推荐系统
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天继续和大家分享一下SVD矩阵分解代码案例
#博学谷IT学习技术支持
前言
今天和大家分享推荐系统中SVD矩阵分解代码案例
一、读取电影数据集
import pandas as pd
import numpy as np
users_Name=['user_id','gender','age','work','zip']
ratings_Name=['user_id','movies_id','ratings','timeStamp']
movie_Name=['movie_id','title','calss']
users=pd.read_table('./dataset/ml-1m/users.dat',encoding='latin-1',sep='::',header=None,names=users_Name)
ratings=pd.read_table('./dataset/ml-1m/ratings.dat',encoding='latin-1',sep='::',header=None,names=ratings_Name)
movies=pd.read_table('./dataset/ml-1m/movies.dat',encoding='latin-1',sep='::',header=None,names=movie_Name)
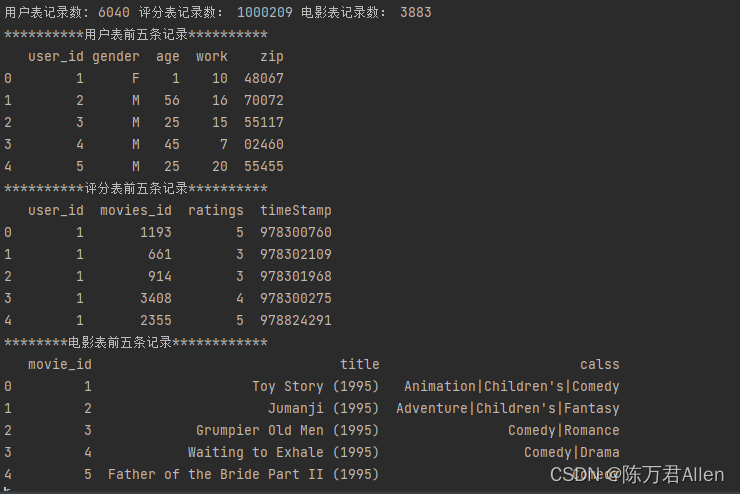
print('用户表记录数:',len(users),'评分表记录数:',len(ratings),'电影表记录数:',len(movies))
print('**********用户表前五条记录**********')
print(users.head(5))
print('**********评分表前五条记录**********')
print(ratings.head(5))
print('********电影表前五条记录************')
print(movies.head(5))
二、SVD
class SVD:
def __init__(self, learning_rate, regularized_rate, max_step, n_users, n_items, n_factors):
self.learning_rate = learning_rate
self.regularized_rate = regularized_rate
self.max_step = max_step
self.bu = np.zeros(n_users, np.double)
self.bi = np.zeros(n_items, np.double)
self.pu = np.zeros((n_users, n_factors), np.double)
self.qi = np.zeros((n_items, n_factors), np.double)
self.mean = 0
def get_pred_value(self, u, i):
return self.mean + self.bu[u] + self.bi[i] + np.dot(self.pu[u], self.qi[i])
def fit(self, X):
for index, row in X.iterrows():
u, i, r = row['user_id'], row['movies_id'], row['ratings']
err = r - self.get_pred_value(u, i)
self.bu[u] += self.learning_rate * (err - self.regularized_rate * self.bu[u])
self.bi[i] += self.learning_rate * (err - self.regularized_rate * self.bi[i])
tmp = self.pu[u]
self.pu[u] += self.learning_rate * (err * self.qi[i] - self.regularized_rate * self.pu[u])
self.qi[i] += self.learning_rate * (err * tmp - self.regularized_rate * self.qi[i])
if index == self.max_step:
break
return self
def transform(self, X):
result = [0] * len(X)
for index, row in X.iterrows():
u, i, r = row['user_id'], row['movies_id'], row['ratings']
result[index] = self.get_pred_value(u, i)
return result
if __name__ == '__main__':
algo = SVD(learning_rate=learning_rate, regularized_rate=regularized_rate, max_step=max_step, n_users=n_users,
n_items=n_items, n_factors=n_factors)
model = algo.fit(ratings)
result = model.transform(ratings)
print(result[:10])
得到输出的结果:
[0.712061395401814, 0.19680425997661766, 0.2770262567858081, 0.4959207041970778, 0.6168076353251164, 0.9046821307908399, 0.29919052853100275, 0.554204908108176, 0.30406646989523367, 0.6900106995374652]
总结
根据公式自定义的SVD举证分解代码案例