有时候看到网页中的PPT特别好,在线阅读加载太慢,这个时候就可以查看网页规律,把他下载下来慢慢看。你说是不?O(∩_∩)O哈哈~
(1)查看翻到下一页时,HTML的网页变化。http://www.doczj.com/doc/1ae34adebf1e650e52ea551810a6f524cdbfcb2e-83.html,其实,就是最后的页数有发生变化。这和PPT就有83页,所以,你在网页导航中修改这个数字,就可以发现,也可以到指定页面。(注意我用红色横线标记处的地方)
(2)找到这个图片链接。不知道怎么操作,可以看我的另外一篇文章python自动化办公之爬取HTML图片写入PPT实战添加链接描述,这里不过多赘述。

(3)现在开始写代码,批量爬取图片。我们可以发现所有的图片都是src="",这个时候要使用正则表达式,匹配到所有的图片链接。以下为这一步的所有的代码:
import urllib
import re
import time
#封装获取网页所有信息的函数
def getHtml(url):
res = urllib.request.urlopen(url) #调用urlopen()从服务器获取响应界面
html = res.read().decode('utf-8') #对返回的响应数据解码,并赋值给html
return html
#封装获取满足正则表达式的图片地址
def getImg(html):
imglist=re.findall('src="(.*?)"',html)[2]
return imglist
这里需要注意imglist=re.findall(‘src="(.*?)"’,html)[2],这个地方我们取的最后一个元素,因为最后一个元素才是我们需需要的图片路径。
(4)我们在前面说过了,每一页PPT对应一个HTML,所以这里要用循环,来模拟翻页的动作,之后再提取该页中的图片。
for w in range(1,84,1):
k=w
print(w)
#根据网址的规律,通过改变网址来下载所有的照片(这个得自己去看看网址哦)
html = getHtml("http://www.doczj.com/doc/1ae34adebf1e650e52ea551810a6f524cdbfcb2e-%s.html" %k)
#下载照片
try:
urllib.request.urlretrieve("http://appwk.baidu.com/naapi/doc/"+getImg(html)[5:],"/root/data_warehouse/test/number%s.jpg" %k)
except:
print ("some problem!")
print ('finish!')
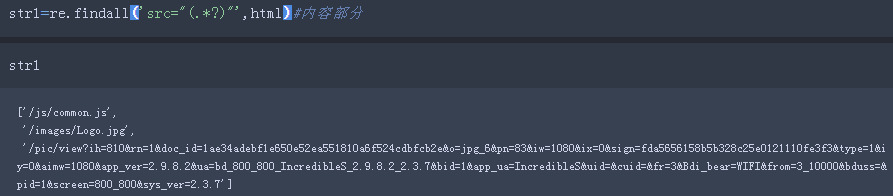
这一步也需要注意一个地方,我们在上一步提取的图片路径,直接使用还是有问题的?为什么呢?
下图为我们用代码获取的图片地址:

再对比一下我们通过【复制图片地址】获取的内容:
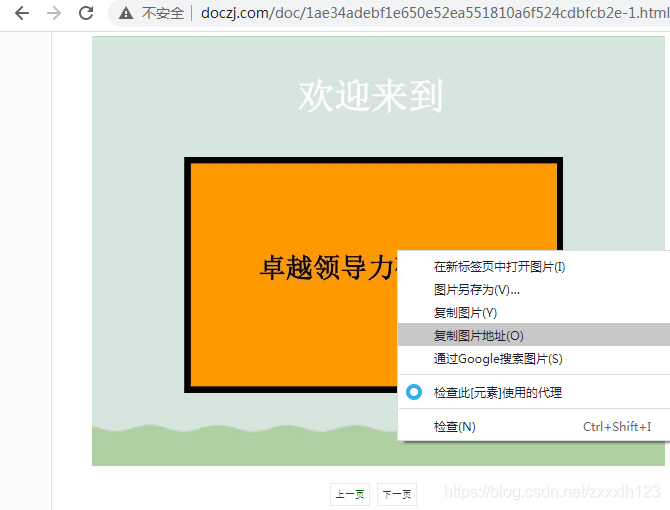

我们发现的了不同,“http://appwk.baidu.com/naapi/doc/”+getImg(html)[5:],这句代码就是把这个图片地址修正过来。
(5)将图片存储到指定路径下。

**整理内容不易,走过路过觉得课程内容不错,请帮忙点赞、收藏!Thanks♪(・ω・)ノ****如需转载,请注明出处