
这篇文章基于DCN(可变形卷积)提出了一种DCN变体TDAN,隐式的运动补偿机制,flow-free的方法。与VESPCN使用flow-based方法不同。VSR通常的结构都是对齐网络+融合SR网络。在这篇文章中,对齐网络部分提出了改进,融合SR部分还是使用普通的结构,融合采用的是最简单的早期融合。
原文链接:TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution
参考目录:超分之TDAN
TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution
Abstract
这篇文章出发点是:对齐多帧连续图像很重要,但是基于光流flow-based的方式来对齐参考帧与支持帧,很容易出现伪影。于是提出了一种flow-free的方法。
- 由于摄像机或物体的不同运动,参考帧和每个支持帧没有对齐。因此,时间对齐对VSR来说是一个关键的步骤。以前的VSR方法都是基于光流来进行时间对准,但是这种方法非常
依赖于光流估计,如果估计值不准,那么会很大程度的影响到后续图像重建的质量。
为了解决这个问题,作者提出了一种时间可变形对齐网络(TDAN),在不计算光流的情况下,在特征级自适应对齐参考帧和每个支持帧。TDAN的对齐方法是基于DCN的一种变体。与DCN类似,TDAN使用来自参考帧和每个支持帧的特征来动态预测偏移量。通过使用相应的核进行卷积,TDAN网络使支持帧与参考帧对齐。TDAN能够缓解重建过程出现的遮挡和伪影。
VESPCN中对齐模块使用的是STN的变体,原理是学习图像两帧之间的运动估计得到运动矢量,然后通过重采样的方式来恢复支持帧的估计值,并且使其近似于参考帧。这个过程中需要用到图像运动的分析,光流是一定存在的。且输入运动估计模块的是图像本身,所以这个过程是image-wise的。
TDAN中对齐模块使用的是DCN的变体,原理是通过学习特征图像采样位置的偏移来确定偏移后的特征值,并趋近于参考帧的特征,是一种feature-wise的方法,且避免了光流估计。
1 Introduction
在视频超分任务中,由于相机抖动和物体的运动,会导致不同帧间图像发生变化,因此对齐相邻帧图像是必不可少的一个步骤。以往的对齐方式都是基于光流flow-based的方法,但其过于依赖运动估计的准确性,使得光流估计的误差很容易导致输出估计图像产生各种artifacts。
对此本文提出了一种不基于光流flow-free的对齐方法TDAN,一种隐式的运动补偿机制,通过学习支持帧特征位置的偏移,让卷积核提取变换后的特征图新位置像素,再重建支持帧,能够有效的避开光流方法。TDAN具有很强的能力和灵活性,能够处理时态场景中的各种运动条件。
本文的贡献有三个方面:
- 提出了一种
one-stage的特征级可变形对齐网络(TDAN),是一种flow-free方法; - 网络整体由两部分组成:基于DCN的对齐网络TDAN + 融合SR网络,是一种端到端可训练VSR框架;
- 在Vid4数据集上实现了SOTA的表现。
2 Method
2.1 Overview
整体结构:
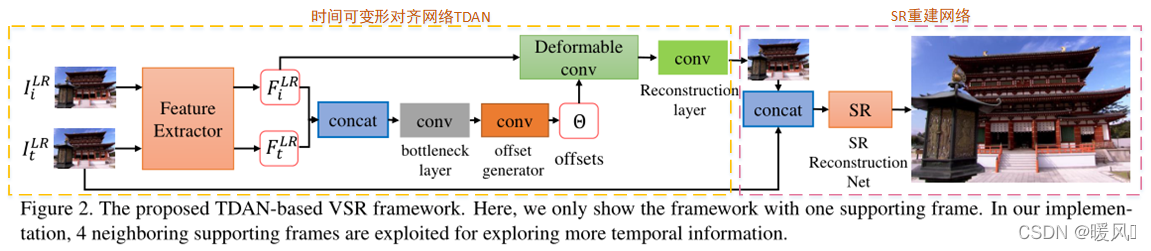
由两个子网络组成:一个用于将每个支持帧与参考帧对齐的时间可变形对齐网络(TDAN)和一个用于预测HR帧的SR重建网络。
接下来用 I t L R ∈ R H × W × C I_t^{LR}\in\mathbb{R}^{H\times W\times C} ItLR∈RH×W×C 表示视频第 t t t帧, I t H R ∈ R s H × s W × C I_{t}^{HR}\in \mathbb{R}^{sH\times sW\times C} ItHR∈RsH×sW×C 表示视频第 t t t帧对应的高分辨率图像,即Ground Truth,其中 s s s为SR放大倍率,而 I t H R ′ ∈ R s H × s W × C I_t^{HR'}\in\mathbb{R}^{sH\times sW\times C} ItHR′∈RsH×sW×C 表示超分的结果。
VSR的目标就是每次将视频中连续的2 N + 1 N+1 N+1帧 { I i L R } t − N t + N \{I_i^{LR}\}^{t+N}_{t-N} {
IiLR}t−Nt+N 输入进网络,超分出 I t H R ′ I_t^{HR'} ItHR′。
在这 2 N + 1 2N+1 2N+1帧中,第 t t t帧 I t L R I_t^{LR} ItLR为参考帧,其余 2 N 2N 2N帧 { I t − N L R , ⋯ , I t − 1 L R , I t + 1 L R , ⋯ , I t + N L R } \{I_{t-N}^{LR},\cdots, I_{t-1}^{LR}, I_{t+1}^{LR},\cdots, I_{t+N}^{LR}\} {
It−NLR,⋯,It−1LR,It+1LR,⋯,It+NLR}为支持帧。
整体网络结构分为两部分:
TDAN对齐网络。对齐物体或相机运动带来的内容不匹配问题。SR重建网络。将对齐后的 2 N + 1 2N+1 2N+1帧进行融合然后超分的过程。
TDAN对齐网络:
对齐网络每次输入2帧,其中一帧是固定参考帧 I t L R I_t^{LR} ItLR,另一帧是支持帧 I i L R , i ∈ { t − N , ⋯ , t − 1 , t + 1 , ⋯ t + N } I_i^{LR},i\in\{t-N, \cdots, t-1,t+1, \cdots t+N\} IiLR,i∈{
t−N,⋯,t−1,t+1,⋯t+N}, f T D A N ( ⋅ ) f_{TDAN}(\cdot) fTDAN(⋅)表示对齐算子。 I i L R ′ I_i^{LR'} IiLR′为支持帧 I i L R I_i^{LR} IiLR和参考帧 I t L R I_t^{LR} ItLR对齐之后的结果,也就是 I i L R I_i^{LR} IiLR的估计值。对齐网络表达式为:
I i L R ′ = f T D A N ( I t L R , I i L R ) . (1) I_i^{LR'} = f_{TDAN}(I_t^{LR}, I_i^{LR}).\tag{1} IiLR′=fTDAN(ItLR,IiLR).(1)
SR重建网络:
该部分的输入是 2 N 2N 2N个对齐后的支持帧和参考帧一起输入进SR网络来重建出高分辨率图像,表达式如下:
I t H R ′ = f S R ( I t − N L R ′ , ⋯ , I t − 1 L R ′ , I t L R , I t + 1 L R ′ , ⋯ I t + N L R ′ ) (2) I_t^{HR'} = f_{SR}(I_{t-N}^{LR'},\cdots, I_{t-1}^{LR'}, {I_{t}^{LR}},I_{t+1}^{LR'},\cdots I_{t+N}^{LR'})\tag{2} ItHR′=fSR(It−NLR′,⋯,It−1LR′,ItLR,It+1LR′,⋯It+NLR′)(2)
2.2 Temporally Deformable Alignment Network
本节是本文最重要的部分,也就是文章提出的TDAN网络。用于对齐支持帧 I i L R I_i^{LR} IiLR和参考帧 I t L R I_t^{LR} ItLR。
使用的是DCN的变体,加入了时间元素。整个过程和DCN大体相同。DCN是单张图像输入,参考帧作为最后的标签;而TDAN是同时输入两帧(支持帧 I i L R I_i^{LR} IiLR和参考帧 I t L R I_t^{LR} ItLR),参考帧又作为标签。
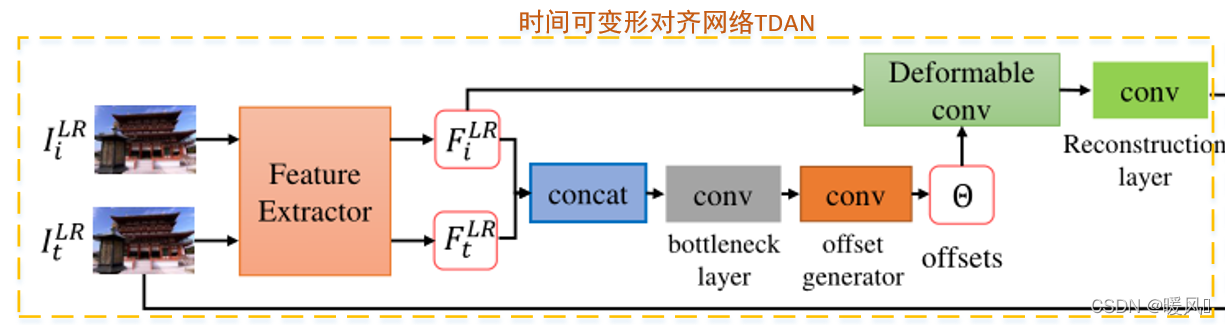
TDAN网络主要包括三个部分:特征提取、变形对齐和对齐帧重建
特征提取:
该部分由一个卷积层和EDSR中相似的 k 1 k1 k1个残差块组成,ReLU作为激活函数,提取参考帧 I t L R I_t^{LR} ItLR和支持帧 I i L R I_i^{LR} IiLR的特征 F t L R 、 F i L R F_t^{LR}、F_i^{LR} FtLR、FiLR,用于feature-wise的时间对齐。
变形对齐:
首先将提取的特征 F t L R 、 F i L R F_t^{LR}、F_i^{LR} FtLR、FiLR拼接concat后经过bottleneck layer(3×3),这层的作用是减小输入feature map的特征通道数。然后经过offset generator层,预测整个图像的偏移参数 Θ \Theta Θ。 Θ \Theta Θ的 h × w h×w h×w和输入feature map一样,通道数为 ∣ R ∣ |\mathcal{R}| ∣R∣。公式中 f θ ( ⋅ ) f_\theta(\cdot) fθ(⋅)表示上述过程:特征提取部分公式为:
Θ = f θ ( F i L R , F t L R ) . (2) \Theta = f_\theta(F_i^{LR}, F_t^{LR}).\tag{2} Θ=fθ(FiLR,FtLR).(2)
Θ = { Δ p n ∣ n = 1 , ⋯ , ∣ R ∣ } \Theta = \{\Delta p_n | n=1,\cdots, |\mathcal{R}|\} Θ={
Δpn∣n=1,⋯,∣R∣}, ∣ R ∣ |\mathcal{R}| ∣R∣为卷积核总参数个数,比如对于一个 3 × 3 3\times 3 3×3卷积核来说 ∣ R ∣ = 9 |\mathcal{R}| = 9 ∣R∣=9。
Offset在DCN原论文中为2 ∣ R ∣ |\mathcal{R}| ∣R∣,分别表示x、y方向的偏移;在TDCN中为 ∣ R ∣ |\mathcal{R}| ∣R∣,直接学习的是x、y的合成方向。
有了offset位置偏移 Θ \Theta Θ后,将偏移量加到特征图像对应位置上,再使用卷积抓取偏移位置像素值进行计算。
f d c ( ⋅ ) f_{dc}(\cdot) fdc(⋅)为可变形卷积算子,将 Δ p n \Delta p_n Δpn加到输入feature map F i L R F_i^{LR} FiLR对应位置上,然后用卷积核 R \mathcal{R} R去提取偏移后的采样点,变形对齐公式如下:
F i L R ′ = f d c ( F i L R , Θ ) . (3) F_i^{LR'} = f_{dc}(F_i^{LR}, \Theta).\tag{3} FiLR′=fdc(FiLR,Θ).(3)
w ( p n ) w(p_n) w(pn)为卷积核位置 p n p_n pn的可学习参数, p 0 p_0 p0为 F i L R F_{i}^{LR} FiLR的整数格点位置, F i L R ′ F_i^{LR'} FiLR′就是可变形卷积的输出,可变形卷积的具体过程可表示成:
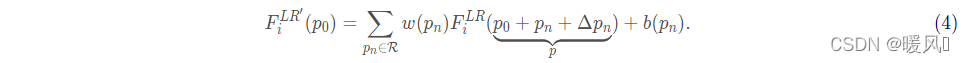
由于偏移量一般不是整数,而是浮点数,我们不能直接得到非整数坐标处对应的像素值,因此需要通过插值来获取对应值,这一步和DCN是完全相同的。
- 作者
串联使用四个可变形卷积层来增强变换对齐模块的灵活性和能力。 - 参考帧 F t L R F_t^{LR} FtLR的特征仅用于计算偏移,其信息不会传递到对齐后的支持帧 F i L R F_i^{LR} FiLR中。
为什么说TDAN是隐式的运动补偿?
- 在STN中,光流估计分为两步:运动估计+运动补偿。根据映射关系,求出偏移量,然后得到对应位置,再重采样。是针对图像进行操作的。关键在于重采样直接计算(复制)出了对应位置的像素值,得到了输出图像。
- 在TDAN中,通过卷积学习位置偏移量,得到输入的特征位置偏移,用卷积去抓取偏移位置的像素,做卷积。是针对特征图像进行操作的。卷积抓取偏移位置的像素,再经过卷积计算,这一步考虑到了该位置周边卷积核大小的环境因素,得到的输出特征是输入feature map周围一个卷积核运算范围内的卷积结果。容错率更高,同时避开了光流估计,有更强的探索能力。
对齐帧重建:
经过前述步骤得到可变形卷积后对齐的特征图像 F i L R ′ F_i^{LR'} FiLR′,对其恢复重建就能得到我们想要的支持帧估计值 I i L R ′ I_i^{LR'} IiLR′。
使用一个反卷积的过程将feature map重建成Image,作者使用了一个 3 × 3 3\times 3 3×3的卷积层来实现。
这一步重建也很关键,虽然可变形对齐能捕捉运动线索,将 F t L R 、 F i L R F_t^{LR}、F_i^{LR} FtLR、FiLR对齐,但如果没有这一层的重建层后和 I t L R I_t^{LR} ItLR做loss,隐式对齐很难学习。利用这一步的监督对齐损失来强制可变形对齐模块捕捉运动,并在特征级别对齐两帧。
2.3 SR Reconstruction Network
在将2N个参考帧和支持帧对经过TDAN后,获得相应的2N个对齐LR帧,就可以用于重建HR视频帧了。
本文的重心在于提出了时间对齐网络TDAN,融合SR重建网络没有进行改进,所以使用的是比较简单的结构。

该部分网络的输入是对齐后的2N+1个相邻帧 I t − N L R ′ , ⋯ , I t − 1 L R ′ , I t L R , I t + 1 L R ′ , ⋯ I t + N L R ′ I_{t-N}^{LR'},\cdots, I_{t-1}^{LR'}, {I_{t}^{LR}},I_{t+1}^{LR'},\cdots I_{t+N}^{LR'} It−NLR′,⋯,It−1LR′,ItLR,It+1LR′,⋯It+NLR′,输出为超分辨率重建后的图像 I t H R ′ I_t^{HR'} ItHR′。
这部分网络分为三个部分:时间融合 + 非线性映射 + HR帧重建 (就是常规的融合+SR重建网络)
时间融合:
时间融合部分作者使用了最简单的Early fusion(其实就是concat拼接2N+1帧),然后使用一个 3 × 3 3\times 3 3×3卷积来进行浅层特征提取。(VESPCN中提出了三种时间融合的方法:Early fusion、Slow fusion以及3D卷积。)
非线性映射:
采用k2个残差块进行堆叠,来提取深层特征。(残差块的结构与EDSR类似)
重建层
在LR空间中提取深层特征后,使用ESPCN中提出的亚像素卷积作为上采样,重建高分辨率图像。对于×4放大倍数,将使用两个亚像素卷积模块。最后再接一个卷积层进行调整,最后输出最终的重建图像 I t H R ′ I_t^{HR'} ItHR′。
2.4 Loss Function
本文提出的网络结构有两个损失函数,对齐网络TDAN损失 L a l i g n \mathcal{L}_{align} Lalign 和SR超分网络损失 L s r \mathcal{L}_{sr} Lsr
对于对齐模块,目的是让支持帧的估计值 I i L R ′ I_{i}^{LR'} IiLR′尽可能靠近参考帧 I t L R I_{t}^{LR} ItLR,从而让相邻帧的内容对齐到参考帧使得时间上更加连续,使用参考帧作为伪标签,这一部分属于自监督的训练,因为其本身并没有明确的标签信息(Ground Truth)。TDAN L a l i g n \mathcal{L}_{align} Lalign损失函数表达式为:
L a l i g n = 1 2 N ∑ i = t − N , ≠ t ∣ ∣ I i L R ′ − I t L R ∣ ∣ . (5) \mathcal{L}_{align} = \frac{1}{2N}\sum_{i=t-N,\ne t}||I_i^{LR'} - I_t^{LR}||.\tag{5} Lalign=2N1i=t−N,=t∑∣∣IiLR′−ItLR∣∣.(5)
对于重建模块,SR网络损失函数使用 L 1 L_1 L1损失(1范数损失):
L s r = ∣ ∣ I t H R ′ − I t H R ∣ ∣ 1 . (6) \mathcal{L}_{sr} = ||I_t^{HR'} - I_t^{HR}||_1.\tag{6} Lsr=∣∣ItHR′−ItHR∣∣1.(6)
最终要优化的损失函数是上述两者之和,将对齐子网络和超分子网络放一起训练,因此整个TDAN模型的训练是端对端的。完整的损失函数表达式为:
L = L a l i g n + L s r . (7) \mathcal{L} = \mathcal{L}_{align} + \mathcal{L}_{sr}.\tag{7} L=Lalign+Lsr.(7)
2.5 Analyses of the Proposed TDAN
TDAN可以采用时间对齐方式来将给定的一个参考帧和一组支持帧对齐。总结TDAN的几个优点:
- one-stage:
Ⅰ Ⅰ Ⅰ 以前的时间对准方法大多基于光流,是一种image-wise的two-stage方法。光流将时间对准问题分为两个子问题:流/运动估计和运动补偿。这些方法的性能在很大程度上取决于光流估计的准确性,很容易引入伪影。
Ⅱ Ⅱ Ⅱ 而TDAN是一个feature-wise的单阶段方法,它在特征级别对齐支持帧。通过自适应学习采样点的偏移位置并进行卷积,隐式地捕获运动线索,而无需显式地估计运动场,并根据对齐的特征重建恢复出我们要估计的对齐帧。 - 自监督训练:TDCN的训练属于自监督训练,因为我们并没有 I i L R ′ I_{i}^{LR'} IiLR′对应的标签,只是用参考帧来作为伪标签。
- 探索能力:
Ⅰ Ⅰ Ⅰ 在光流方法中,对于一帧中的每个位置,光流计算的运动场仅指一个潜在位置p。意思就是说,STN方法通过映射关系找到变换前的位置p,再经过重采样,得到该处的像素值。利用的仅是这一个位置p。
Ⅱ Ⅱ Ⅱ 而DCN方法,找到偏移后的位置p的像素值后,还进行了卷积,也就是说了还利用了卷积大小范围内的更多特征,这些特征可能与p具有相同的图像结构,并且有助于聚合更多上下文,以便更好地重建估计帧。(这个卷积范围不是指往常的例如3×3方框,因为被卷积的位置进行了偏移变形,所以是对应于变形后的范围,当然还是要强调一下,卷积核并没有变形,变形的是输入feature map的位置)(找到偏移位置的时候两种方法都利用了插值,关键在于DCN使用了卷积。) 还有一点就是本文中的TDAN方法,对特征进行了重建输出了恢复图像,恢复图像和参考帧进行了loss,这一步的监督也很重要,强制可变形对齐模块捕捉运动进行对齐,如果没有这个监督,隐式学习很难对齐。 - 通用性:提出的TDAN是一个通用的时间对齐框架,可以很容易地用于替代其他任务的基于流的运动补偿,例如视频去噪、视频去块、视频去模糊、视频帧插值,甚至视频预测。
3 Experiments
setting:
作者采用Vimeo视频超分数据集作为训练集,这是一个包含了64612个样本的数据集,其中每个样本包含了连续7帧的 448 × 256 448\times 256 448×256的视频。因此其并没有高分辨率的训练集, 448 × 256 448\times 256 448×256也只是从原视频中resize出来的;作者采用Temple序列作为验证集,Vid4作为测试集,其中包括{city,walk,calendar, foliage}四个场景。
SR缩放倍率r=4
Patch大小48 × 48
Batch=64
每个样本包含连续5帧
Adam优化,初始学习率为 1 0 − 4 10^{-4} 10−4,每过100个epochs,下降一半。
具体实验部分可以参看博文超分之TDAN
- SISR方法都是按独立帧去处理的,没法利用时间冗余信息,so表现力弱于VSR方法。
- two-stage方法表现力也同样低于one-stage的TDAN,证明了one-stage对齐方法的优越性。
- 作者还对比了模型大小,TDAN网络更轻量,但有更好的效果;DUF比TDAN轻量,但效果不如TDAN。
- 作者还进一步比较了有无TDAN子网络,串联不同数量可变形卷积对结果造成的影响
- 作者也在真实场景的视频超分中做了实验对比
- 最后作者分析了TDAN的局限性
①数据集:实验训练集只是较小的低分辨率集448 × 256,因此无法训练出一个更深的网络以及得到更好的重建质量。故障案例中可以看到:在DIV2K上训练的RCAN可以准确地恢复城市视频帧中显示的图像区域的结构, 因为DIV2K图像数据集分辨率很高,所以RCAN可以准确重建图像细节,而Vimeo数据集分辨率低,很难训练非常深的网络,所以TDAN没法恢复更精细的图像结构和细节。证明了一个较大较高清(比如2k、4k)的数据集的重要性。
②融合方式:在TDAN中,重点改进了对齐网络,只使用了简单的Early fusion来做融合,但扩展更优秀的融合方法会使网络性能更好。
③对齐LOSS:还可以改进对齐LOSS,在本文中使用的对齐标签是参考帧,是伪标签。作者指出可以使用这篇文章Learning with Noisy Labels中的方法去进一步改善噪声标签问题。
4 Conclusion
这篇文章提出了一种用于视频超分辨率的时间对齐网络:TDAN。
特点:one-stage 、 feature-wise 、 flow-free 、隐式地捕捉运动信息、能够探索图像上下文信息
最后祝各位科研顺利,身体健康,万事胜意~