python-docx库的安装
命令行窗口下输入下面代码
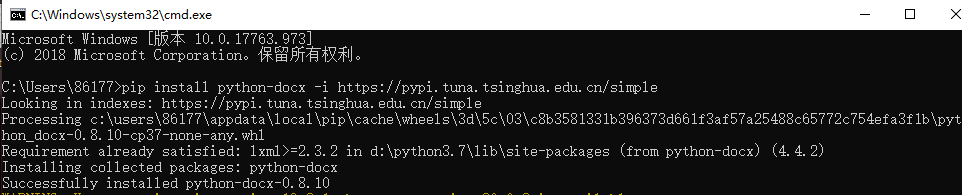
pip install python-docx -i https://pypi.tuna.tsinghua.edu.cn/simple
–> 输出结果为:
python-docx库的导入
不需要使用全称,直接使用下面代码就可以了
import docx
检验是否导入成功

Word文档结构
Documeent: 文档

Paragraph: 段落

Run: 文字块(三种不同的样式就是三个文字块)

读取Word文档内容
doc.paragraphs 得到的是一个列表,包含了每个段落的实例
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('这是一个文档.docx')
print(doc.paragraphs)
–> 输出结果为:
[<docx.text.paragraph.Paragraph object at 0x02F1FE30>, <docx.text.paragraph.Paragraph object at 0x02F1FFF0>]
paragraphs.text 得到该段落的文字内容
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('这是一个文档.docx')
for paragraph in doc.paragraphs:
print(paragraph.text)
–> 输出结果为:
这是第一段内容
这是第二段,加粗,斜体
paragraphs.runs 得到一个列表,包含了每个文字块
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('这是一个文档.docx')
paragraph = doc.paragraphs[1]
runs = paragraph.runs
print(runs)
–> 输出结果为:
[<docx.text.run.Run object at 0x03A7FF10>, <docx.text.run.Run object at 0x03A7FF50>, <docx.text.run.Run object at 0x03A7FF90>, <docx.text.run.Run object at 0x03A7FFD0>]
run.text 得到该文字块的文字内容
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('这是一个文档.docx')
paragraph = doc.paragraphs[1]
runs = paragraph.runs
for run in runs:
print(run.text)
–> 输出结果为:
这是第二段,
加粗
,
斜体
综合应用
编写一个Python程序,要求
(1)打开文件"Netease Q2 2019 Earnings Release-Final.docx"
(2)计算关键词profit出现的次数
参考代码
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('Netease Q2 2019 Earnings Release-Final.docx')
ls_1 = []
count = 0
for paragraph in doc.paragraphs:
if 'profit' in paragraph.text:
count += 1
#print("profit关键词出现:{}次\n".format(count))
#print(paragraph.text)
ls_1.append(paragraph.text)
print(count)
–> 输出结果为:12
检验
直接打开Word文件,使用查找功能,寻找profit这个单词,发现这个单词出现了25次,但是这里把Profit和profits都检索出来了,还有一些profit关键词是存在表格里面的,最后通过计数发现总共有17个‘profit’关键词(这里指的是在文本内容中的,不包含表格里面的和大小写及复数的情况)

调试
由于当前的学习,只学习到了提取Word文件中的文本内容,并未学习到提取表格的内容,所以表格里含有关键词‘profit’的进行忽略,而为什么进行文本内容的提取关键词少了一些,经过调试发现,并不是一段里面只有一个“profit”,有些段落里面有多个,所以这里就造成了数量的减少,这里进行了两种方式的尝试
第一种方式、按照paragraph的文字内容进行统计
调试过程中,生成的ls_1列表就是包含了profit关键词的所有段落,然后再将所有的段落合并成一段lst,最后在对lst里面的单词进行一一匹配,如果单词是profit就+1
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('Netease Q2 2019 Earnings Release-Final.docx')
ls_1 = []
count = 0
for paragraph in doc.paragraphs:
if 'profit' in paragraph.text:
count += 1
#print("profit关键词出现:{}次\n".format(count))
#print(paragraph.text)
ls_1.append(paragraph.text)
lst = ["".join(x for x in ls_1)]
s = 0
for i in lst[0].split(" "):
if i == 'profit':
s += 1
print("含有profit单词的段落有:{}个\n".format(len(ls_1)))
print("profit关键词一共出现:{}次".format(s))
–> 输出结果为:
含有profit单词的段落有:12个
profit关键词一共出现:17次
第一种方式、按照run的文字内容进行统计
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('Netease Q2 2019 Earnings Release-Final.docx')
num = 0
ls_2 = []
for paragraph in doc.paragraphs:
runs = paragraph.runs
for run in runs:
if 'profit' in run.text:
num += 1
#print("profit关键词出现:{}次\n".format(num))
#print(run.text)
ls_2.append(run.text)
lst = ["".join(x for x in ls_2)]
s = 0
for i in lst[0].split(" "):
if i == 'profit':
s += 1
print("含有profit单词的文字块有:{}个\n".format(len(ls_1)))
print("profit关键词一共出现:{}次".format(s))
–> 输出结果为:
含有profit单词的文字块有:16个
profit关键词一共出现:17次
全部代码
import os
os.chdir('D:\\python_major\\auto_office13')
from docx import Document
doc = Document('Netease Q2 2019 Earnings Release-Final.docx')
ls_1 = []
count = 0
for paragraph in doc.paragraphs:
if 'profit' in paragraph.text:
count += 1
#print("profit关键词出现:{}次\n".format(count))
#print(paragraph.text)
ls_1.append(paragraph.text)
#print("含有profit单词的段落有:{}个\n".format(len(ls_2)))
num = 0
ls_2 = []
for paragraph in doc.paragraphs:
runs = paragraph.runs
for run in runs:
if 'profit' in run.text:
num += 1
#print("profit关键词出现:{}次\n".format(num))
#print(run.text)
ls_2.append(run.text)
lst = ["".join(x for x in ls_2)]
s = 0
for i in lst[0].split(" "):
if i == 'profit':
s += 1
print("含有profit单词的文字块有:{}个\n".format(len(ls_2)))
print("profit关键词一共出现:{}次".format(s))
最后如果要提取包含大小写或者负数的profit关键词,这个操作和【python自动化办公(1)】里面的要求几乎一致,可以查看相应的内容,这里不进行叙述了
