摘要
由于复杂的程序和昂贵的硬件,同步定位和建图(SLAM)的发展一直严重依赖公共数据集操练(drill,这个词理解不好,评估就是旁观者,那么这里理解为参与者即操作或练习吧)和评估,从而产生了许多令人印象深刻的演示和良好的基准测试分数。然而,与此形成巨大反差的是,SLAM在走向成熟部署的道路上仍在苦苦挣扎,这听起来是一个警告:一些数据集曝光过度,导致使用和评估出现偏差。这就提出了如何全面了解现有数据集并正确选择它们的问题。此外,当前数据集确实存在局限性,那么如何构建新的数据集以及该往哪个方向发展?然而,目前尚不存在能够解决上述问题的综合调研,但是问题迫在眉睫。为了填补这一空白,本文力求涵盖有关SLAM相关数据集的一系列有凝聚力的主题,包括一般收集方法和基本特性维度、SLAM相关任务分类和数据集分类、最新技术介绍、概述和对比现有数据集,回顾评估标准,分析和讨论当前的局限性和未来的方向,期望不仅可以指导数据集的选择,也可以促进数据集的建设研究。
一、 引言
同时定位和映射(SLAM)是关于在移动机器人中实现“内外兼修”的主题——通过构建地图外部了解世界,通过跟踪位置了解自身。作为移动机器人社区的决定性技术,SLAM引起了广泛关注,并引发了许多工业中的应用。在自动驾驶汽车[4]、导航机器人[5]和无人机(UAV)[6]、[7]中,SLAM周围环境进行建图并计算出地图内的自我运动。在虚拟现实/增强现实(VR/AR)系统[8]中,SLAM给出了智能体的准确姿势,从而有助于直观地操纵虚拟对象。在移动建图[9]中,SLAM估计相邻帧之间的转换,并将3D点合并到一个一致的模型中。然而,从实际部署的角度来看,此类技术还远未成熟,这表明基准分数与成熟生产力之间存在巨大差距。
SLAM相关问题的研究在很大程度上依赖于公开可用的数据集。一方面,SLAM相关问题的具体实验涉及相当昂贵的硬件和复杂的程序。必须使用移动平台(如轮式机器人)、传感器(如激光雷达和相机)和地面实况仪器(如实时运动学(RTK)校正的全球导航卫星系统(GNSS)和一套动作捕捉系统),这对个体研究人员来说是巨大的经济负担。如果需要多传感器数据(在大多数情况下是这样),则必须在数据收集之前执行时间和空间校准。总体来说,几乎不可能以现场实验的方式测试每一个草案。另一方面,数据集可以为评估和比较提供公平的基准。为了公平地量化算法性能,数据集提供者提出了几个一致的评估标准和指标[12]、[13]。通过评估相同的数据集,世界各地的研究人员能够横向比较他们的算法。逐渐地,公共基准分数已成为当今论文发表的基本依据。
在此背景下,出现了四个主要问题。首先,现有数据集的使用存在很大偏差。实际上,在过去的十年中,已经发布了大量数据集,而研究人员缺乏方便的方法来了解它们,因此只测试了几个最知名的数据集,例如KITTI[14]、TUM RGB-D[12]和EuRoC[15]。这很可能会导致过度拟合,因此在某个基准上的高分并不能确保在其他基准上取得同样好的结果。其次,数据集的选择缺乏有效方法,有时是不正确的。SLAM 是一个新兴但复杂的学科,而相关任务仍然没有明确的分类法。这导致了双向选择困难:算法研究人员没有选择合适数据集的方法,数据集提供者没有指定它们的可评估任务的依据。第三,现有数据集在某些维度上仍然有限。例如,缺乏场景类型、数据大小、传感器数量和模式、实际真值(ground-truth)的限制等。虽然不同的数据集是互补的,但数据集的整体仍然不能全面反映现实世界,因此很容易隐藏算法的缺陷。然而,这些限制很少被分析,进而推荐未来发展方向。第四,创建数据集的门槛较高。SLAM相关数据集的研究是一个自成一体的学科,可以将算法的极限推向另一个层次,而社区仍然无法获得关于收集方法和特性的系统知识,这很可能会影响新数据集的广泛发布。
据我们所知,没有公开文献解决上述问题。甚至,目前还没有任何专门针对SLAM数据集的调研。Firman[16]调研了总共102个RGB-D数据集,而其中只有9个可用于SLAM相关问题研究。蔡等人[17]还调查了基于RGB-D的数据集,将46个数据集分为5个类别,而仅涵盖2个用于SLAM用途。布列松等人[18]对自动驾驶中SLAM的趋势进行了一项调查,总结了10个数据集,但这些数据集相当陈旧,主要针对基于LiDAR的方法收集,远非全面。Yurtsever等人[19]还提出了一项关于自动驾驶的调查,概述了18个数据集。但是,没有指定适用的任务:其中许多不能用于SLAM研究。
为了填补这一空白,本文力求对SLAM相关数据集进行结构化和全面的调查。一方面,由于在此期间SLAM领域没有任何完美或主导的数据集(如计算机视觉领域的ImageNet[20]),我们认为SLAM相关数据集应该以互补的方式使用。为此,本文的主要目标是作为一个字典,以确保全面、正确和高效的数据集选择。基于提出的SLAM相关任务分类和数据集分类,我们调查了总共97个数据集,每个数据集都指定了适用的任务,同时对特征的多个维度进行了总结和比较。另一方面,无论是从操练(drill)还是评估的角度来看,我们相信这些数据集可以将SLAM相关算法的极限推向另一个层次。因此,本文的另一个目标是降低数据集的使用门槛并指导数据集研究的未来方向。因此,描述了SLAM相关数据集的一般收集方法和基本特性维度,并分析和讨论了当前的局限性和未来的方向。此外,还详细介绍了一些最先进的数据集和公共评估标准,这对未来数据集xx的发布具有指导意义。
本文的其余部分分为5个部分(整体结构如图1所示)。第二节介绍了SLAM相关数据集的一般收集方法和基本特性维度,以便为以下介绍铺平道路。第三节阐明了SLAM相关任务的分类,从而产生了数据集分类的四大类。第四节详细介绍了16个最先进的数据集。第五部分按类别调查尽可能多的现有SLAM相关数据集(总共97个),形成每个类别的2个概览和比较表,并提供数据集选择指南。第六节回顾了关键的评估标准。第七节对数据集评估的当前局限性和未来方向进行了分析和讨论。最后,第八节做一个简短的总结并对今后的工作进行安排。

二、SLAM相关数据集:收集方法和基本维度
2.1 基本收集方法

数据集收集的一般方法如图2所示:首先配置硬件,然后执行时空传感器校准,然后在目标测试场景中收集数据序列,最后生成准确的真实数据(ground truth)。可以看出,该过程比其他类型的数据集更复杂,例如对象检测,不需要严格的传感器校准或高端地面实况生成技术。为降低研究门槛,为后续介绍做铺垫,本部分将对一般方法论进行具体说明。需要注意的是,除了现实世界的数据采集之外,还有一种虚拟合成的方式,就像一些逼真的3D电脑游戏的渲染一样。但是这种方式的方法论主要是软件问题(比如使用AirSim1和POVRAY2),这里就不详细介绍了。
2.1.1 硬件设置
硬件配置涉及移动平台和感知传感器的选择。对于移动平台,选择主要取决于目标应用,例如:用于VR/AR和智能手机应用的手持载体、用于移动地图的背包、用于自动驾驶的汽车、用于服务和导航机器人的轮式机器人、和用于空中应用的无人机。
对于感知传感器,需要根据算法所基于的传感器类型进行选择。但是,很有可能尝试不同的方式和传感器的融合来填补一定的空白。因此,为了支持这种需求,采集系统通常配备非单一传感器和多种模式,例如相机(单色、立体、灰度、彩色和基于事件的[21])、激光雷达(单和多光束)、RGB-D传感器[22]和惯性测量单元(IMU)。这里我们主要指的是商业级IMU,因为它便宜且无处不在,而一些高端IMU(如光纤陀螺仪(FOG))过于昂贵,主要用作地面实况仪器而不是感知传感器。
2.1.2 传感器校准
在多传感器配置的情况下(在大多数情况下是这样),不同传感器之间的时空校准是强制性的。
空间校准旨在找到不同传感器框架之间的刚性变换(也称为外部参数),从而能够将所有数据统一到一个坐标系中。通常,外参标定可能出现在成对的相机与相机、相机与惯性测量单元、相机与激光雷达,并且可以在多传感器情况下逐组扩展。对于立体相机校准,在机器视觉领域应用最广泛的可能是张在2000年提出的方法[23]。它非常灵活,因为该技术只需要在印刷平面棋盘的几个不同方向上自由拍摄图像。该算法会在每张拍摄图像中检测棋盘上的角点,作为闭式解的约束,然后求解一组粗略值。最后,通过最小化重投影误差进一步细化结果。到目前为止,已经校准了内在、镜头畸变和外在参数。该算法已在Matlab3、OpenCV4和ROS5中实现,被证明是高度准确和可靠的,显着降低了3D视觉研究的界限。对于相机到IMU的校准,最著名的框架是Kalibr6工具箱 [24]、[25]、[26]。校准时,只需在校准图案前挥动视觉惯性传感器套件即可。该框架将变换矩阵和时间偏移参数化为统一原则的最大似然估计器,因此通过最小化总客观误差,Levenberg-Marquardt(LM)算法可以一次估计所有未知参数。对于相机到激光雷达的校准,一般的方法是找到2D图像和3D点云之间的相互对应关系,从而计算它们之间的刚性变换(示例如图3所示)。两个常用的框架是KIT Camera and Range Calibration Toolbox7[27]和Autoware Calibration Toolbox8[28],它们分别展示了全自动和交互式的实现。

时间校准旨在同步不同传感器的时钟或数据包,或估计它们之间的时间偏移。最理想的解决方案是与硬件支持同步,例如外部触发(工业相机通常具有)、GNSS定时和精确时间协议[29](PTP,也称为IEEE-1588)同步。然而,这些功能在消费级产品上几乎找不到,尤其是普通相机和IMU。为此,一种可行的方法是估计由不同步时钟或不同传感器之间的通信延迟引起的时间偏移。解决此类问题的一般方法是参数化时间偏移,并通过最大化互相关或最小化不同传感器过程之间的设计误差函数来进一步执行优化。例如,如上所述,Kalibr工具箱实现了相机到IMU统一时间和空间校准。
总的来说,不同传感器之间时空对齐的过程和技术是相当普遍的,因此我们不会在以下部分详细介绍每个数据集的校准过程。
2.1.3 目标场景下序列收集
目标场景的选择取决于算法的预期测试场景。例如,我们可以选择城市、农村和高速公路的场景进行自动驾驶测试。对于数据序列收集,为了更好地复制现实世界,需要更多的序列、更多的路径和更长的路径。此外,如果要测试算法可能的位置识别和闭环功能,路线应该多次遍历同一位置。
2.1.4 真实数据生成
真实数据是要在评估中进行比较的准确参考数据。明确地说,在SLAM相关问题的范围内,我们只讨论两种真实数据:位姿(即位置和方向)和3D结构,分别用于定位和建图评估。
- 位置与方向:用于位姿测量的技术可能由于不同的场景而不同。对于小规模和室内场景,最有效的解决方案是动作捕捉系统(MoCap)(例如,VICON9、OptiTrack10和MotionAnalysis11)(如图4所示),它以相当高的速率工作,同时提供了令人难以置信的位置和方向的准确性。但它也有缺点:成本较高,在户外不能很好地工作,因为红外光的过度干扰会影响摄像头的跟踪。对于大型室外场景,具有RTK校正和双天线的全球卫星定位导航系统(GNSS)可能是最成熟的解决方案[31]。但是,适用条件也很严格——移动代理应该在开阔的天空下,否则精度会显着漂移。所以很常见的是,在单个数据序列中,可能存在一些不可信任的片段,这将极大地影响数据集的质量(如图5所示)。另一个支持室内和室外环境的高精度解决方案是激光跟踪仪(例如,FARO12和Leica13)。它提供了卓越的定位精度(可达亚毫米级),同时应确保无遮挡,为从仪器发射到目标的激光让路,这在许多情况下很难实现。本地化也有一些替代方案,例如Fiducial Marker[32]、全球移动通信系统(GSM)[33]、超宽带(UWB)[34]、Wi-Fi(我们指的是无线网络技术基于IEEE 802.11 系列标准)[35]和蓝牙[36],所有这些都在工业中广泛部署。然而,尽管更普遍,这些解决方案要么准确性不足,要么在某些条件下难以解决。此外,有时环境可能过于复杂而无法测量地面实况(例如,城市峡谷和室内外一体化场景),那么使用多传感器融合算法的结果(例如,将LiDAR里程计或SLAM与高端INS和车轮里程计)作为基线[37]或直接测量开始到结束的漂移[38]来进行评估。

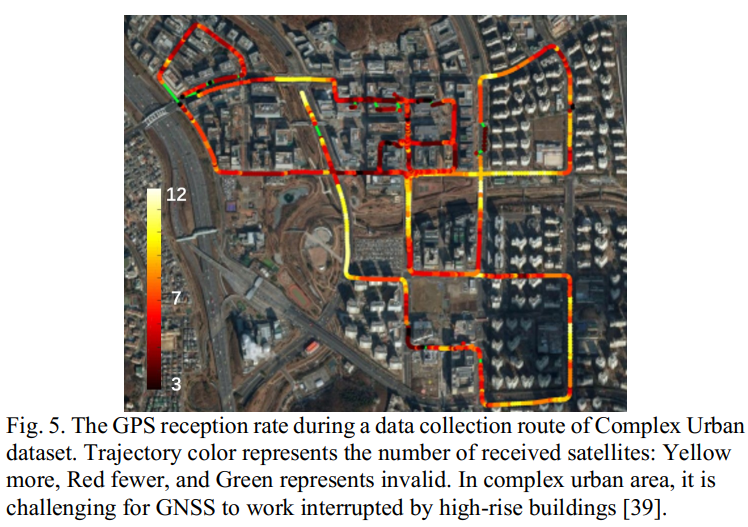
- 3D结构:长期以来,尽管建图是研究的一个组成部分和关键部分,提供3D结构真实数据有点不通用,如SLAM数据集[12]、[40]、[41]。一个主要原因可能是硬件负担——提供密集场景模型的高精度3D扫描仪(如图6所示)对于许多机构来说很难负担,更不用说单个研究人员了。对于物体或小规模场景,由结构光或激光驱动的便携式3D扫描仪可能是最佳选择(例如GOM ATOS14、Artec 3D15 和 Shining 3D16),精度可达10微米级。对于大尺度场景,最好的解决方案是使用专业的测量仪器(如FARO、Leica17、Trimble18),精度可达数百米。通过注册多个站点,扫描仪能够覆盖非常大的区域,每次单独的扫描耗时数到数十分钟。此外,有时面积可能太大,如果位姿数据准确,也适用于使用移动测绘系统(MMS,例如RIEGL19,融合了高精度RTK、LiDAR和IMU)或采用基于LiDAR的建图/SLAM算法的建图结果作为3D结构参考[37]。
2.2 基本特性维度
如收集方法所反应的,收集数据集的特性主要由5个基本特征决定:移动平台、传感器设置(校准感知传感器)、目标场景、数据顺序和真实数据(ground truth)。因此,这些维度构成数据集介绍、比较分析的基础。下面给出了各个维度的描述。
2.2.1 运动平台
移动平台决定数据集的运动模式。表I列出了几种常见平台的一般特性,解释了自由度(DoF)、速度和运动特性。这些特征被确定为影响算法性能,例如,快速运动(例如,抖动、急转弯/旋转/移位和高速)会影响数据质量,例如相机运动模糊(见图7-左)和LiDAR失真(2D/3DLiDAR都设计用于扫描激光发射器以异步扫描大量点,这些点被打包到一个帧中,但在运动中确实具有不同的坐标,严重扰乱了结果,见图7-右)。此外,纯旋转会导致单目情况下的基础矩阵退化,而快速的速度可能会导致相邻帧之间的狭窄重叠。如表所示,一般6自由度平台(手持、背包、无人机)算法难度较大。

2.2.2 传感器设置
传感器设置是指已校准感知传感器的数量和模式,从而决定数据集支持的算法类型。如方法中所示,我们可以假设所有感知传感器都已校准好,因此它们可以以任意组合使用。例如,如果数据集包含双目立体相机、LiDAR和IMU的传感器设置,那么它可以支持基于立体视觉、视觉-惯性融合(VI)、视觉-LiDAR融合(VL)、视觉的算法-LiDAR-inertial fusion (VIL)等。在构建或选择数据集时,它是要考虑的主要因素。
2.2.3 目标场景
目标场景涉及预期测试环境的类型、条件和规模。场景的类型决定了数据的外观和结构,这正是算法估计运动所依赖的,从而直接影响性能。想象一下,如果相机在纯白的墙壁前移动(即弱纹理),那么基于视觉的算法就不可能提取显著特征来跟踪运动。此外,如果基于LiDAR的方法在较长的走廊(即重复结构)中工作,则很难在LiDAR扫描之间获得匹配。同样,场景类型也可以引入一些其他具有挑战性的元素,包括重复纹理(草地、沙地等)、弱结构(开阔地、农田等),以及干扰特征和结构(水和玻璃的反射等)。
场景条件主要包括光照、动态物体、天气、季节和时间。这些因素都会对算法性能产生影响,例如,在光线不好或黑夜的情况下,相机无法获得好的图像。
场景尺寸也很重要,因为它间接影响数据序列的数量和种类。它很大程度上取决于场景类型,例如,城市或校园场景通常可以覆盖大范围,而房间场景通常面积较小。
2.2.4 数据序列 Data sequence
数据序列涉及序列的数量、路径的长度以及采集路径的多样性。通常,数量更多、轨迹更长、路线多样的数据集对场景的覆盖更完整,因此更有机会检查算法的弱点。
2.2.5 真实数据(ground truth)
真实数据涉及参考数据的类型和质量,它决定了数据集的可评估性。前面的方法论部分对现有的ground truth技术进行了全面的介绍,但它们在适用场景、要求和准确性方面存在很大差异。表二给出了它们之间的特性比较。需要注意的是,虽然精度不同,但大多数真实数据已经足够用于SLAM相关的评估。

三、SLAM相关任务和数据集分类
本节提供了清晰的SLAM相关任务分类和数据集分类,以解决算法研究人员和数据集提供者之间的双向选择困难的问题。
提出的SLAM相关任务分类考虑了2个方面:面向传感器和面向功能。
以传感器设置为导向,SLAM相关任务主要有五个分支:基于激光雷达、基于视觉、视觉-激光雷达融合、基于RGB-D和基于图像。受益于激光传感器的高精度测距,基于LiDAR的方法(2D[44]和3D[45])被广泛采用,是一种成熟的解决方案。然而,LiDAR的价格太高,多光束版本(3D)至少要花费数千美元[46]。随着视觉传感器的普及,以及计算硬件的改进,基于视觉的方法极大地在SLAM社区[47]、[48]、[49]得到了极大地发展。更具体地说,由于视觉模态的多样性,出现了许多子类,包括单目、立体、鱼眼、基于事件的[50]方法等,适用于不同的应用场景。尽管不如基于LiDAR的方法[45]、[51]、[52]稳健和准确,但仍然证明视觉方法具有巨大的潜力,并且正在稳步向前发展[53]。为了结合两种模式的优势,视觉-LiDAR融合已成为备受关注的热门话题[54]。
RGB-D是一种新颖的模式,它还结合了成像和测距传感器。它收集彩色图像以及深度通道,这使得执行3D感知变得更加容易。自从微软Kinect[22]首次推出以来,RGB-D传感器由于其低成本和互补性而被广泛应用于SLAM研究[55]、[56]。此外,还有一个名为基于图像的分支,它在3D计算机视觉中很流行。与基于视觉的方法相比,它不需要专门安排传感器设置或连续图像,从互联网收集的照片也可用于恢复场景或物体的3D模型。对于其他模态,如IMU、GNSS和车轮里程计,它们可以提供先验并融合到优化中,从而提高运动估计的准确性和鲁棒性。由于它们主要被采用以起到辅助作用,因此相关的融合被分为上述五个分支。

在上述传感器设置的背景下,以功能为导向,SLAM相关问题有两个主要分支:移动定位和建图,以及3D重建。
在移动定位和建图的范围内,有3个具体的任务:里程计、建图(这里我们指的是实时或准实时顺序方式)和SLAM。这3个术语在技术层面具有层级关系,如图8所示。里程计意味着随着时间的推移逐步跟踪代理的位置和方向[57]。此类系统的缩写通常命名为“O”,如VO、VIO、LO,分别指Visual Odometry、Visual-Inertial Odometry和LiDAR Odometry。由于更好的性能,特别是在不平坦或其他不利的地形[58],[59],[60],它被提议作为车轮里程计的替代或补充。严格来说,除了跟踪路径,里程计还可以恢复3D点,而这些路标仅用于局部优化而不是地图。制图是指通过移动采集以特定格式构建环境地图。通常,建图与里程计一起工作,因此被称为里程计和建图(OAM)(我们避免使用术语移动建图,因为它通常指的是测绘领域中更专业的应用[61]),因为它依赖于姿态估计恢复3D点并将场景结构合并在一起。至于SLAM,直观上是兼具里程计和建图的功能,但并不是两者的简单结合。SLAM意味着跟踪代理的位置,同时构建全局一致且可重用的地图[57]、[62]。这暗示了SLAM的两个核心功能:闭环和重定位,它们依赖于地图数据库来查询以前访问过的地方。闭环是指在重新访问的地方周围添加新的约束以进行全局优化,从而消除路径的累积漂移并确保全局一致的地图。重定位是指在机器人失去轨道后在预建地图内恢复定位。可以看出,“SLAM地图”不仅是一个模型,还是一个用于查询的数据库,它支持地图复用能力,在SLAM和其他两者之间划清界限。需要注意的是,地图不一定要密集或好看,重点是机器人能不能识别。毕竟,稀疏地图点也可以存储特征和描述符[63],[64]。

3D重建是指从顺序数据或不同位置和视角的数据中恢复出高质量的场景或对象的3D地图或模型。通用方法与移动定位和地图绘制类似,但它不需要顺序数据和实时运行。它可以在任何共可见数据帧之间建立尽可能多的约束,并进行更多的优化,因此无疑可以实现更好的准确性和密度。它可以通过多种传感器(例如,相机、激光雷达和RGB-D)来实现,但在这里我们想强调一下基于图像的方法,它不需要顺序数据或固定传感器。基于图像的领域主要有两个特定的任务:运动结构(SfM)和多视图立体(MVS)。SfM是一个从不同位置和视图的2D图像中恢复3D结构的过程[65],通过估计任何可见视图中的相机位姿。通常,输出模型由稀疏点云组成。MVS可以看作是双视立体的泛化,它假设每个视图的已知相机位姿(就像双目相机之间的外在参数)来恢复密集的3D模型。由于SfM已经预先估计了相机的位姿,因此MVS可以直接作为SfM的后处理来构建准确且密集的模型[66]。
总体而言,综合考虑上述原则和该领域的共识,我们提出分类为基础传感器、辅助传感器和功能的组合,如表III所示。例如,如果一个算法是基于LiDAR并且功能是里程计和建图(OAM),那么该任务将被归类为LOAM(这与Zhang等人[45]提出的算法的名称一致);如果算法基于视觉(V),辅以IMU(I),并且功能是里程计(O),那么该任务将被归类为VIO。需要注意的是,在辅助传感器中,通常使用GNSS和车轮里程计来生成真实数据,但将它们融合到SLAM过程中也是可行且有效的。
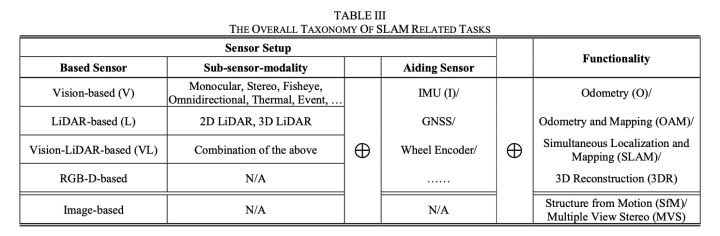
至于数据集分类,从逻辑上讲,为了将数据集与相应的算法类型进行匹配,我们主要以传感器设置为基础。尽管某些方法需要特定的数据集(例如基于事件的VO/VSLAM[50]),但考虑到通常数据集不仅是为一项任务设计的,为了保持兼容性和选择覆盖率,我们避免将数据集分类得太细,因此产生了4大类:
- 基于视觉的移动定位和建图以及3D重建数据集,
- 与LiDAR相关的移动定位和建图以及3D重建数据集,
- 基于RGB-D的移动定位和建图和3D重建数据集,
- 基于图像的3D重建数据集。
该标准与所提出的SLAM任务分类的传感器设置相吻合,而唯一的区别是适用于基于LiDAR和基于视觉LiDAR算法的数据集被合并到LiDAR相关类别中。因为,从数据集的角度来看,如果平台配备了激光雷达,那么它也可以容纳摄像头。需要注意的是,包含相机数据的RGB-D数据集和LiDAR相关数据集也可以支持基于视觉的方法。例如,最著名的KITTI数据集[14]和TUM RGB-D数据集[12]通常用于对VO和VSLAM算法进行基准测试。此外,一些具有IMU数据[67]和6-DoF运动的数据集最初可以设计用于IMU融合算法,因此通常具有更高的难度。为避免可能的混淆,我们将在第五节中进一步提供周到的数据集选择指南。
四、SOTA 数据集
本节对上述4个大类的16个最先进的数据集进行了结构化和详细的介绍,我们认为这些数据集可以很好地代表整个数据集,有助于理解当前数据集,也可以作为一个很好的服务未来的版本。给出了许多甚至没有被原始论文涵盖的深刻见解,因此值得列举。请注意,由于篇幅所限,我们避免详细介绍更多案例,另一方面,由于信息同质,这也不会更有意义。因此,这样的选择并不意味着任何推荐偏差,而消除偏差使用正是本文的主要目标之一。为了实现清晰的描述,数据集以结构化的方式引入,主要关注一般信息、平台和传感器设置、场景和序列、真实数据和亮点。虽然是单独介绍,但我们确实按照时间顺序,并强调了与以往作品相比的特点和进步。为了进行整体比较和分析,我们将在第五节中安排一个简洁而全面的概述,涵盖所有数据集,并在第七节中进行分析和讨论。
4.1 视觉移动定位与建图和三维重建分类
4.1.1 欧洲微型飞行器(EuRoC MAV)
EuRoC MAV 数据集是在欧洲机器人挑战赛(EuRoC)收集公布的,特别是视觉惯性算法的微型飞行器竞赛。自2016年发布以来,经过众多团队的测试和大量文献的引用,成为SLAM范围内使用最广泛的数据集之一。
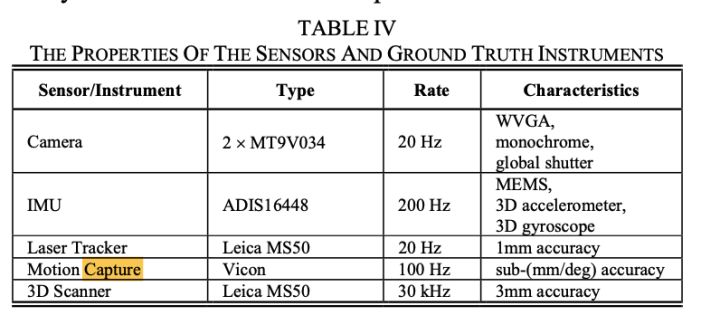
平台和传感器设置:使用MAV收集数据集,逻辑上设计用于提供从慢到高速的6自由度运动。配备了两个灰度相机(立体设置)和一个IMU,并具有严格的时空对齐(属性列于表IV),因此非常适合视觉(单声道和立体),尤其是IMU融合算法。
场景和序列:数据集由机房和房间两部分组成,分别有5个和6个序列。根据纹理、运动和照明条件的不同,数据集被记录为3个难度级别:简单、中等和困难。这已被证明对许多算法[49]、[68]、[69]具有挑战性,使研究人员能够有效地定位弱点并增强他们的算法。
Ground truth:数据集拥有可靠的定位和3D建图的ground truth数据,支持两种评估。对于在机房收集的第一批,3D位置ground truth由激光跟踪仪提供。对于房间里的第二批,分别由动作捕捉系统和激光扫描仪提供6D姿势和3D地图ground truth。所有ground truth都具有极高的质量,如仪器属性中的表 IV 所示。
亮点:Vision-IMU设置、多个复杂度级别、高精度ground truth、3D地图ground truth。
4.1.2 TUM MonoVO
TUM MonoVO数据集于2016年发布,专门用于测试O/SLAM的远程跟踪精度,补充了之前更大场景下的数据集。值得注意的是,所有图像都经过光度校准。
平台和传感器设置:数据集是通过手持载体收集的,这使得运动模式具有挑战性。使用了两个灰度相机,但只是用广角和窄角镜头,而不是形成立体对,因此只能用于单目算法。这些相机具有高达60Hz的帧速率,这远远高于正常水平,可以在设计算法时处理快速和不流畅的运动。
场景和序列:该数据集提供了从室内到室外的各种场景中的50个序列。室内场景主要记录在一栋教学楼内,涵盖办公室、走廊、大厅等。室外场景主要记录在校园区域,包括建筑、广场、停车场等。许多序列具有极长的距离,研究人员希望这些距离能够进行远程测试。
地面实况Ground truth:由于室内外集成环境中的大量采集,使用GNSS/INS或动作捕捉系统几乎不可能测量地面实况。因此,该数据集旨在记录在同一位置开始和结束的每个序列,并在开始和结束段生成一组“ground truth”姿势,允许基于循环漂移评估跟踪精度。请注意,您没有机会检查错误发生的确切位置,因此如果您以逐帧精度为目标,则不建议这样做。并且您必须禁用SLAM使用的“闭环”功能,否则零漂移将使评估无效。
亮点:手持运动模式,多种场景多种序列,光度校准,室内外一体化。
4.1.3 UZH-FPV 无人机竞速
2019年发布的UZH-FPV无人机竞速数据集正式用于IROS 2020无人机竞速大赛。在现有的真实世界数据集中,它包含最激进的运动,进一步补充了之前的6-DoF数据集。
平台和传感器设置:数据集是使用由专家飞行员控制的四旋翼飞行器收集的,以实现极高的速度、加速度和快速旋转,证明远远超出现有算法的能力[71]。它配备了一个灰度事件相机和一个灰度双目立体相机,都具有硬件同步的IMU(属性列于表V),因此可以很好地支持基于视觉(单和立体)、IMU融合和基于事件的方法。
场景和序列:数据集是在室内飞机机库和树木环绕的室外草地上采集的,共形成27个序列。它具有340.1/923.5(m)的最大距离和12.8/23.4(m/s)的室内/室外场景最高速度(两个最高速度都大于任何现有序列)。
地面实况:地面实况是通过使用Leica MS60 全站仪跟踪3D位置生成的,精度低于1毫米。然而,由于激进的飞行,总是会发生激光丢失跟踪导致轨迹中断,因此只选择完整的序列进行发布。
亮点:激进的运动、高度准确的地面实况、事件数据。
4.1.4 OpenLORIS-场景
OpenLORIS-Scene于2019年发布,是IROS 2019 Lifelong SLAM Challenge 的官方数据集。与以前的数据集相比,它是一个真实世界的动态和日常变化场景的集合,专门用于长期机器人导航。
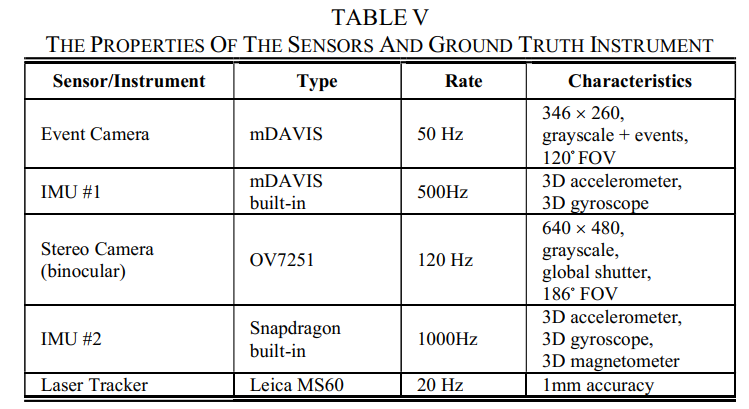
平台和传感器设置:数据集由带有RGB-D相机和彩色双目立体相机(均具有硬件同步IMU)和2D/3D LiDAR的轮式机器人(带里程计)收集(所有属性列于表中)六)。它很好地支持单目、双目、RGB-D和IMU融合方法,但不推荐用于基于LiDAR的方法,因为LiDAR已经用于生成地面实况。

场景和序列:数据集分为办公室、走廊、家庭、咖啡厅和市场5个场景,这些场景是服务机器人非常典型的应用场景,但在以前的数据集中很少出现。得益于真实的记录,很多动态的人和物都被带进了里面,满足了对这些数据的迫切期待。它还针对长期SLAM,因此捕获了每个相同场景但在不同时间段的许多序列,其中包含不断变化的照明、视点以及由人类活动引起的变化(见图9)。
地面实况:对于办公场景,地面实况由Motion Capture System 提供,频率为240Hz,非常适合逐帧评估。对于其他场景,地面实况由LiDAR SLAM 生成,部分伴随传感器融合,据报道具有厘米级精度,虽然没有那么严格,但足以用于视觉方法评估。

亮点:服务机器人平台、多模态传感器、典型场景、多变环境、长期数据。
4.1.5 TartanAir
TartanAir,发布于2020年,是CVPR 2020 Visual SLAM Challenge的官方数据集。它是通过模拟收集的合成数据集,从而完成设计许多具有挑战性的效果,其使命是推动视觉SLAM的极限。
平台和传感器设置:TartanAir是一个模拟数据集,因此没有实际的平台或传感器设置。然而,它创建了具有高度复杂性的随机运动模式,这有利于测试,但不像现实世界的运动那样真实。此外,还模拟了多模态传感器:两个彩色相机(立体设置)、一个IMU、一个深度相机和一个3D LiDAR,支持许多SLAM相关任务的模态,而这些数据非常完美,无法模拟真实-LiDAR的世界相机模糊或运动失真,暗示这种方式的弱点。
场景和序列:TartanAir模拟了多种场景(6类30种):城市、乡村、自然、家庭、公共和科幻。如图10所示,场景设计具有许多具有挑战性的效果,例如光线变化、照明不佳、恶劣天气、时间和季节效果以及动态物体。该数据集共有1037个长序列,产生超过1M帧,比现有数据集大得多。然而,尽管图像看起来很丰富,但在全分辨率下检查时,您仍然会发现质量远非真实。
地面实况:提供相机姿势和3D地图地面实况。值得注意的是,由于模拟方式,它们绝对准确。此外,还提供了一些其他标签,例如语义分割、立体视差、深度图和光流。
亮点:多样的运动模式,多样的场景,丰富的序列,具有挑战性的效果,完美的真实场景。

4.2 激光雷达移动定位与建图和三维重建分类
4.2.1 KITTI 里程计
KITTI里程计数据集,是由Karlsruhe of Technology(KIT)和 Toyota Technological Institute 在 2012 年发布的数据集,是SLAM领域最受欢迎的数据集。除了高质量的数据集本身,很大程度上也是因为著名的公共基准。
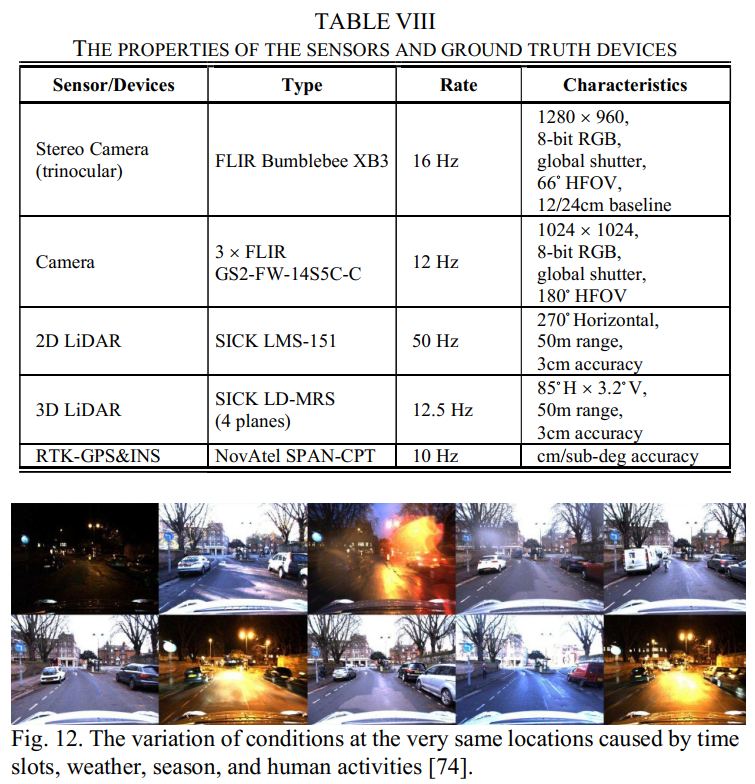
平台和传感器设置:KITTI是使用带有双目立体彩色和单色摄像头(两对通过硬件触发并具有长基线)、激光雷达(每次扫描与摄像头帧同步)和RTK-GPS&INS设备(用于基本事实)。所有传感器都是顶级的(属性列于表VII)并提供高质量的数据,支持基于视觉(单声道和立体)和LiDAR相关的O/SLAM,反之则平滑运动、清晰图像和密集点云确实使算法易于处理,这可能不足以证明正常情况。
场景和序列:数据集是在卡尔斯鲁厄中等城市周围、农村地区和高速公路上收集的。它包含大量原始数据,同时考虑到较长的轨迹、变化的速度和可靠的GPS信号,总共选择了39.2公里的行驶距离,形成了22个频繁闭环的序列,非常适合SLAM验证目的。然而,尽管在现实生活中收集,但众所周知,KITTI仍然很容易:良好的照明和天气、足够的纹理和结构,以及大多数序列中的静态场景,导致翻译误差为0.53%[73],令人印象深刻。值得注意的是,在高速公路上捕获的第21和第22序列是高度动态的(见图11),这可能对运动估计算法具有挑战性。

Groundtruth:使用高端RTK-GPS&INS设备生成姿态地面实况。选择具有良好 GPS 信号的轨迹以确保厘米级精度。但请注意,由于绝对测量的GPS特性,ground truth局部不平滑,如果研究非常小的子序列,将导致评估结果有偏差。直观的理解是,你无法准确测量一张纸的厚度,但可以同时测量100页。因此,在 2013 年,KITTI将最小评估长度从5更改为100,并计算更长的序列,从而更好地指标性能。这也给了我们一个教训:如果你的技术不能给出准确的基本事实,请关注更长的片段进行评估(研究从头到尾的漂移是这个概念的一个极端版本,例如TUM MonoVO)。
亮点:高质量的视觉-LiDAR数据、准确的地面实况、丰富的序列、闭环、公共基准。
4.2.2 Oxford RobotCar
牛津RobotCar数据集于2016年公布,是通过在大约一年内每周两次穿越同一条路线记录下来的,从而产生超过1000公里的轨迹。里面涵盖了各种时间段、天气和场景变化,用长期和具有挑战性的数据极大地补充了以前的数据集(如KITTI)。
平台和传感器设置:汽车配备4个摄像头(1个三目立体和3个单目)、2个2D-LiDAR、1个3D-LiDAR和一套RTK-GPS&INS设备(用于地面实况),从而支持视觉-基于(单和立体)和LiDAR相关的O/SLAM。传感器特性列于表VIII。
场景与序列:由于长期频繁采集,采集到因光照变化、天气变化、动态物体、季节效应、施工工程等引起的多种场景表象和结构,涵盖行人、自行车、车辆交通,小雨和大雨,阳光直射,雪,下,黄昏和夜晚。与KITTI相比,RobotCar在模仿现实世界的层面上更加全面,因此如果算法能够处理好这样的变化和挑战,将更有说服力。图 12 中显示了几个示例图像,以提供直观的感觉。
Ground truth:与数据集分开,RobotCar的 ground truth于2020年发布[75]。在从整个数据集中精心挑选后,通过对高端GNSS/INS进行RTK校正后处理,以10Hz的频率为72个遍历的样本提供6D位姿地面实况,从而获得厘米/亚度精度。
亮点:长期数据集、长轨迹、视觉-LiDAR 设置、反复遍历、各种具有挑战性的条件。
4.2.3 Complex Urban
2019年发布的Complex Urban数据集记录了在不采用GNSS或不准确的多样化和复杂的城市环境中,以完全不同的城市风格补充了KITTI和RobotCar。
平台和传感器设置:使用配备不同级别多模态传感器的汽车收集数据集:两个彩色相机(双目立体)、两个2D-LiDAR、两个3D-LiDAR、一个消费级GPS、一个VRS- RTK GPS(地面实况)、3轴FOG(地面实况)、消费级IMU和两轮编码器(地面实况),支持基于视觉(单声道和立体)的各种SLAM 相关任务)、激光雷达和IMU/GNSS 融合。传感器特性列于表IX。但请注意,由于不重叠,它不支持在构建视觉-LiDAR 融合算法时将LiDAR点投影到相机帧上的确切位置。

场景与序列:数据集采集于大都市区、住宅区、综合公寓、高速公路、隧道、桥梁、校园等多样复杂的城市场景。它覆盖了许多复杂的高层建筑(GNSS性能摇摇欲坠)、多车道的道路、拥挤的移动物体,与KITTI等欧洲城市风格完全不同,对算法提出了新的挑战。所有序列都有数公里的轨迹长度,可以进行真实而彻底的测试。示例帧和相关的3D点云如图13所示,很好地说明了“复杂性”。

地面实况:由于高层建筑、桥梁和隧道的严重遮挡,VRS-GPS无法计算出完整准确的地面实况轨迹。为此,该数据集使用iSAM位姿图SLAM框架[76]生成了基线,采用了FOG、编码器、VRS-GPS和基于ICP的闭环的约束。见表九,传感器和器件性能良好,在如此严格的后处理下不会出现太大偏差。
亮点:多模态多层次传感器,复杂的城市环境,多样的场景。
4.1.4 Newer College
新学院(2009年新学院升级版数据集[78])于2020年发布,是第一个以手持运动模式收集的激光雷达相关数据集,同时具有轨迹和3D建图地面实况,显着补充了之前的车辆数据集,因此非常珍贵。
平台和传感器设置:数据集是使用手持载体收集的,具有6自由度运动,包含可能导致运动模糊和LiDAR失真的振动。它配备了一个RGB-D传感器(仅用作双目立体相机)和一个3D-LiDAR,均嵌入了IMU,支持基于视觉(单目和立体)、LiDAR相关以及IMU融合SLAM相关任务。传感器特性如表 X 所示。
场景序列:数据集采集于牛津新学院,有一个轨迹长度为2.2km的序列。它以步行速度(大约 1 m/s)记录,并带有几个设计的回环,因此可以很好地支持SLAM和其他位置识别算法的验证。环境的3D地图如图14所示。

Groundtruth:该数据集提供准确的姿态和3D地图ground truth,从而支持定位和建图评估,这在以前的数据集中是相当罕见的。正如我们所分析的,使用GNSS生成地面真实姿态并不总是准确和平滑的,因此Newer College采用了一种新方法:首先使用测量级3D激光扫描仪扫描场景的密集地面真实3D地图(如图所示)在图14中),然后通过将LiDAR数据与预构建地图(此处使用ICP)配准进行定位,从而可以计算出高速率和准确的6D位姿。如表 X 所示,3D扫描仪的精度小于1cm,而LiDAR的精度为厘米级,因此我们可以推断姿态地面实况也是厘米级的精度。这也是我们在构建中等规模或室内外综合数据集时获得地面真实姿态的启发。
亮点:手持式LiDAR数据集、准确的姿态和3D地图地面实况、长轨迹、闭环。
4.3 基于RGB-D的移动定位与建图和三维重建分类
4.3.1 TUM RGB-D
TUM RGB-D,由慕尼黑工业大学于2012,已成为过去十年中最受欢迎的SLAM相关数据集。虽然使用RGB-D传感器捕获,但它也广泛用于纯视觉方法。值得注意的是,该数据集提出了一套评价标准和指标,成为迄今为止本地化评价的共识(将在第六节中说明)。
平台和传感器设置:有两个记录平台:手持和机器人,从而涵盖了广泛的运动。它们都配备了RGB-D传感器(表 XI 列出了属性),支持视觉和基于RGB-D的O/SLAM。
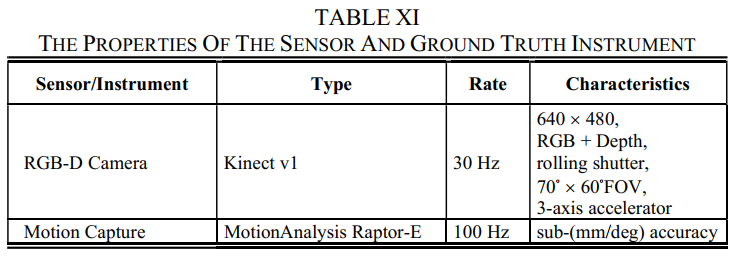
场景和序列:数据集记录在2个不同的室内场景中:办公室(用于手持设备)和工业大厅(用于机器人)。总共捕获了39个序列,有和没有闭环,支持SLAM验证。
Groundtruth:两个场景都被运动捕捉系统完全覆盖(表XI列出了属性),提供了高速率和准确的6D位姿ground truth,支持逐帧评估。为了便于使用,提供了一套自动评估工具。然而,这个数据集缺乏3D地图地面实况,这可能是唯一明显的弱点。
亮点:手持和机器人平台,高精度地面实况。
4.3.2 ICL-NUIM
ICL-NUIM 于 2014 年发布,是一个包含相机姿态和3D地图地面实况的合成数据集,通过建图评估补充了TUM RGB-D 数据集。
平台和传感器设置:与许多其他合成数据集(例如 TartanAir)不同,ICL-NUIM复制了真实世界的手持轨迹以使运动模式逼真。然后,模拟RGB-D传感器以在POV-Ray软件中捕获3D模型中的数据。
场景和序列:数据集模拟了2个室内场景:客厅和办公室。每个场景有4个序列,其中一个设计有一个小的循环轨迹以支持SLAM的使用。值得注意的是,噪声被添加到RGB和深度图像中以模拟真实世界的传感器噪声。这样的过程使数据非常逼真,这对之后的数据集来说是一个很好的启迪。如图15所示,渲染的质量甚至比一些后来发布的数据集更好,例如Tartan-Air。而遗憾的是,这两个场景覆盖的区域都比较小,最大序列长度只有11m。

Groundtruth:由于集合已经遵循了一些预先定义的路线,它们直接作为完美的ground truth。这些路线是通过在真实客厅中从手持数据中运行Kintinuous SLAM[80]获得的,因此非常逼真。对于办公室场景,还提供了3D模型作为3D建图地面实况。
亮点:真实的轨迹和数据,准确的groundtruth,3D场景ground truth。
4.3.3 InteriorNet
InteriorNet于2018年推出,是一个逼真的、大规模的、高度可变的室内场景合成数据集,显着补充了以前的合成数据集(例如ICL-NUIM)。
平台和传感器设置:为了克服先前数据集中轨迹真实性的弱点,InteriorNet提出首先生成随机轨迹,然后使用学习风格模型对其进行扩充以模拟真实运动。与ICL-NUIM的复制真实世界轨迹相比,这种方法更加灵活高效。至于传感器设置,除了RGB-D传感器外,它还模拟了IMU(可用噪声)、立体、事件等。值得注意的是,最终帧是通过快门打开和关闭渲染之间的平均值获得的,完成模拟运动模糊,优于许多其他数据集。

场景和序列:数据集在各种室内场景和布局中渲染,从世界领先的家具制造商收集,具有精细的几何细节和高分辨率纹理,从小型工作室到大型42室公寓。总共提供了15k个序列,每个序列有1k帧,以及许多具有挑战性的条件,包括各种照明、移动物体和运动模糊。渲染的图像非常接近真实世界,如图16所示。
Groundtruth:3D场景的groundtruth由预先设计的CAD模型提供。可以从模拟器中以完美的精度轻松访问相机姿势地面实况。
亮点:场景多样,序列丰富,数据真实,准确的ground truth,3D场景ground truth。
4.3.4 BONN Dynamic
Bonn Dynamic于2019年发布,是一款专门设计在现实世界中收集的高动态RGB-D数据集。提供相机姿势和3D建图地面实况以供评估。
平台和传感器设置:数据集是由手持载体使用RGB-D传感器(表XII列出了属性)捕获的,正是在这种情况下,由于6-DoF运动模式和滚动,很容易出现运动模糊快门。
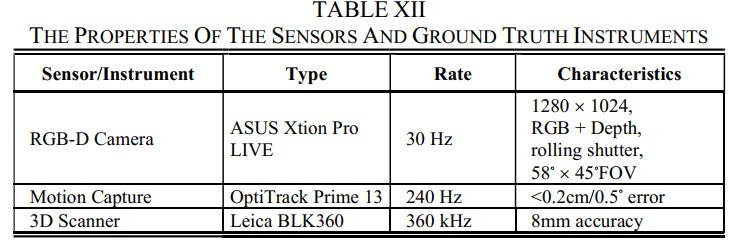
场景和序列:在高动态条件下共捕获了24个序列,例如操纵盒子和玩气球,这对运动估计具有挑战性,在静态条件下捕获了2个序列。图17中显示了三个动态帧,可以看出,动态还增加了对运动模糊的影响。

Groundtruth:姿态ground truth是由运动捕捉系统以高速率和准确度测量的。此外,还提供了3D场景地面实况,仅包含场景的静态部分,可以进行3D重建评估。表 XII 列出了地面实况仪器的属性。
亮点:高动态环境、财富序列、准确的ground truth、3D场景ground truth。
4.4 基于图像的三维重建分类
4.4.1 Middlebury
Middlebury于2006年公布,是顶级著名的多视图具有已知3D形状地面实况的立体数据集。提出了新的评估指标,以实现对映射准确性和完整性的定量比较,这在过去几十年中一直被社区主要使用。
平台和传感器设置:数据集是使用安装在斯坦福球形龙门机械臂上的CCD相机收集的。机械臂具有很高的运动灵活性,可以使相机在一米球体上的任何视点拍摄,在0.2mm和0.02度内具有相当高的定位精度。传感器的特性列于表XIII。
场景和序列:数据集很好地选择了两个目标对象进行研究:Temple和Dino(如图18左2部分所示),两者都是石膏模型。数据集中包含了许多具有挑战性的特征,例如尖锐和光滑的特征、复杂的拓扑结构、强凹面以及强和弱的表面纹理。对于每个模型,提供了3组数据(参见图18的右侧部分):半球视图(黑色)、环形视图(蓝色)和稀疏环形视图(红色)。

地面实况:相机姿势地面实况由高精度机械臂提供。然后根据准确的位姿,对于每个物体,将3D扫描仪获取的约200次单独扫描合并成一个完整的模型,该模型具有0.25mm的分辨率和优于0.2mm 的精度(如表XIII所列),用作3D重建基本事实。
亮点:3D模型ground truth,具有挑战性的模型,新颖的评估指标。
4.4.2 BigSfM
BigSFM项目是海量互联网照片数据集的集合,刺激了近年来许多大规模重建方法的发展。它提供了一种获得大量数据资源以支持大规模3D重建研究的开创性方法。
平台和传感器设置:这类数据集通常是在互联网上收集的,例如 Flickr 和 Google 图片,因此平台和传感器各不相同。大多数照片是通过手持智能手机或数码相机拍摄的,因此没有固定的分辨率或相机内在,另一方面,这也可以作为3D重建算法的挑战。
场景和序列:BigSFM包含各种社区照片数据集。一些著名的有罗马[83]、威尼斯[84]、杜布罗夫尼克[85]、巴黎圣母院[86]、地标[87]等。对于每个场景,可能有数百到数万张从大量视点拍摄的图像.一些具有代表性的图像和重建模型如图 19 所示。

地面实况:由于照片可以使用随机相机、由不同的人、在不同的条件下收集的无组织性,提供地面实况3D模型进行评估通常是不切实际的。作为替代方案,有时GPS标签和照片(如果可用)可用于验证相机姿势,指示重建质量,尽管不是那么准确。
亮点:大型场景、海量照片、网络资源。
4.4.3 Tanks and Temples
Tanks and Temples 于 2017 年出版,是一幅大型图像——基于3D重建数据集,涵盖室外和室内场景。最重要的贡献是提供了大规模和高质量的地面实况3D模型,这些模型在以前的数据集[83]、[89]、[90]中长期缺失。
平台和传感器设置:有两种用于捕获数据的设置,均使用稳定器和专业数码相机。如表十四所列,两台摄像机均以30hz拍摄4k视频,并且由于稳定器,图像质量很高,所有这些都可以实现高保真场景重建。

场景和序列:共提供21个序列(每个场景1个),分为3组:中级组、高级组和训练组,涵盖黑豹、游乐场、礼堂、法庭等场景(见图20),面积可达4295平方米。从礼堂模型中可以看出,由于规模、复杂性、照明和其他因素,高级组更具挑战性。
地面实况:3D场景地面实况是由工业级大型激光扫描仪(表 XIV 列出属性)通过重叠区域将多个单独的扫描配准在一起获得的。此外,使用地面实况点云[88]估计地面实况摄像机位姿。
亮点:3D场景ground truth,多重复杂度,大尺度场景,多样场景。
五、总览和对比当前数据集
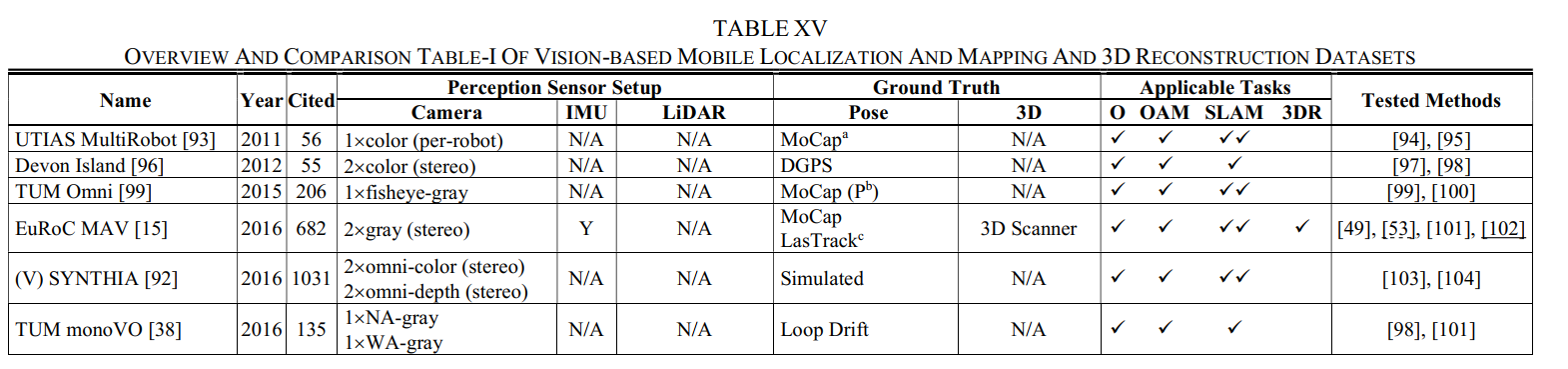
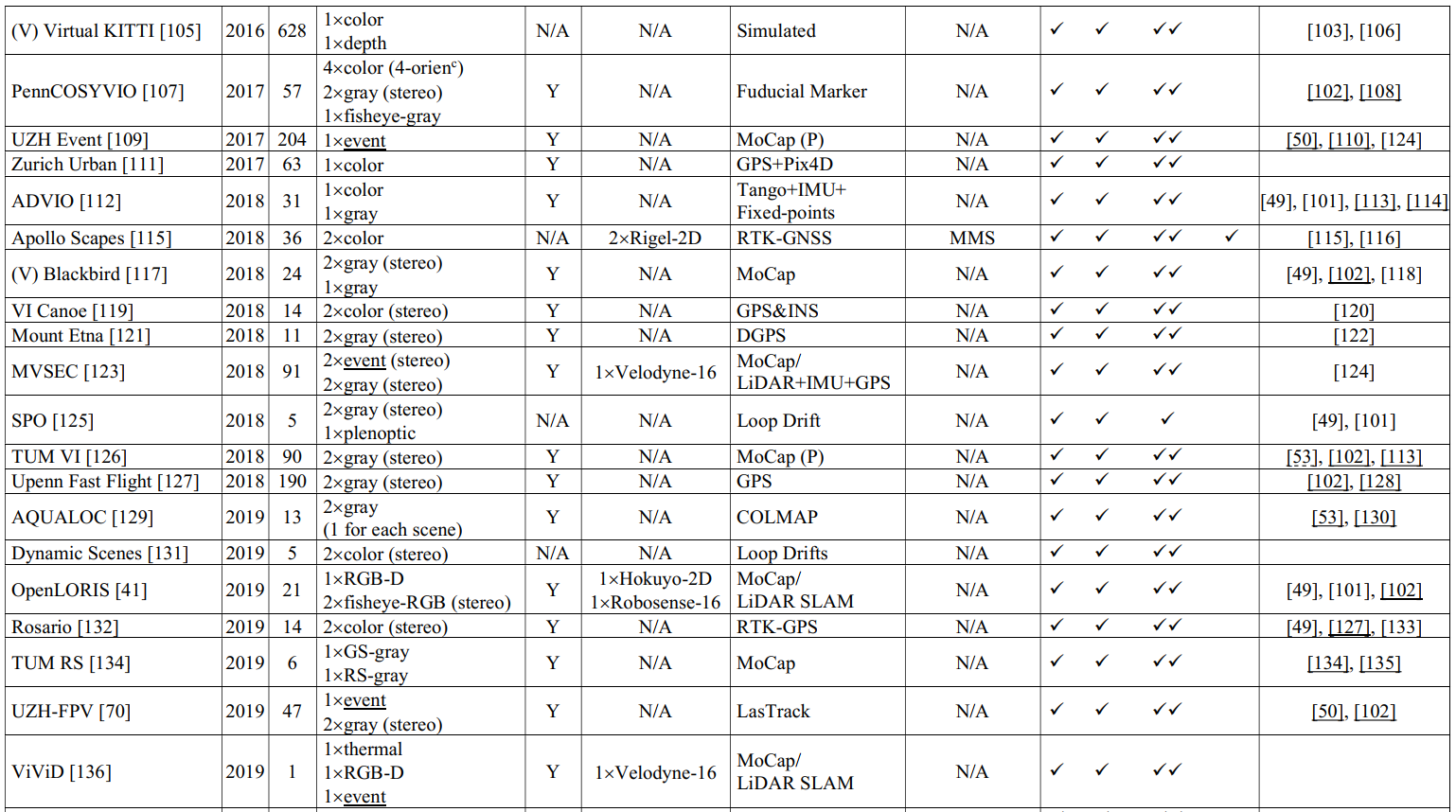
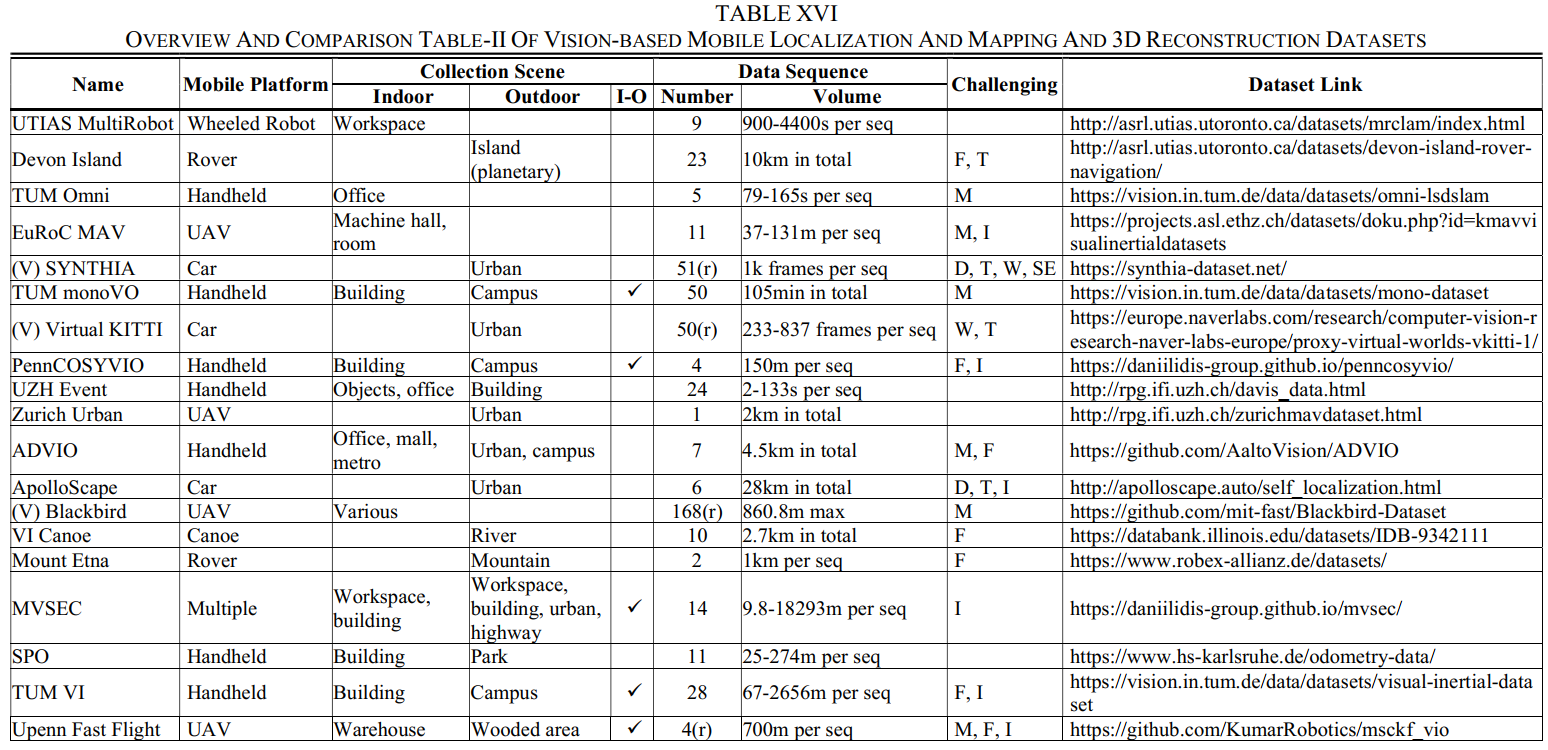
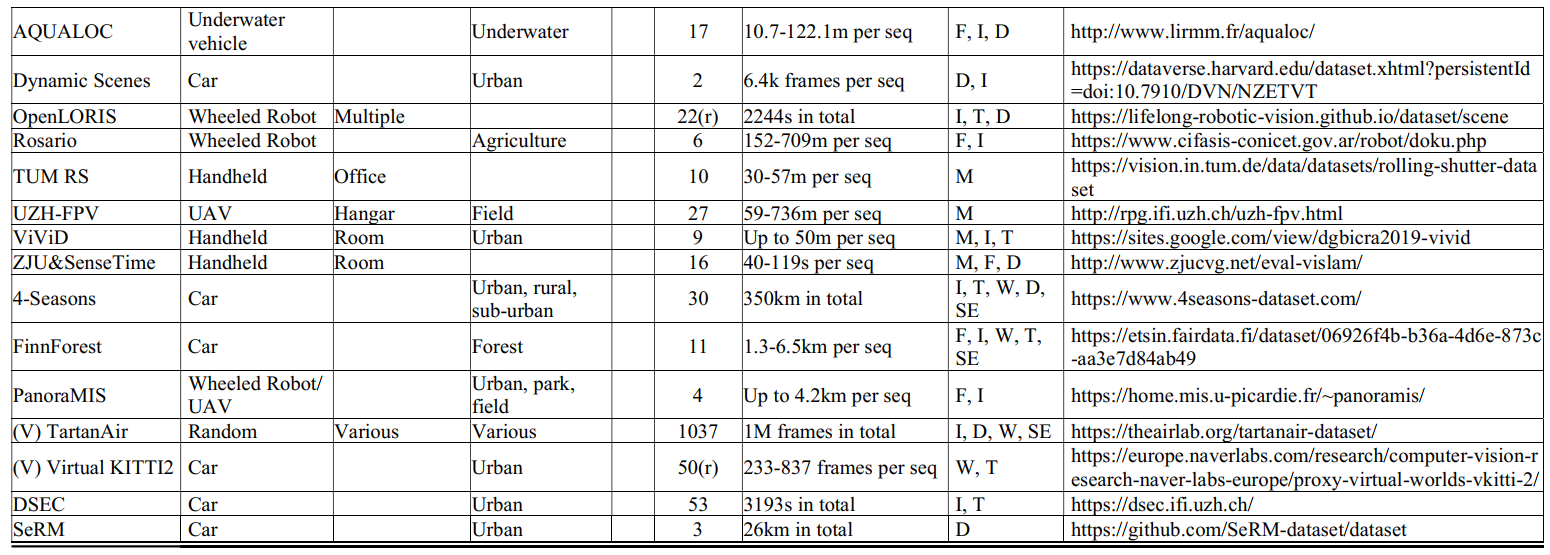
在本节中,基于提议的4大类,我们全面调查了97个SLAM相关数据集,并按类别提供了简洁但全面的概述和比较表(按时间顺序,对于同一年提出的几个数据集,我们按照字母表order)用作字典。我们涵盖了第II节中介绍的数据集的5个基本维度,并明确指定了每个数据集的适用任务和具有挑战性的元素。对于每一类数据集,提供了两个表格:在第一个表格中,除了数据集名称和发布/发布年份外,我们将引用数、感知传感器设置、ground truth、适用任务和测试方法进行排列,以供一般选择;在第二个表格中,我们对移动平台、采集场景、数据序列、挑战元素和数据集链接进行了排列,使选择更精细,访问更容易。每个维度的细节如下图所示。
名称:数据集名称(通常来自提供者)和相应的引用。如果一个数据集是通过合成和虚拟的方式收集的,那么我们将其标注为“V”。如果数据集是从网络上收集的,那么我们将其标注为“W”。
年份:数据集 的发布或发布年份。
CitedNumber:数据集的引用数(参考Google Scholar上的统计),可以部分表示利用率。我们在这里使用“部分”是因为:一方面,许多数据集没有自包含的出版物[83],然后引用与相应的算法论文一起共享;另一方面,一些数据集并不是专门为SLAM相关任务设计的[92],因此引用可能由其他用途贡献。
感知传感器设置:该维度列出了校准的感知传感器,分为3列:相机(我们也将RGB-D传感器放入此类)、IMU和LiDAR。相机列列出了具体的相机类型,例如彩色、灰度、事件、深度、RGB-D、全光、热和强度,以及一些需要强调的功能,例如立体、鱼眼、全向、广角(WA)、窄角(NA)、全局快门(GS)和卷帘快门(RS)。对于基于图像的3D重建数据集,我们指出相机类型是专业的、消费者的或随机的,以指示图像来源和质量。IMU列显示感知目的IMU是否可用,这意味着我们不会涵盖主要用于地面实况生成的IMU。LiDAR列显示LiDAR类型(2D或3D)和光束数量(例如,4、16、32和 64)。对于极少数带有雷达的数据集,我们也将其放在激光雷达一栏中,因为它们都是测距传感器。
基本事实:这个维度分为2列:姿势和3D。每列显示这种类型的基本事实是否可用,如果可用,将显示生成技术,指示准确性。
适用任务:该维度明确规定了每个数据集的适用任务。对于基于视觉、与LiDAR相关和基于RGB-D的类别,任务分为4列:O、OAM、SLAM和 3DR。如果pose ground truth可用,那么我们将在O、OAM和SLAM的空白处打“”;如果3D地面实况可用,那么我们将在3DR中给出“”。此外,基于所提出的分类法的定义,SLAM具有闭环或重定位特征,因此为了很好地支持它们,如果序列包含重新访问的地方,我们将给出另一个“”。但是,如果使用循环进行评估,我们不会给出“”,因为SLAM可以关闭循环并使结果产生偏差。对于基于图像的类别,列出了2列:SfM和MVS。我们将首先给SfM和MVS打一个“”,因为从大量的单个2D图像重建到3D已经是成功的。如果有任何一个姿势或3Dground truth可用,我们将在SfM的空白处再给出一个“”;如果 3D ground truth 可用,我们会给 MVS 另一个“”。
测试方法:该维度列出了在相应数据集上测试的一些方法,以期说明使用情况并提供有用的参考。限于篇幅,这些内容我们无法一一列举,可以通过数据库进一步索引。IMU融合方法(例如,VINS-mono[102])带有下划线。
移动平台:在这个维度中,给出了收藏的移动平台,表示不同的运动模式。
采集场景:该维度展示了数据序列的采集场景,分为室内、室外、室内外一体化(I-O)场景3列。室内外栏目列出了具体的场景,如城市、办公室、房间等。如果使用的场景类型较多,我们将填空为多种或多种。I-O列显示数据序列是否在室内和室外场景之间遍历(如果是,我们将在空白处打“”)。
数据序列:该维度分为两列:数量和体量。数字列列出了数据集的总序号,表示收集路径的多样性。为了避免误解,如果序列有重复的路线,数据集将被注释为“r”。体积列显示数据序列的长度、持续时间或帧数。
挑战元素:在这个维度中,列出了数据集中的挑战元素,这些元素可能由运动模式、场景类型和场景条件导致。总体而言,运动模式引起的元素会被标注一个“M”,主要包括快速运动、纯旋转、运动模糊和激光雷达失真;对于场景类型产生的元素,即特征和结构的弱、重复、干扰,我们分别标记为“F”和“S”;对于场景条件,我们将动态对象标记为“D”,变化、坏和变化的照明标记为“I”,各种恶劣的天气标记为“W”,不同的时间段标记为“T”,多个季节标记为“SE”.对于基于图像的数据集,我们将额外将复杂几何标记为“C”,将大规模序列(每个超过1k 帧)标记为“L”。
数据集链接:数据集的网络链接。可以通过链接轻松访问详细信息并下载数据集。
**数据选择指南**
我们建议数据集用户遵循我们的指南,使用我们的“字典”(下表)选择有用的数据集。
- 确定你的算法属于哪个大类(参见第三节)并进入相应的会话(A~D)。例如,如果您正在构建基于视觉的 SLAM 相关算法,则转到会话 A、B 和 C。
- 考虑您正在构建的特定任务(请参阅第 III 节),并查看适用的任务列(O/OAM/SLAM/3DR 或SfM/MVS)以找到可用的数据集(通常您可以在此步骤中找到许多候选者)。
- 考虑您要使用的特定传感器(相机、立体、事件、IMU、LiDAR等),并查看感知传感器设置列以进一步找到一些合适的数据集。例如,如果你想用IMU融合构建立体视觉算法,你可以定位EuRoC、Blackbird、Complex Urban等;如果你想要基于事件的视觉数据集,你可以定位UZH-event、MVSEC等。请注意,一些具有IMU数据和6-DoF运动的数据集可能难度更高。
- 考虑您要评估的指标(姿势或 3D 结构),并查看地面实况列以选择具有预期地面实况质量的数据集(参见第 II-B-5 节)。例如,如果你想研究 VO 的逐帧精度,那么最好选择带有 MoCap 或 LasTrack 的数据集。
- 选择您期望的移动平台(它们具有不同的运动模式,请参阅第二节)。
- 选择您期望的测试场景(室内、室外、室内-室外,或者特别是办公室、校园......)。
- 选择您想要的数据量(每个序列 100 帧或数千帧)。
- 在数据集中选择您预期的具有挑战性的元素(质地较弱、光照不佳、恶劣天气等)。
- 前往数据集链接获取详细信息并下载使用。
注意:除了“以需求为导向”的选择外,从算法测试的角度来看,最好选择多个数据集(不同平台、不同场景等)进行评估,以避免在某些基准上出现过拟合和隐藏缺陷。我们稍后将在第 VI-C 节分析互补使用的必要性。
接下来就是表格按照上面描述的A|B|C|D四大类的表格,这里就不在贴了。感兴趣可以参考下原文。文章到这其实对一个刚入门SLAM的来说还是很不错的,能够了解SLAM一些数据集,以及它们的收集方法,总结的很全面,很佩服作者的总结能力。下面就直接介绍下一部分了评估准则,一个到哪里都极其重要的话题。

六、评估准则
尽管可靠的ground truth是决定性的前提,但评估标准对于基准测试也是必不可少的。它们在正确量化和公平比较算法性能,识别潜在的故障模式,从而寻找突破口方面发挥着重要作用。在本节中,我们将重点关注2个指标:定位和建图,它们是SLAM相关问题的主要功能。其他一些非功能性问题,例如耗时、CPU和RAM使用以及GPU要求,尽管已经通过一些努力进行了调查[234]、[235]、[236],但由于不成熟和利用率低,将不会被涵盖。在C部分,我们比较了2个不同基准的最佳结果,以说明互补使用的必要性。
6.1 定位评估
由于早些年大规模测量技术的限制,获得地面实况3D地图相当困难。因此,通过检查定位性能来评估SLAM相关算法已经有很长一段时间了。最广泛使用的评估指标可能是TUM RGB-D基准中提出的两个指标——相对姿态误差(RPE)和绝对轨迹误差(ATE)[12]。
相对位姿误差(RPE)研究运动估计系统在固定时间间隔Δ内的局部精度。如果估计的轨迹位姿定义为P1,...,Pn属于SE(3)并且地面真实位姿定义为Q1,...,Qn属于SE(3),则时间步长i的RPE可以是定义为:
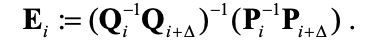
考虑到一系列n个相机姿势,可能有(m = n – Δ)个单独的RPE。那么如何衡量整个轨迹上的性能呢?TUM RGB-D基准建议计算平移分量所有时间间隔的均方根误差(RMSE):

其中 trans(Ei) 是指RPE的平移分量。请注意,由于欧几里得范数的放大效应,RMSE可能对异常值敏感。因此,如果需要,评估均值或中值误差作为替代方法也是合理的。虽然这里只测量平移误差,但旋转误差也可以在内部一起反映。此外,时间间隔Δ的选择可能会随着不同的系统和条件而变化。例如,可以将Δ设置为1以检查实时性能,从而产生每帧漂移;对于通过前几个帧进行推断、执行局部优化和专注于大规模导航的系统,依靠每个单独帧的估计是没有必要也不合理的。然而,直接将Δ设置为n是不合适的,因为它对早期旋转误差的惩罚远大于接近尾声的情况。相反,建议在广泛的时间间隔内对RMSE进行平均,但为了避免过于复杂,依赖固定数量间隔的近似值也可能会达到折衷。
绝对轨迹误差(ATE)通过将估计的轨迹与地面实况进行比较以获得绝对距离来测量全局精度。由于2条轨迹可能位于不同的坐标中,通过刚体变换S将估计的姿势P1:n 映射到地面真实姿势Q1:n的对齐是先决条件。那么时间步i的ATE可以计算为:
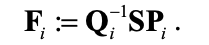
与RPE类似,平移分量所有时间指标的均方根误差(RMSE)也被提议作为ATE的一种可能指标:

需要注意的是,ATE只考虑平移误差,但实际上旋转误差也会导致错误的平移。与RPE相比,ATE具有直观的可视化来检查算法的实际意外区域。图21显示了ATE的可视化示例以及ATE和RPE之间的比较。如比较所示,由于旋转误差的影响更大,RPE可能略大于ATE。

有许多主流数据集[126]、[41]、[134]与上述共享相同的评估标准,或者基于相同的机制开发一些扩展版本。例如,KITTI Odometry benchmark21扩展了RPE以研究旋转误差,从而获得更深入的洞察力;TartanAir将成功率(SR)定义为未丢失帧与总序列长度的比率,因为丢失跟踪无法计算RPE和ATE。
然而,正如我们在第二节中提到的,并非所有数据集都能够提供完整的地面真实轨迹[126]、[38]。在这种情况下,通常开始和结束段是可用的,然后在对齐之后,仍然可以评估RPE和ATE。
6.2 建图评估
在现有的SLAM算法出版物中,很少会遇到对建图性能的评估。但实际上,3D重建的评价标准由来已久,主要来源于Middlebury数据集[13]。将ground truth几何表示为G,重建结果表示为R,通常需要考虑两个指标:准确性和完整性。
准确率通过计算对应点之间的距离来衡量R与G的接近程度,通常通过找到最近的匹配来确定。如果重建或地面实况模型采用三角形网格等其他格式,则可以使用顶点进行比较。当G不完整时会遇到一个问题,导致最近的参考点落在边界或远处。在这种情况下,提出了一个填充孔的版本G'来计算距离,并且与修复区域匹配的点将被打折。图22很好地说明了原理。

完整性研究了R对G的建模程度。与准确性指标比较R与G相反,完整性衡量G到R的距离。直观地说,如果匹配距离超过阈值,我们可以认为没有对应的R 上的点,因此G上的点在逻辑上可以被视为“未覆盖”,如图22所示。
为方便评估,ICL-NUIM提出利用开源软件CloudCompare22计算重建模型与地面实况模型之间的距离。可以获得五种标准统计量:平均值、中值、标准、最小值和最大值。评估演示如图 23 所示。

6.3 数据集互补使用
如第V节所示,SLAM相关数据集可以在多个维度上发生变化,这会对算法性能产生不同的影响(运动模式、场景外观和结构等),并导致许多具有挑战性的效果。然而,正如引用统计数据所揭示的那样,数据集的使用存在很大偏差,这可能会导致某些基准的过度拟合和隐藏的缺陷。为了有效地说明这种风险,这里我们选择使用最广泛的KITTI里程计基准(仅显示基于视觉的方法)和UZH-FPV 基准(IROS 2020 比赛的结果),使用提出的RPE指标对TOP 7结果进行比较通过KITTI基准测试(如表 XXIII 和表 XXIV 所示)。这两个数据集具有完全不同的平台、场景、序列,并且在引文方面存在巨大差异(KITTI 6341 vs. UZH-FPV 47)。
可以看出,两个基准上的TOP结果有着巨大的反差:与KITTI相比,UZH-FPV基准上的平移误差大一个数量级,旋转误差大两个数量级。即使在UZH-FPV的方法都融合IMU数据的情况下也会发生这种情况,而KITTI列出的方法仅使用纯视觉数据。当然,并不是所有的数据集都会在算法性能上形成如此大的对比,但事实是结果会有所不同。因此,从这个角度来看,人们不应该对某个基准过于自信,因为许多缺陷可能被隐藏起来。但这绝不意味着应该放弃产生好分数的数据集:一方面,算法的机制确实各不相同,不能确保算法不会在“更容易”的数据集中遇到某些挑战(尤其是基于学习的方法);另一方面,从应用的角度来看,不同场景下的结果都是有意义的。为此,我们不鼓励根据基准结果在数据集选择上产生偏差(大多数数据集甚至还没有经过全面测试和评估),而是应该以互补的方式使用数据集,并利用不平衡结果的优势寻找突破口。
七、分析与讨论
正如论文中反复提到的,SLAM相关数据集相互补充,共同形成数据集社区。因此,除了了解数据集及其差异之外,研究整体还有另一个重要意义。因此,在第五节的概述和比较的基础上,本节进行了整体研究,并给出了数据集和评估标准的当前局限性和未来方向。最后,我们讨论了如何为SLAM社区构建全面的数据集。
7.1 数据集局限与未来
对于数据集的局限性和方向,我们主要选择7个维度进行分析和讨论,分别针对移动平台、传感器设置、目标场景、数据序列和ground truth 5个基本维度和最近的2个热点话题,即具有挑战性的元素,以及虚拟和合成数据集。
7.1.1 运动平台
对于目前的局限,首先是移动平台的多样性不足。图24显示了不同移动平台在每个数据集类别中的分布(我们没有显示基于图像的类别,因为通常在收集时可以确保良好的图像质量,例如使用稳定器,因此运动模式不会影响太大)。可以看出,基于视觉的类别分布相对均衡,而与激光雷达相关的类别主要利用汽车和轮式机器人(均具有3-DoF运动),而基于RGB-D的类别主要利用手持和轮式机器人。虽然这部分是应用场景造成的,但从算法开发的角度来看,运动模式多样性的不足将潜在地隐藏缺陷。另一个限制是,大多数数据集仅使用单个移动平台进行收集。虽然它们可以以互补的方式使用,但如果要研究不同运动模式的影响,进行横向比较确实是不公平的。
对于未来的方向,首先,鼓励更多样化的平台,例如船[119]、摩托车[123]和背包[177]。其次,我们预计在LiDAR相关数据集中会有更多的6自由度平台,例如无人机和背包[9]越来越多地用于移动测量并且急需验证。第三,强烈建议在每个场景和路线中部署各种平台,以实现公平的横向比较。
7.1.2 传感器设置
考虑到主流传感器可以在时间和空间上进行有效校准,传感器设置的限制主要是由于数量和类型的不足。利用多个传感器和模态融合是提高系统精度和可靠性的必然趋势,尤其是立体视觉和IMU融合方法,已被广泛采用并被证明是有效的。然而,如第V节所示,许多数据集仅使用基本必需的传感器:TUM MonoVO [38]仅配备单目相机,大多数 RGB-D数据集没有IMU数据。此外,目前,基于事件的视觉正在获得快速发展,并在稳健和高速机器人技术中发挥着至关重要的作用,同时相关数据集严重短缺,需要更多的投入。
未来,我们鼓励每个数据集配备冗余和多样化的传感器(例如事件和热传感器),以实现可能的开发和比较。然后具体来说,我们希望未来的每个数据集都至少设置立体相机和IMU,它们无处不在且价格合理。此外,事件数据集还需要更多的专门工作,不仅是现实世界的集合,还要将正常的视觉数据转换为事件(见图25)。

7.1.3 收集场景
对于目前的限制,首先,场景类型的多样性还存在不足。例如,只有3个数据集[41]、[112]、[187]涵盖了购物中心,这是高度动态的,在现实生活中很常见。其次,室内外一体化场景严重缺乏。而在日常生活中,机器人或人类来回穿梭是很常见的。第三,具有大规模室内场景的数据集仍然不够。室内场景多为办公室和房间,无法满足工厂机器人、BIM等应用的需求。
因此,对于未来的方向,首先,希望有更多多样化的场景来补充当前的数据集,尤其是购物中心、废墟和工业园区等典型场景。其次,迫切需要更多的室内外一体化场景来研究无间歇导航。第三,预计会有更多的大型室内场景,如大型建筑和大型厂房。
7.1.4 数据序列
数据序列的限制主要是由于序列号和单一会话的多样性和长度的不足。例如,Zurich Urban[111]只收集了大规模城市环境中的单个序列;ICL-NUIM[79]每次会话仅遍历2m-11m的长度,与其他室内数据集相比,这甚至太短了。这样的数据集没有充分利用场景,浪费了更彻底测试的机会。
为此,希望在未来的数据集中充分利用场景,即收集尽可能多的数据序列并遍历各种更长的路线。这在大规模环境中尤其可行。此外,我们希望每个数据集都发布会话长度统计信息。
7.1.5 Ground truth
对于位姿ground truth,限制主要在于某些数据集的准确性低和覆盖不完整。例如,Complex Urban [37](在户外 GNSS 拒绝区域)必须使用SLAM来生成基线;TUM VI [126](远程室内和室外综合)仅在开始和结束段中具有地面实况数据。对于3D地面实况,主要限制是大多数数据集(62/97)没有提供此类数据,也有一些数据集使用基于SLAM的算法生成3D基线,这可能不太准确。
在未来,我们预计可能会出现用于生成位姿地面实况的新技术和方法,尤其是那些在室内和室外都具有多功能性的技术和方法。对于3D结构,我们希望未来的数据集尽可能提供基本事实,以实现建图评估。此外,预计会有更多类型的ground truth,例如深度图像和语义标签。
7.1.6 挑战因素
迄今为止,已经在数据集中识别并嵌入了许多具有挑战性的元素,被证明会动摇算法的性能(图 26 显示了 TartanAir [72]上的一些失败案例)。但在一些明确设计的元素上仍然存在不足,例如密集的动态、多时隙、极端天气和不同的季节。例如,在RGB-D类别中,只有InteriorNet[81]和Bonn[82]设计了带有移动对象的序列,而这种情况在现实世界的部署中很常见。
未来,首先,预计会有越来越多的具有密集且具有各种挑战性元素的数据集,尤其是上面提到的那些。然后,非常需要对算法的故障模式进行严格的研究,这将有助于量化挑战的影响并识别更多此类元素。
7.1.6 虚拟合成数据集
合成数据集开辟了一条新途径来处理现实世界数据集的缺点,例如复杂的收集过程、有限的场景和序列以及不准确的基本事实。对于此类数据集,其局限性主要源于数据现实的不足。首先,渲染的图像有时仍然很不真实[72],[92]。其次,模拟真实世界的传感器延迟和噪声仍然非常罕见,例如相机运动模糊和LiDAR运动失真,这将使数据过于理想。
因此,在未来,考虑到合成数据集可以在各种场景下生成无限的序列,尤其是具有完美的ground truth,鼓励更多这样的数据集来弥补一定的差距,但具有更高的数据真实性。
B 评估局限与方向
对于评价标准的局限性和方向,我们主要选择3个维度进行分析和讨论,分别在2个功能维度,即定位和建图,以及1个非功能维度,即硬件消耗。
1)定位评估
随着过去几年的广泛实验和时间的考验[240]、[241]、[242],定位的评价标准相对成熟,主要包括ATE、RPE和相关的变体。然而,这样的维度仍然非常有限,因为SLAM任务包含许多步骤,例如初始化、闭环和重定位。为此,未来预计会有更加多样化和细化的指标,如初始化的准确率和速度、重定位的准确率和成功率、闭环的检测率[41]、挑战下的定位准确率在苛刻条件下[243]。这些维度对于深入、全面地考察一个算法必将具有重要意义。
2)建图评估
正如文献中所反映的,在SLAM中很少测量地图性能,而有时,构建准确的地图甚至比定位更重要,例如路径规划、避障以及制作高清(HD)地图和轻量级地图语义图[144]、[244]作为用于定位的虚拟传感器。此外,现有标准仅研究3D几何[79]、[13],而忽略了其他维度。因此,在未来,算法应该在建图中得到广泛的评估,并且社区需要结合几何、纹理和语义标签的新标准。
3)硬件消耗评估
目前的评价标准和算法主要集中在功能层面——定位和建图,忽略硬件消耗,这是从实验室到应用过渡的一个决定性因素。因此,在未来,预计会有更多这样的标准被提出并被广泛采用,例如CPU和RAM使用、GPU要求和时间消耗[234]。这些指标决定了一个算法是否可以在现实世界中广泛部署,即是否可以轻量级嵌入,是否可以实时工作,以及总成本是否合理。
C 如何构建综合数据集
综合数据集是算法改进和突破的动力。在2009年ImageNet发布之前[20],没有人在10年的旅途中想象过人工智能可以像今天这样:物体分类的准确率从71.8%上升到97.3%,超过了人类的能力,证明了数据集可以将算法的极限推到另一个层次[245]。然而,与机器学习相比,收集SLAM数据集更加复杂和耗时,因此在SLAM领域构建ImageNet几乎是不可能的。
在这种情况下,我们主要提倡两种方法来弥合差距。一是开发成熟的技术和管道来生成高现实的合成数据集。这正是许多数据集正在努力做,例如 Replica(使用 Habitat-Sim)[213]、[246]和 InteriorNet[81]。此外,令人惊讶的是,从RTX20系列开始,NVIDIA 已经发布了带有RT Cores的光线追踪GPU[247]。这种硬件级的光线追踪技术可以让用户实时获得高质量的照片渲染(见图27,RTX3090渲染的 Red Dead Redemption 2 游戏截图),带来更方便和无限的方式生成真实的SLAM数据集。

二是建立一套数据集标准,呼吁将数据集(如不同平台、不同场景、不同天气等)分发给社区,最终将符合标准的数据集公开发布。这样,个人和机构都可以加入收藏并享受反馈。
值得注意的是,模拟不能代替真实世界数据的实验是一个原则问题,特别是对于像SLAM这样与生命安全问题密切相关的任务。因此建议联合使用:使用合成数据集作为初步测试目的,验证某个假设,然后在得到支持性结果后,可以提出相应的真实数据集。我们相信在接下来的几年里,数据集社区可以见证繁荣并显著地推动SLAM 技术。
8 结论和未来工作
本文是第一个专门针对SLAM相关数据集的综合调研。我们将SLAM相关的数据集视为一个研究分支,而不仅仅是一个工具,因此除了数据集的正常调研维度外,我们还引入了收集方法,这将我们的调查与许多其他调研区分开来。通过提出一系列具有凝聚力的主题,解决了两个主要问题:一个是消除对数据集的偏见使用,并确保全面、正确和高效的选择;二是降低门槛,促进数据集研究的未来方向。我们相信,通过充分利用现有数据集并开发新的数据集,SLAM相关算法可以很快实现关键突破。此外,为了保持本文的优势,我们将在GitHub上定期更新数据集字典和评论:
https://github.com/robot-pesg/SLAM_Datasets_Survey_JAS。
论文本身已经是全面而具体的,很好地完成了它关于数据集的任务,但随后出现了另一个关键主题,即“数据集-算法-评估”的研究。尽管每个数据集中都指出了许多定性的挑战元素,但如何量化这些元素?它们对算法的定量影响是什么?我们不想让这个调研过于拥挤,这可能会导致发散性结构,相反,我们认为这些问题值得一篇独立的研究论文,这正是我们未来几个月的主要目标,针对大量不同的算法进行全面评估数据集。此外,我们还在典型、大规模和室内外集成场景中构建一个新的视觉-LiDAR数据集,同时具有准确的定位和建图地面实况(ground truth)。
9 some thing to say
第二篇结束了,如前一篇的仁兄所说,基本都是机器翻译,本想自己翻译,可以翻了几句后,发现现在的机器翻译已经超越我的能力,这也得益于人工智能的高速发展。也有比较纠结的地方,比如ground truth 我一直理解为真实数据,可是机器一会地面状况,一会基本事实,搞得我有点蒙,我能做得在能力范围内尽可能减少错误出现。写着玩意的目的:一是自己做点事情,只是证明自己看过,由于水平有限,还未形成自己的见解,故莫太多期望;二是将自己认为不错的论文分享出来,让自己感觉SLAM这条路上不是在孤军奋战,小白上路~。