一、实验介绍
1.1 实验内容
在新媒体时代,人们面对层出不穷的大数据,很容易陷入信息盲区,如何有效处理和利用这些数据,成为人们急须解决的问题之一。针对文本数据,目前人们通常采用自然语言处理技术进行重要信息的挖掘。而这些挖掘出的信息究竟以何种方式组织起来才能方便人们进行理解、浏览、传播及应用,是一个值得关注的问题。“词云”就是为此而诞生的。“词云”是对文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的无意义信息,让人看过词云图片就可以抓住内容的主旨。本实验将使用Python的wordcloud扩展包制作词云,生成图片保存。并介绍如何改进wordcloud扩展包使其能显示中文字符,最后介绍如何使用自己喜欢的图片定制词云图片轮廓。
1.2 词云原理
词云的原理是对输入的文本数据进行词频统计,根据词汇出现频率的不同,按不同比例显示出词汇,生成图片。频率高的词汇显示的大,频率低的词汇显示的小。文本数据可以是本地数据,也可是是爬虫动态从网络中获取的。
1.3 实验前期准备
下载并安装实验需要的扩展包 。无论是Windows还是Linux还是Mac,都强烈推荐安装Anaconda,这是一个Python的科学计算包,里面几乎包含了常用的所有扩展包,不用自己费力安装了,该软件由Python之父带头维护,三个平台同时更新。但是有些扩展包不包含在内需要自行安装,本文实验环境为python 3 。
1、安装wordcloud扩展包
pip install wordcloud2、下载测试文本constitution.txt和小说《三体》I、 II、 III,链接地址如下:
http://labfile.oss.aliyuncs.com/courses/756/constitution.txt
http://labfile.oss.aliyuncs.com/courses/756/santi.txt
http://labfile.oss.aliyuncs.com/courses/756/santi2.txt
http://labfile.oss.aliyuncs.com/courses/756/santi3.txt
二、实验步骤
2.1 简单测试
首先我们做一个简单的测试,程序运行时会搜寻python脚本所在的路径下的文本文件“constitution.txt”,所以我们在运行脚本前需要将这个文本放入脚本的同级目录下,码如下所示。
from os import path
from wordcloud import WordCloud
d = path.dirname(__file__)
# Read the whole text.
text = open(path.join(d, 'constitution.txt')).read()
# Generate a word cloud image
wordcloud = WordCloud().generate(text)
# Display the generated image:
# the matplotlib way:
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
plt.axis("off")
# lower max_font_size
wordcloud = WordCloud(max_font_size=40).generate(text)
plt.figure()
plt.imshow(wordcloud)
plt.axis("off")
plt.show()脚本运行结果如下:
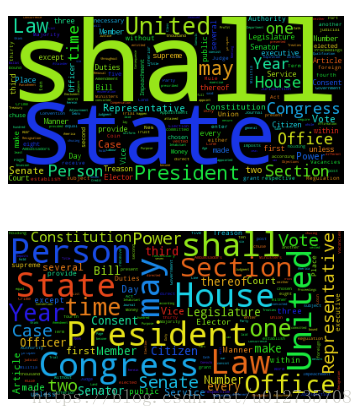
至此,我们得到了一个英文词云。
2.2 中文测试
我们将文本文档换成《三体》I,进行中文词云的生成。
from os import path
from wordcloud import WordCloud
d = path.dirname(__file__)
# Read the whole text.
#text = open(path.join(d, 'constitution.txt')).read()
text = open("santi.txt").read()
# Generate a word cloud image
wordcloud = WordCloud().generate(text)
# Display the generated image:
# the matplotlib way:
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
plt.axis("off")
# lower max_font_size
wordcloud = WordCloud(max_font_size=40).generate(text)
plt.figure()
plt.imshow(wordcloud)
plt.axis("off")
脚本运行结果如下:

出现上图的原因是wordcloud没有找到用于显示汉字的字体,因此我们可以指定一个字体文件给wordcloud,代替默认的字体显示词云。系统中存在字体库,一般在'C:\Windows\Fonts'路径下,我们这选择了该目录下的simkai.ttf进行实验。我们将simkai.ttf文件位置作为字体参数传递给wordcloud。
wordcloud = WordCloud(font_path='C:\Windows\Fonts\simkai.ttf',max_font_size=40).generate(text)

此时,我们发现中文词云显示正常。但是这种形式的词云我们是很难接受的,毕竟太丑了!接下来我们需要对该词云进行深加工,这就需要我们了解wordcloud的参数。
2.3 wordcloud参数简单介绍
font_path : string //字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
width : int (default=400) //输出的画布宽度,默认为400像素
height : int (default=200) //输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) //词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
mask : nd-array or None (default=None) //如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread('读取一张图片.png'),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存,就ok了。
scale : float (default=1) //按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
min_font_size : int (default=4) //显示的最小的字体大小
font_step : int (default=1) //字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。
max_words : number (default=200) //要显示的词的最大个数
stopwords : set of strings or None //设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
background_color : color value (default=”black”) //背景颜色,如background_color='white',背景颜色为白色。
max_font_size : int or None (default=None) //显示的最大的字体大小
mode : string (default=”RGB”) //当参数为“RGBA”并且background_color不为空时,背景为透明。
relative_scaling : float (default=.5) //词频和字体大小的关联性
color_func : callable, default=None //生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) //使用正则表达式分隔输入的文本
collocations : bool, default=True //是否包括两个词的搭配
colormap : string or matplotlib colormap, default=”viridis” //给每个单词随机分配颜色,若指定color_func,则忽略该方法。
fit_words(frequencies) //根据词频生成词云(frequencies,为字典类型)
generate(text) //根据文本生成词云
generate_from_frequencies(frequencies[, ...]) //根据词频生成词云
generate_from_text(text) //根据文本生成词云
process_text(text) //将长文本分词并去除屏蔽词(此处指英语,中文分词还是需要自己用别的库先行实现,使用上面的 fit_words(frequencies) )
recolor([random_state, color_func, colormap]) //对现有输出重新着色。重新上色会比重新生成整个词云快很多。
to_array() //转化为 numpy array
to_file(filename) //输出到文件
针对于如何让词云显示的更清晰,对一些参数进行详细的分析。
mask:遮罩图,字的大小布局和颜色都会依据遮罩图生成。其实理论上这对字大小和清晰程度的影响不大, 但是遮罩图色和背景色background_color如果易混淆,则可能是一个导致看起来不清晰的因素; 另外遮罩图自身各个颜色之间的对比不强烈,也可能使图看起来层次感不够。 比如,一些图明度比较高,再加上背景白色,有可能导致字色太浅(背景色background_color又是白色)于是看起来不够“清晰”。
background_color:背景色,默认黑。 这个本来其实也不怎么影响清晰度,但是,就像之前在mask中提到的,如果遮罩图像颜色过浅、背景设置白色, 可能导致字看起来“不清晰”。而实际上,我对一个浅色遮罩图分别用白、黑两种背景色后发现, 黑色背景的强烈对比之下会有若干很浅也很小的词浮现出来,而之前因背景色、字色过于相近而几乎无法用肉眼看出这些词。
mode:默认“RGB”。根据说明文档,如果想设置透明底色的云词图,那么可以设置
(注:background_color=None, mode="RGBA" 但是!!!实际中我尝试设置透明背景色并没有成功过! 当我选取的遮罩图是白色底时,如果background_color设置为"white"或"black"时,生成的云词确实是对应的“白色”“黑色”; 但是按照上述参数设置透明色时,结果出来依然是白色。 当我选取的遮罩图是透明底时,那么不管我background_color设置为"white"或"black",还是None加上mode="RGBA", 结果都是把背景部分当做黑色图块,自动匹配黑色的字!——也就是并没有实现透明底的云词。)
max_font_size:最大字号。源文件中也有讲到,图的生成会依据最大字号等因素去自动判断词的布局。 经测试,哪怕同一个图像,只要图本身尺寸不一样(比如我把一个300×300的图拉大到600×600再去当遮罩),那么同样的字号也是会有不同的效果。 原理想想也很自然,字号决定了字的尺寸,而图的尺寸变了以后,最大字相对于图的尺寸比例自然就变了。 所以,需要根据期望显示的效果,去调整最大字号参数值。 min_font_size:最小字号。不设置的情况下,默认是4。 尝试了设置比4大的字号,例如8、10,结果就是原本小于设定值且大于4号的词都直接不显示了,其它内容和未设置该值时都一样。
relative_scaling:表示词频和云词图中字大小的关系参数,默认0.5。 为0时,表示只考虑词排序,而不考虑词频数;为1时,表示两倍词频的词也会用两倍字号显示。
scale:根据说明文档,当云词图很大的,加大该值会比使用更大的图更快,但值越高也会越慢(计算更复杂)。 默认值是1。实际测试中,更大的值,确实输出图像看起来更精细(较小较浅的词会颜色更重,也感觉清楚,大的词差异不明显)。
三、定制词云
看着我们自己方方正正的词云,是不是感觉太中规中矩了?都不好意思拿出手了吧? 没关系,我们也可以做一个不规则边缘的词云! 为了达到一个定制词云的效果,我们需要一个图片作为mask,这个mask的作用就是为我们的词云提供一个空间,让我们的词云只在这个空间里显示。我们的mask图片是星github上有关于wordcloud项目的开源代码: https://github.com/amueller/word_cloud 中所提供的,图片是这个样子的。

为此,我们需要修改我们的代码,增加图片mask,修改后的代码如下:
import numpy as np
from PIL import Image
from os import path
import matplotlib.pyplot as plt
import matplotlib
import os
from wordcloud import WordCloud
d = path.dirname(__file__) if "__file__" in locals() else os.getcwd()
mask = np.array(Image.open(path.join(d, "alice_mask.png")))
text = open(path.join(d, 'santi.txt')).read()
text = text.replace(u"汪淼说", u"汪淼")
text = text.replace(u"汪淼问", u"汪淼")
text = text.replace(u"叶文洁说", u"叶文洁")
text = text.replace(u"元首说", u"元首")
wc = WordCloud(font_path='C:\Windows\Fonts\simkai.ttf',max_words=200, mask=mask, margin=10,background_color='white',
min_font_size=4,max_font_size=100,random_state=1,mode='RGBA').generate(text)
default_colors = wc.to_array()
#标题字体设置
myfont = matplotlib.font_manager.FontProperties(fname='C:\Windows\Fonts\simkai.ttf')
wc.to_file("a_new_hope.png")
plt.figure(figsize=(20,20))
plt.title(u"三体-词频统计",fontproperties=myfont,fontsize=100)
plt.imshow(default_colors, interpolation="bilinear")
plt.axis("off")
plt.show()
脚本执行结果如下:

是不是美观了很多~
但这跟我们定制的要求还有出入,形状要根据咱们的要求来指定,那就要求对图片进行处理,在这里我用的是比较简单的美图秀秀。
原图是这样儿的~

美图秀秀抠图后

之后只需要将新图传给mask
mask = np.array(Image.open(path.join(d, "panda_new.png")))

搞定!