A. Treat Model
我们专注于协作数据共享,其中K个数据提供者(所有者)和一个数据请求者一起工作以完成数据共享任务。 数据提供者和数据请求者被认为是不诚实的。 拟议的机制容易受到三种威胁。 首先是所提供数据的质量。 不诚实的提供者可能会向请求者提供有偏见和不准确的结果,从而降低整个共享数据的可用性。 第二个是数据隐私。 提供者和接收者可能会尝试从共享数据中推断其他人的私有数据,这可能会导致数据提供者不必要的敏感数据泄漏。 如果一组参与者试图推断其他参与者的数据,则存在共谋威胁。 第三是数据权限管理。 原始数据共享后,数据所有者将失去对这些数据的控制权,不诚实的参与者可能会将数据共享给其他未授权实体
B. Our Proposed Architecture
我们提出的数据共享架构如图2所示。提出的系统包括两个模块:许可区块链模块和联合学习模块。 许可的区块链通过其加密记录在所有最终IoT设备之间建立安全连接,加密记录由配备有计算和存储资源的实体(称为超级节点,例如基站和路边单元)维护。 我们许可的区块链中有两种交易类型:检索交易和数据共享交易。 出于隐私考虑和存储限制,我们仅使用许可的区块链来检索相关数据并管理数据的可访问性,而不是记录原始数据。 此外,许可的区块链记录所有数据共享事件,可以跟踪数据的使用情况以进行进一步审核。
Adam Richardson
D. Consensus: Proof of Training Quality (PoQ)
将数据共享问题转移到模型共享中可以为数据共享带来很多好处。仅共享数据模型而不共享原始数据,有助于保护数据所有者的隐私。此外,机器学习数据模型更有效地为新的共享请求提供了所需的信息。
**直接使用现有共识(例如PoW)进行数据共享会带来高昂的计算和通信资源成本,或者对数据共享的贡献有限。**为了解决这个问题,我们提出了一种联合学习授权的共识-PoQ协议。 PoQ将数据模型训练与共识过程相结合,可以更好地利用节点的计算资源。对于特定的数据共享请求,我们通过在区块链中检索请求的相关节点来选择共识委员会的成员。该委员会负责推动达成共识的过程,并负责为请求的数据学习数据模型。联合学习的目的是训练全局数据模型M,该模型可以为数据共享请求Req提供有效的响应M(Req)。可以使用一系列机器学习算法来训练模型M,例如随机树,随机森林和梯度提升决策树(GBDT)。构建完成后,即使查询是新鲜的,模型M仍可以生成针对数据查询的答案。
2)基于培训质量的共识:
**共识过程由所选委员会根据协作培训的工作执行。**委员会节点是所有参与者的子集。通过仅向委员会节点而非所有节点发送共识消息来减少通信开销。但是,节点数量的减少也使达成共识更具挑战性。为了平衡开销和安全性,我们提供了数据共享共识方面的培训工作证明。**将根据经过训练的模型的质量选择委员会负责人。**由于每个委员会节点都训练本地数据模型,因此应在共识过程中验证和衡量模型的质量。**我们利用预测准确性来量化训练后的局部模型的性能。**更具体地,在训练期间的分类中,准确度由正确分类的记录的分数表示。在执行回归任务时,准确性是通过平均绝对误差(MAE)来衡量的
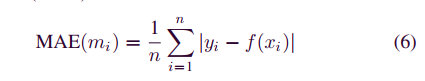
当共识过程开始时,届时具有最低MAEu的委员会节点将通过基于MAE的投票选举为委员会负责人。领导者负责推动参与节点之间的共识过程。,领导者收集开始时收到的所有交易,包括最终数据模型M,以形成一个块Bk =(Hk,tm i,M),其中Hk是Bk的头。然后,领导者将毕先生广播给委员会所有成员以供批准。除了对区块进行常规验证(例如,头格式,区块大小和时间戳)外,委员会节点还通过验证模型交易轨迹来审核区块,就像验证节点所做的以验证比特币中的交易金额一样。每个验证节点为每个模型事务和MAE(M)计算MAE(mi)。如果计算出的MAE在一定范围内,则会将批准发送给领导。如果每个委员会节点都批准了包含所有交易的数据块,则组长将使用其签名签名的数据块发送到所有节点。然后,记录将存储在防篡改的区块链中。基于共识的培训工作过程如图8所示。