目录
背景
Weka的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),是一款免费
的,非商业化软件,与之对应的是SPSS公司商业数据挖掘产品--Clementine ;weka是基于JAVA环境下开源的
机器学习(machine learning)以及数据挖掘(data mining)软件。Weka的主要开发者来自新西兰的怀卡托大学(The University of Waikato)。WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
一、安装
安装简单,一路next。
1.打开weka3.8.6的安装包

2.点击 next
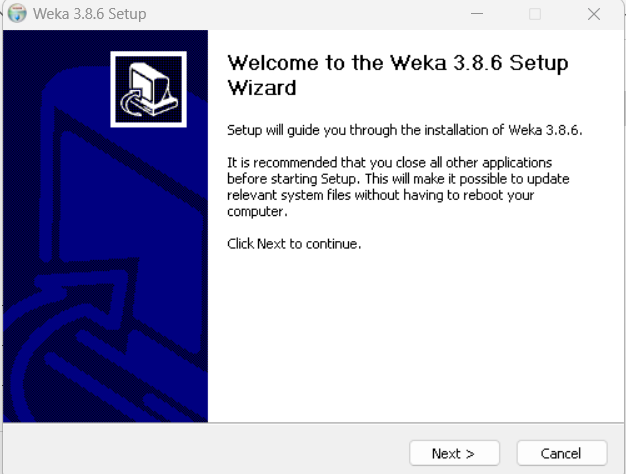
3.点击I Agree
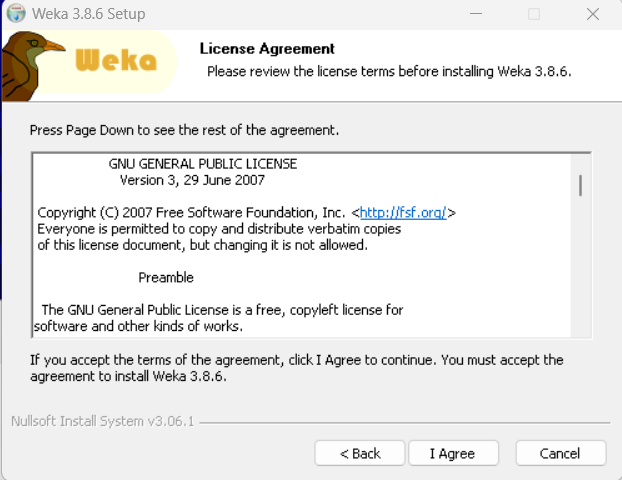
4.点击next
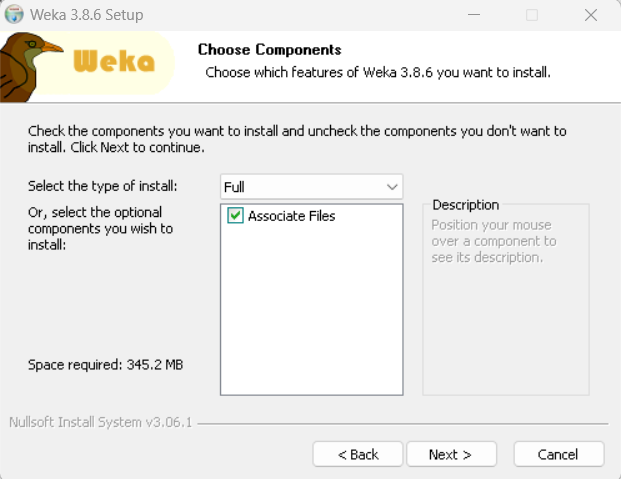
5.选择安装路径如:D:\weka-3-8-6
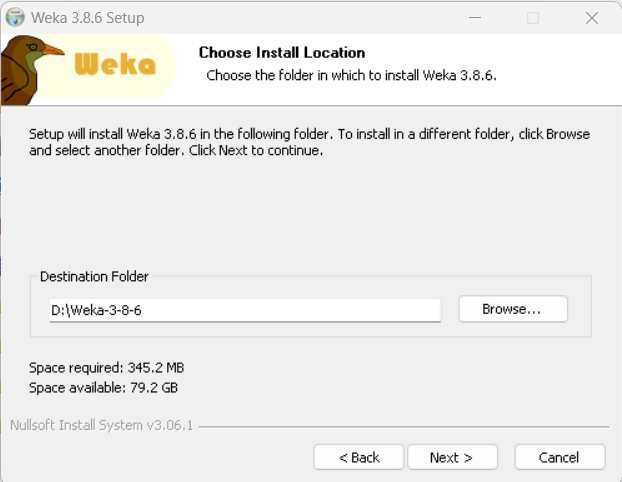
6.点击install
等待后,finish。下面是安装成功后打开的初始界面
二、使用explorer
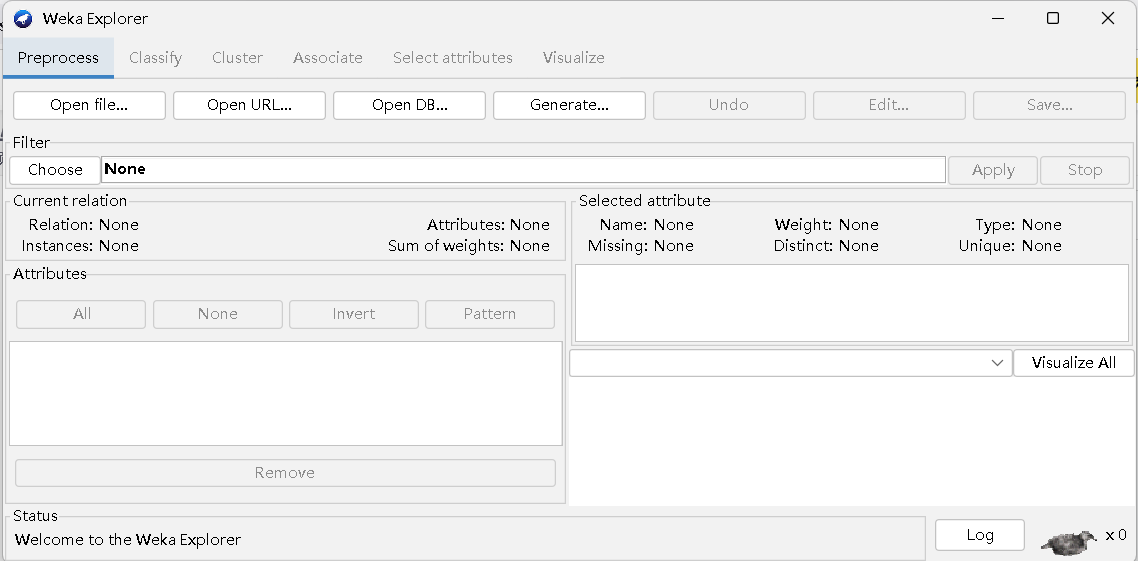
1. 介绍

Preprocess:预处理
Classify:分类
Cluster:聚类
Associate:关联
Select attributes:选择属性
Visualize:可视化

- open file:从文件中打开一组实例
- open URL:从URL中打开一组实例
- open DB:从数据库中打开一组实例
- generate:生成人工数据
- undo:撤销对数据集最后更改
- edit:在查看器中打开当前数据集进行编辑
- save:将工作关系保存到文件中

属性
- ALL:全选
- None:全不选
- invert:取反
- pattern:输入perl正则表达式
该位置展示具体属性都有什么
- remove:选择属性后,点击删除,可用undo撤回。

当前的关系
- 关系:投票 属性:17
- 实例:435 权重和:435
2.打开自带的数据集(Preprocess)
1.打开步骤
选择openfile

选择data文件
这里我们可以看到一些weka自带的数据集
选择其中一个数据集打开,我选择的是vote.arff
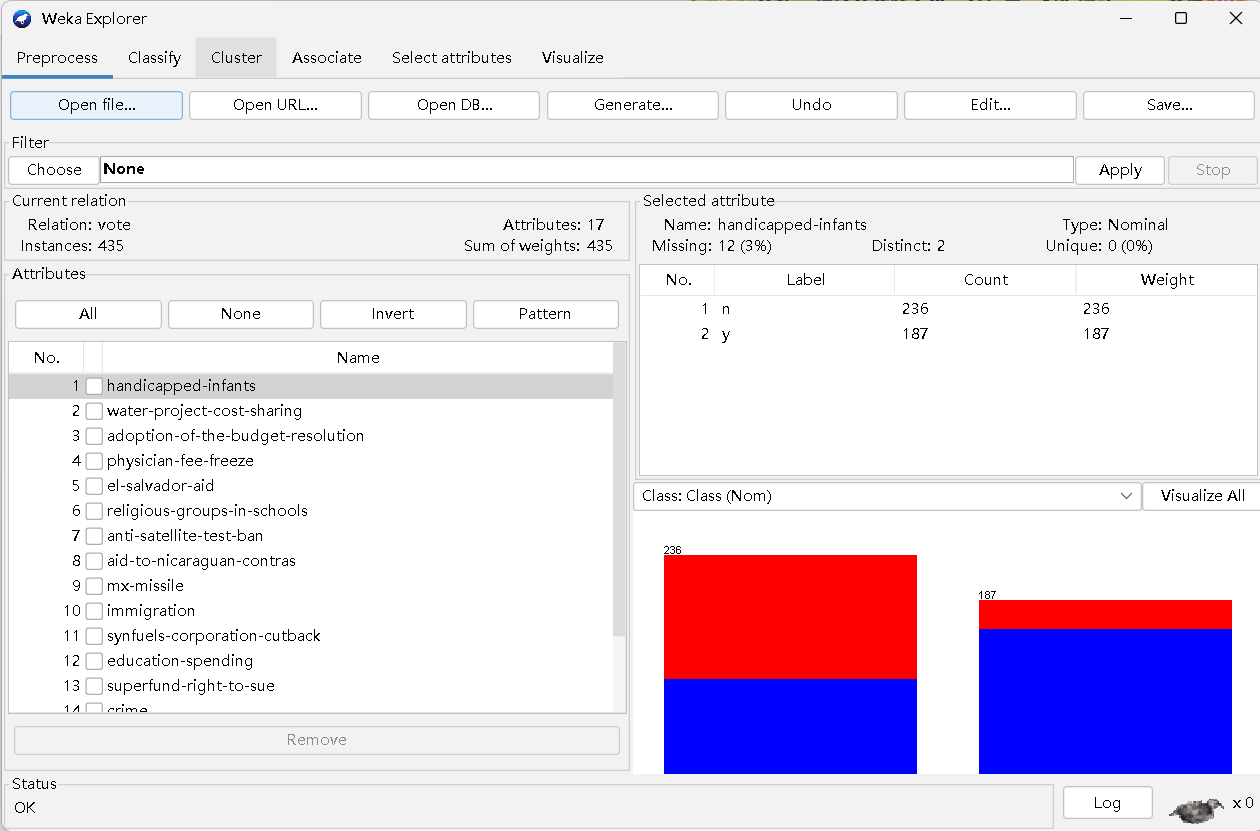
2.查看属性和数据编辑
2.1查看属性
选择属性,可以下拉查看并选择

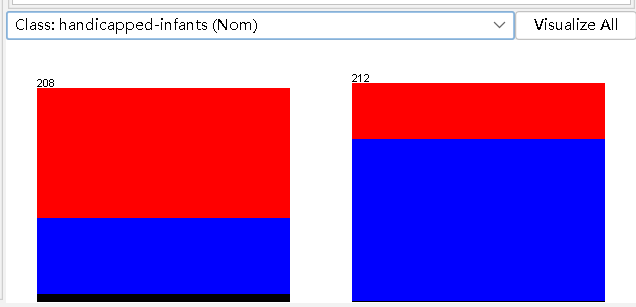
Visualize All:查看所有属性直方图

2.2数据编辑
点击Edit,弹出viewer,在这里面可以查看并编辑数据。
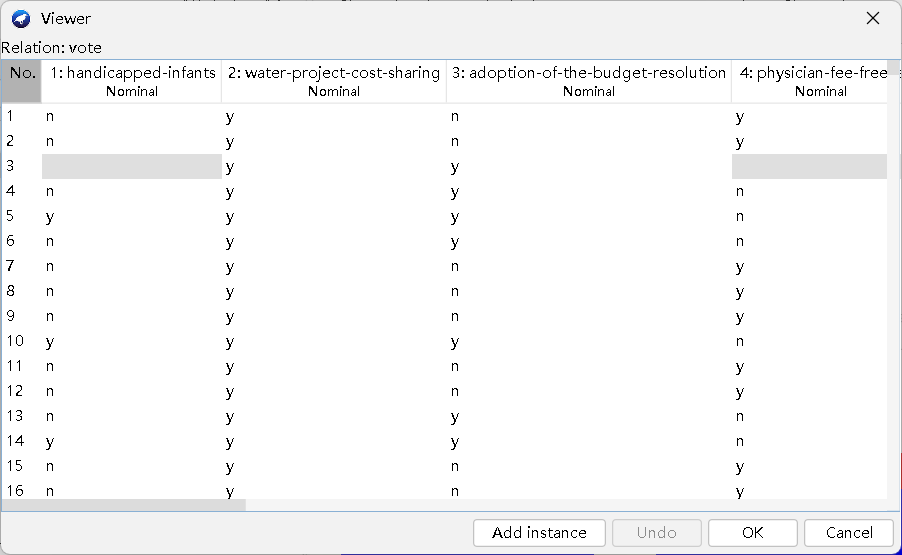
3.classify
分类是指根据事物的某些共同特征,将它们分成若干组或类别,以达到简化、归纳和管理的目的。在机器学习领域中,分类是指根据已有数据集中的特征和标签信息,训练出一个算法模型,用于预测新样本所属的类别。分类问题是机器学习中最常见的问题类型,其应用广泛,如垃圾邮件识别、图像分类、医学诊断等等。机器学习中一些常见的分类算法包括决策树、支持向量机、朴素贝叶斯、神经网络等。
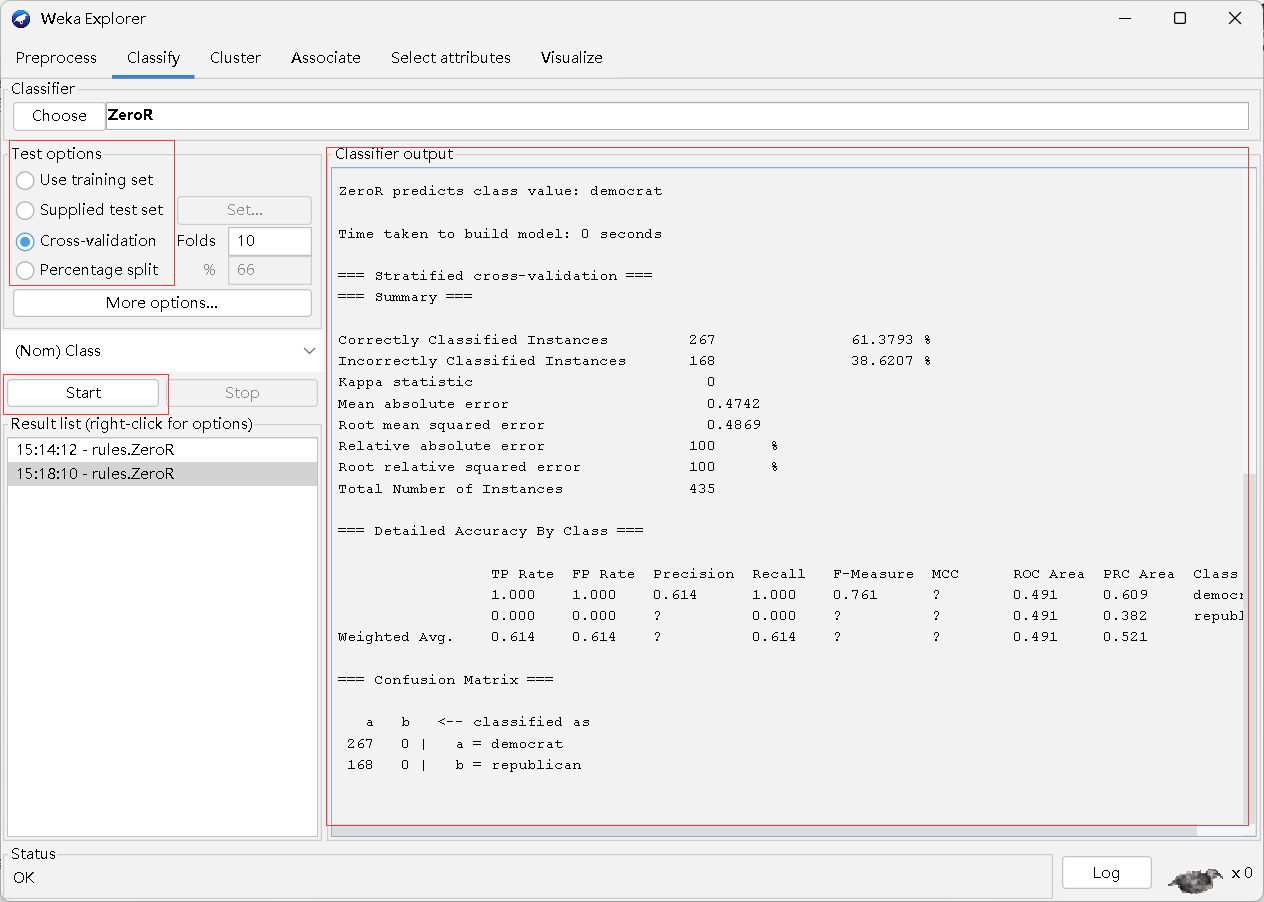
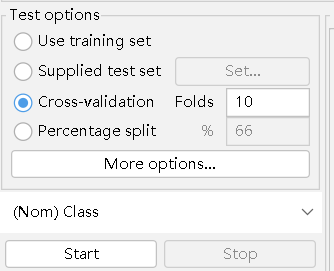
测试选项
- Use training set:使用训练集
- Supplied test set:提供测试集
- Cross-validation:交叉验证
- Percentage split:按比例分配
- start:点击即用
4.Cluster
聚类是指根据一组数据的相似性,将它们分为若干个组或簇,使得同一个簇内的元素彼此相似,不同簇之间的元素差异较大。聚类是无监督学习领域中的重要问题,与分类问题不同,聚类问题中没有预先定义好的标签信息,需要通过算法自动挖掘数据的内在结构和规律。聚类算法可以应用于数据挖掘、图像分割、社交网络分析等领域,是机器学习中的重要研究方向。常见的聚类算法有K-means、层次聚类、DBSCAN、OPTICS等。
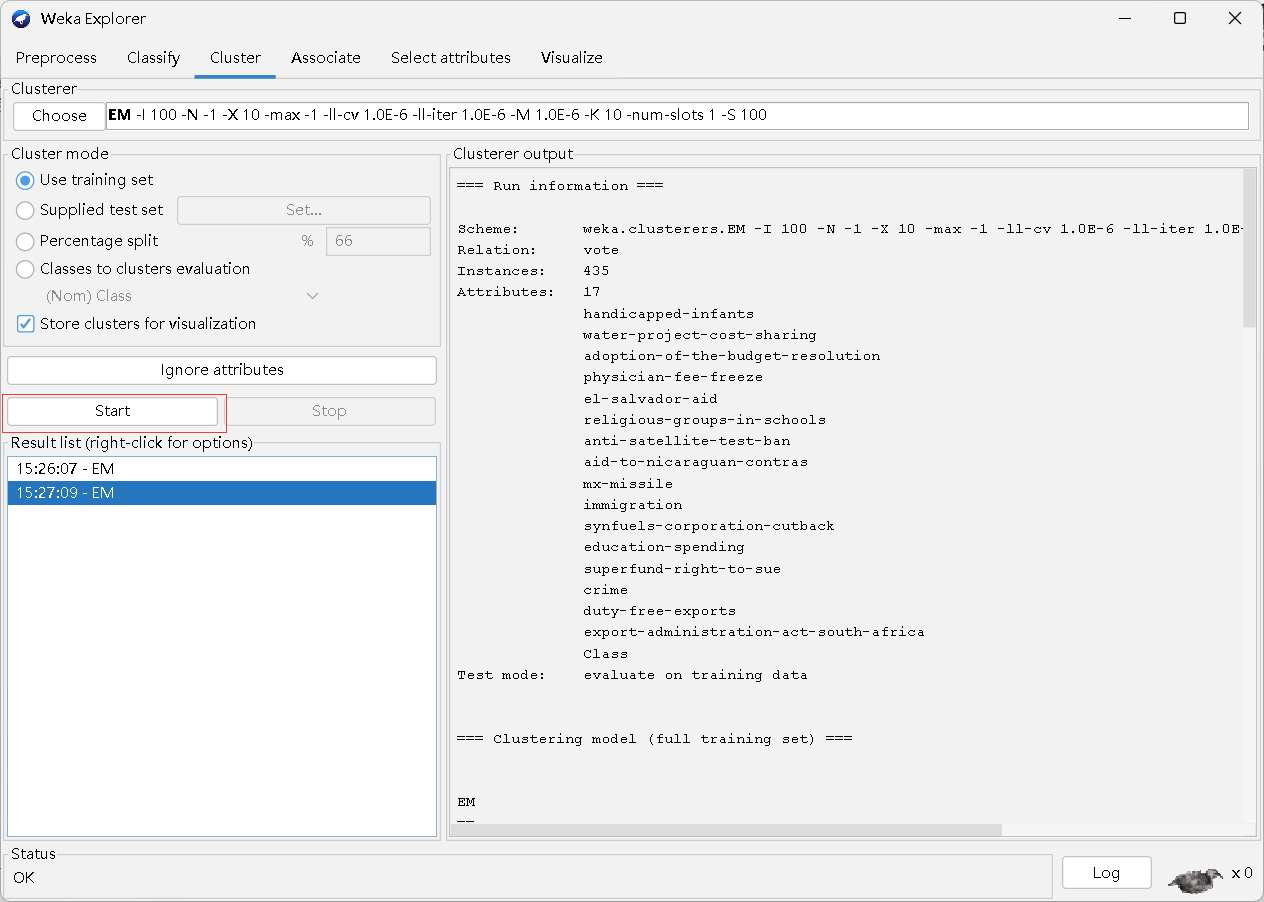
集群模式【Cluster mode】
- Use training set:使用训练集
- Supplied test set:提供测试集
- Percentage split:比例分割
- Classes to clusters evalation:类到聚类的评估
5.Associate
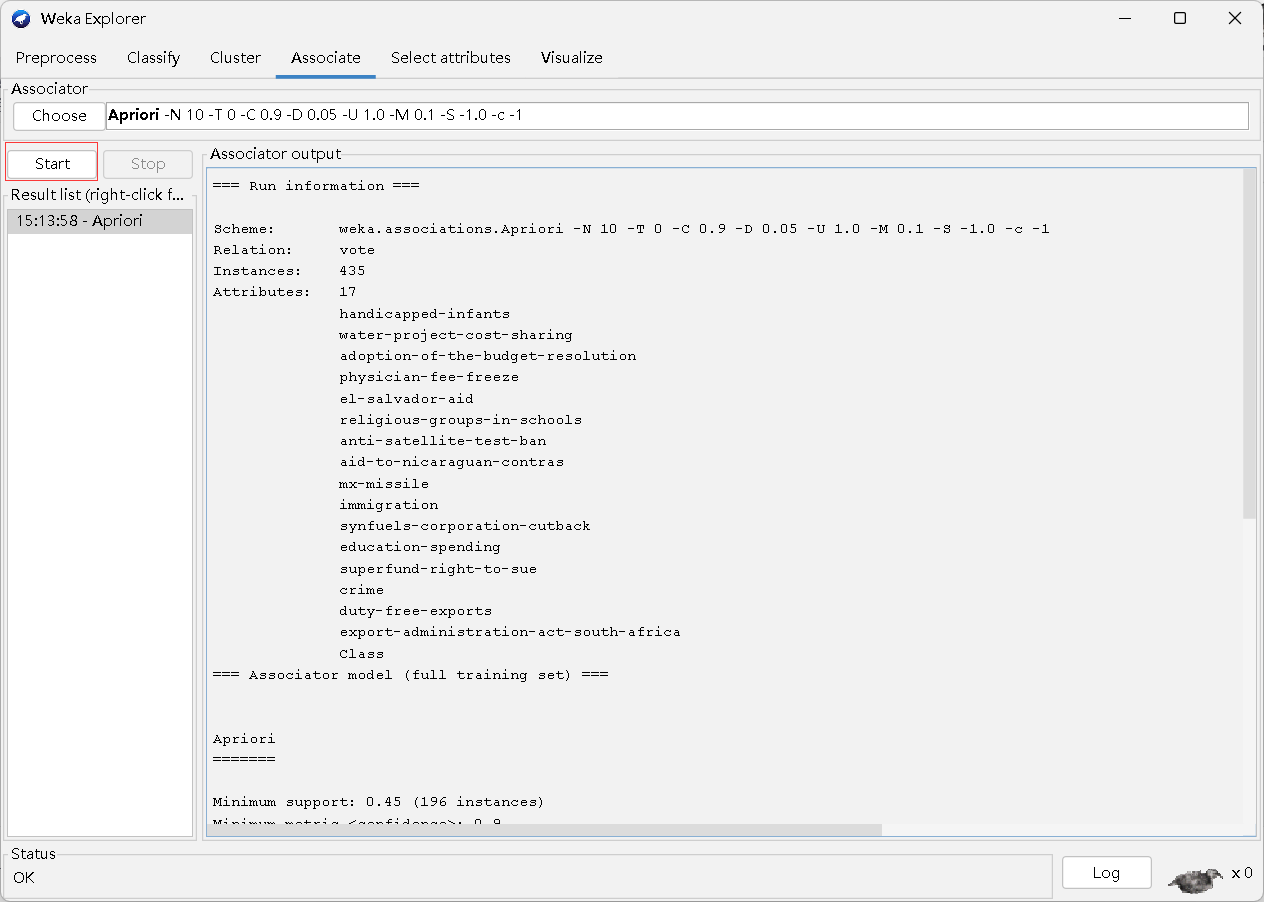
6.Select attributes
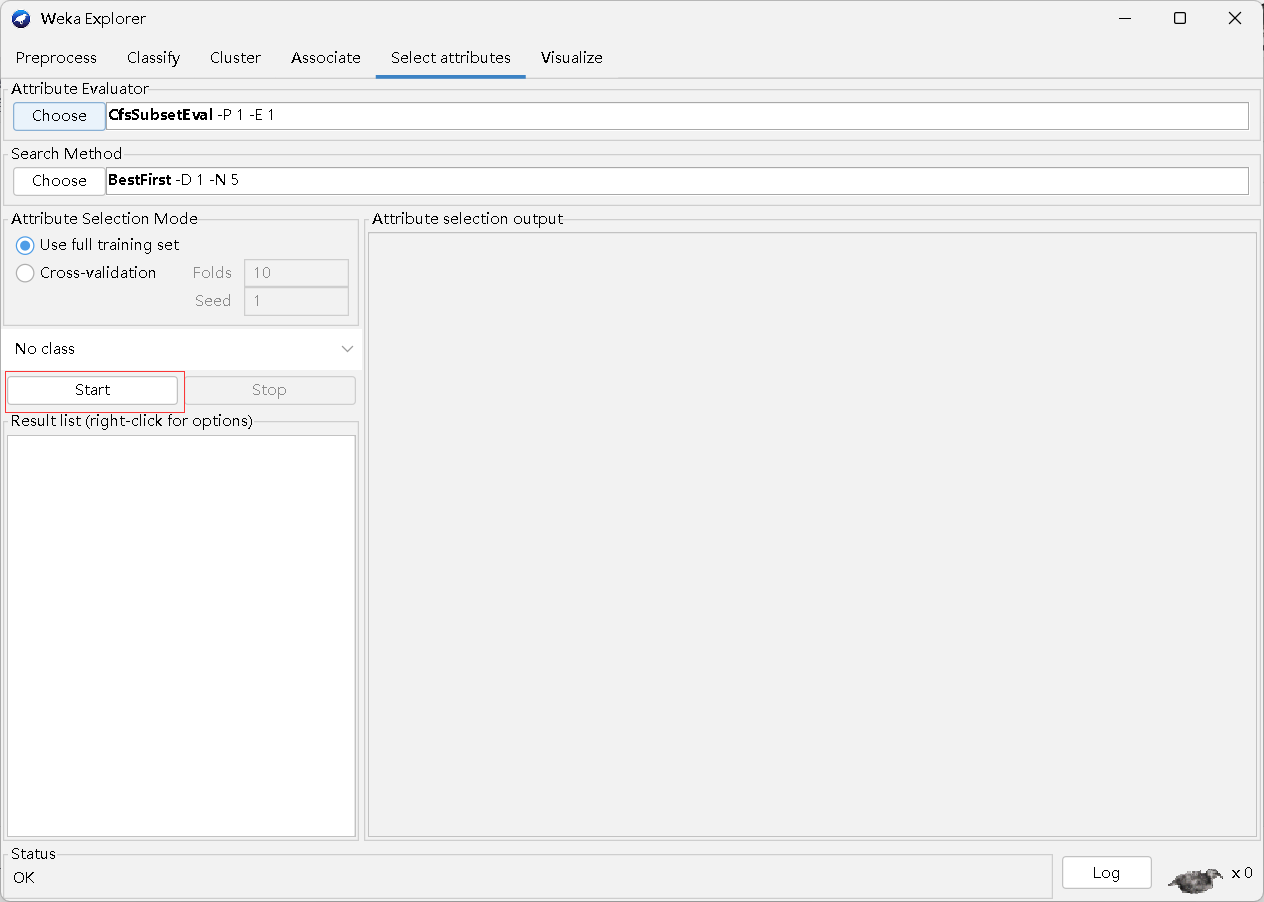
属性选择模式
-
Use full training set:使用完整的训练集
- Cross-validation:交叉验证
7.Visualize
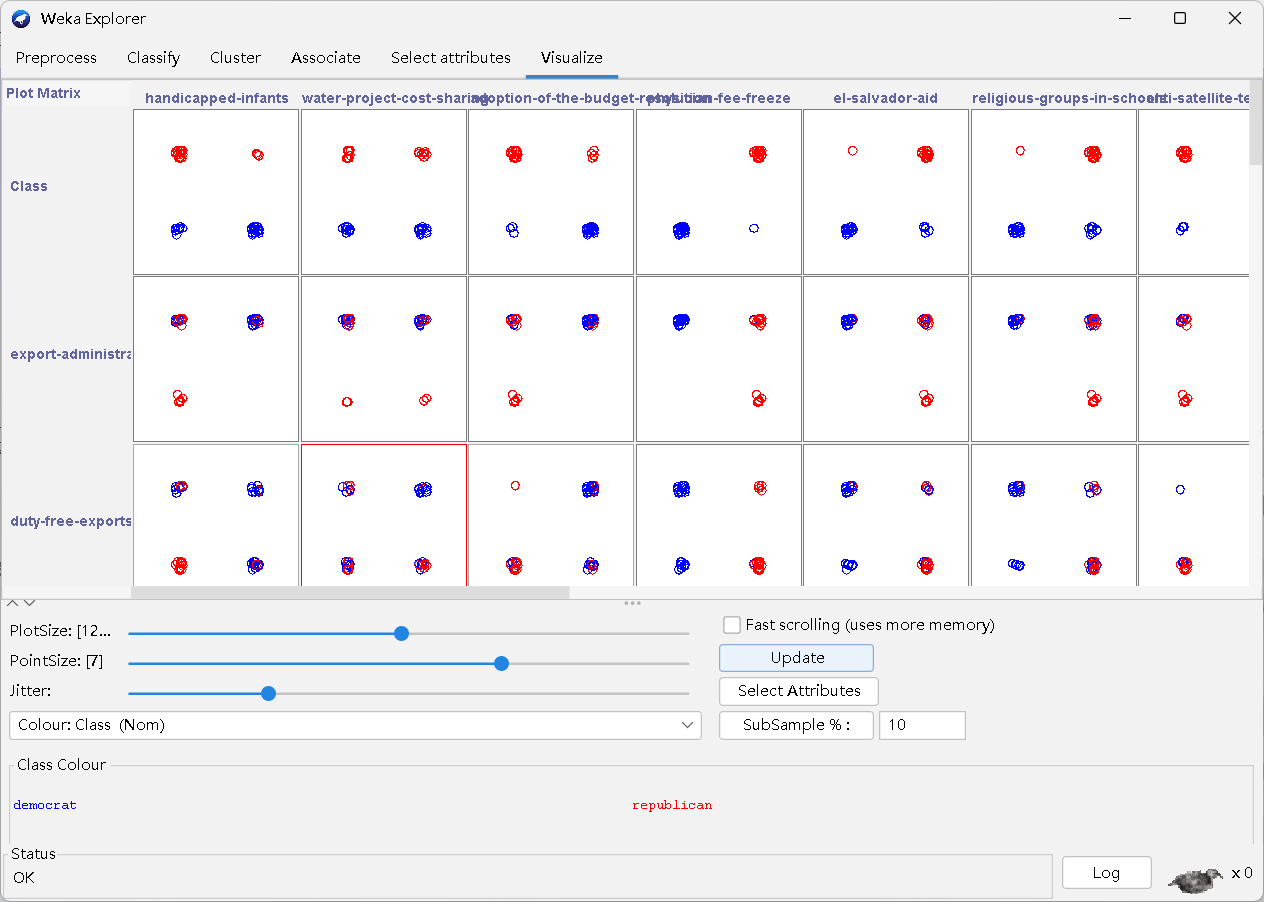
- update:更新
- select attribute:选择属性
- subsample:子样品