入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
(2)ColumnParallelLinear(h->4h)
(4)RowParallelLinear(4h->h)+dropout
(1)ColumnParallelLinear —— h->4h+gelu激活
(2)RowParallelLinear —— 4h->h+dropout
✨下文中有关ColumnParallelLinear和RowParallelLinear的解说可以看看往期博文
一、原理
1、总体介绍
MLP是“多层感知器”,也被称为前馈神经网络或人工神经网络(ANN)
原理图如下所示:
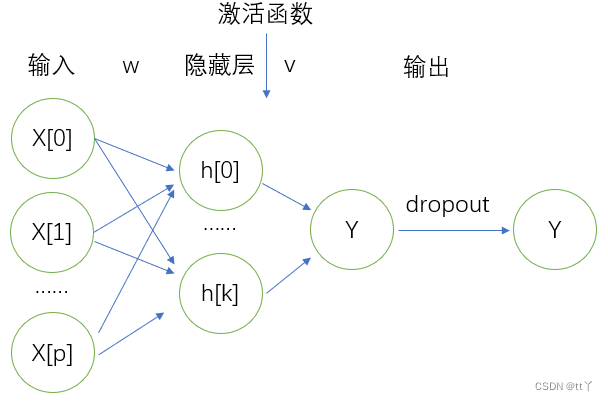
令f为激活函数,则有:
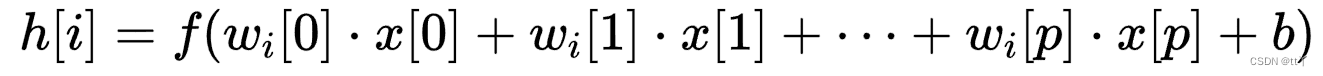
![]()
2、具体内容
(1)输入
输入的shape:(b,s,h);
补:
b——batch_size;
s——sequence length;
h——hidden_size/number of partitions;
(2)ColumnParallelLinear(h->4h)
权重矩阵W的shape:(4hp,h);
所以 X*W^T 的shape为:(b,s,4hp);
偏置矩阵B的shape:(1,4hp);(默认每一列加的偏置都一样,即类似于偏置是b个(s,4hp),并且每一个的每一行的值都一样)
最终得到的shape为:(b,s,4hp);
(3)激活函数gelu
然后通过激活函数gelu
指标准正态分布的概率函数(均值为0,方差为1)。其近似的表达式(代码采用)为:
应用优点:使激活变换就会随机依赖于输入,当输入x越小时,会有一个更高的概率被dropout掉。
(4)RowParallelLinear(4h->h)+dropout
权重矩阵V的shape:(h,4hp);
所以 X*V^T 的shape为:(b,s,h);
偏置矩阵B的shape:(1,h);(默认每一列加的偏置都一样,即类似于偏置是b个(s,h),并且每一个的每一行的值都一样)
所以最终shape为:(b,s,h);
最后再来个dropout就完成了。
二、代码解析
代码位置:model/mpu/sparse_transformer.py
1、__init__
(1)参数说明
- hidden_size:self attention的隐藏大小;
- output_dropout_prob:self attention和输出层后的输出被dropout的概率;
- init_method:权重初始化方法;
- output_layer_init_method:输出层权重的初始化方法
class GPT2ParallelMLP(torch.nn.Module):
"""MLP for GPT2.
MLP will take the input with h hidden state, project it to 4*h
hidden dimension, perform gelu transformation, and project the
state back into h hidden dimension. At the end, dropout is also
applied.
Arguments:
hidden_size: The hidden size of the self attention.
output_dropout_prob: dropout probability for the outputs
after self attention and final output.
init_method: initialization method used for the weights. Note
that all biases are initialized to zero and
layernorm weight are initialized to one.
output_layer_init_method: output layer initialization. If None,
use `init_method`.
"""
def __init__(self, hidden_size, output_dropout_prob, init_method,
output_layer_init_method=None):
super(GPT2ParallelMLP, self).__init__()(2)线性变化定义
✨h->4h
# Project to 4h.线性变换(从h变为4h)
self.dense_h_to_4h = ColumnParallelLinear(hidden_size, 4*hidden_size,
gather_output=False,
init_method=init_method)✨4h->h
# Project back to h.
self.dense_4h_to_h = RowParallelLinear(
4*hidden_size,
hidden_size,
input_is_parallel=True,
init_method=output_layer_init_method)(3)dropout定义
self.dropout = torch.nn.Dropout(output_dropout_prob)2、forward
(1)ColumnParallelLinear —— h->4h+gelu激活
def forward(self, hidden_states):
# [b, s, 4hp]
intermediate_parallel = self.dense_h_to_4h(hidden_states)
intermediate_parallel = gelu(intermediate_parallel)(2)RowParallelLinear —— 4h->h+dropout
# [b, s, h]
output = self.dense_4h_to_h(intermediate_parallel)
output = self.dropout(output)
return output补充:这里的gelu函数
@torch.jit.script
def gelu_impl(x):
"""OpenAI's gelu implementation."""
return 0.5 * x * (1.0 + torch.tanh(0.7978845608028654 * x *
(1.0 + 0.044715 * x * x)))
def gelu(x):
return gelu_impl(x)欢迎大家在评论区批评指正,谢谢~