Flume监听文件夹并上传到HDFS
监听/tools/flume文件夹,并上传到hdfs的flume目录下,且目录为当天的日期,并自定义监控文件前缀为:flu-
1.编写配置文件
#me the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /tools/flume
# Describe the sink
a1.sinks.k1.type = logger
a1.sources.r1.fileHeader = true
#采集数据到hdfs
a1.sinks.k1.type = hdfs
#配置上传到hdfs路径
a1.sinks.k1.hdfs.path = hdfs://lingyun2:9000/flume/%y-%m-%d
#是否按照时间滚动生成文件夹
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 1
a1.sinks.k1.hdfs.roundUnit = hour
#生成的文件类型,默认是Sequencefile;可选DataStream,则为普通文本;可选CompressedStr
#配置hdfs监控文件前缀
a1.sinks.k1.hdfs.filePrefix = flu-
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 每x秒生成一个文件,默认30秒,如果设置成0,则表示不根据时间来滚动文件;
a1.sinks.k1.hdfs.rollInterval = 60
# 每x字节,滚动生成一个文件;默认1024 (0 = 表示不根据临时文件大小来滚动文件)
a1.sinks.k1.hdfs.rollSize = 0
# 每x个event,滚动生成一个文件;默认10 (0 = 不根据事件滚动)
a1.sinks.k1.hdfs.rollCount = 0
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
#默认该通道中最大可以存储的event数量
a1.channels.c1.capacity = 1000
#每次最大可以从source中拿到或者送到sink中的event数量
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.启动flume
确保hadoop已启动
flume-ng agent -n a1 -c ./conf -f $FLUME_HOME/conf/flume_folder.conf -Dflume.root.logger=INFO,console
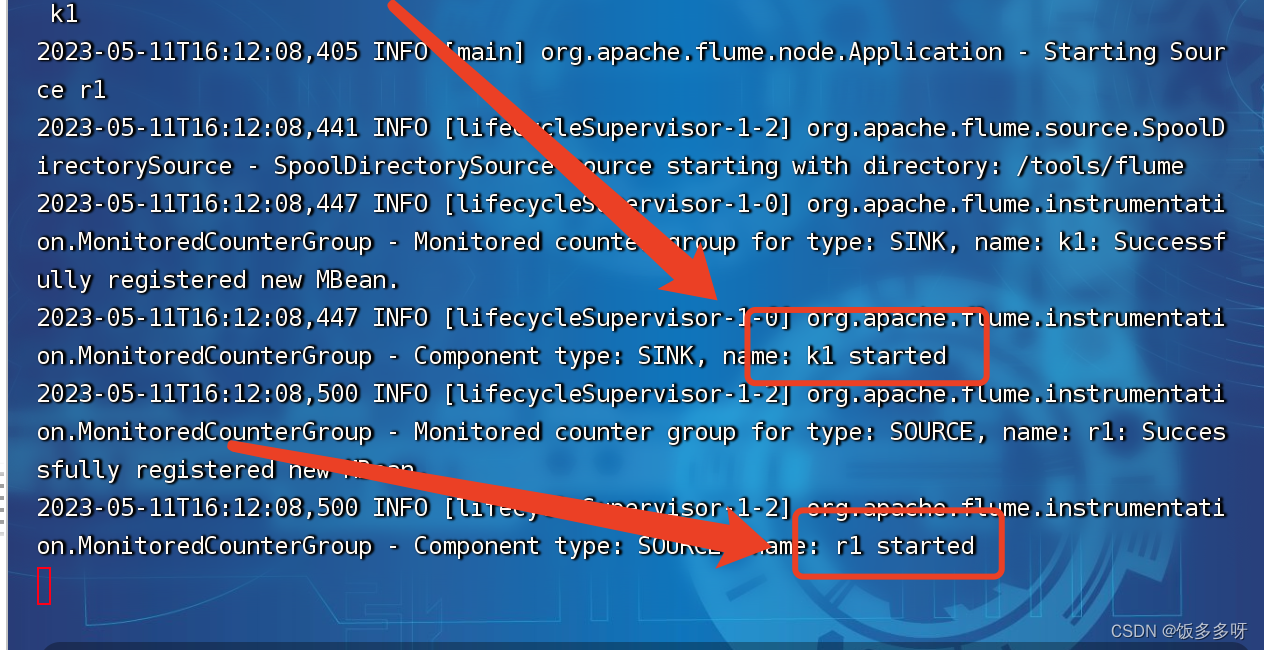
如下图所示为已成功启动
3.向被监控的文件夹中添加文件
可移动任意一个文件
mv flume_tail.log /tools/flume/
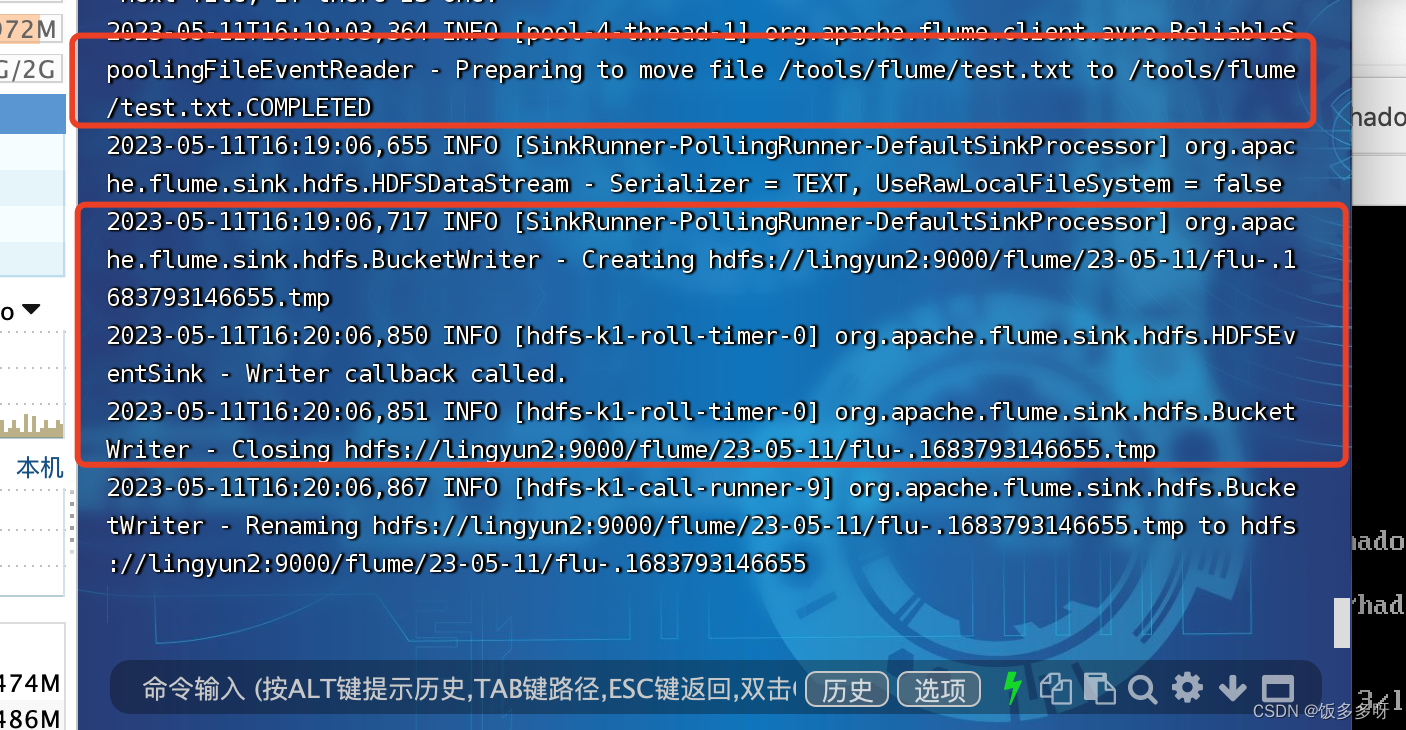
观察到已经监控到刚才的文件操作
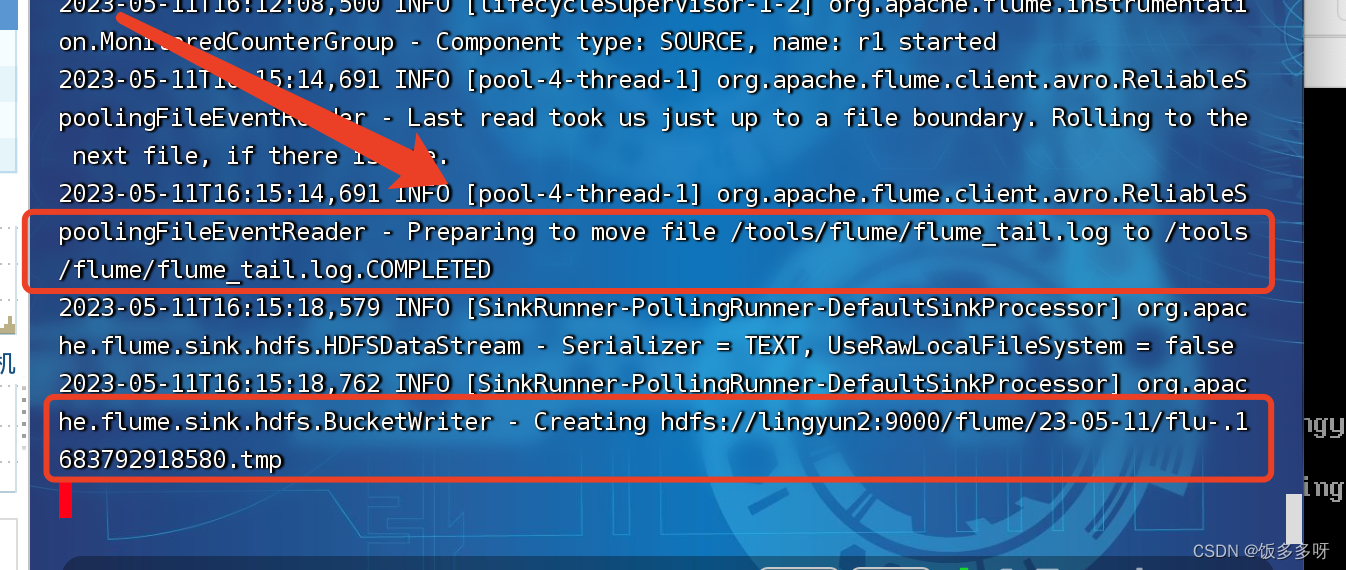
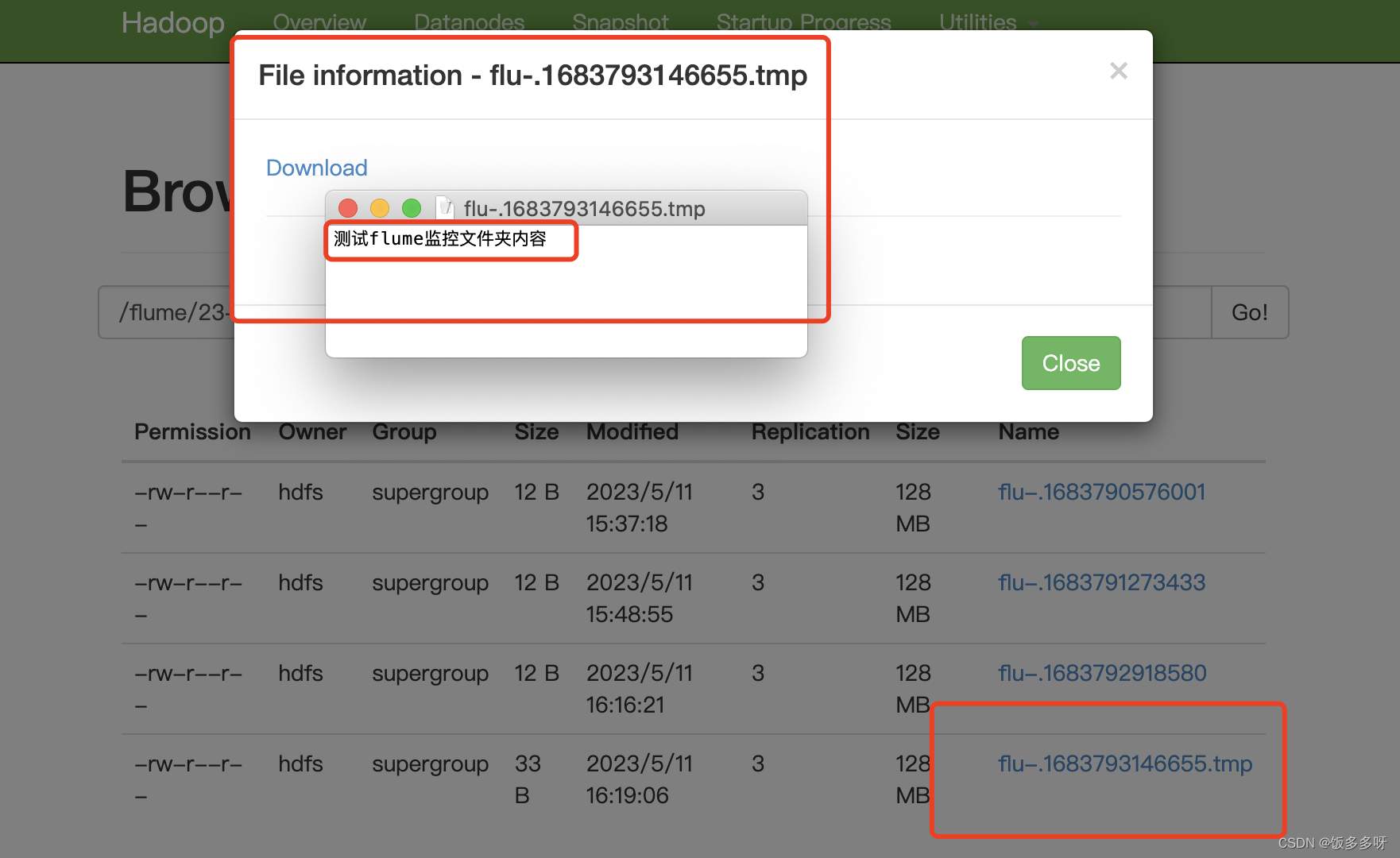
4.查看hdfs
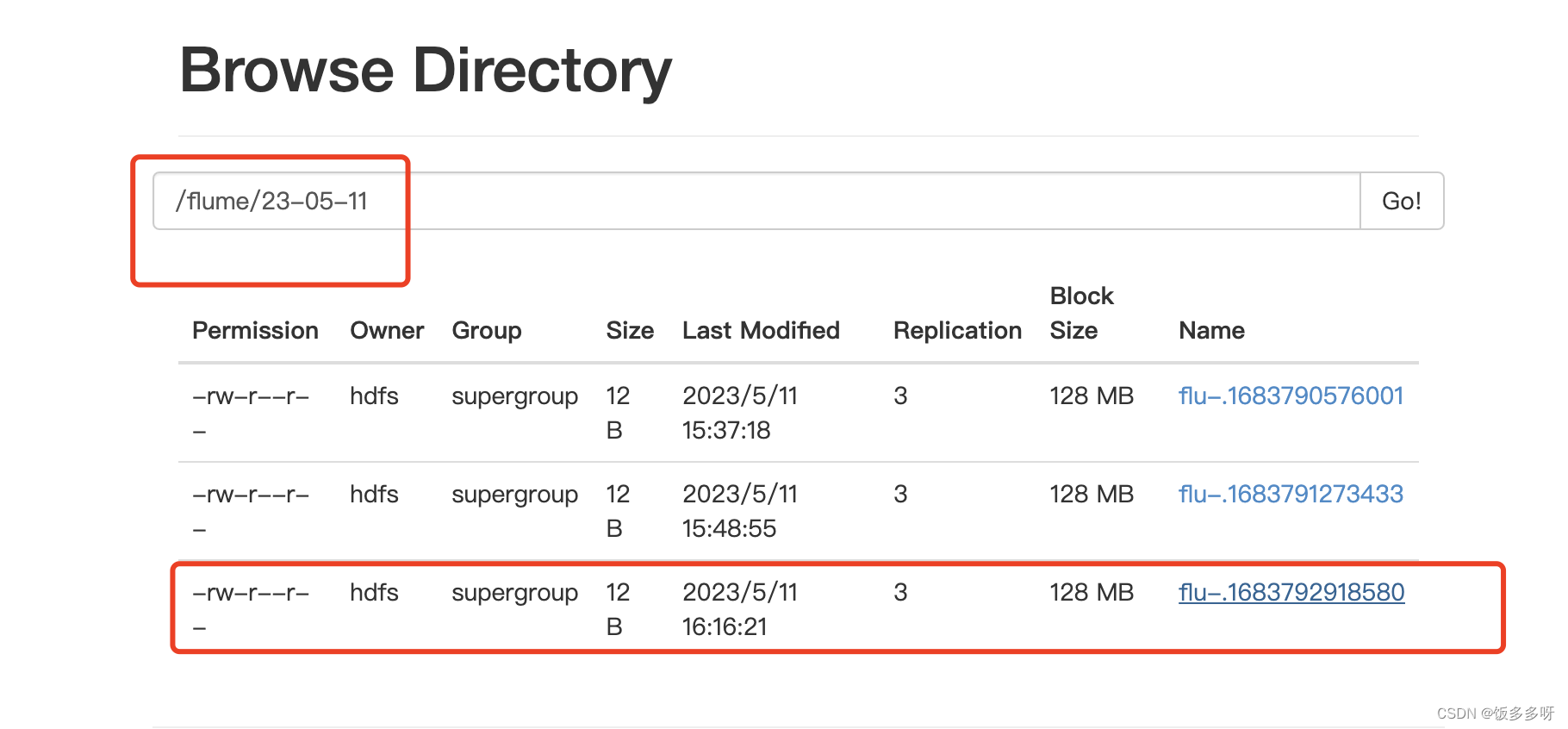
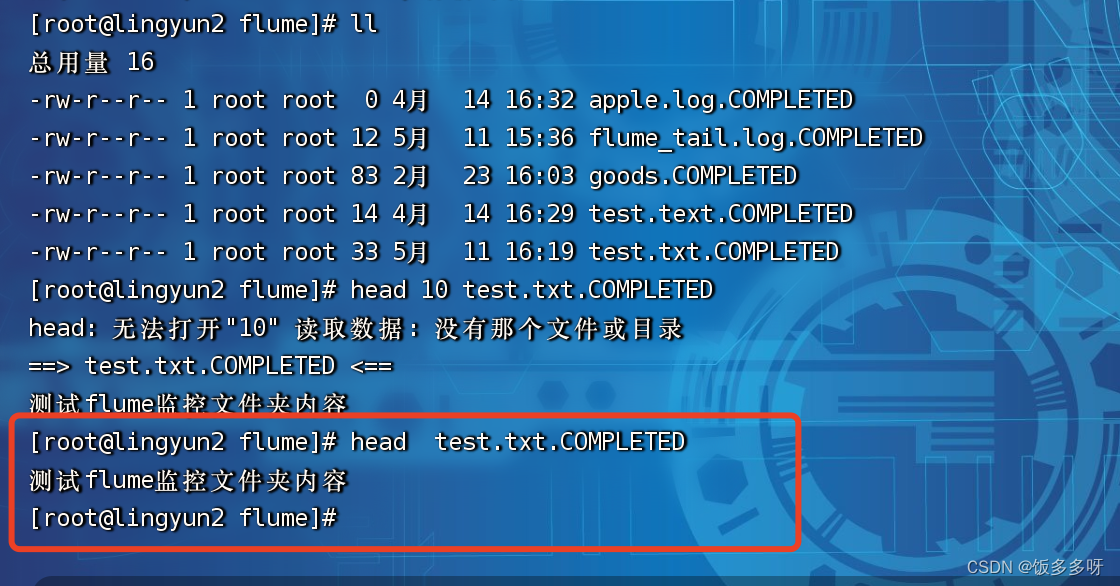
也可以直接向/tools/flume/目录下写入一个文件,如下图所示