目录
Flume安装
- 官网下载Flume:http://flume.apache.org/download.html
- 解压:tar -zxvf apache-flume-1.9.0-bin.tar.gz
- 重命名目录:mv apache-flume-1.9.0-bin flume-1.9.0
- 重命名conf目录下的flume-env.sh.template:mv flume-env.sh.template flume-env.sh
- 修改flume-env.sh:

- 修改/etc/profile:
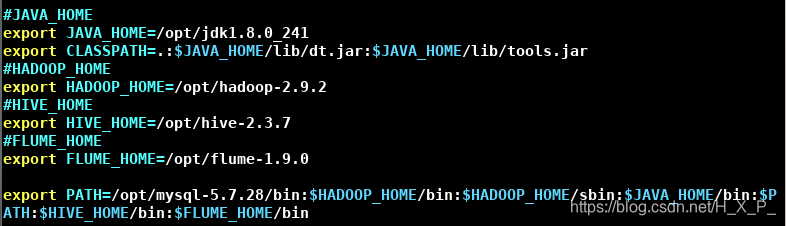
- source /etc/profile

案例一:监听端口
配置文件所需要的参数可以去官网查看,黑体为必选项。

案例分析
- 通过netcat工具向本机的44444端口发送数据
- Flume监听本机的44444端口,通过source端读取数据
- Flume将获取的数据通过sink端写出到控制台
案例步骤
-
每台主机安装netcat:yum install -y nc
-
查看端口44444是否被占用:netstat -tunlp | grep 44444
-
netcat用法:输入 nc -lk 44444 作为服务端,nc host 44444 作为客户端,相互可以通信

-
创建Flume Agent配置文件netcat-flume-logger.conf:
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1配置文件有5个部分,之间用空行隔开
- 给Agent的组件命名。a1是Agent名,r1是sources名,c1是channels名,k1是sinks名。注意单词是有复数的,说明可以有多个组件。
- 配置source。r1这个source的类型是netcat,监听的主机是localhost,监听的端口号是44444。
- 配置sink。k1的类型是logger,输出到控制台。
- 配置channel。c1这个channel的类型是内存,缓存容量是1000个事件(Flume以事件Event为传输单元),事务容量为100个事件(一次传输的数据)。
- 绑定三个组件。由于source、channel和sink可以有多个,所以需要绑定。INFO是指INFO及以上的消息。注意channel的复数,一个source可以绑定多个channel,一个channel可以绑定多个sink,一个sink只能绑定一个channel。
-
启动Flume,此时Flume作为服务端。conf是Flume目录下的conf目录,conf-file是自己写的配置文件,name是Agent的名字。
bin/flume-ng agent --conf conf --conf-file netcat-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console 或者 bin/flume-ng agent --c conf --f netcat-flume-logger.conf --n a1 -Dflume.root.logger=INFO,console -
启动新终端输入 nc localhost 44444,输入字符串


-
Ctrl+c关闭。可以用kill,但不要用kill -9,kill -9不会执行hook程序(收尾工作)。
案例二:监控本地文件
案例分析
- Flume监控本地文件的变化
- 通过crontab定时更改文件
- Flume将数据输出到控制台
案例步骤
-
在Flume目录下创建一个空文件:touch date.txt
-
创建Flume Agent配置文件exec-flume-logger.conf,source的类型为exec,sink的类型为logger,指令为tail:
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/flume-1.9.0/date.txt # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
启动Flume
bin/flume-ng agent -c conf -f exec-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console -
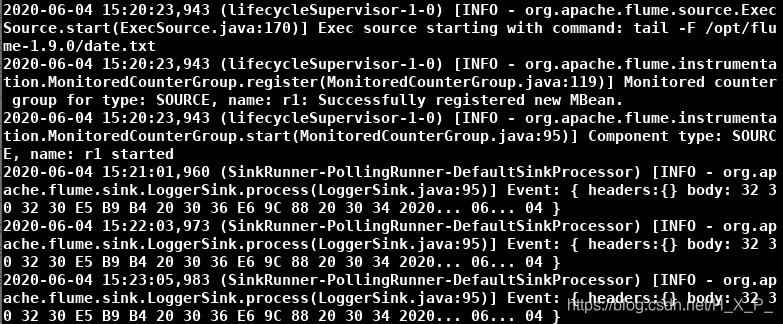
启动新终端,输入crontab -e,编辑定时任务,每分钟修改一次文件,保存

-
最终效果如下:
-
输入 crontab -r 删除当前用户定时任务
案例三:监控本地文件并上传HDFS
案例分析
- Flume对Hive日志文件进行监控
- 开启Hive,生成日志
- Flume将获取到的数据写入HDFS
案例步骤
-
由于需要将数据上传到HDFS上,所以需要准备好Hadoop相关的jar包。jar包可以在Hadoop安装目录下的share/hadoop目录下找。

-
将这些jar包复制到Flume目录下的lib目录下,Flume启动时会将lib下的jar包加载到内存:mv tempjar/* /opt/flume-1.9.0/lib
-
开启HDFS和Yarn:start-dfs.sh,start-yarn.sh
-
创建Flume Agent配置文件exec-flume-hdfs.conf,source的类型为exec,sink的类型是hdfs。注意:对于所有与时间相关的转义序列,Event Header中必须存在有“timestamp”的key(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自动添加timestamp)。
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/hive-2.3.7/log/hive.log # Describe the sink a1.sinks.k1.type = hdfs # 创建文件的路径 a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y%m%d/%H # 上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs # 是否按照时间滚动文件夹 # 下面3个参数一起配置 a1.sinks.k1.hdfs.round = true # 多久创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 # 定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour # 是否使用本地时间戳(必须配置) a1.sinks.k1.hdfs.useLocalTimeStamp = true # 积累多少个Event才flush到HDFS一次(单位为事件) a1.sinks.k1.hdfs.batchSize = 100 # 设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream # 多久滚动生成一个新的文件(单位为秒) # 这个参数只是实验用,实际开发需要调大点 # 下面3个参数一起配置 a1.sinks.k1.hdfs.rollInterval = 30 # 设置每个文件的滚动大小(略小于文件块大小128M) a1.sinks.k1.hdfs.rollSize = 134217700 # 文件的滚动与Event数量无关(0则不按照该值) a1.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
启动Flume
bin/flume-ng agent -c conf -f exec-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console -
启动新终端,启动hive,执行查询操作
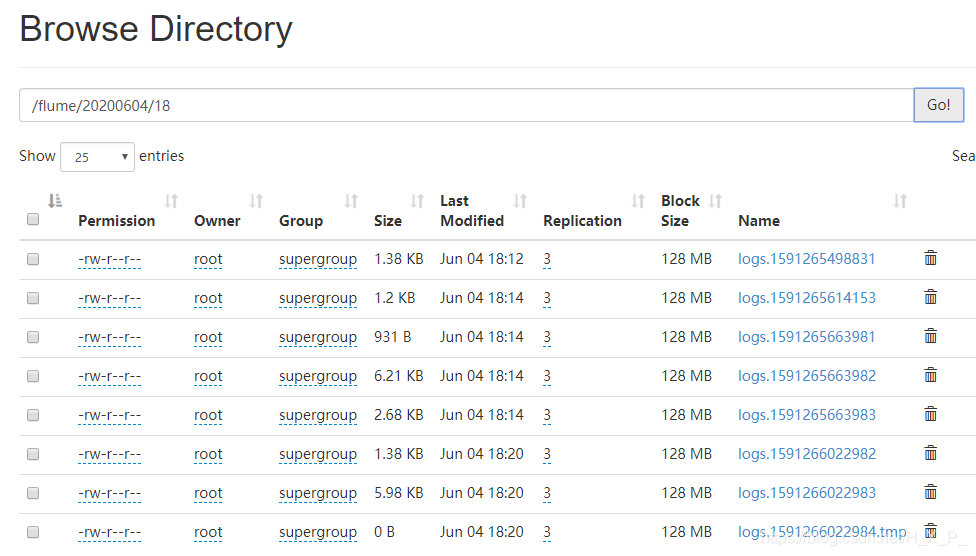
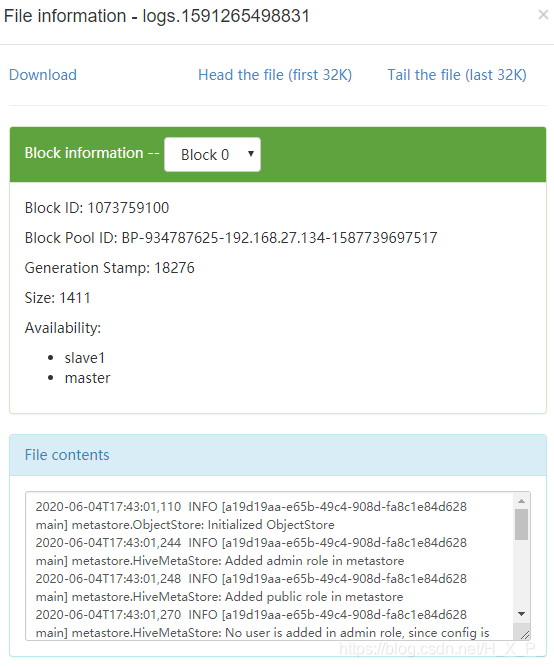
异常问题
2020-06-04 17:53:52,961 (conf-file-poller-0) [ERROR - org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:469)] Sink k1 has been removed due to an error during configuration
java.lang.InstantiationException: Incompatible sink and channel settings defined. sink’s batch size is greater than the channels transaction capacity. Sink: k1, batch size = 1000, channel c1, transaction capacity = 100
原因:channel和sink的设置不匹配,sink的batch size大于channel的transaction capacity
解决:将a1.sinks.k1.hdfs.batchSize设置为小于等于100
案例四:监控目录新文件并上传HDFS
案例分析
- Flume对指定目录进行监控,被监控的文件夹每500毫秒扫描一次文件变动
- 向目录添加新文件
- Flume将获取到的数据写入HDFS。上传后的文件在本地后缀默认为 .COMPLETED。没上传的文件在HDFS用 .tmp 后缀。
Flume通过上面这种方式判断是否有新文件,但如果目录中本来就存在没上传的且后缀为 .COMPLETED 的文件,那么Flume就不会将这个文件上传。
同时,如果修改了带有后缀为 .COMPLETED 的文件,Flume也不会将这个文件上传到HDFS,因为它有 .COMPLETED 后缀,Flume认为它已经上传了。
所以这种方式不能动态监控变化的数据。
案例步骤
-
创建一个新的目录:mkdir directory。
-
创建Flume Agent配置文件spooldir-flume-hdfs.conf,source的类型为spooling directory,sink的类型是hdfs
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = spooldir # 监控的目录 a1.sources.r1.spoolDir = /opt/flume-1.9.0/directory #忽略所有以.tmp 结尾的文件,不上传 a1.sources.r1.ignorePattern = ([^]*\.tmp) # Describe the sink a1.sinks.k1.type = hdfs # 创建文件的路径 a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y%m%d/%H # 上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs # 是否按照时间滚动文件夹 a1.sinks.k1.hdfs.round = true # 多久创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 # 定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour # 是否使用本地时间戳(必须配置) a1.sinks.k1.hdfs.useLocalTimeStamp = true # 积累多少个Event才flush到HDFS一次(单位为事件) a1.sinks.k1.hdfs.batchSize = 100 # 设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream # 多久滚动生成一个新的文件(单位为秒) a1.sinks.k1.hdfs.rollInterval = 30 # 设置每个文件的滚动大小(略小于文件块大小128M) a1.sinks.k1.hdfs.rollSize = 134217700 # 文件的滚动与Event数量无关(0则不按照该值) a1.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
启动Flume
bin/flume-ng agent -c conf -f spooldir-flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console -
在directory目录下创建文件:date > one.txt,date > two.txt,date > three.txt

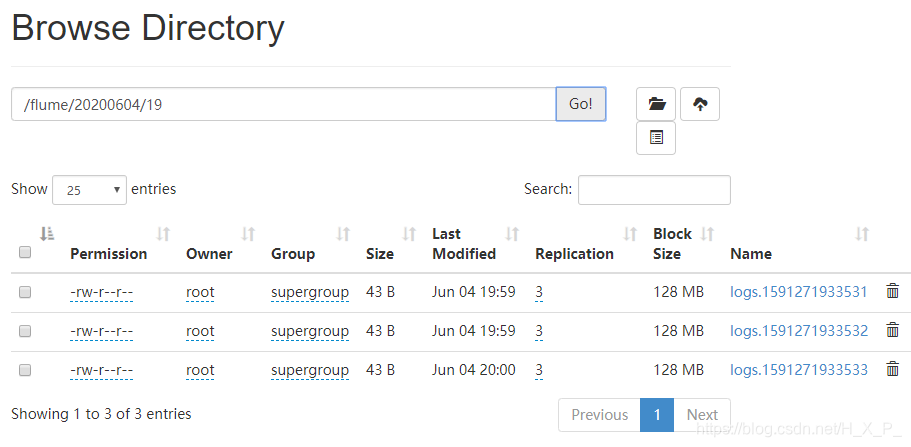
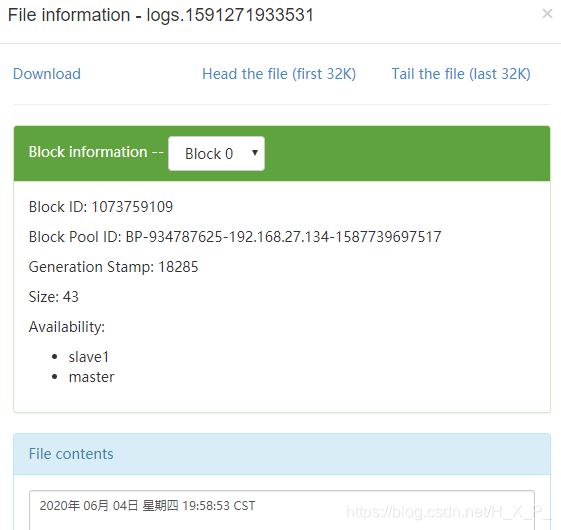
异常问题
如果向directory目录扔一个已经存在的文件,那么Flume会报错。比如我扔一个one.txt进去,date > one.txt。Flume会报错,directory目录有新文件one.txt,但没有后缀 .COMPLETED,而HDFS上有新文件。再次向目录扔新文件时three.txt,新文件不改名也不上传了,上传了一个1B的错误文件。
2020-06-04 20:22:32,879 (pool-5-thread-1) [ERROR - org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:296)] FATAL: Spool Directory source r1: { spoolDir: /opt/flume-1.9.0/directory }: Uncaught exception in SpoolDirectorySource thread. Restart or reconfigure Flume to continue processing.
java.lang.IllegalStateException: File name has been re-used with different files. Spooling assumptions violated for /opt/flume-1.9.0/directory/one.txt.COMPLETED


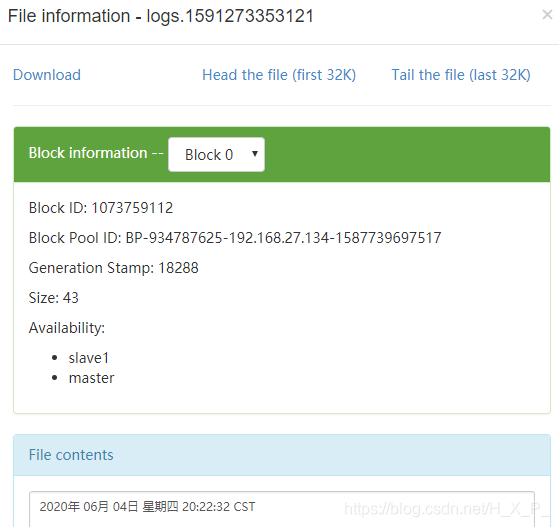

原因:新文件使用了目录中已经存在的文件名。Flume先上上传文件,然后在改名字,改名字时发生错误。之后错误一直存在,新文件无法上传。
解决:删除异常文件,重启Flume,重新向目录扔文件即可
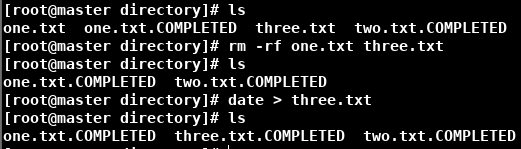
案例五:监控追加文件(断点续传)
Taildir Source 既能够实现断点续传,又可以保证数据不丢失,还能够进行实时监控。
案例步骤
-
创建一个新的目录:mkdir file。
-
在file目录下创建两个文件:touch one.txt,touch two.txt
-
创建Flume Agent配置文件taildir-flume-logger.conf,source的类型为taildir,sink的类型是logger
# Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinks = k1 # Describe/configure the source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/file/.*\.txt a1.sources.r1.positionFile = /opt/flume-1.9.0/file/position.json # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
启动Flume。
bin/flume-ng agent -c conf -f taildir-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console -
启动新终端,echo A >> one.txt,echo B >> two.txt

-
Ctrl+c关闭Flume,输入echo C >> one.txt,echo D >> two.txt,重启Flume

-
查看position.json可以发现,该文件记录了文件上次修改的位置,所以可以实现断点续传。(Unix/Linux系统内部不使用文件名,而使用inode来识别文件)

异常问题
配置文件将两个文件赋值给f1,最终one.txt不能被监控,而two.txt可以。
a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/file/one.txt
a1.sources.r1.filegroups.f1 = /opt/flume-1.9.0/file/two.txt
这是因为第二个将第一个覆盖了。要么用正则表达式,要么用两个变量f1,f2。