1. Kmeans算法的认识
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,也是一种无监督的机械学习算法。
聚类的认识
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。
k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。算法采用误差平方和准则函数作为聚类准则函数。
2. Kmeans具体的算法描述
需要把数据点分成三类。我们需要遵循下面的几个步骤
(注意:分类,其实是分割的意思,表达的意思是聚类。)
- 选取三个类的初始中心
- 计算剩余点到这三个中心的距离
- 将距离中心点距离最短的点归为一类
- 依次划分好所有的数据点
- 重新计算中心
- 重复2-5 个步骤,直到中心点不会在变化为止
第一步 选择中心点
随机选择坐标系上的几个点。
第二步 计算点之间的距离
两个点之间的距离用曼哈顿聚类距离,也可以叫做城市街区距离。
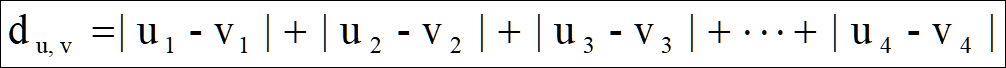
举例(一个二维的数据集)
坐标系上存在八个点:
A1 ( 2 ,10 )、 A2 ( 2 , 5 )、 A3 ( 8 , 4 ) 、A4 ( 5 , 8 )、 A5 ( 7 , 5) 、A6 ( 6 , 4) 、A7 ( 1 , 2 ) 、A8 ( 4 , 9 )
选择在XY坐标上的任意三个点,当然可以选择更多都是可以的。
这里选取的初始点是A1(2,10),A4(5,8),A7(1,2)分别命名为点1,点2,点3

点1和A1的曼哈顿聚类距离:| 2 - 2 | + | 10 - 10 | = 0
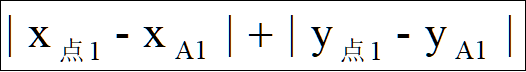
点2和A1的曼哈顿聚类距离:| 5 - 2 | + | 8 - 10 | = 5
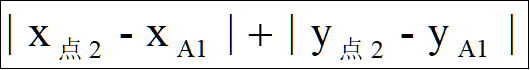
点3和A1的曼哈顿聚类距离:| 1 - 2 | + | 2 - 10 | = 9
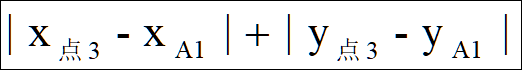
( 注意: 中心点的选取不同,最后的聚类结果可能大不相同 )
这时,已经得到了第一轮的结果,需要重新计算每个聚类中心

点1:
对于第一个聚类只有一个点所以它的聚类的中心就是自己
点2:
X :( 8 + 5 + 7 + 6 + 4 ) / 5 = 6
Y :( 4 + 8 + 5 + 4 + 9 ) / 5 = 6
中心点就是( 6 ,6 )
点3:
X :( 2 + 1 ) / 2 = 1.5
Y :( 5 + 2 ) / 2 = 3.5
这时,进行第二轮迭代:

这时,得到了第二轮的结果,也需要重新计算每个聚类中心
点1:
X :( 2 + 4 ) / 2 = 3
Y :( 10 + 9 ) / 2 = 9.5
点2:
X :( 8 + 5 + 7 + 6 ) / 4 = 6.5
Y :( 4 + 8 + 5 + 4 ) / 4 = 5.25
中心点就是(6,6 )
点3:
X :( 2 + 1 ) / 2 = 1.5
Y :( 5 + 2 ) / 2 = 3.5

这时,得到了第三轮的结果,还需要重新计算每个聚类中心
点1:
X :( 2 + 5 + 4 ) / 3 = 3.67
Y :( 10 + 8 + 9 ) / 3 = 9
点2:
X :( 8 + 7 + 6 ) / 3 = 7
Y :( 4 + 5 + 4 ) / 3 = 4.33
中心点就是(6,6 )
点3:
X :( 2 + 1 ) / 2 = 1.5
Y :( 5 + 2 ) / 2 = 3.5

此时,发现第四轮的结果和第三轮的结果一致了,可以停止该算法了。
可以看一下这个迭代过程的图谱
- 选择中心点后

- 依次迭代的过程:



