git入门
git简介
什么是“版本控制”?我为什么要关心它呢? 版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。在CODE CHINA 中,我们对保存着软件源代码的文件作版本控制,但实际上,你可以对任何类型的文件进行版本控制。
如果你是位图形或网页设计师,可能会需要保存某一幅图片或页面布局文件的所有修订版本(这或许是你非常渴望拥有的功能),采用版本控制系统(VCS)是个明智的选择。 有了它你就可以将选定的文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因,又是谁在何时报告了某个功能缺陷等等。 使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先的样子。 但额外增加的工作量却微乎其微。
接下来,我们将要回顾版本控制系统的发展历史。
版本控制系统发展可以分为三个阶段:
- 本地版本控制系统
- 许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。 这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。
其中最流行的一种叫做 RCS,现今许多计算机系统上都还看得到它的踪影。 RCS 的工作原理是在硬盘上保存补丁集(补丁是指文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
- 许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。 这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
- 集中化的版本控制系统
- 接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作? 于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。 这类系统,诸如 CVS、Subversion 以及 Perforce 等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。多年以来,这已成为版本控制系统的标准做法。
这种做法带来了许多好处,特别是相较于老式的本地 VCS 来说。 现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。
但这么做也有一个显而易见的缺点,那就是是中央服务器的单点故障。 - 如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作 - 如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问你将丢失所有数据——包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。
本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
- 接下来人们又遇到一个问题,如何让在不同系统上的开发者协同工作? 于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。 这类系统,诸如 CVS、Subversion 以及 Perforce 等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。多年以来,这已成为版本控制系统的标准做法。
- 分布式的版本控制系统
- 于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。 在这类系统中,像 Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照, 而是把代码仓库完整地镜像下来,包括完整的历史记录。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
不仅如此,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。这样一来,你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
- 于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。 在这类系统中,像 Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照, 而是把代码仓库完整地镜像下来,包括完整的历史记录。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
Git 的诞生
接下来,让我们来看一看 Git 诞生的故事。
Git 诞生的背景
同生活中的许多伟大事物一样,Git 诞生于一个极富纷争大举创新的年代。
Linus 在1991年创建了开源的 Linux,从此,Linux 系统不断发展,已经成为最大的服务器系统软件了。在1991-2002年期间,世界各地的志愿者把源代码文件通过 diff 的方式发给 Linus,然后由 Linus 本人通过手工方式合并代码。
你也许会想,为什么 Linus 不把 Linux 代码放到版本控制系统里呢?不是有CVS、SVN这些免费的版本控制系统吗?因为Linus 坚定地反对CVS和SVN,这些集中式的版本控制系统不但速度慢,而且必须联网才能使用。有一些商用的版本控制系统,虽然比CVS、SVN好用,但那是付费的,和 Linux 的开源精神不符。
Linus 两周完成 Git
到 2002 年,Linux 系统已经发展了十年了,代码库之大让 Linus 很难继续通过手工方式管理了,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码,BitKeeper 的东家 BitMover 公司也免费授权 Linux 社区使用这个版本控制系统。后来 BitMover 公司发现社区有人试图破解 BitKeeper 的协议,于是 BitMover 公司收了回 Linux 社区的免费使用权。
这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,开发出自己的版本系统。 他们对新的系统制订了若干目标:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
- 有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
于是,Linus 花了两周时间自己用 C 写了一个分布式版本控制系统,这就是 Git!一个月之内,Linux 系统的源码已经由 Git 管理了!

Git 的发展壮大
自 2005 年诞生以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。它的速度飞快,极其适合管理大项目,有着令人难以置信的非线性分支管理系统。Git 迅速成为最流行的分布式版本控制系统,尤其是2008年,GitHub 网站上线了,它为开源项目免费提供 Git 存储,无数开源项目开始迁移至 GitHub ,包括jQuery,PHP,Ruby等等。
git安装
Git安装 在你开始使用 Git 前,需要将它安装在你的计算机上。 即便已经安装,最好将它升级到最新的版本。 你可以通过软件包或者其它安装程序来安装,或者下载源码编译安装。 下面,我们将会介绍不同操作系统上 Git 的安装方法。
在 Windows 上安装
在 Windows 上安装 Git 的方法如下:
使用官方版本安装
官方版本可以在 Git 官方网站下载。 打开 https://git-scm.com/download/win,然后选择相应的版本即可。
在 macOS 上安装
在 Mac 上安装 Git 有多种方式。
最简单的方法是安装 Xcode Command Line Tools。 Mavericks (10.9) 或更高版本的系统中,在 Terminal 里尝试首次运行 git 命令即可。 bash $ git --version 如果没有安装过命令行开发者工具,将会提示你安装。 如果你想安装更新的版本,可以使用二进制安装程序。 官方维护的 macOS Git 安装程序可以在 Git 官方网站下载,网址为 https://git-scm.com/download/mac。
在 Linux 上安装
在 Linux 上用二进制安装程序来安装基本的 Git 工具,可以使用发行版包含的基础软件包管理工具来安装。 以 Fedora 为例,如果你在使用它(或与之紧密相关的基于 RPM 的发行版,如 RHEL 或 CentOS),你可以使用 dnf: bash $ sudo dnf install git-all 如果你在基于 Debian 的发行版上,如 Ubuntu,请使用 apt: bash $ sudo apt install git-all 要了解更多选择,Git 官方网站上有在各种 Unix 发行版的系统上安装步骤,网址为 https://git-scm.com/download/linux。
Git环境配置
好了,当你当完成了 Git 的安装后,接下来我们就需要对 Git 进行一些必要的环境配置。 通常情况下,每台计算机上只需要配置一次 Git,当 Git 程序升级时会保留配置信息。 你可以在任何时候再次通过运行 git config命令来修改它们。
git config
Git 自带一个 git config 的工具来帮助设置控制 Git 外观和行为的配置变量。 接下来,我们先学习如何通过 git config 命令来配置 用户信息
配置用户名和邮件地址
安装完 Git 之后,要做的第一件事就是设置你的用户名和邮件地址。 这一点很重要,因为每一个 Git 提交都会使用这些信息,它们会写入到你的每一次提交中,不可更改:
git config --global user.name "李老师"
git config --global user.email [email protected]
再次强调,如果使用了 --global 选项,那么该命令只需要运行一次,因为之后无论你在该系统上做任何事情, Git 都会使用那些信息。
当你想针对特定项目使用不同的用户名称与邮件地址时,可以在那个项目目录下运行没有
--global选项的命令来配置。
检查配置
如果想要检查你的配置,可以使用 git config --list 命令来列出所有 Git 当时能找到的配置。
git config --list
Git 颜色配置
到目前为止,我们已经配置了 user.name 和 user.email ,实际上,Git 还有很多可配置项。 比如,让 Git 显示颜色,会让命令输出看起来更醒目:
git config --global color.ui true
Git 显示颜色
这样,Git 会适当地显示不同的颜色,比如使用git status命令后文件名就会标上颜色。
Git忽略文件配置
有些时候,你必须把某些文件放到 Git 工作目录中,但又不能提交它们,比如保存了数据库密码的配置文件等等,每次git status都会显示Untracked files ...,这种情况下,就可以实用忽略特殊文件 .gitignore 来很方便的解决这个问题。 首先我们在 Git 工作区的根目录下创建一个特殊的 .gitignore文件,然后把要忽略的文件名填进去,Git 在每次进行提交的时候就会自动忽略这些文件。
忽略文件的规则
日常使用中,我们一般不需要从头开始编辑.gitignore文件,已经有各种现成的种配置文件,只需要组合一下就可以使用了。所有配置文件可以直接在线浏览:https://codechina.csdn.net/codechina/gitignore
忽略文件的原则是:
- 忽略操作系统自动生成的文件,比如缩略图等;
- 忽略编译生成的中间文件、可执行文件等,也就是如果一个文件是通过另一个文件自动生成的,那自动生成的文件就没必要放进版本库,比如Java编译产生的.class文件;
- 忽略你自己的带有敏感信息的配置文件,比如存放口令的配置文件。
强制添加被忽略文件
git add App.class
The following paths are ignored by one of your .gitignore files: App.class Use -f if you really want to add them.
如果你确实想添加该文件,可以用-f强制添加到 Git:
git add -f App.class
或者你发现,可能是.gitignore写得有问题,需要找出来到底哪个规则写错了,可以用git check-ignore命令检查:
检查忽略规则
git check-ignore -v App.class
.gitignore:3:*.class App.class
Git会告诉我们,.gitignore的第3行规则忽略了该文件,于是我们就可以知道应该修订哪个规则。
还有些时候,当我们编写了规则排除了部分文件时:
bash # 排除所有.开头的隐藏文件: .* # 排除所有.class文件: *.class
但是我们发现.*这个规则把.gitignore也排除了,并且App.class需要被添加到版本库,但是被*.class规则排除了。
添加例外规则
这个时候,虽然可以用git add -f强制添加进去,但我们建议你可以添加两条例外规则:
bash # 排除所有.开头的隐藏文件: .* # 排除所有.class文件: *.class # 不排除.gitignore和App.class: !.gitignore !App.class 把指定文件排除在.gitignore规则外的写法就是!+文件名,所以,只需把例外文件添加进去即可。
配置 git log -1
配置一个git last,让其显示最后一次提交信息:
git config --global alias.last 'log -1'
这样,用git last就能显示最近一次的提交:
git last
commit 4aac6c7ee018f24d2dabfd01a1e09c77612e1a4e (HEAD -> master)
Author: Miykael_xxm
Date: Tue Nov 17 11:14:15 2020 +0800
branch test
配置 git lg
git config --global alias.lg "log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit"
以上这些就是 git 常用的一些配置了。
Git 配置文件
这些自定义的Git配置文件通常都存放在仓库的.git/config文件中:
全局配置文件
cat .git/config
别名就在[alias]后面,要删除别名,直接把对应的行删掉即可。 而当前用户的 Git 配置文件放在用户主目录下的一个隐藏文件.gitconfig中:
git使用
创建目录
初始化仓库
git init
瞬间 Git 就把仓库建好了,而且告诉你是一个空的仓库(empty Git repository),同时在当前目录下多了一个.git的目录,这个目录是 Git 来跟踪管理版本库的,如果你没有看到 .git 目录,那是因为这个目录默认是隐藏的,用ls -ah命令就可以看到了。
克隆现有的仓库
git clone <url>
自定义本地仓库名称
当然如果你想在克隆远程仓库的时候,自定义本地仓库的名字也是可以的,你可以通过额外的参数指定新的目录名:
git clone https://codechina.csdn.net/codechina/help-docs mydocs
这会执行与上一条命令相同的操作,但目标目录名变为了 mydocs。
Git 支持多种数据传输协议。 上面的例子使用的是 https:// 协议,不过你也可以使用 git:// 协议或者使用 SSH 传输协议,比如 user@server:path/to/repo.git 。
编辑并添加文件
接下来,我们来尝试在已经准备好的 Git 仓库中编辑一个readme.txt文件,内容如下:
bash Git is a version control system. Git is free software.
接下来,我们可以通过2个命令将刚创建好的readme.txt添加到Git仓库:
第一步,用命令git add告诉 Git,把文件添加到仓库:
git add readme.txt
执行上面的命令,没有任何显示,说明添加成功。
提交变动到仓库
第二步,用命令git commit告诉 Git,把文件提交到仓库:
git commit -m "wrote a readme file"
[main aac23f0] wrote a readme file
1 file changed, 1 insertion(+)
create mode 100644 readme.txt
这里简单解释一下git commit命令,-m后面输入的是本次提交的说明,可以输入任意内容,当然最好是有意义的,这样你就能从历史记录里方便地找到改动记录。
git commit命令执行成功后会告诉你:
1 file changed:1个文件被改动(我们新添加的readme.txt文件)
1 insertions:插入了一行内容(readme.txt有一行内容)
为什么 Git 添加文件需要add,commit一共两步呢?因为commit可以一次提交很多文件,所以你可以多次add不同的文件,比如:
git add file1.txt $ git add file2.txt file3.txt
git commit -m "add 3 files."
查看Git仓库当前状态变化
我们已经成功地添加并提交了一个readme.txt文件,接下来让我们继续修改readme.txt文件,改成如下内容:
bash Git is a distributed version control system. Git is free software.
现在,运行git status命令看看结果:
git status
On branch master Changes not staged for commit: (use "git add ..." to update what will be
committed) (use "git checkout -- ..." to discard changes in working directory)
modified: readme.txt
no changes added to commit (use "git add" and/or "git commit -a")
注意,git restore和git checkout具有相同的效果,现在最新的使用的是git restore
git status命令可以让我们时刻掌握仓库当前的状态,上面的命令输出告诉我们,readme.txt被修改过了,但还没有准备提交的修改。

比较变动
虽然 Git 告诉我们readme.txt被修改了,但并没有告诉我们具体修改的内容是什么,假如刚好是上周修改的,等到周一来班时,已经记不清上次怎么修改的readme.txt,这个时候我们就需要用git diff这个命令查看相较于上一次暂存都修改了些什么内容了:
运行 git diff 命令
git diff readme.txt

git diff顾名思义就是查看 difference,显示的格式正是 Unix 通用的 diff 格式,可以从上面的输出看到,我们在第一行添加了一个distributed单词。
综合操作
知道了对readme.txt作了什么修改后,再把它提交到仓库就放心多了,提交修改和提交新文件是一样的两步,第一步是git add:
git add readme.txt
同样没有任何输出。在执行第二步git commit之前,我们再运行git status看看当前仓库的状态:
git status
On branch master Changes to be committed: (use "git reset HEAD ..." to unstage)
modified: readme.txt
git status告诉我们,将要被提交的修改包括readme.txt,下一步,就可以放心地提交了:
git commit -m "add distributed"
[master e55063a] add distributed 1 file changed, 1 insertion(+), 1 deletion(-)
提交后,我们再用git status命令看看仓库的当前状态:
git status

Git告诉我们当前没有需要提交的修改,而且,工作目录是干净(working tree clean)的。
查看日志
如果嫌输出信息太多,看得眼花缭乱的,可以试试加上–pretty=oneline参数:
git log --pretty=oneline
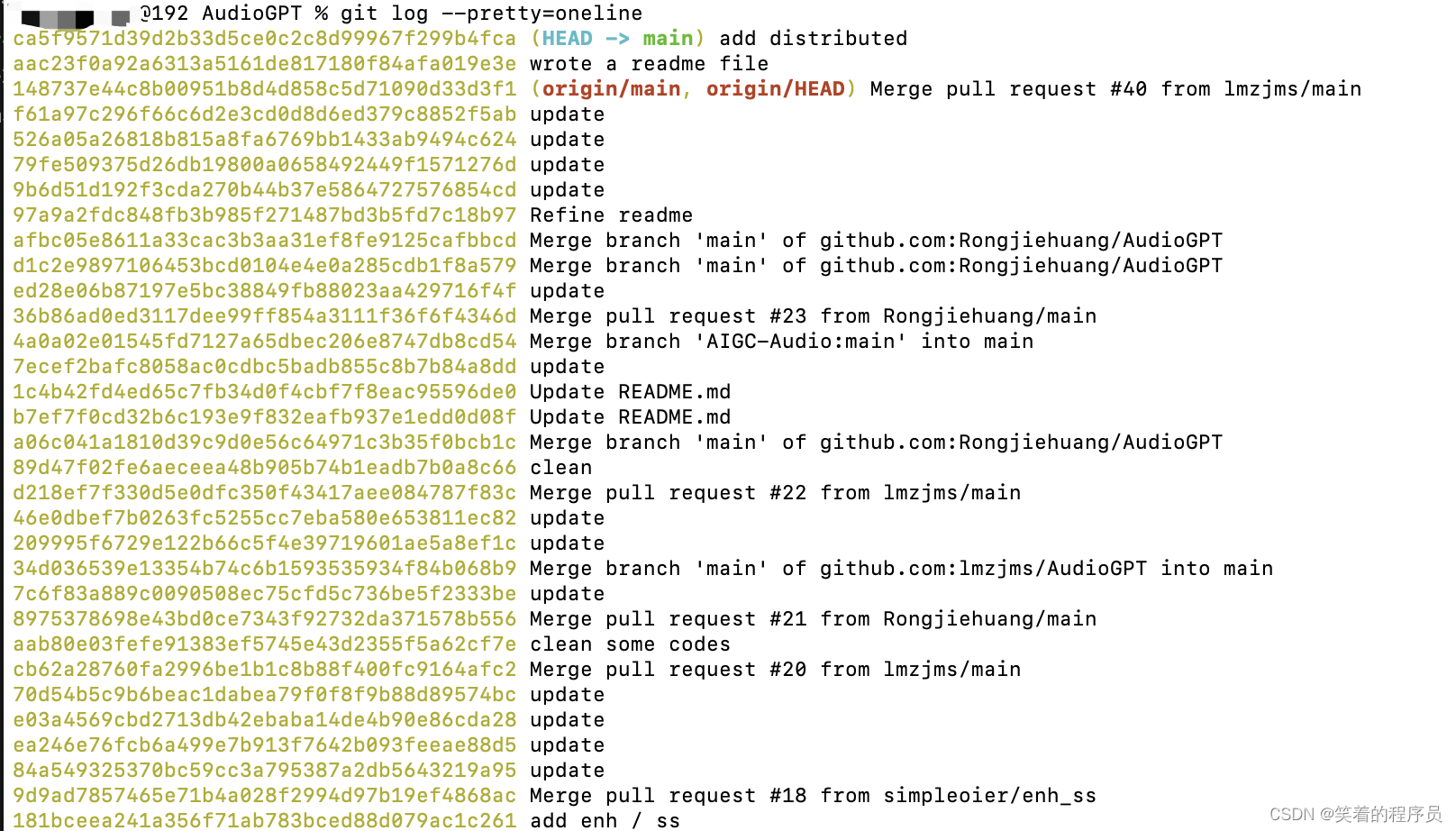
每提交一个新版本,实际上 Git 就会把它们自动串成一条时间线。如果使用可视化工具或者之前在 git 自定义配置中介绍的 git lg命令,就可以更清楚地看到提交历史的时间线:
git lg
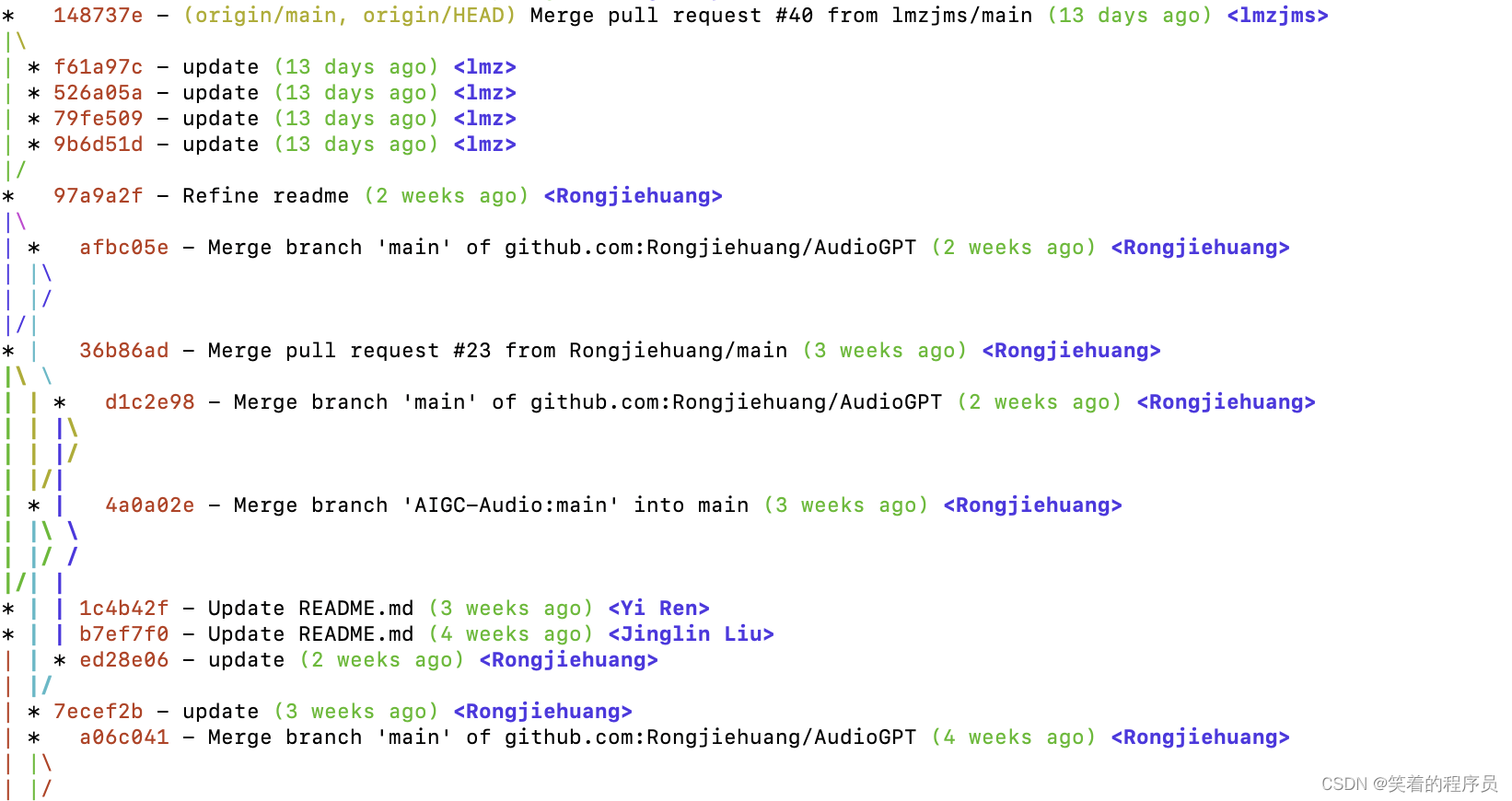
作为一个优秀的版本控制系统,Git 能够让我们查看每一次提交的记录。在日常的工作中,我们可以随时对 Git 仓库中的内容进行修改,每当你觉得文件修改到一定程度的时候,就可以“保存一个快照”,这个快照在 Git中 被称为commit / 提交。一旦你把文件改乱了,或者误删了文件,还可以从最近的一个commit恢复,然后继续工作,而不是把几个月的工作成果全部丢失。
git log
在 Git 中,我们可以通过git log命令查看全部的commit记录:
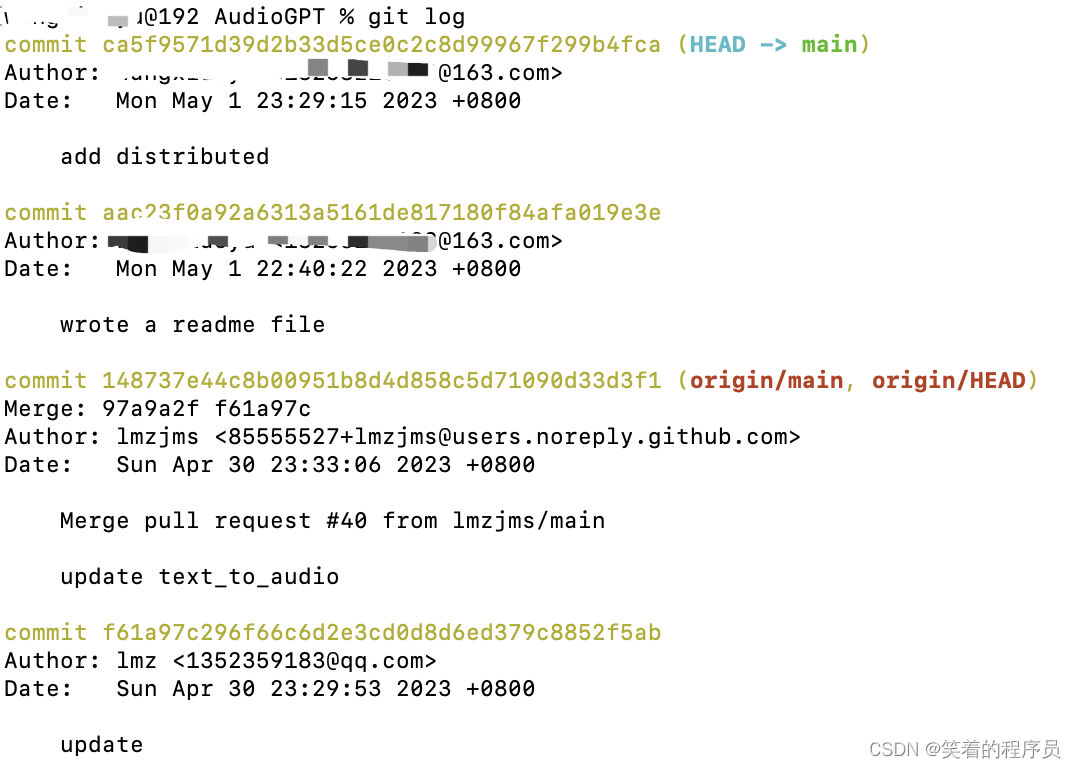
git log命令显示从最近到最远的提交日志,我们可以看到2次提交,最近的一次是add distributed,最早的一次是wrote a readme file。
Git 回退
这个时候,假设我们需要将 readme.txt 回退到上一个版本,也就是 wrote a readme file 的这个版本,我们需要怎么操作呢?
首先,Git 必须知道当前版本是哪个版本,在 Git 中,用HEAD表示当前版本,也就是最新的提交e55063a,上一个版本就是HEAD^,上上一个版本就是HEAD ^^,当然往上100个版本写100个 ^比较容易数不过来,所以写成HEAD~100。
现在,我们要把当前版本add distributed回退到上一个版本wrote a readme file,就可以使用git reset命令:
git reset --hard HEAD^
HEAD is now at aac23f0 wrote a readme file
现在让我们看看readme.txt的内容是不是版本wrote a readme file:
cat readme.txt
Git is a version control system. Git is free software.
果然还原到最初wrote a readme file这个版本了。
Git 的版本回退速度非常快,因为 Git 在内部有个指向当前版本的HEAD指针,当你回退版本的时候,Git 仅仅是把HEAD从指向add distributed:
HEAD 指针移动记录
┌────┐ │HEAD│ └────┘ │ └──> ○ add distributed │ ○ wrote a readme file 改为指向wrote a readme file: ┌────┐ │HEAD│ └────┘ │ │ ○ add distributed │ │ └──> ○ wrote a readme file
然后顺便把工作区的文件更新了。所以你让HEAD指向哪个版本号,你就把当前版本定位在哪。
Git重置
现在,你回退到了某个版本,关掉了电脑,第二天早上就后悔了,想恢复到新版本怎么办?找不到新版本的commit id怎么办?
好在 Git 提供了一个命令git reflog用来记录你的每一次命令,当你用git reset --hard HEAD^回退到wrote a readme file版本时,再想恢复到add distributed,就可以通过git reflog命令找到add distributed的commit id。
git reflog
aac23f0 (HEAD -> main) HEAD@{
0}: reset: moving to HEAD^
ca5f957 HEAD@{
1}: commit: add distributed
aac23f0 (HEAD -> main) HEAD@{
2}: commit: wrote a readme file
148737e (origin/main, origin/HEAD) HEAD@{
3}: clone: from https://github.com/xxxx-sky/AudioGPT
从上面的输出可以看到,add distributed的commit id是ca5f957,现在,我们就可以通过 git reset --hard ca5f957切换到最新的版本上了。
工作区和暂存区
Git 和其他版本控制系统如 SVN 的一个不同之处就是有暂存区的概念。
工作区(Working Directory)
就是你在电脑里能看到的目录,比如我的learngit文件夹就是一个工作区:
版本库(Repository)
工作区有一个隐藏目录.git,这个不算工作区,而是 Git 的版本库。
Git 的版本库里存了很多东西,其中最重要的就是称为stage(或者叫index)的暂存区,还有 Git 为我们自动创建的第一个分支master,以及指向 master 的一个指针叫HEAD。
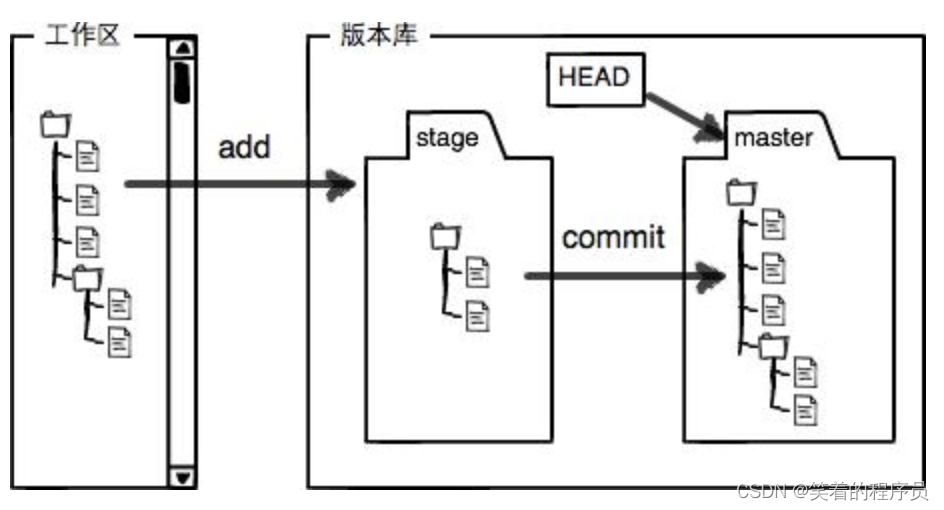
前面讲了我们把文件往 Git 版本库里添加的时候,是分两步执行的:
第一步是用git add把文件添加进去,实际上就是把文件修改添加到暂存区;
第二步是用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支。
因为我们创建 Git 版本库时,Git自动为我们创建了唯一一个master分支,所以,现在,git commit就是往 master 分支上提交更改。
你可以简单理解为,需要提交的文件修改通通放到暂存区,然后,一次性提交暂存区的所有修改。
现在,我们来试一下,先对readme.txt做个修改,比如加上一行内容:
bash Git is a distributed version control system. Git is free software distributed under the GPL. Git has a mutable index called stage.
然后,在工作区新增一个LICENSE文本文件。
先用git status查看一下状态:
git status
On branch master Changes not staged for commit: (use "git add ..." to update what will be committed) (use "git checkout -- ..." to discard changes in working directory)
modified: readme.txt
Untracked files: (use "git add ..." to include in what will be committed)
LICENSE
no changes added to commit (use "git add" and/or "git commit -a")
Git非常清楚地告诉我们,readme.txt被修改了,而LICENSE还从来没有被添加过,所以它的状态是Untracked。
现在,使用两次命令git add,把readme.txt和LICENSE都添加后,用git status再查看一下:
git status
On branch master Changes to be committed: (use "git reset HEAD ..." to unstage)
new file: LICENSE
modified: readme.txt
现在,暂存区的状态就变成这样了:
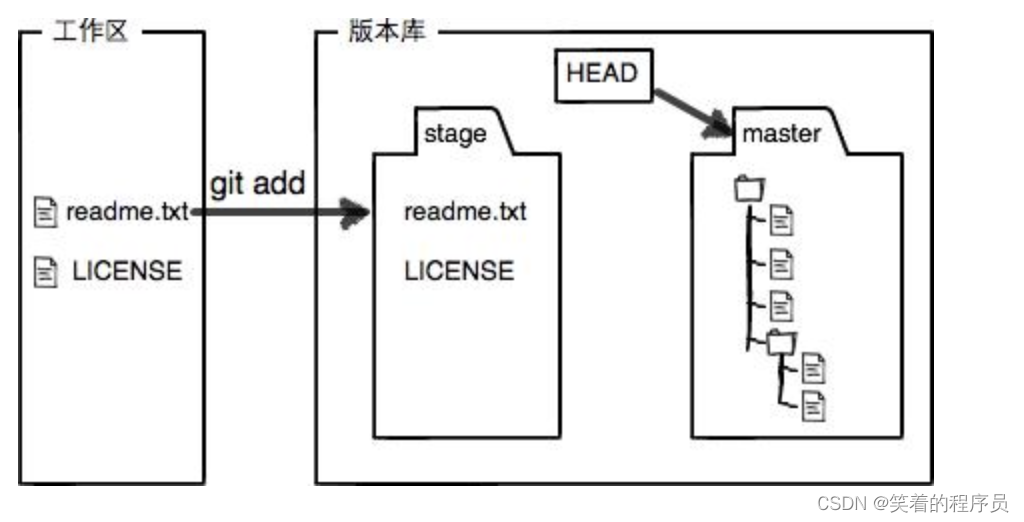
所以,git add命令实际上就是把要提交的所有修改放到暂存区(Stage),然后,执行git commit就可以一次性把暂存区的所有修改提交到分支。
git commit -m "understand how stage works"
[master 599dbdb] understand how stage works 2 files changed, 2 insertions(+) create mode 100644 LICENSE
一旦提交后,如果你又没有对工作区做任何修改,那么工作区就是“干净”的:
git status
On branch master nothing to commit, working tree clean
现在版本库变成了这样,暂存区就没有任何内容了:

撤销修改
git commit --amend
当你在修补最后的提交时,并不是通过用改进后的提交 原位替换 掉旧有提交的方式来修复的, 理解这一点非常重要。从效果上来说,就像是旧有的提交从未存在过一样,它并不会出现在仓库的历史中。
修补提交最明显的价值是可以稍微改进你最后的提交,而不会让“啊,忘了添加一个文件”或者 “小修补,修正笔误”这种提交信息弄乱你的仓库历史。
git commit -m 'initial commit'
git add forgotten_file
git commit --amend
取消暂存的文件
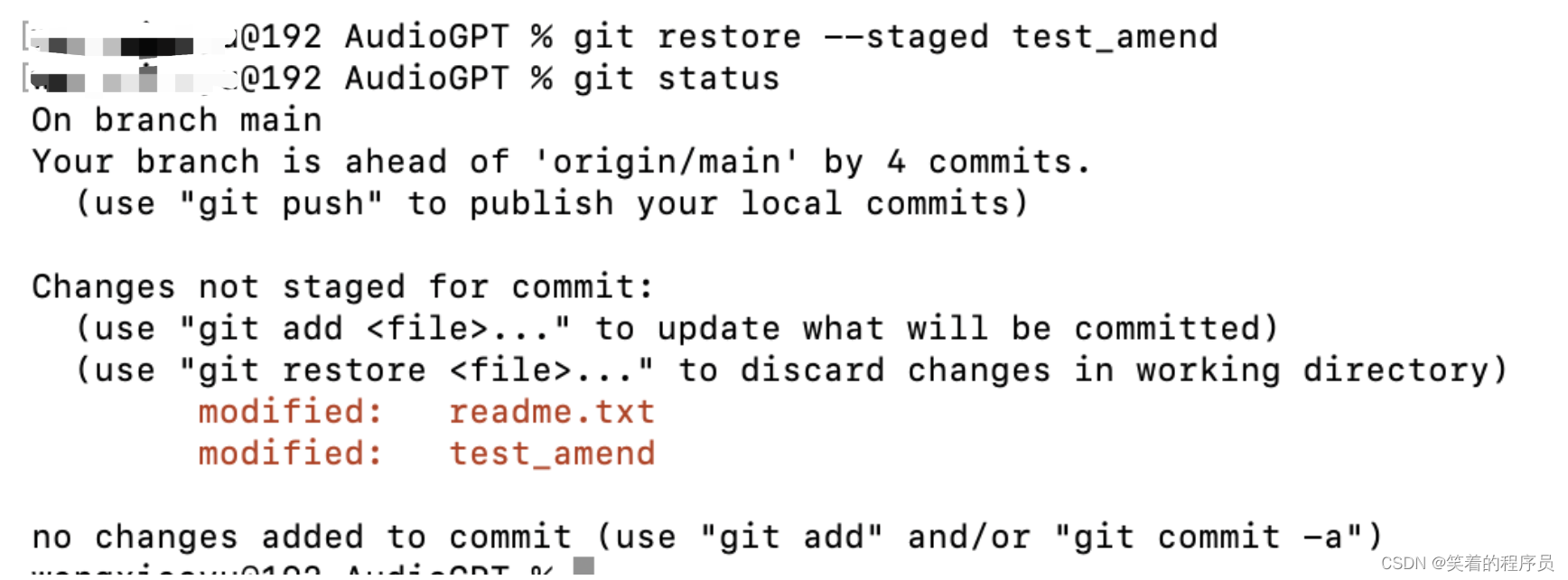
- git reset HEAD
- git restore --staged
已知有这两种方法,当前git add添加到缓存区之后提示的是第二种方法
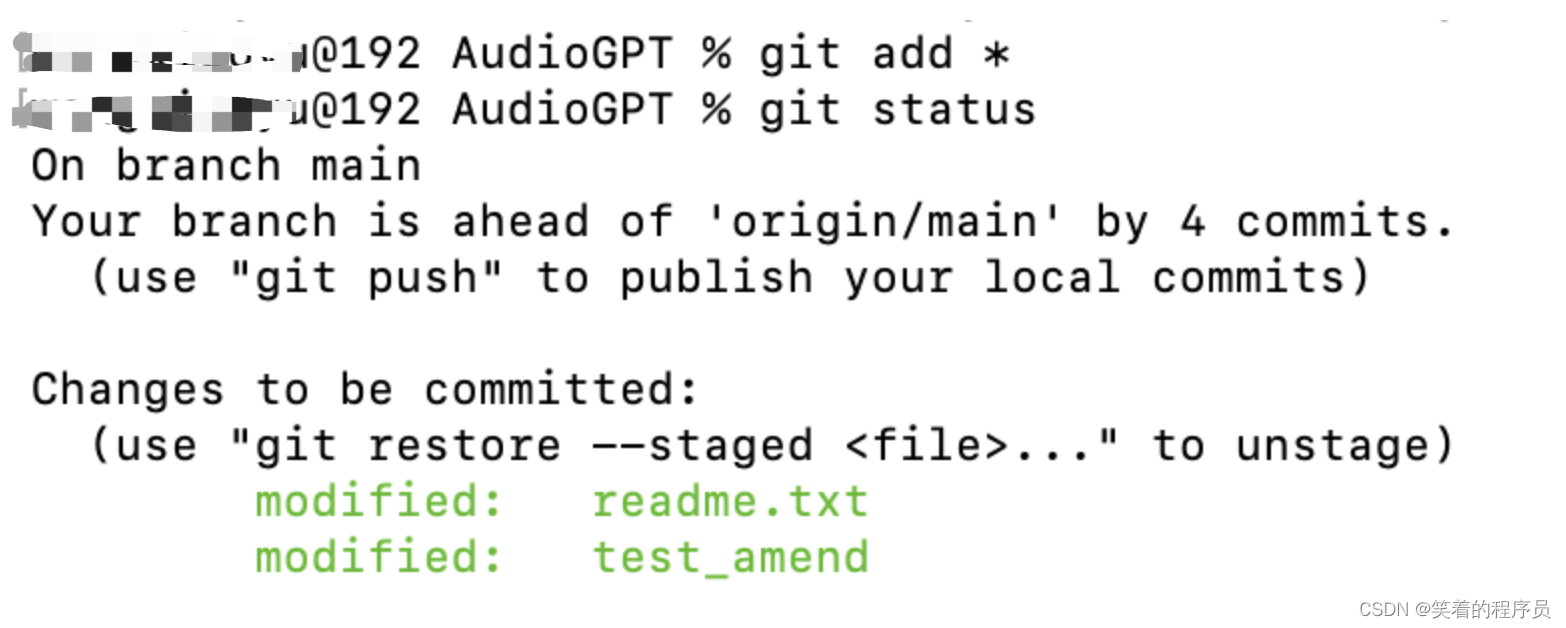
git reset方法:
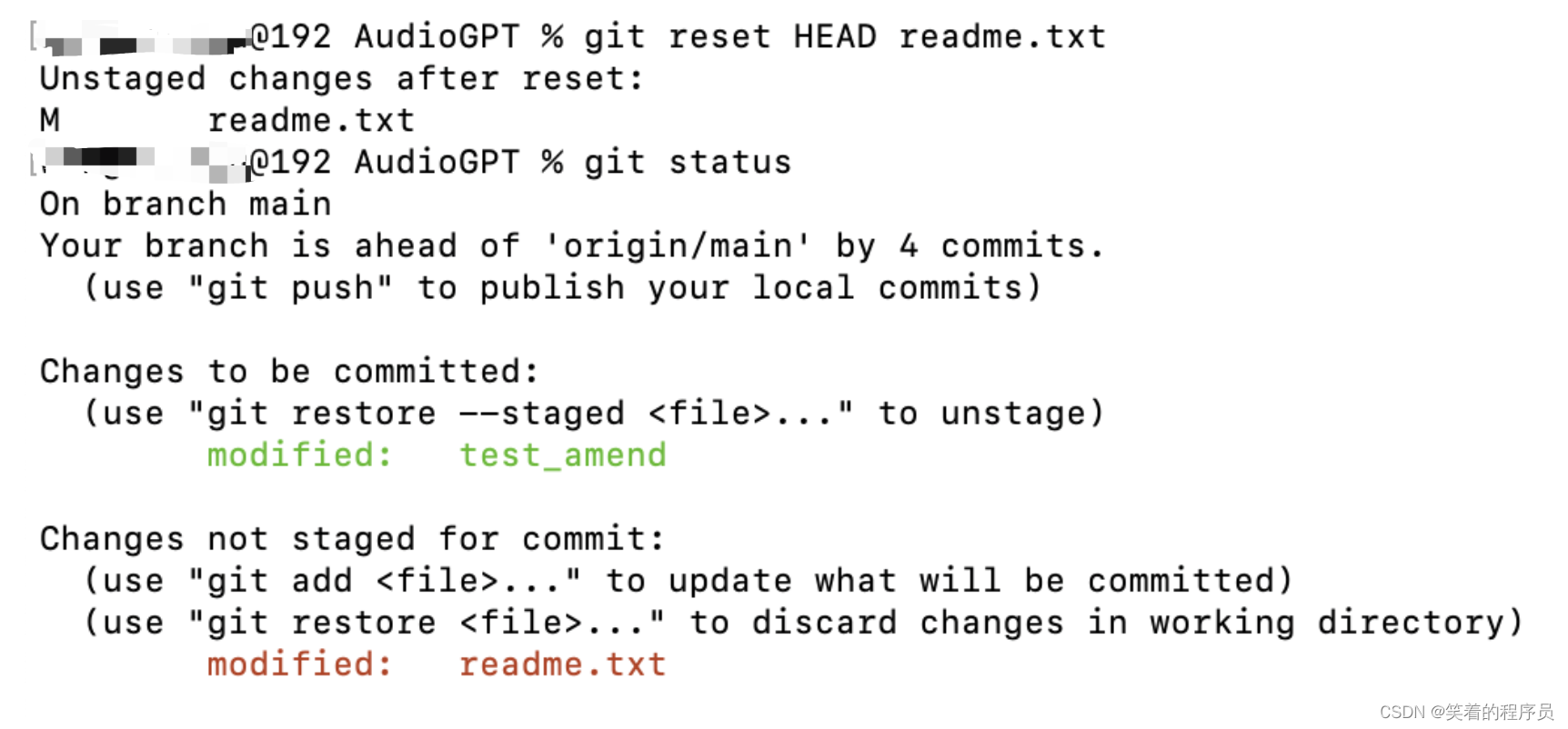
git restore方法:
撤销对文件的修改
git checkout方法:
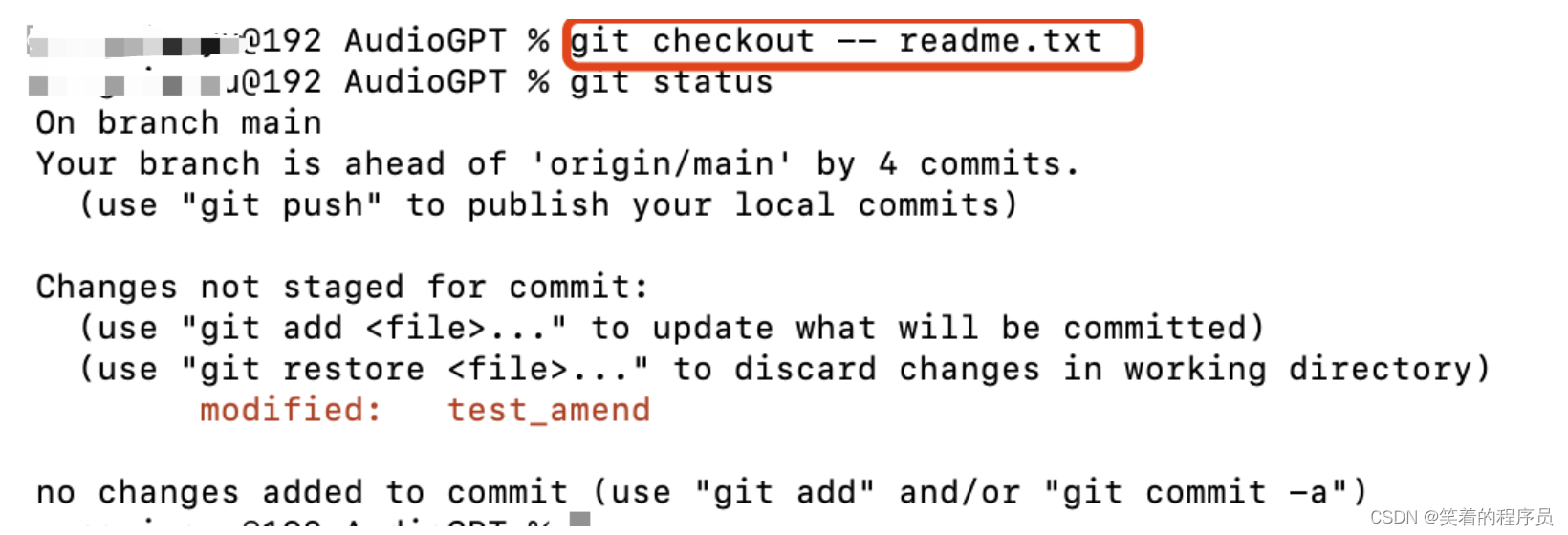
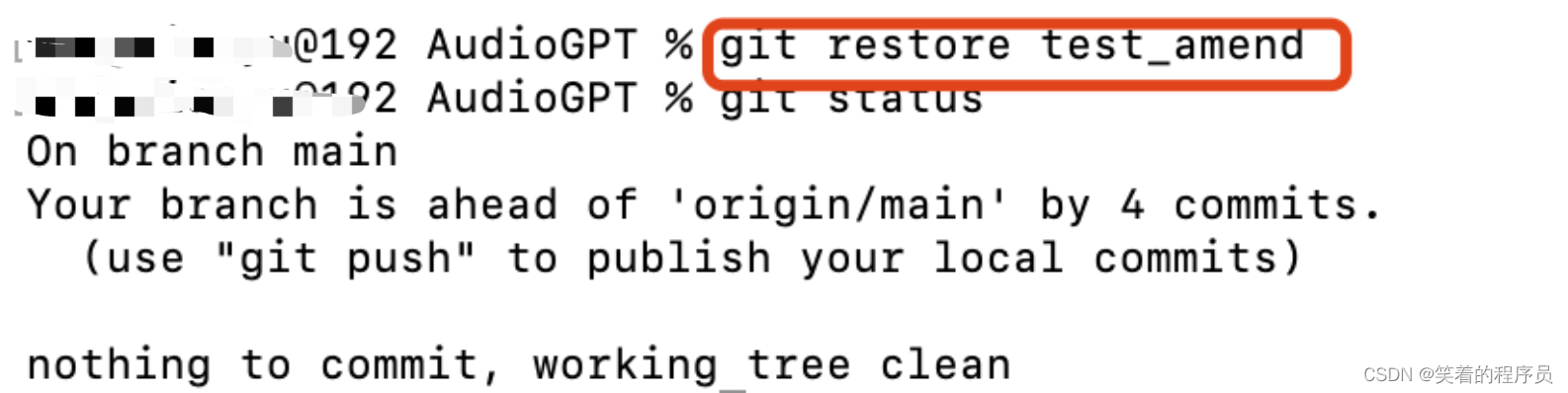
git restore方法:
删除/还原文件
本地删除文件
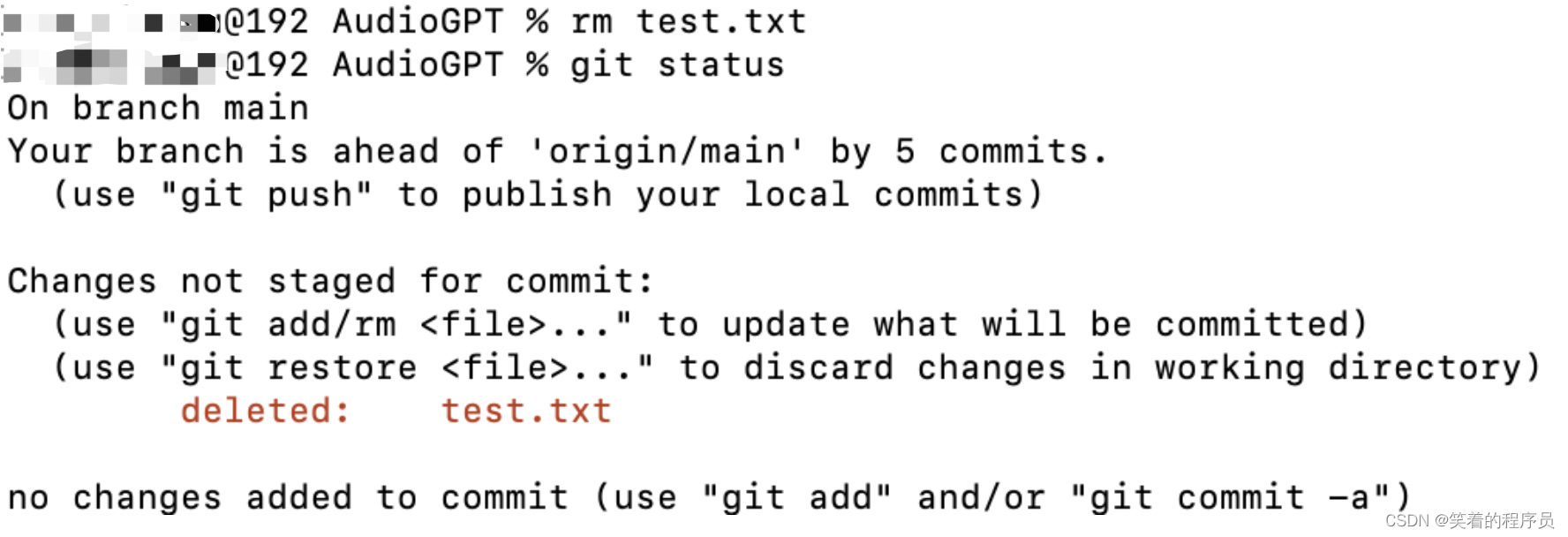
git add test.txt
git commit -m "remove test.txt"
删除文件另一种方法:
git rm
先手动删除文件,然后使用git rm 和git add效果是一样的。
还原文件(本地删除,但已经commit的文件)
git checkout --
分支管理
几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。 在很多版本控制系统中,这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。
有人把 Git 的分支模型称为它的“必杀技特性”,也正因为这一特性,使得 Git 从众多版本控制系统中脱颖而出。 为何 Git 的分支模型如此出众呢? Git 处理分支的方式可谓是难以置信的轻量,创建新分支这一操作几乎能在瞬间完成,并且在不同分支之间的切换操作也是一样便捷。 与许多其它版本控制系统不同,Git 鼓励在工作流程中频繁地使用分支与合并,哪怕一天之内进行许多次。 理解和精通这一特性,你便会意识到 Git 是如此的强大而又独特,并且从此真正改变你的开发方式。
git分支简介
为了真正理解 Git 处理分支的方式,我们需要回顾一下 Git 是如何保存数据的。
前面我们了解到,Git 保存的不是文件的变化或者差异,而是一系列不同时刻的 快照 。
在进行提交操作时,Git 会保存一个提交对象(commit object)。 知道了 Git 保存数据的方式,我们可以很自然的想到——该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。 首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象, 而由多个分支合并产生的提交对象有多个父对象,
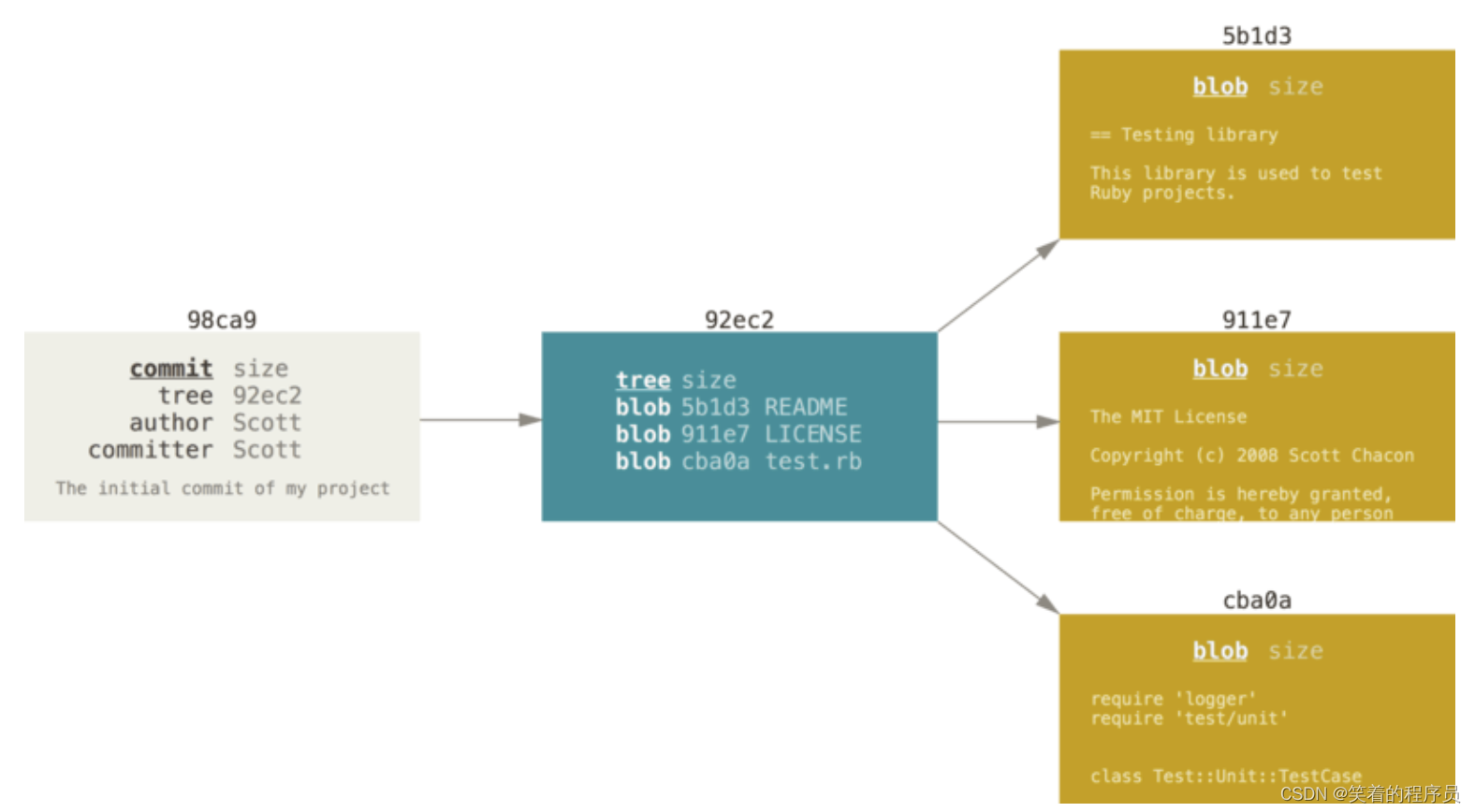
为了更加形象地说明,我们假设现在有一个工作目录,里面包含了三个将要被暂存和提交的文件。 暂存操作会为每一个文件计算校验和,然后会把当前版本的文件快照保存到 Git 仓库中 (Git 使用 blob 对象来保存它们),最终将校验和加入到暂存区域等待提交:
git add readme.txt test.md LICENSE
git commit -m 'The initial commit of my project'
当使用 git commit 进行提交操作时,Git 会先计算每一个子目录(本例中只有项目根目录)的校验和, 然后在 Git 仓库中这些校验和保存为树对象。随后,Git 便会创建一个提交对象, 它除了包含上面提到的那些信息外,还包含指向这个树对象(项目根目录)的指针。 如此一来,Git 就可以在需要的时候重现此次保存的快照。
现在,Git 仓库中有五个对象:三个 blob 对象(保存着文件快照)、一个 树 对象 (记录着目录结构和 blob 对象索引)以及一个 提交 对象(包含着指向前述树对象的指针和所有提交信息)。
做些修改后再次提交,那么这次产生的提交对象会包含一个指向上次提交对象(父对象)的指针。
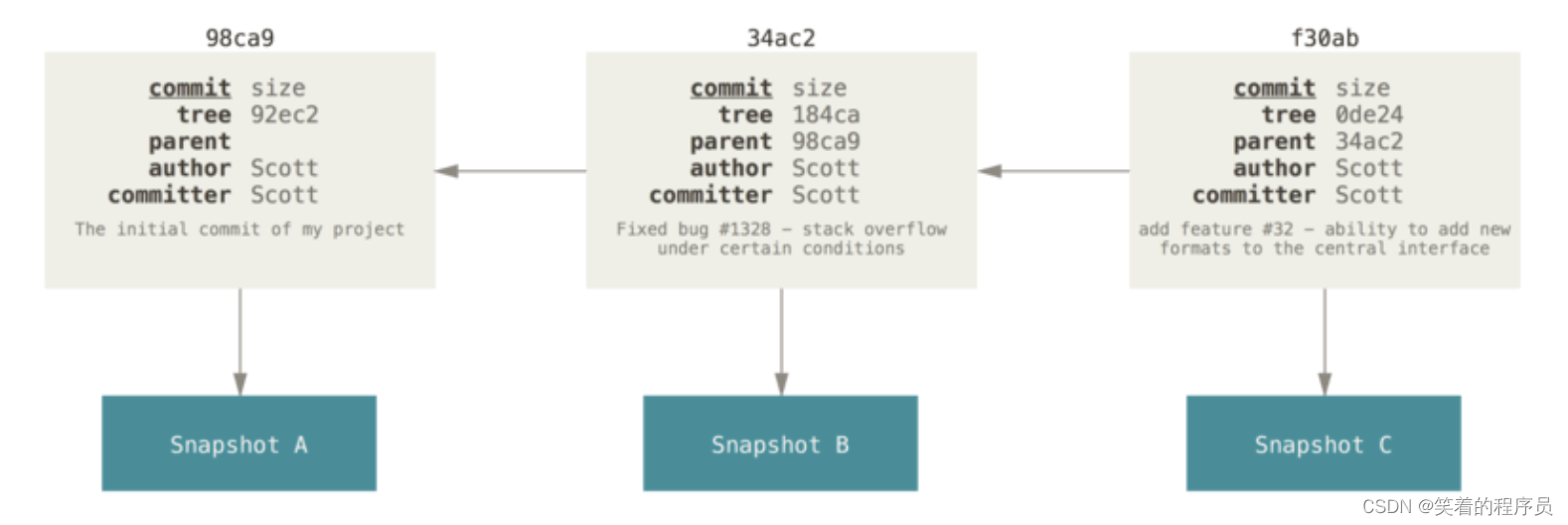
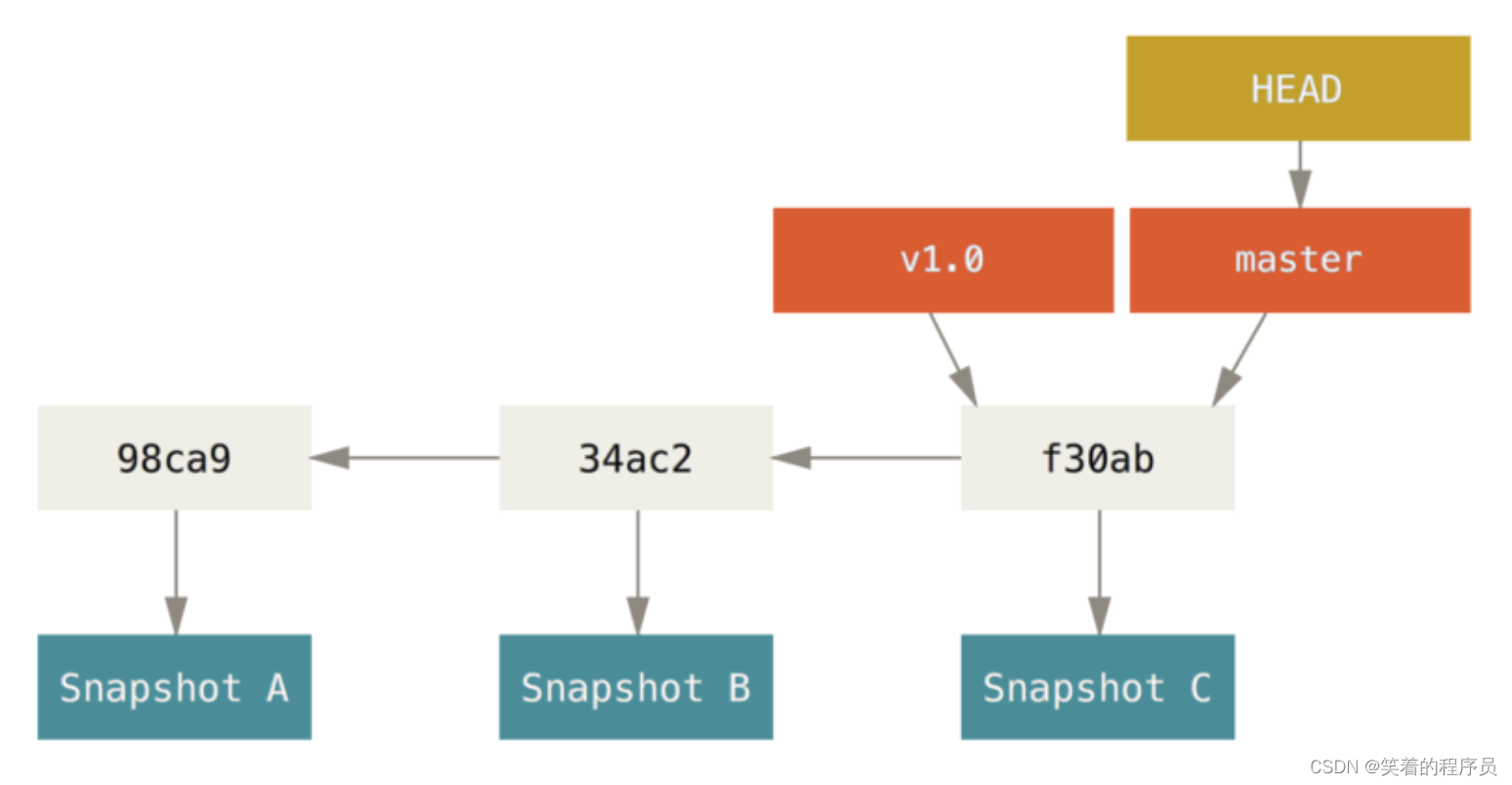
Git 的分支,其实本质上仅仅是指向提交对象的可变指针。 Git 的默认分支名字是 master。 在多次提交操作之后,你其实已经有一个指向最后那个提交对象的 master 分支。 master 分支会在每次提交时自动向前移动。
创建分支
Git 会把仓库中的每次提交串成一条时间线,这条时间线就是一个分支。在 Git 里,每个仓库都会有一个主分支,即master分支。HEAD严格来说不是指向提交,而是指向master,master才是指向提交的,所以,HEAD指向的就是当前分支。
一开始的时候,master分支是一条线,Git 用master指向最新的提交,再用HEAD指向master,就能确定当前分支,以及当前分支的提交点:
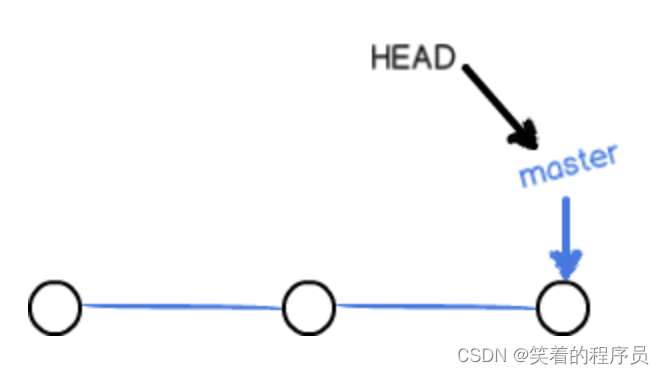
每次提交,master分支都会向前移动一步,这样,随着你不断提交,master分支的线也越来越长。
当我们创建新的分支,例如dev时,Git 新建了一个指针叫dev,指向master相同的提交,再把HEAD指向dev,就表示当前分支在dev上:
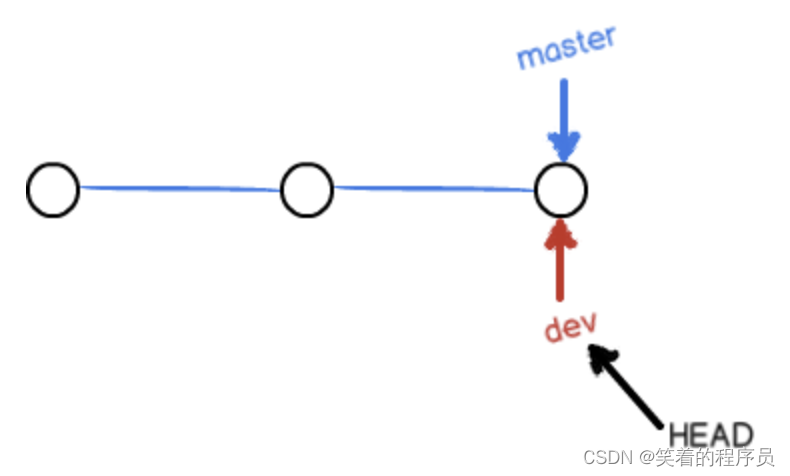
你看,Git 创建一个分支很快,因为除了增加一个dev指针,改改HEAD的指向,工作区的文件都没有任何变化!
不过,从现在开始,对工作区的修改和提交就是针对dev分支了,比如新提交一次后,dev指针往前移动一步,而master指针不变:
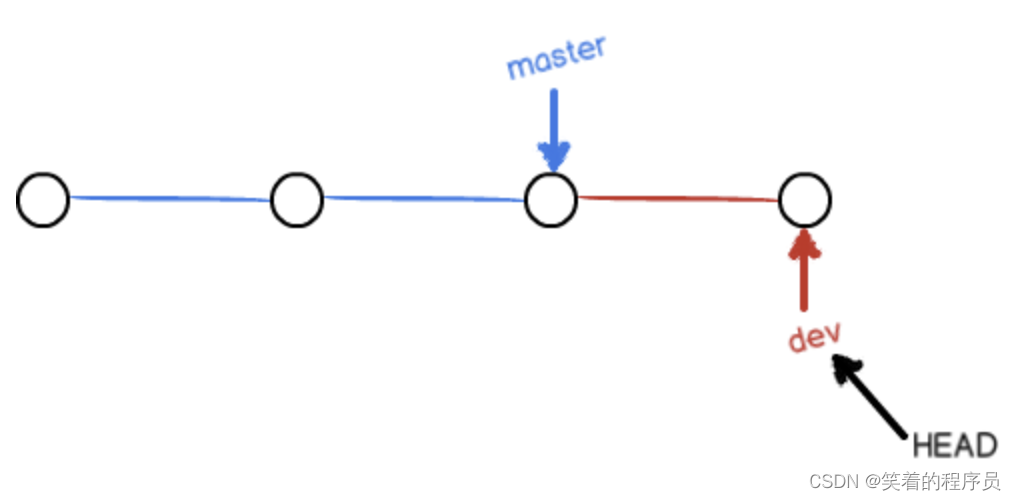
假如我们在dev上的工作完成了,就可以把dev合并到master上。Git 怎么合并呢?最简单的方法,就是直接把master指向dev的当前提交,就完成了合并:
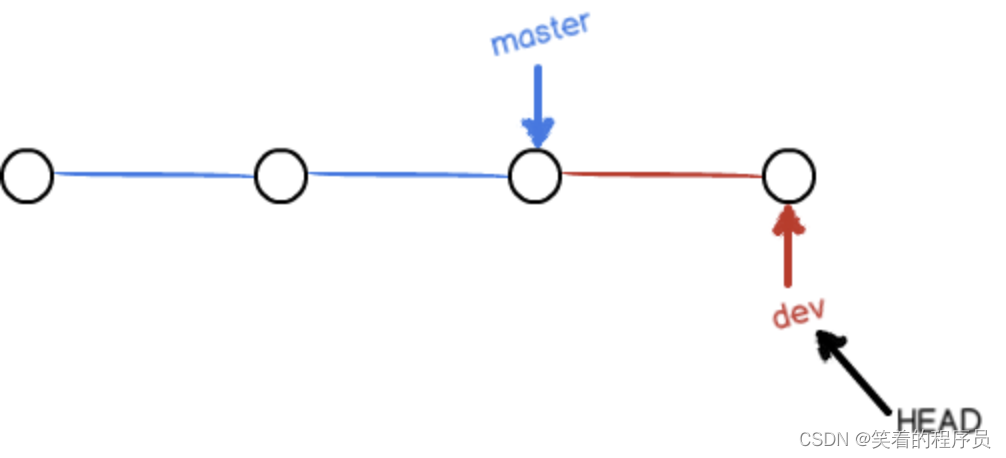
所以 Git 合并分支也很快!就改改指针,工作区内容也不变!
合并完分支后,甚至可以删除dev分支。删除dev分支就是把dev指针给删掉,删掉后,我们就剩下了一条master分支:
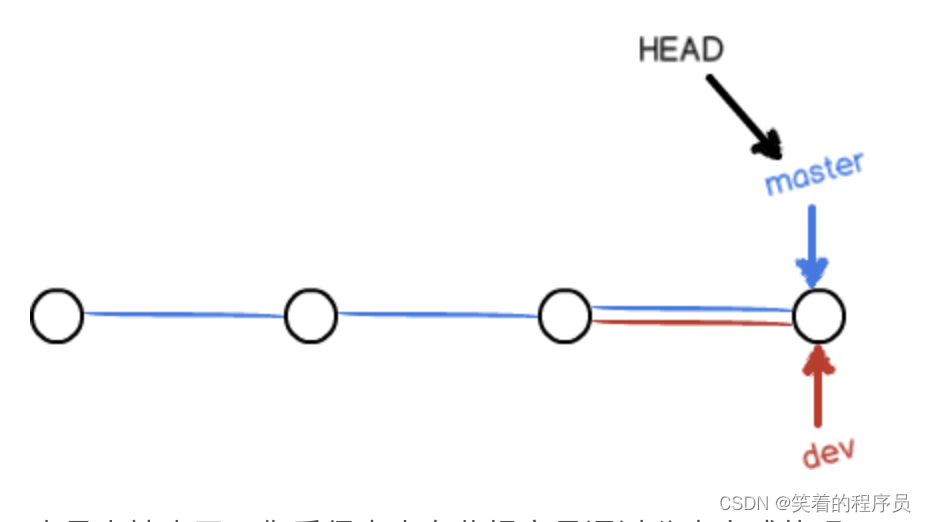
真是太神奇了,你看得出来有些提交是通过分支完成的吗?
下面开始实战。
创建分支:
git branch 分支名
创建并切换到分支:
git checkout -b 分支名
git switch -c 分支名
切换分支:
git checkout 分支名
git switch 分支名
查询分支:
git branch
合并分支
git merge 分支名
git merge命令用于合并指定分支到当前分支。
git merge dev
合并dev分支到main之后,在main分支可以看到之前在dev中增加的内容。
删除分支:
git branch -d 分支名
分支管理策略
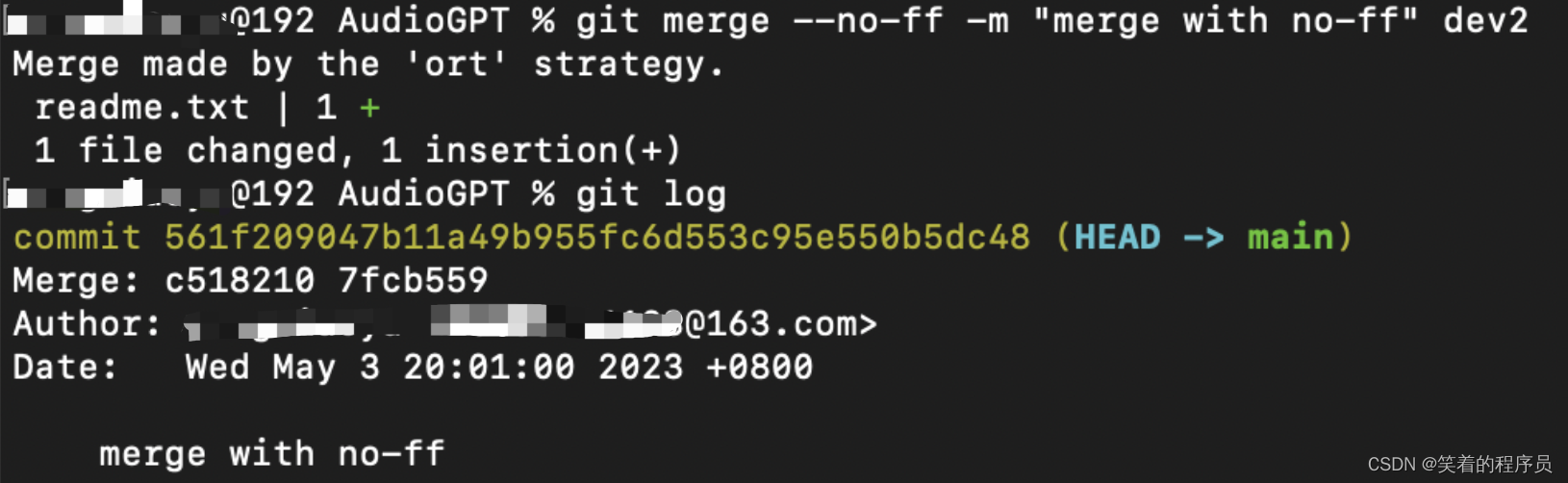
通常,合并分支时,如果可能,Git会用Fast forward模式,但这种模式下,删除分支后,会丢掉分支信息。
如果要强制禁用Fast forward模式,Git 就会在merge时生成一个新的commit,这样,从分支历史上就可以看出分支信息。
强制禁用Fast forward
--no--ff
git merge --no-ff -m "merge with no-ff" dev
使用此模式git log能看到分支合并信息,否则的话就看不到
bug分支
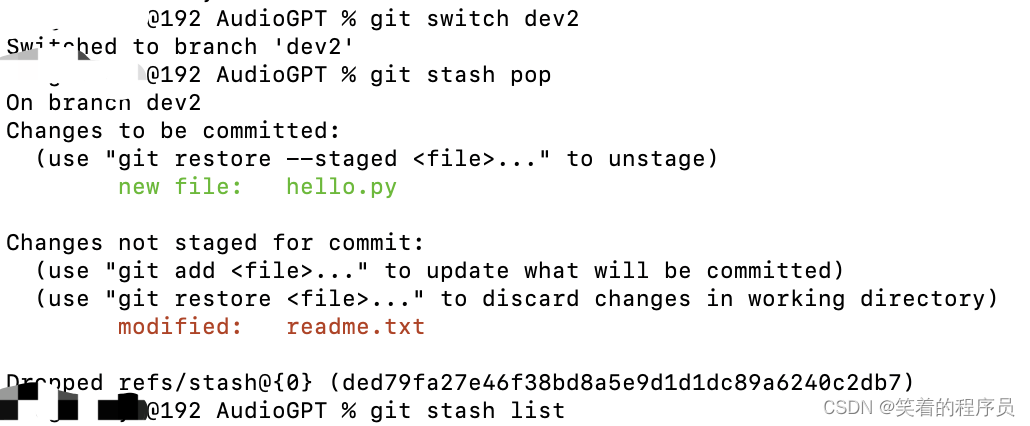
git还提供了一个stash功能,可以把当前工作现场“储藏”起来,等以后恢复现场后继续工作:
git stash
不能处理untracked的对象
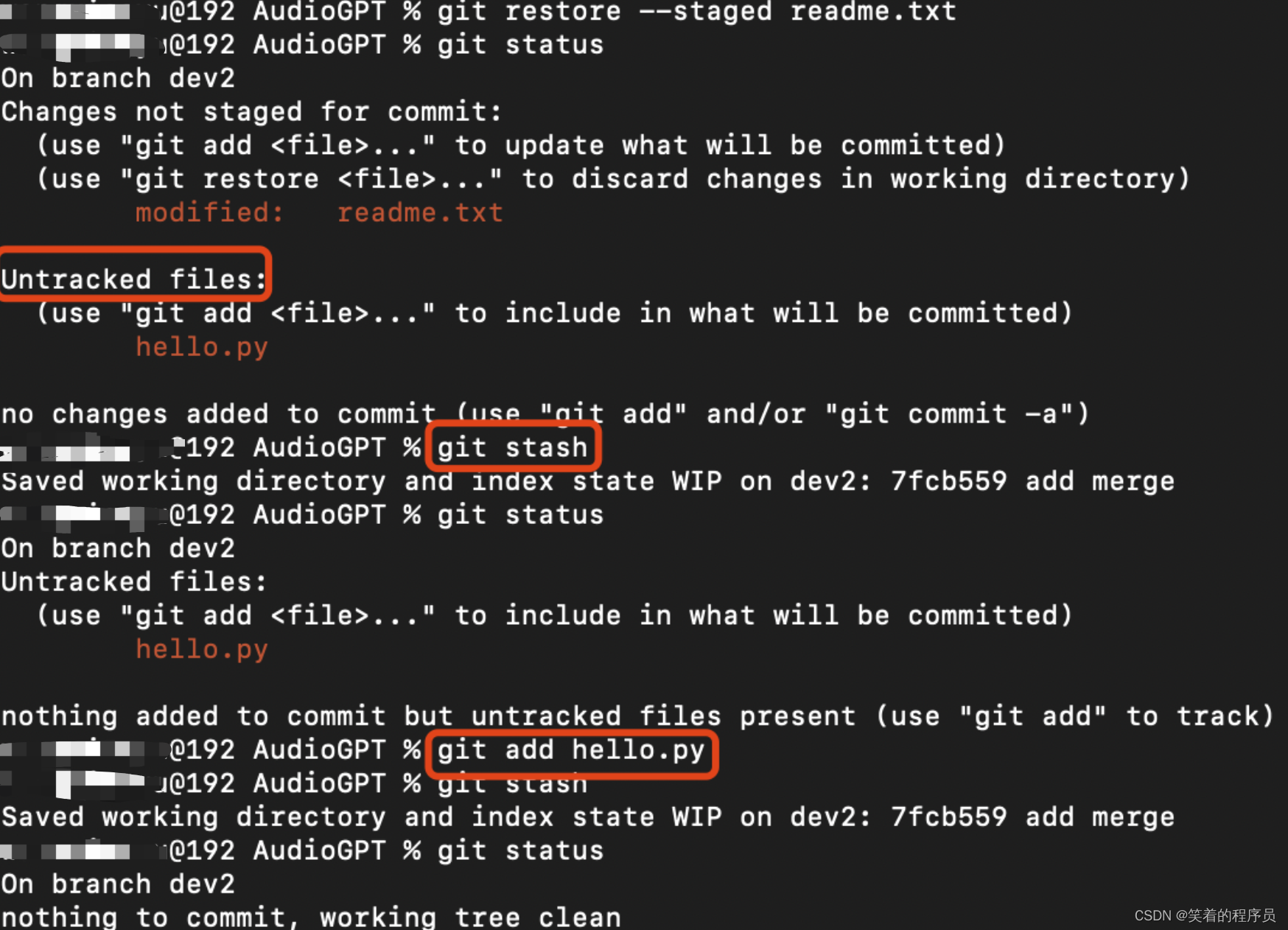
恰好上面的场景,造成了2个stash
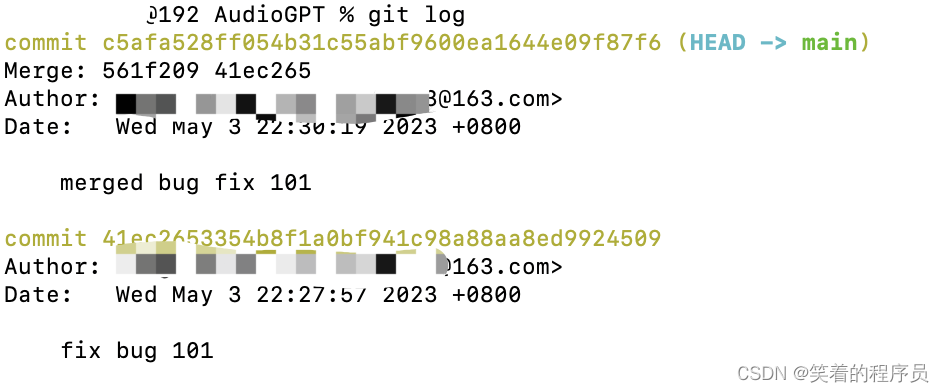
创建issue-101分支,修复bug后删除分支
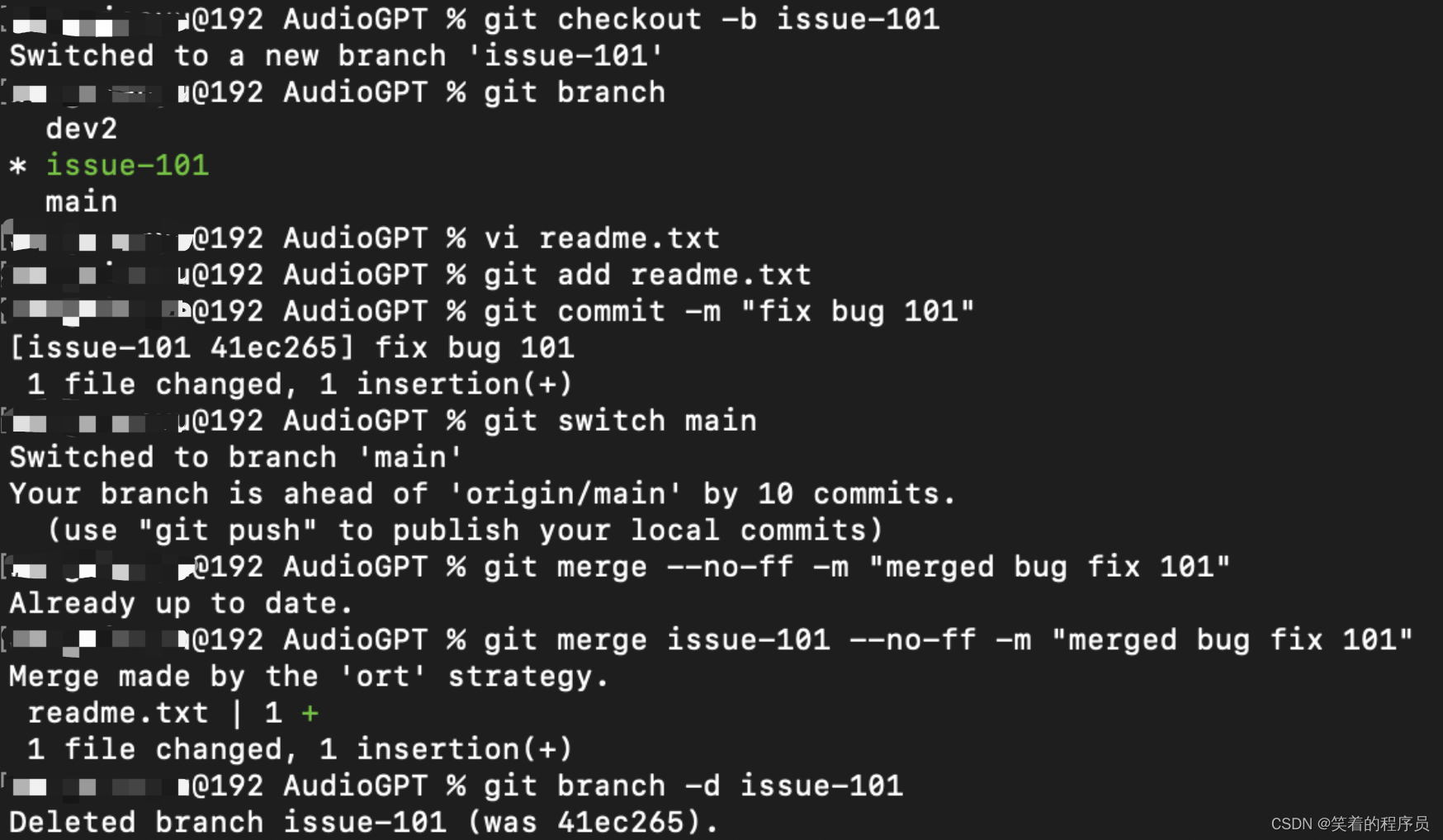
回到工作分支,恢复现场,如果使用
git stash apply stash@{0}命令的话,需要配合使用
git stash drop删除stash内容,或者直接使用git stash pop,恢复的同时也能把stash的内容删除。
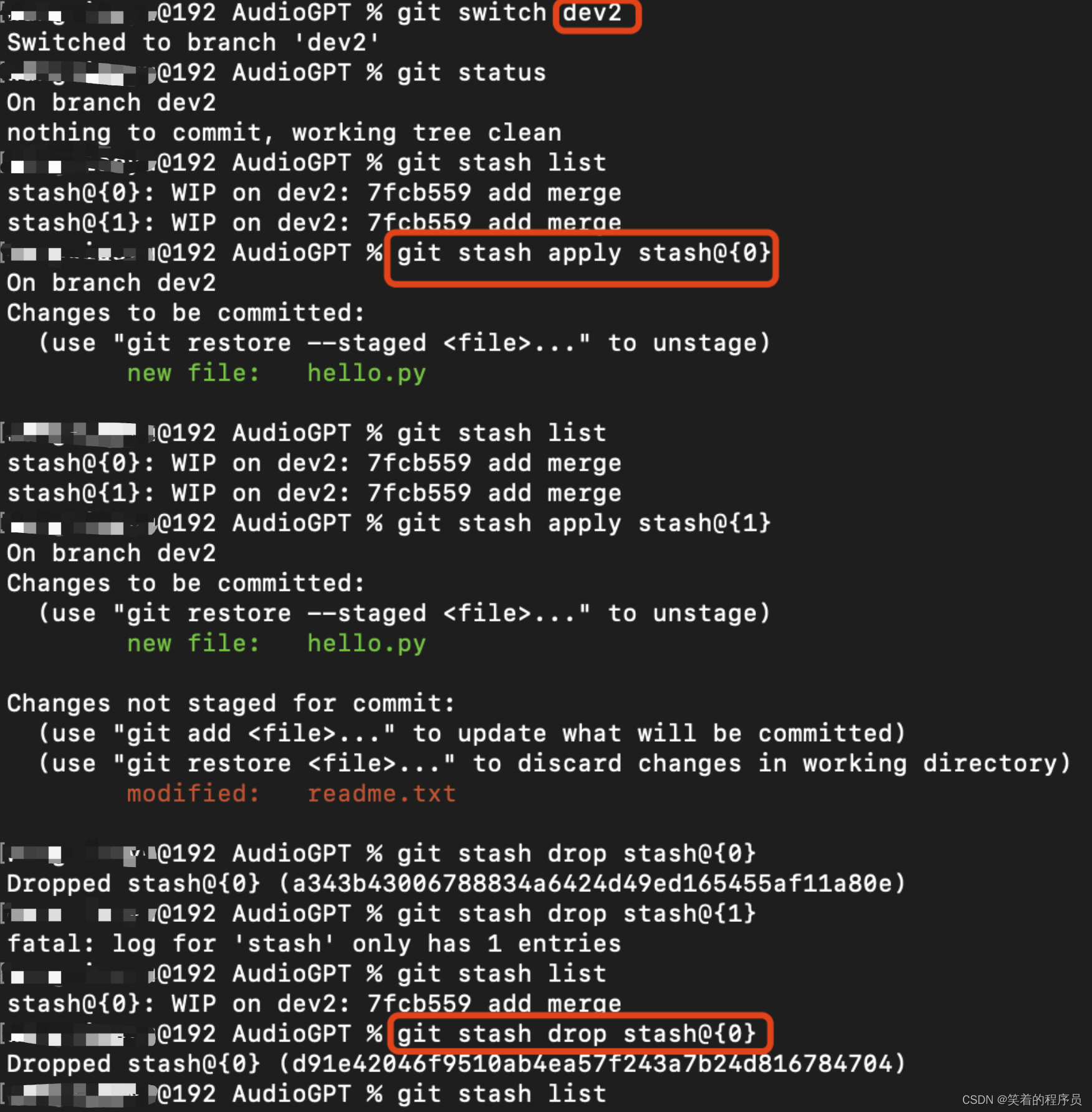
git stash pop的用法:
本分支add到暂存区之后,才能stash
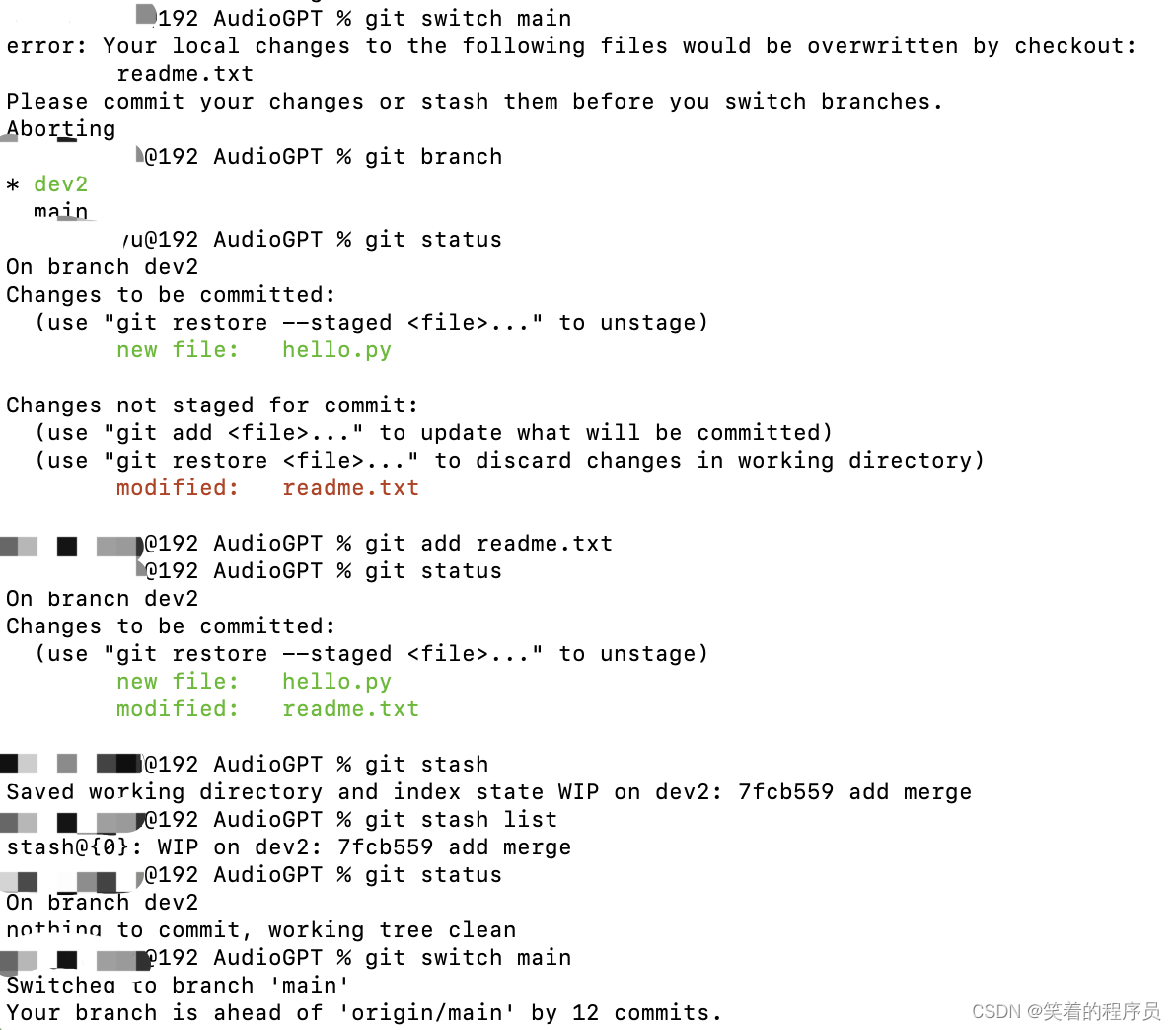
回到工作分支之后,使用git stash pop命令,可以看到git stash list没有回显,所以就不必再删除stash的内容,因为已经删除了。
cherry-pick命令的使用
对于多分支的代码库,将代码从一个分支转移到另一个分支是常见需求。
这时分两种情况。一种情况是,你需要另一个分支的所有代码变动,那么就采用合并git merge。另一种情况是,你只需要部分代码变动(某几个提交),这时可以采用 Cherry pick。
git log查询到特定提交的commitHash
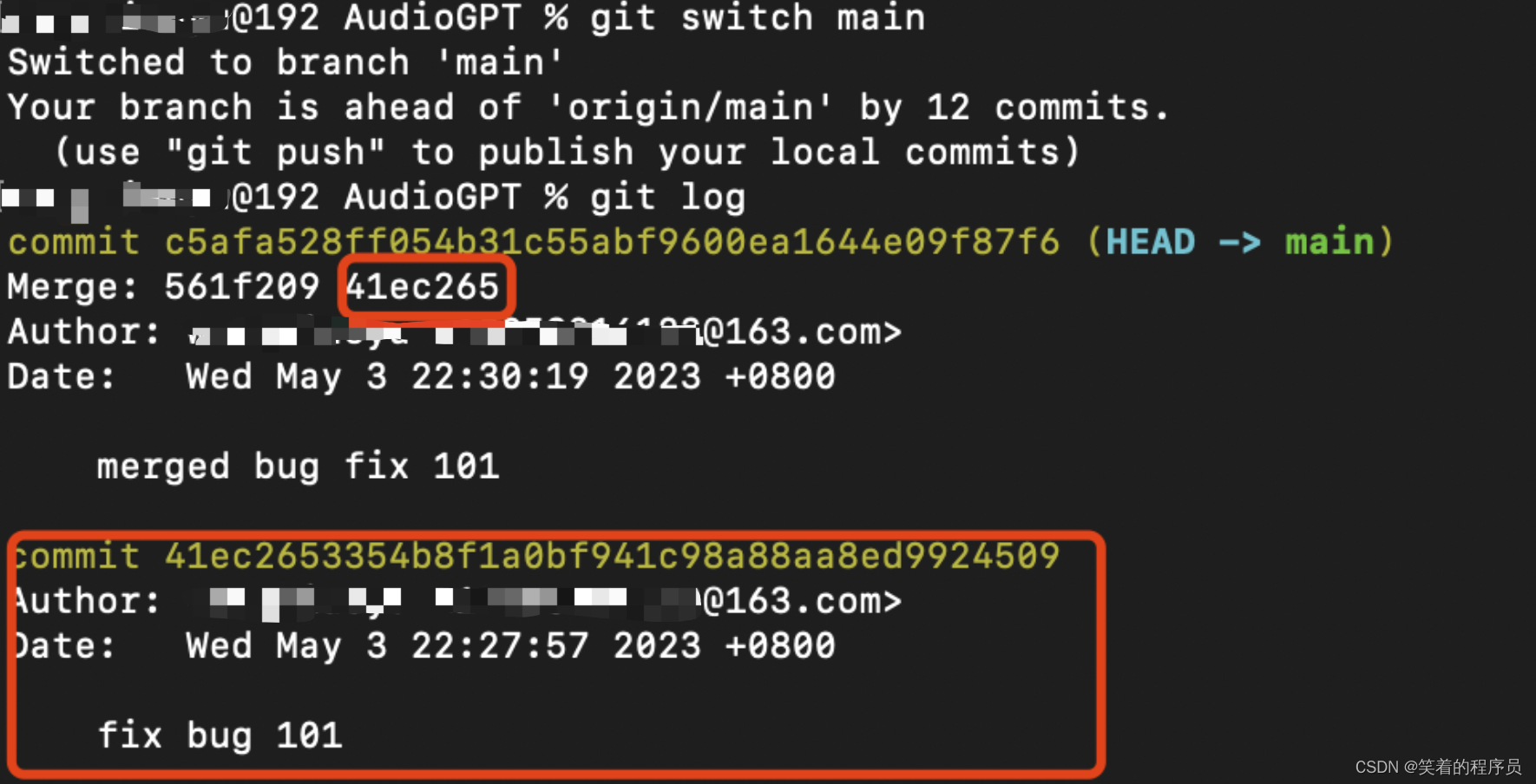
git cherry-pick命令的作用,就是将指定的提交commit应用于其他分支。
git cherry-pick commitHash
上面命令就会将指定的提交commitHash,应用于当前分支。这会在当前分支产生一个新的提交,当然它们的哈希值会不一样。
Cherry pick 支持一次转移多个提交。
git cherry-pick命令的参数,不一定是提交的哈希值,分支名也是可以的,表示转移该分支的最新提交。
git cherry-pick feature
上面代码表示将feature分支的最近一次提交,转移到当前分支。
git cherry-pick 转移多个提交
Cherry pick 支持一次转移多个提交。
git cherry-pick <HashA> <HashB>
上面的命令将 A 和 B 两个提交应用到当前分支。这会在当前分支生成两个对应的新提交。
如果想要转移一系列的连续提交,可以使用下面的简便语法。
git cherry-pick A..B
上面的命令可以转移从 A 到 B 的所有提交。它们必须按照正确的顺序放置:提交 A 必须早于提交 B,否则命令将失败,但不会报错。
注意,使用上面的命令,提交 A 将不会包含在 Cherry pick 中。如果要包含提交 A,可以使用下面的语法。
git cherry-pick A^..B
git cherry-pick 配置项
git cherry-pick命令的常用配置项如下。
-e,--edit: 打开外部编辑器,编辑提交信息。
-n,--no-commit: 只更新工作区和暂存区,不产生新的提交。
-x: 在提交信息的末尾追加一行cherry picked from commit ...,方便以后查到这个提交是如何产生的。
-s,--signoff: 在提交信息的末尾追加一行操作者的签名,表示是谁进行了这个操作。
-m parent-number,--mainline parent-number: 如果原始提交是一个合并节点,来自于两个分支的合并,那么 Cherry pick 默认将失败,因为它不知道应该采用哪个分支的代码变动。
-m配置项告诉 Git,应该采用哪个分支的变动。它的参数parent-number是一个从1开始的整数,代表原始提交的父分支编号。git cherry-pick -m 1 <commitHash>表示,Cherry pick 采用提交commitHash来自编号1的父分支的变动。一般来说,1号父分支是接受变动的分支,2号父分支是作为变动来源的分支。
git cherry-pick 转移到另一个代码库
Cherry pick 也支持转移另一个代码库的提交,方法是先将该库加为远程仓库。
git remote add target git://gitUrl
上面命令添加了一个远程仓库target。
然后,将远程代码抓取到本地。
git fetch target
上面命令将远程代码仓库抓取到本地。
接着,检查一下要从远程仓库转移的提交,获取它的哈希值。
git log target/master
最后,使用git cherry-pick命令转移提交。
git cherry-pick <commitHash>
git cherry-pick 代码冲突
如果操作过程中发生代码冲突,Cherry pick会停下来,让用户决定如何继续操作。
(1)--continue
用户解决代码冲突后,第一步将修改的文件重新加入暂存区(git add .),第二步使用下面的命令,让 Cherry pick 过程继续执行。
git cherry-pick --continue
(2)--abort
发生代码冲突后,放弃合并,回到操作前的样子。
(3)--quit
发生代码冲突后,退出 Cherry pick,但是不回到操作前的样子。
cherry-pick和保留现场的stash发生冲突,
如下图,通过修改文件,然后git add解决
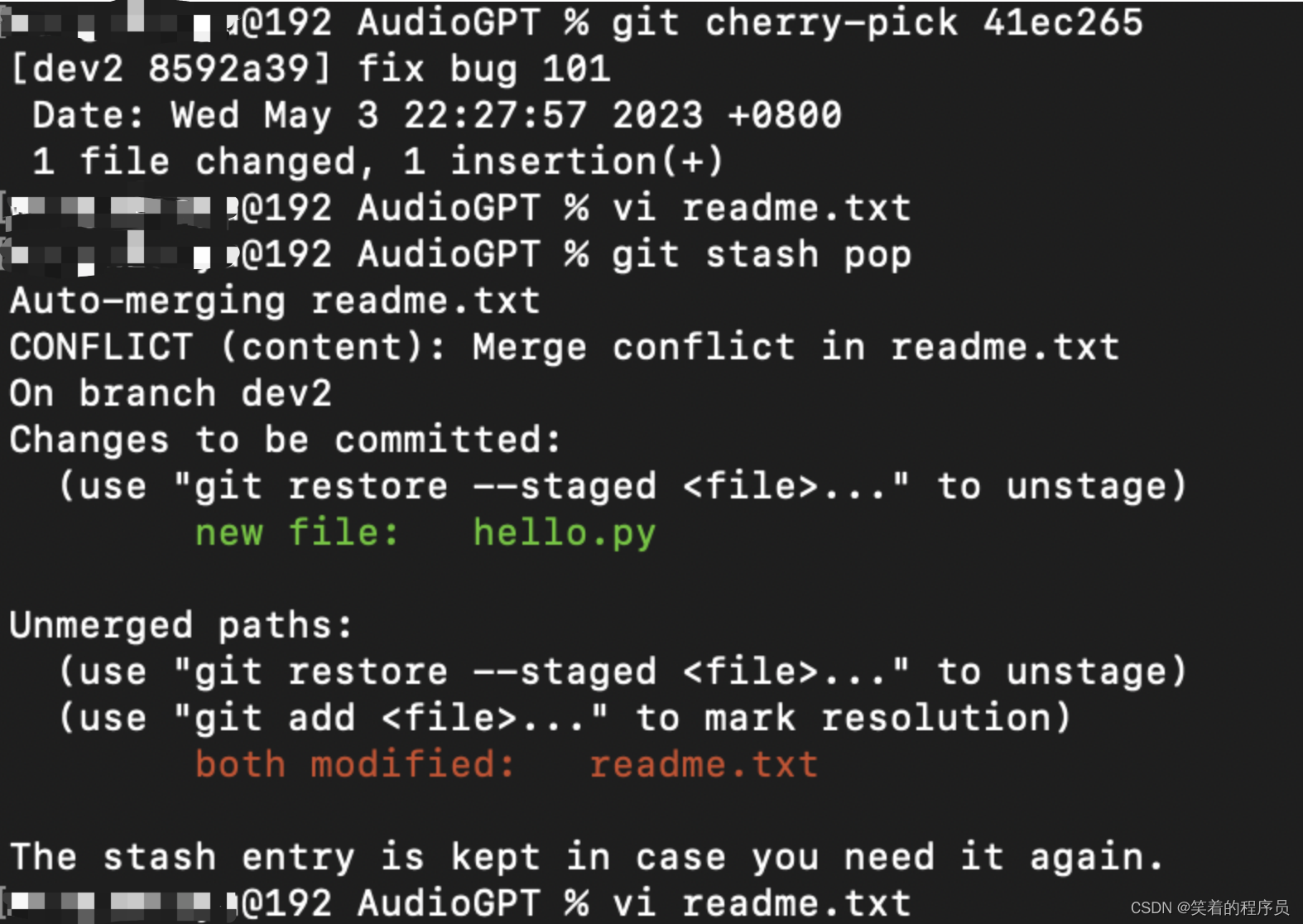
修改冲突文件,git add filename,问题解决
查看远程分支
当你从远程仓库克隆时,实际上 Git 自动把本地的master分支和远程的master分支对应起来了,并且,远程仓库的默认名称是origin。
要查看远程库的信息,用git remote:
git remote origin
或者,用git remote -v显示更详细的信息:
git remote -v origin
[email protected]:michaelliao/learngit.git (fetch) origin [email protected]:michaelliao/learngit.git (push)
上面显示了可以抓取和推送的origin的地址。如果没有推送权限,就看不到push的地址。
推送分支
推送分支,就是把该分支上的所有本地提交推送到远程库。推送时,要指定本地分支,这样,Git 就会把该分支推送到远程库对应的远程分支上:
git push origin master
如果要推送其他分支,比如dev,就改成:
git push origin dev
但是,并不是一定要把本地分支往远程推送,那么,哪些分支需要推送,哪些不需要呢?
- master分支是主分支,因此要时刻与远程同步;
- dev分支是开发分支,团队所有成员都需要在上面工作,所以也需要与远程同步;
- bug分支只用于在本地修复bug,就没必要推到远程了;
- feature分支是否推到远程,取决于你是否和你的小伙伴合作在上面开发。
总之,就是在 Git 中,分支完全可以在本地,你可以根据分支的需求来决定是否需要推送到远程!
抓取分支
多人协作时,大家都会往master和dev分支上推送各自的修改。
现在,你的小伙伴要在dev分支上开发,就必须创建远程origin的dev分支到本地,于是他用这个命令创建本地dev分支:
git checkout -b dev origin/dev
现在,他就可以在dev上继续修改,然后,时不时地把dev分支push到远程:
推送失败,因为你的小伙伴的最新提交和你试图推送的提交有冲突,解决办法也很简单,Git 已经提示我们,先用git pull把最新的提交从origin/dev抓下来,然后,在本地合并,解决冲突,再推送:
git pull
There is no tracking information for the current branch. Please specify which branch you want to merge with. See git-pull(1) for details.
git pull <remote> <branch>
If you wish to set tracking information for this branch you can do so with:
git branch --set-upstream-to=origin/<branch> dev
git pull也失败了,原因是没有指定本地dev分支与远程origin/dev分支的链接,根据提示,设置dev和origin/dev的链接:
git branch --set-upstream-to=origin/dev dev
Branch 'dev' set up to track remote branch 'dev' from 'origin'.
再pull:
git pull
Auto-merging env.txt CONFLICT (add/add): Merge conflict in env.txt Automatic merge failed; fix conflicts and then commit the result.
这回git pull成功,但是合并有冲突,需要手动解决,解决的方法和分支管理中的解决冲突完全一样。解决后,提交,再push:
因此,多人协作的工作模式通常是这样:
首先,可以试图用git push origin 推送自己的修改;
如果推送失败,则因为远程分支比你的本地更新,需要先用git pull试图合并;
如果合并有冲突,则解决冲突,并在本地提交;
没有冲突或者解决掉冲突后,再用git push origin 推送就能成功!
如果git pull提示no tracking information,则说明本地分支和远程分支的链接关系没有创建,用命令git branch --set-upstream-to origin/。
这就是多人协作的工作模式,一旦熟悉了,就非常简单。
git rebase
发布一个版本时,我们通常先在版本库中打一个标签(tag),这样,就唯一确定了打标签时刻的版本。将来无论什么时候,取某个标签的版本,就是把那个打标签的时刻的历史版本取出来。所以,标签也是版本库的一个快照。
Git 的标签虽然是版本库的快照,但其实它就是指向某个commit的指针(跟分支很像对不对?但是分支可以移动,标签不能移动),所以,创建和删除标签都是瞬间完成的。
在上一节我们看到了,多人在同一个分支上协作时,很容易出现冲突。即使没有冲突,后push的童鞋不得不先pull,在本地合并,然后才能push成功。
- rebase操作可以把本地未push的分叉提交历史整理成直线
- rebase的目的是使得我们在查看历史提交的变化时更容易,因为分叉的提交需要三方对比