

CodeFuse 开源火热进行中!本次开源的是 ModelCache 大模型语义缓存,可大幅降低大模型应用的推理成本,提升用户体验。
CodeFuse-ModelCache 项目地址:
https://github.com/codefuse-ai/CodeFuse-ModelCache
0 背景
在LLM技术浪潮席卷全球的背景下,大型模型快速增长的参数规模,对部署所需的推理资源带来了极大的挑战。为了提高大型模型的推理性能和效率,我们尝试从缓存角度解决当前大模型规模化服务部署的困境。类似传统应用,大模型的用户访问同样具有时间和空间的局部性(例如:热门话题相关内容,热门 GitHub repo)。如果有了缓存层,在遇到相似请求时,就无需调用大模型服务,直接从缓存的数据中返回已有的结果给用户,会大幅降低推理成本,提升用户体验。
1 大模型缓存的意义
当前大模型服务面临一下三个挑战:
- 成本高:大模型参数量千亿级别,单实例就需要多张A10卡,规模化部署成本高昂。因此,当前大模型服务基本按照处理的token数量计费,导致用户侧使用成本也居高不下。
- 速度慢:大型模型的推理速度也是一个关键问题。在许多实时应用中,如对话系统、业务助手,响应时间要求非常高,通常在毫秒级别。然而,大型模型的推理速度往往较慢,在秒级,导致无法实时返回结果,用户体验下降。
- 稳定性无保障:由于单实例部署成本高昂,当前大模型服务接受到大流量请求时,通过限流的方式,防止服务不可用。
2 方案调研
我们对开源方案GPTCache进行了调研,其是致力于构建用于存储 LLM 响应的语义缓存的项目,该项目提供了语义相似度匹配框架,并提供了相对完善的功能模块和接口。具有以下优点:
- 项目的活跃性,它不断引入新功能,使得我们能够紧跟最新的发展动态。
- 具备开放的功能模块,可以进行调整和优化,这为业务的扩展提供了便利。
GPTCache的整体架构如图1所示:
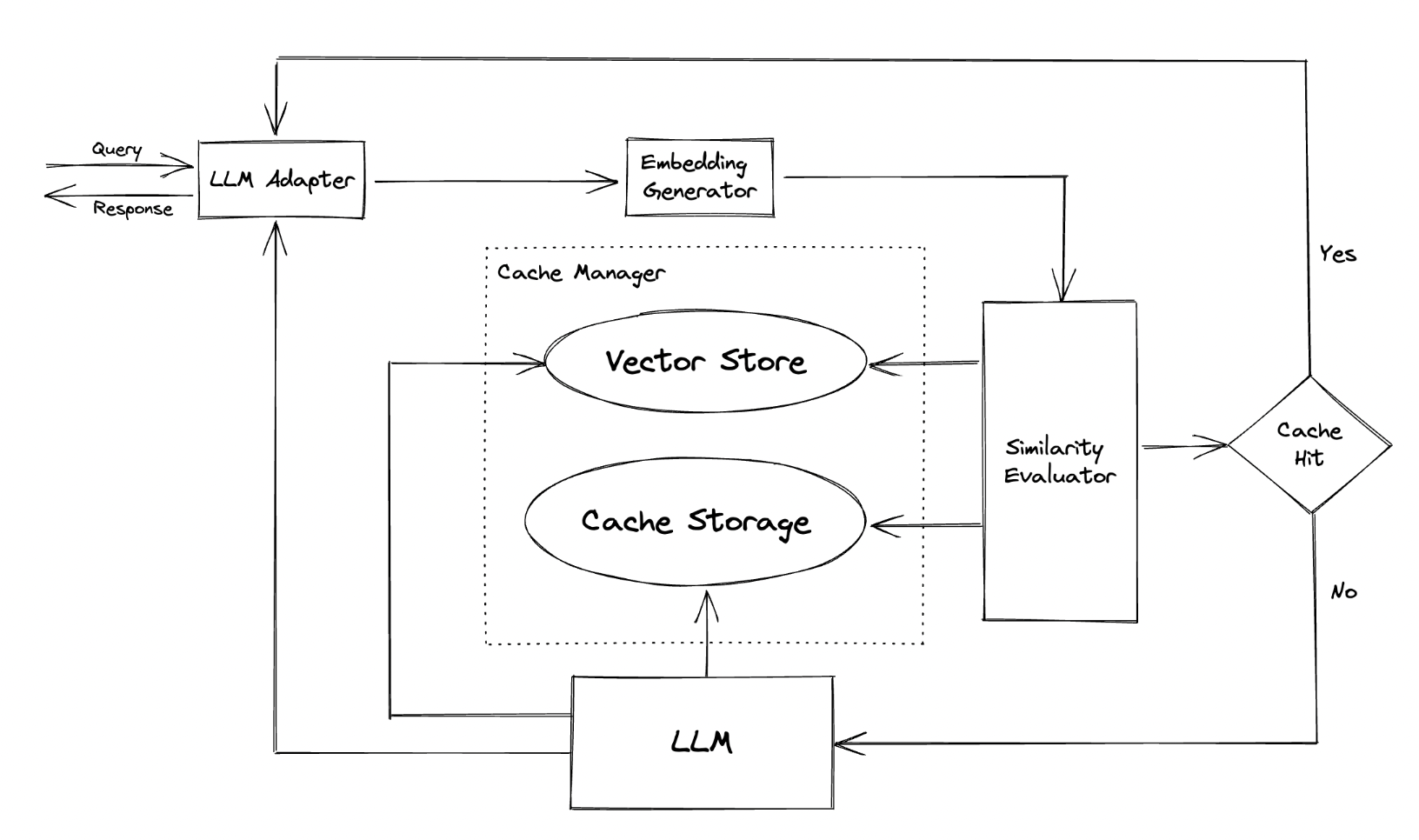
图1. GPTCache架构
但是,GPTCache在落地应用上仍存在诸多不足,包括:
- 架构上将大模型调用和数据回写对用户进行了黑盒处理,使得大模型产品在流式输出、安全审核、问题排查等方面变的复杂。
- 默认采用faiss和sqlite作为存储,不能进行分布式部署,尤其是在关系型数据库方面,SqlAlchemy框架无法支持蚂蚁的OceanBase。
- 数据和资源隔离上,无法处理多模型多版本场景。
- 不支持多轮会话,尤其是当模型有system指令时,无法很好兼容。更多待改进功能会在3.3部分会做详细介绍。
3 ModelCache建设
针对上述问题,我们基于GPTCache进行了二次开发,构建蚂蚁内部缓存产品ModelCache,整体架构见图2,接下来会详细介绍我们的工作,包括:3.1 整体架构;3.2 功能升级。在功能升级部分,会详细介绍ModelCache中新增的功能点。
3.1 整体架构
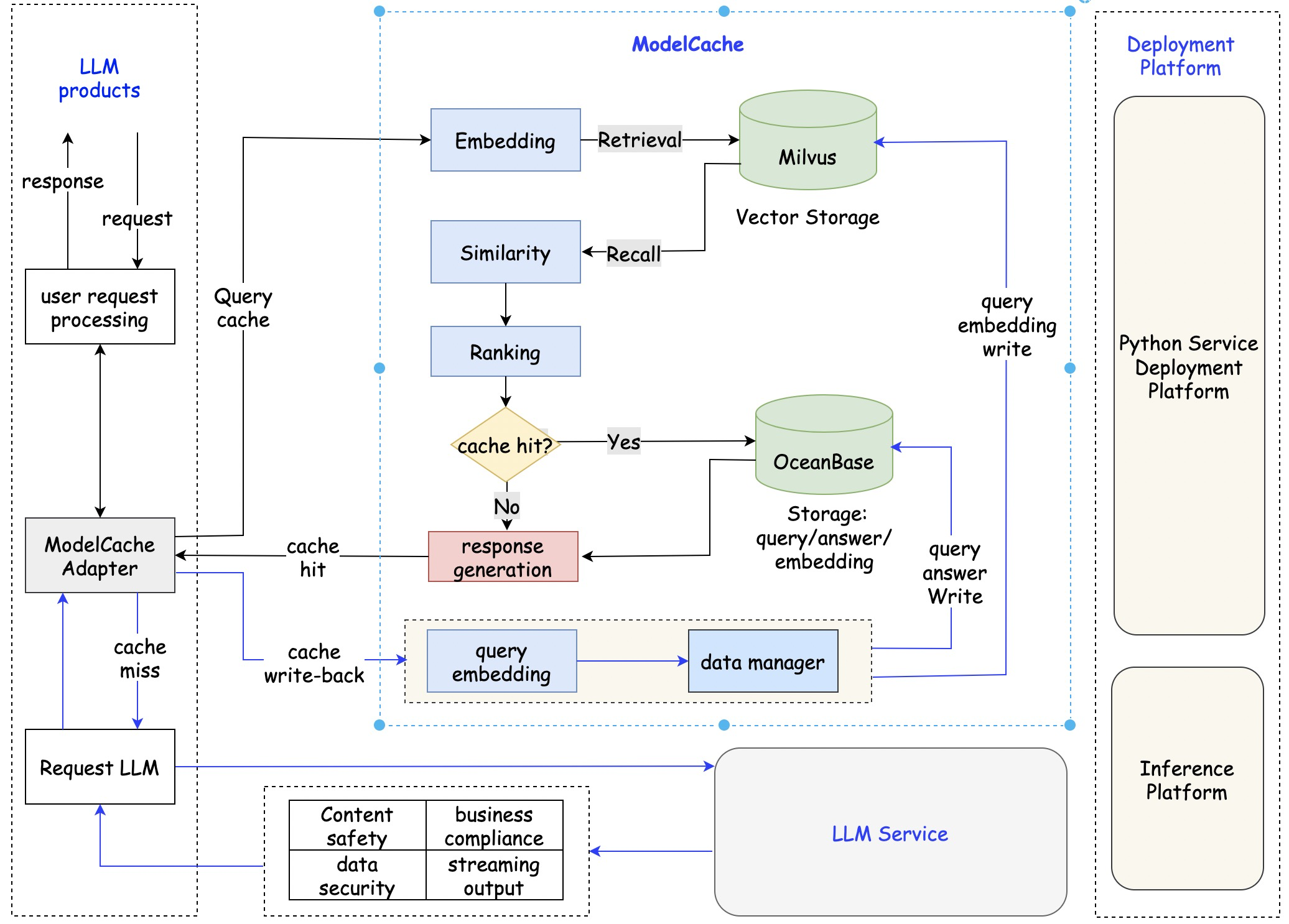
图2. ModelCache架构及上下游
3.1.1 技术架构
在初始架构中,将大模型调用和数据回写对用户进行了黑盒处理。然而,这种架构导致问题排查繁琐,以及流式输出和数据安全审核等方面难以满足企业级要求。
因此,我们对架构进行了重新调整,ModelCache采用了轻量化的接入方式,不打扰大模型产品的功能实现。我们设计ModelCache为类redis结构,提供了开放式的数据查询、数据回写、数据管理等API,同时解耦了大模型调用,可作为一个独立模块嵌入到大模型产品。通过ModelCache,产品侧能够更加灵活地管理和使用大模型,提高系统的可维护性和可扩展性。
3.1.2 核心模块
在ModelCache中,包含了一系列核心模块,包括adapter、embedding、rank和data_manager等,具体功能如下:
- adapter模块:其主要功能是处理各种任务的业务逻辑,并且能够将embedding、rank、data_manager等模块串联起来。
- embedding模块:该模块主要负责将文本转换为语义向量表示,它将用户的查询转换为向量形式,并用于后续的召回或存储操作。
- rank模块:用于对召回的向量进行相似度排序和评估,可根据L2距离、余弦相似度或者评估模型,对两个向量进行相似度评分,并进行排序。
- data_manager模块:该模块主要用于管理数据库,包括向量数据库和关系型数据库,它负责数据的存储、查询、更新和删除等操作。
-
- 向量数据库(Milvus):Milvus作为一个高性能、可扩展、多功能的向量数据库,适用于多种需要向量检索的应用场景。
- 关系型数据库(OceanBase):我们采用蚂蚁的OceanBase数据库,存储用户query、LLM相应、模型版本等信息。
3.1.3 功能对比
功能方面,为了解决huggingface网络问题并提升推理速度,增加了embedding本地推理能力。鉴于SqlAlchemy框架存在一些限制,我们对关系数据库交互模块进行了重写,以更灵活地实现数据库操作。在实践中,大型模型产品需要与多个用户和多个模型对接,因此在ModelCache中增加了对多租户的支持,同时也初步兼容了系统指令和多轮会话。更详细的功能对比请参见表1。
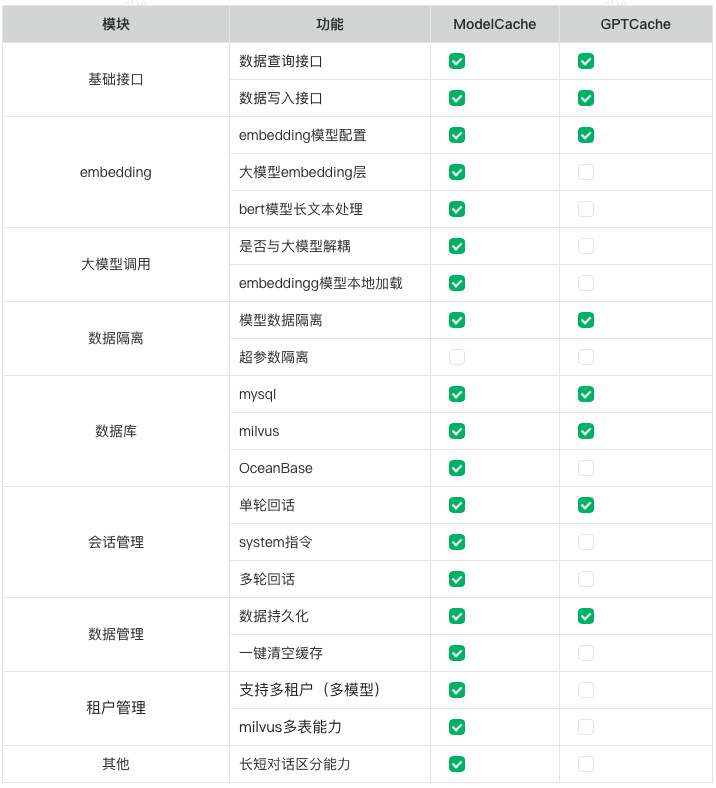
表1. ModelCache与GPTCache功能点对比
3.2 功能升级
为了将Cache产品应用于企业级用户,并实现真正的落地效果,我们对其功能进行了大量迭代升级,核心功能如图3所示。
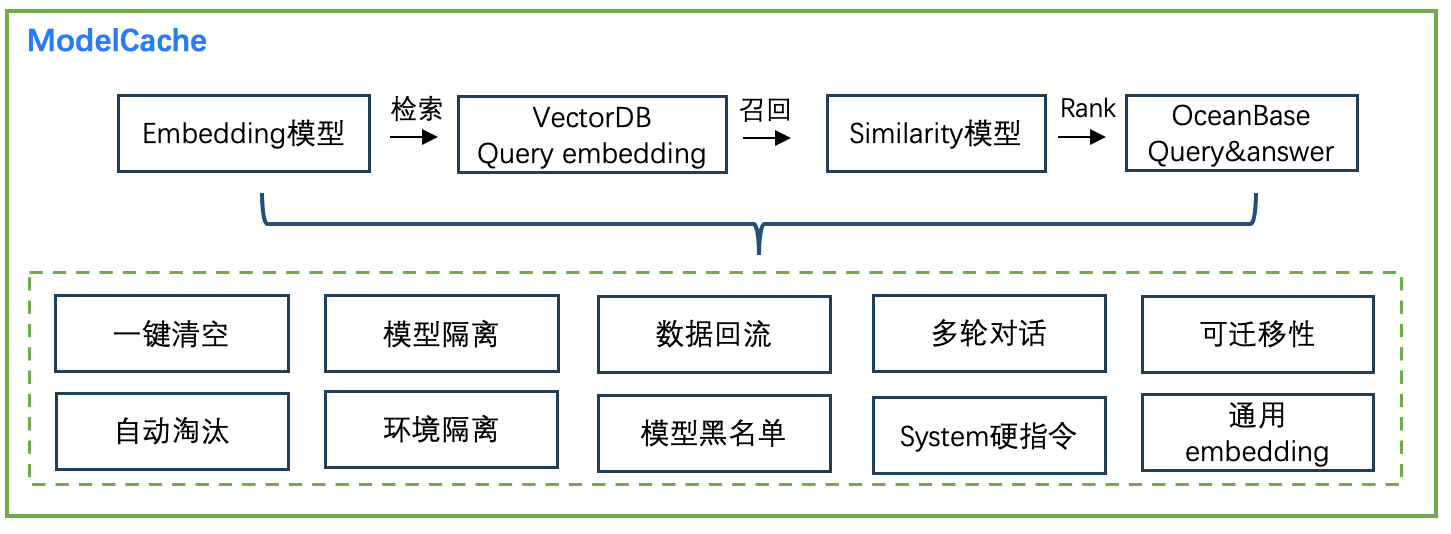
图3. ModelCache核心功能
3.2.1 数据管理
Cache需要确保过时或不必要的数据不会在缓存中累积,缓存管理是Cache中关键的一环,为此,我们实现了两个重要的功能:
- 一键清空能力:ModelCache中提供了数据移除接口,使用户能够一键清空其缓存。这项功能确保当模型版本或者参数发生变更时,前期版本的数据不会对线上的回答造成干扰。
- 缓存淘汰策略:ModelCache支持可定制化的缓存淘汰策略,使用户能够根据自身需求来定制缓存。
3.2.2 数据隔离
在实际应用中,数据隔离是一个重要的功能,为了满足不同场景的需求,ModelCache实现了多种数据隔离功能,包括:
- 环境隔离: 支持在不同环境中进行数据隔离,包括DEV、预发和线上环境。这些环境可能存在模型版本和参数上的差异,因此确保了数据在不同环境中的独立性。
- 模型隔离: 支持模型级别的隔离,使用向量数据库表和OB表字段实现独立存储。通过这种方式,不同模型之间的数据可以得到有效的隔离,确保数据的安全性和完整性。
3.2.3 数据回流
数据回流功能具有知识持久化的能力,能够确保系统重要数据得到有效地保存和持续使用,从而支持系统的长期发展。为此,Cache中提供了数据回流功能,使得系统中的数据能够得到有效的持久化,这项功能采用异步方式进行,尽可能减少对系统性能的影响。
3.2.4 system指令及多轮对话支持
在ModelCache中,提供了system指令和多轮对话支持,以满足用户的需求。具体如下:
- system指令支持: ModelCache中支持system指令,尤其是后续用户可以自定义system指令的情况下,会区分不同system指令下对话的语义相似性,保持Cache的稳定性,未来,我们还计划将system指令与会话进行分离,以进一步提升系统的灵活性和可扩展性。
- 多轮对话能力: ModelCache还支持多轮对话,即能够匹配连续对话的语义相似性。
3.2.5 可迁移性
ModelCache具有出色的可迁移性,能够适应不同的场景,OceanBase可以无缝迁移至mysql等产品,Milvus也是一种可快速部署的数据库服务,所以无论是专有云还是公有云都能够快速应对,并提供高质量的服务。这种可迁移性意味着,ModelCache可以为用户提供更加灵活和可扩展的部署方案,以满足不同的需求和场景。
3.2.6 Embedding能力
在当前的cache中,用户可使用中文通用embedding模型(text2vec-base-chinese)。我们也支持大模型embedding层的嵌入能力,这使得embedding能够更好地适应模型本身的语义,但仅使用大模型的embedding层,演变成了词袋模型,无法获取各个token的权重。为此,我们在训练SGPT(GPT Sentence Embeddings for Semantic Search),以更好的支持ModelCache。
4 效果统计
4.1 效率统计
依据蚂蚁内部大模型产品的GOC日志信息,统计了缓存命中时长和直接调用模型时长,因为产品端采用了流式输出,时间上会有一定的增加。经过实际系统统计,命中缓存可以将平均耗时降低10倍,整体有效提速率可达14.5%。有效提速率的定义参见下面公式:

根据回流数据(排除流式输出的延迟),对缓存的耗时进行了评估,缓存未命中的耗时已经控制在数百毫秒量级,我们仍在持续进行查询耗时的优化。
4.2 embedding模型的持续优化
在缓存场景中,我们发现仅仅评估语义相似性是不够的,核心目标应该是判断query对应的大型模型输出是否一致(query的语义相似不等价于大型模型的回复一致)。例如下面的query,一词之差,但生成的结果是完全不同的
-
- query: 从1遍历到1000,找出所有能被13和23整除的数字,用Python实现
- query: 从1遍历到1000,找出所有能被13和23整除的数字,用Java实现
我们调研了SentenceTransformer领域的诸多模型,但都无法满足缓存场景的需求。因此训练了一个面向企业级应用的embedding模型,并希望在此基础上进一步提升语义相似度评估的准确性,以提高缓存的准确率。
5 未来展望
未来,我们旨在提供性能更强、精度更高的解决方案,以满足LLM Cache场景下的需求。将不断地进行研究和优化,以确保Cache系统能够在实际应用中取得最佳的性能和准确性
在性能方面,将通过深入优化各个环节,包括算法、数据和计算资源,以实现更快的召回时间,目标是将整体处理时间压缩到300毫秒以内,以提供更快捷高效的用户体验。
在精度方面,将注重语义模型的建设,通过深入研究和改进语义表示技术,致力于提升模型对复杂语义的准确理解能力,从而更精准地匹配用户的query。此外,还会对相似度评估模块进行优化,以进一步提升召回率。我们将综合考虑多种评估指标,如准确度、召回率和F1分数,以确保模型在各个方面都取得显著的提升。
想了解更多CodeFuse详情,点击进入CodeFuse官网:https://codefuse.alipay.com