Personalize Segment Anything Model with One Shot https://arxiv.org/pdf/2305.03048.pdf https://github.com/ZrrSkywalker/Personalize-SAM

1.摘要
在大数据预训练的驱动下, Segment Anything 模型(SAM)已被证明是一个强大且可推广的框架,彻底改变了分割模型。尽管具有普遍性,但在没有人工提示的情况下为特定视觉概念定制SAM的探索不足,例如,在不同的图像中自动分割宠物狗。在本文中,我们为SAM提出了一种 training-free的个性化方法,称为PerSAM。仅给定具有参考掩码的单个图像,PerSAM首先通过位置先验定位目标概念,并通过三种技术将其分割到其他图像或视频中:目标引导注意力、目标语义提示和级联后细化。通过这种方式,我们在没有任何训练的情况下有效地调整SAM以供私人使用。为了进一步缓解掩码的模糊性,我们提出了一种有效的一次性微调变体PerSAM-F。冻结整个SAM,我们为多尺度掩码引入了两个可学习的权重,仅在10秒内训练2个参数以提高性能。为了证明我们的有效性,我们构建了一个新的分割数据集PerSeg,用于个性化评估,并在具有竞争性能的视频对象分割上测试了我们的方法。此外,我们的方法还可以增强DreamBooth,以个性化文本到图像生成的稳定扩散,从而丢弃背景干扰,实现更好的目标外观学习。
2.动机
Segment Anything(SAM)开发了一个用于收集11M图像掩码数据的精细数据引擎,随后训练了一个强大的分割基础模型,称为SAM。它首先定义了一种新的可提示分割范式,即将手工制作的提示作为输入,并返回期望的掩码。SAM的可接受提示足够通用,包括点、框、掩码和自由格式文本,这允许在视觉上下文中分割任何内容。
然而,SAM本质上失去了细分特定视觉概念的能力。想象一下,打算在相册中剪下你可爱的宠物狗,或者从你卧室的照片中找到丢失的时钟。使用普通SAM模型既耗费人力,又耗时。对于每张图像,需要在不同的姿势或上下文中定位目标对象,然后激活SAM并精确提示进行分割。因此,我们要问:我们能否个性化SAM,以简单高效的方式自动分割独特的视觉概念?
3.改进工作

为此,我们提出了PerSAM,这是一种针对分段任意模型的无训练个性化方法。如图1所示,我们的方法只使用一次拍摄数据,即用户提供的图像和指定个人概念的粗略掩码,就可以有效地定制SAM。具体来说,我们首先利用SAM的图像编码器和给定的掩模来对参考图像中目标对象的嵌入进行编码。然后,我们计算对象和新测试图像上所有像素之间的特征相似度。最重要的是,选择两个点作为正负对,它们被编码为提示token,并作为SAM的位置先验。在SAM的解码器处理测试图像中,我们引入了三种技术来释放其个性化潜力,而无需参数调整。
-
Target-guided Attention。我们通过计算的特征相似性来引导每个token在SAM的解码器中映射 cross-attention层。这迫使prompt tokens主要集中在前景目标区域,以进行有效的特征交互。
-
Target-semantic Prompting。为了更好地为SAM提供高级目标语义,我们将原始的低级提示token与目标对象的embedding 相融合,这为解码器提供了更充分的视觉线索来进行个性化分割。
-
Cascaded Post-refinement。为了获得更精细的分割结果,我们采用了两步后细化策略。我们利用SAM逐步完善其生成的掩码。这个过程只需要额外花费100毫秒。
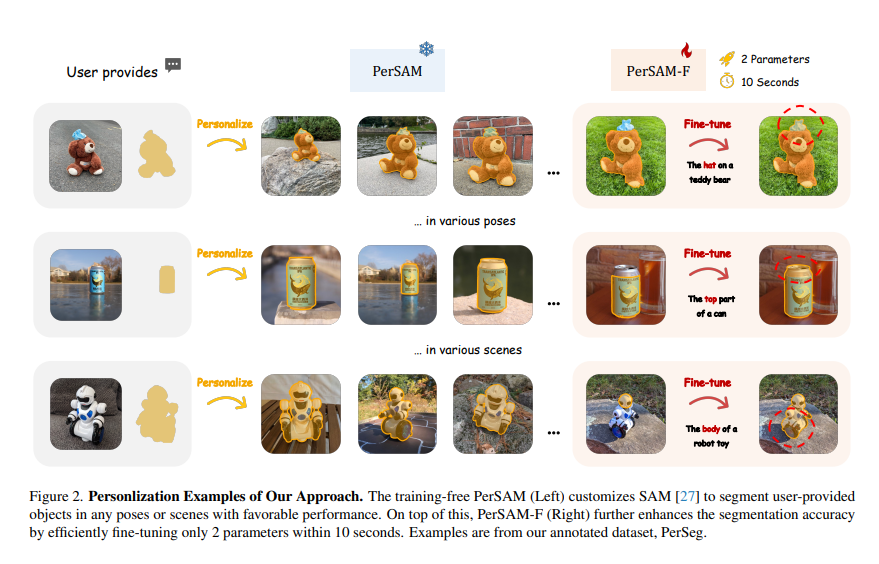
如图2所示,通过上述设计,PerSAM在各种姿势或背景下为独一无二的物体提供了良好的个性化分割性能。然而,可能偶尔会出现故障情况,其中物体包括要分割的分层结构,例如泰迪熊顶部的帽子、机器人玩具的头部或罐子的顶部。这种模糊性给PerSAM确定适当的掩模比例作为分割输出带来了挑战,因为局部部分和全局形状都可以被SAM从像素级别视为有效的掩模。
为了缓解这种情况,我们进一步引入了我们方法的微调变体PerSAM-F。我们冻结整个SAM以保留其预先训练的知识,并且仅在10秒内微调2个参数。详细地说,我们使SAM能够产生具有不同掩模尺度的多个分割结果。为了自适应地为不同的对象选择最佳尺度,我们对每个尺度使用可学习的相对权重,并进行加权求和作为最终的掩码输出。通过这种高效的一次性训练,PerSAM-T表现出更好的分割精度,如图2(右)所示。不使用即时调整或适配器,可以通过有效地加权多尺度掩码来有效地抑制模糊性问题

此外,如图3所示,我们观察到,我们的方法还可以帮助DreamBooth更好地微调Stable Diffusion,以生成个性化的文本到图像。给定一些包含特定视觉概念的图像,例如,你的宠物猫,DreamBooth及其其他作品将这些图像转换为单词嵌入空间中的标识符,然后用于表示句子中的目标对象。然而,标识符同时包括给定图像中背景的视觉信息,例如楼梯。这不仅会覆盖生成的图像中的新背景,还会干扰目标对象的表示学习。因此,我们建议利用我们的PerSAM来有效地分割目标对象,并且只通过少数拍摄图像中的前景区域来监督稳定扩散,从而实现更多样、更高保真的合成。
我们将论文的贡献总结如下:
Personalized Segmentation Task。从一个新的角度来看,我们研究了如何以最低的费用将细分基础模型定制到个性化场景中,即从通用到专用。
Efficient Adaption of SAM。我们首次研究仅通过微调2个参数即可将SAM适配为下游应用,并提出了两种轻量级解决方案:PerSAM和PerSAM-F
Personalization Evaluation。我们注释了一个新的分割数据集PerSeg,该数据集包含不同上下文中的各种类别。我们还在视频对象分割方面测试了我们的方法,并取得了有竞争力的结果。
Better Personalization of Stable Diffusion。通过在少量拍摄的图像中分割目标对象,我们减轻了背景的干扰,提高了DreamBooth的个性化生成。