terms of log-average miss rate on Caltech (HO) test set.
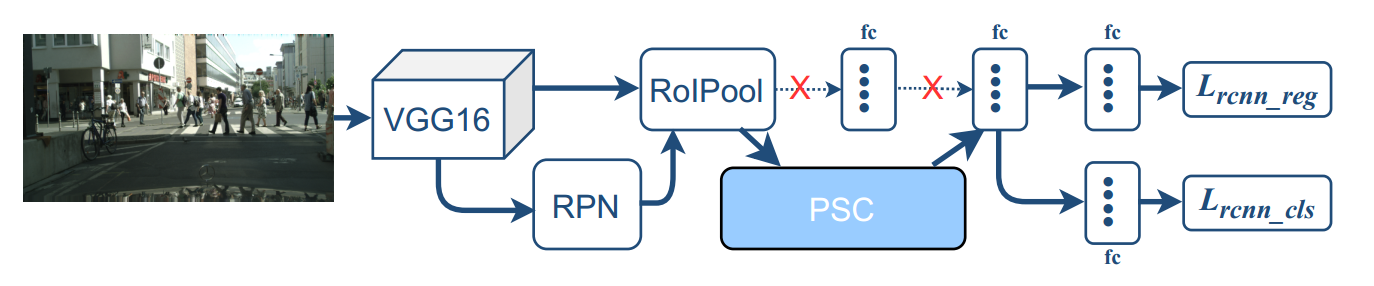
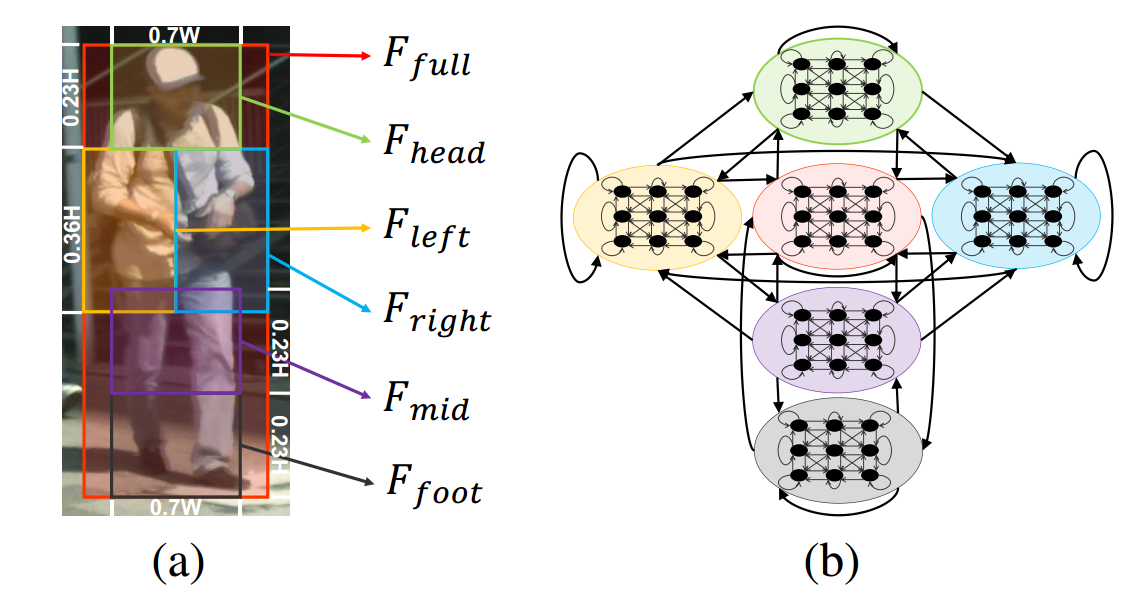
创新点
- OARCNN的基础上,加入了GCN图神经网络使得五个部分的部分间和部分内的共有信息被加强
方法:
-
在五个部位建模图神经网络,单个部分内部将像素建模为图网络,五个大的部分也为一个图网络结构
-
Intra-part Co-occurrence(部分内信息):
- 对每个部分 F m F_m Fm内部,得到关于特征图点的带权重的邻接矩阵,方法如下
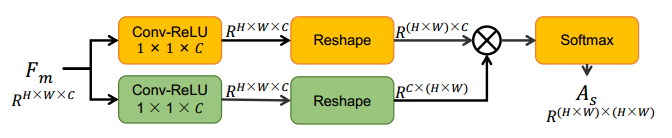
- 之后通过GCN做特征融合,融合公式为 F ^ m = σ ( A s F m W s ) \hat{F}_m=\sigma(A_s F_m W_s) F^m=σ(AsFmWs)
-
Inter-part Co-occurrence(部分间信息):
- 邻接矩阵如PSC模块所示,不相连则为0,相连则通过自注意力机制计算其边权重
- 之后通过GCN做特征融合,融合公式为 F ^ e = σ ( ( I − A p ) F e W p ) \hat{F}_e=\sigma((I-A_p)F_e W_p) F^e=σ((I−Ap)FeWp)
Repulsion Loss: Detecting Pedestrians in a Crowd
Detecting individual pedestrians in a crowd remains a challenging problem since the pedestrians often gather together and occlude each other in real-world scenarios. In this paper, we first explore how a state-of-the-art pedestrian detector is harmed by crowd occlusion via experimentation, providing insights into the crowd occlusion problem. Then, we propose a novel bounding box regression loss specifically designed for crowd scenes, termed repulsion loss. This loss is driven by two motivations: the attraction by target, and the repulsion by other surrounding objects. The repulsion term prevents the proposal from shifting to surrounding objects thus leading to more crowd-robust localization. Our detector trained by repulsion loss outperforms the state-ofthe-art methods with a significant improvement in occlusion cases.
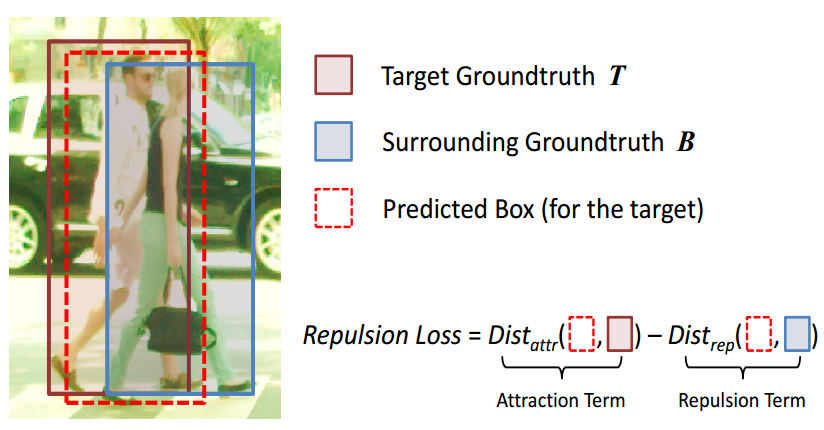
创新点:
- 密集行人场景下,行人的GT也会拥挤,靠的很近,当预测框预测目标A时,也会被目标B带偏,针对这种情况,文中提出了Repulsion loss解决这个问题,即训练的时候利用Repulsion loss使预测框与预测目标更接近,而远离周边的真实框
方法:
- Repulsion loss如下
L = L A t t r + α L R e p G T + β L R e p B O x L = L_{Attr}+\alpha L_{RepGT} + \beta L_{RepBOx} L=LAttr+αLRepGT+βLRepBOx
- L A t t r L_{Attr} LAttr
L A t t r L_{Attr} LAttr目的是使预测框和它的目标框更加接近
L A t t r = ∑ P ∈ P + S m o o t h L 1 ( B P , G A t t r p ) ∣ P + ∣ L_{Attr} = \cfrac{\sum_{P\in P_+}Smooth_{L1}(B^P,G_{Attr}^p)}{|P_+|} LAttr=∣P+∣∑P∈P+SmoothL1(BP,GAttrp)
- L R e p G T L_{RepGT} LRepGT
L R e p G T {L_{RepGT}} LRepGT目的是使得预测框和它目标框周围的框尽可能远,周围的框选取的是除目标框以外的IOU最大的框 G R e p P G_{Rep}^P GRepP
L R e p G T = ∑ P ∈ P + S m o o t h l n ( I O G ( B P , G R e p p ) ) ∣ P + ∣ L_{RepGT} = \cfrac{\sum_{P\in P_+}Smooth_{ln}(IOG(B^P,G_{Rep}^p))}{|P_+|} LRepGT=∣P+∣∑P∈P+Smoothln(IOG(BP,GRepp))
其中IOG为,预测框和周围框的 交 集 最 大 周 围 框 a r e a ( B ∩ G ) a r e a ( G ) \frac{交集}{最大周围框}\quad \frac{area(B \cap G)}{area(G)} 最大周围框交集area(G)area(B∩G)的比例
- L R e p B o x L_{RepBox} LRepBox
L R e p B o x = ∑ i ≠ j S m o o t h l n ( I O U ( B P i , B P j ) ) ∑ i ≠ j 1 [ I O U ( B P i , B P j ) > 0 ] + ε L_{RepBox} = \cfrac{\sum_{i \neq j } Smooth_{ln}(IOU(B^{P_i}, B^{P_j}))}{\sum_{i \neq j} \mathbb 1[IOU(B^{P_i}, B^{P_j}) > 0] + \varepsilon} LRepBox=∑i=j1[IOU(BPi,BPj)>0]+ε∑i=jSmoothln(IOU(BPi,BPj))
L R e p B o x L_{RepBox} LRepBox目的是使得预测框和预测框之间的距离尽可能远
Tracking Pedestrian Heads in Dense Crowd
Tracking humans in crowded video sequences is an important constituent of visual scene understanding. Increasing crowd density challenges visibility of humans, limiting the scalability of existing pedestrian trackers to higher crowd densities. For that reason, we propose to revitalize head tracking with Crowd of Heads Dataset (CroHD), consisting of 9 sequences of 11,463 frames with over 2,276,838 heads and 5,230 tracks annotated in diverse scenes. For evaluation, we proposed a new metric, IDEucl, to measure an algorithm’s efficacy in preserving a unique identity for the longest stretch in image coordinate space, thus building a correspondence between pedestrian crowd motion and the performance of a tracking algorithm. Moreover, we also propose a new head detector, HeadHunter, which is designed for small head detection in crowded scenes. We extend HeadHunter with a Particle Filter and a color histogram based re-identification module for head tracking. To establish this as a strong baseline, we compare our tracker with existing state-of-the-art pedestrian trackers on CroHD and demonstrate superiority, especially in identity preserving tracking metrics. With a light-weight head detector and a tracker which is efficient at identity preservation, we believe our contributions will serve useful in advancement of pedestrian tracking in dense crowds. We make our dataset, code and models publicly available at https://project.inria.fr/crowdscience/project/dense-crowd-head-tracking/

创新点:
- 构建了一个头部检测器
- 构建了基于粒子滤波的头部跟踪器
- 提出了使用轨迹重合比例的跟踪评估指标
方法:
- 网络结构如图所示,ResNet50后接FPN,每一层FPN特征层接CPM模块,后接转置卷积提高分辨率,接RPN输出预测结果
- 跟踪采用粒子滤波,基本基于Tracktor方法,对前一帧的位置微调位置