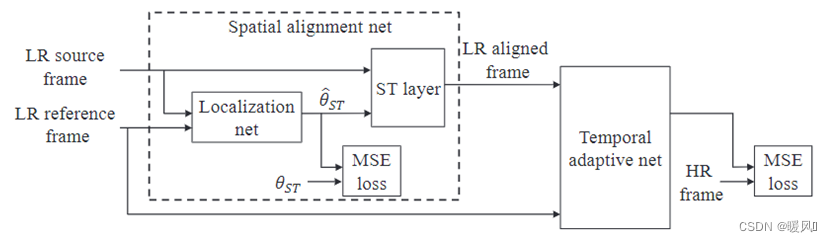
这篇文章的重点在于Robust,也就是说作者提出的方法都有利于网络的稳定和减少错误的发生。VSR任务的架构分为对齐和融合SR。在对齐部分作者提出了spatial alignment network时间对齐网络;在融合SR部分作者提出了空间自适应网络temporal adaptive neural network。
原文链接:RVSR: Robust Video Super-Resolution With Learned Temporal Dynamics【2017 ICCV】
参考文章:超分之Robust VSR with Learned Temporal Dynamics
RVSR: Robust Video Super-Resolution With Learned Temporal Dynamics
Abstract
SISR任务都是充分利用单张图像的空间信息,而VSR任务,因为有时间上相邻的多帧,所以帧间的时间信息也非常重要。非常复杂的运动很难建模,不当的处理会对图像重建产生不利的影响。怎样合理高效的利用帧间的时间信息就非常关键了。因此作者从两个方面提出了想法:
- 提出了空间自适应神经网络temporal adaptive neural network。可以自适应的确定最优的时间依赖的尺度(融合几个连续帧),在融合使用不同时间尺度的滤波器。
- 提出了时间对齐网络spatial alignment network。为了减小相邻帧之间的运动复杂度。减小运动补偿的误差对后续网络训练的影响,从而达到更高的稳定性和鲁棒性。
- 时间对齐网络和空间自适应融合网络是串联结构,从而使整个网络成为一个端到端训练的网络。
1 Introduction
作者为了提高网络的稳定性,从减小网络误差的目的出发提出了两种针对光流估计不精确的问题改进的方法。整体网络分为两个部分:空间对齐网络和时间自适应网络串联组成。
对齐模块在基于光流的方法中,非常的依赖运动估计的准确性。平滑微小的运动非常容易捕捉还原,如果出现复杂大幅度的运动,那么在运动估计的时候很容易出现大的误差,(在大运动的过程中,很难猜测是怎样的一个轨迹)。而不精确的运动估计会严重影响到SR的效果。
-
基于这个问题,作者在提出了时间自适应网络,能够稳定地处理各种类型的运动,并自适应地选择最佳的时间依赖范围,以减轻连续帧之间错误运动估计的不利影响。该网络将经过运动补偿的多个对齐的LR帧作为输入,并应用不同时间大小的滤波器来生成多个HR帧估计图像。同时根据网络中的另一条分支推断出的运动补偿置信度,自适应地聚合生成的多个HR估计。(受GoogLeNet Inception module的启发)对光流质量的改进:①高计算成本的方式DBLP ②仅从单一固定时间尺度提取运动信息VSRCNN。而该模型是通过网络在不完美的运动补偿中学习寻找一种平衡,从而达到鲁棒性。
-
除了在时间域对运动信息进行建模外,还可以在空间域对运动进行补偿,从而有助于时间域的建模。作者发现基于复杂光流的方法可能不是最佳的,因为复杂运动的估计误差会对后续的SR产生不利影响。因此,只需估计
少量的空间变换参数,就可以减少运动的复杂性,并且为对齐不同帧提供了一种更加稳定的方法。提出了一种空间对齐网络,推导出合适的帧之间的空间变换,并生成对齐的支持帧。该方法需要的时间短,可与时域自适应网络级联,联合训练。
2 Temporal Adaptive Neural Network
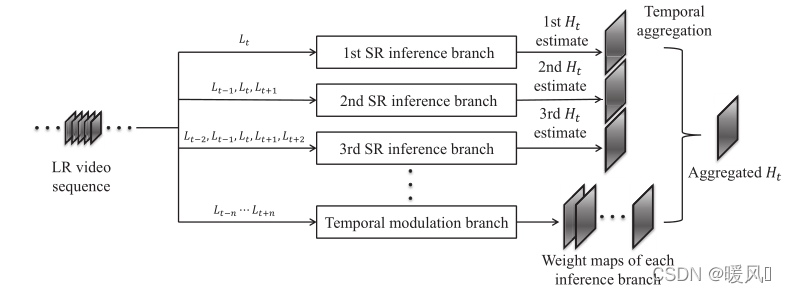
对于VSR,最主要的就是如何利用时间信息来处理各种类型的运动。作者设计了一种能自适应的学习最优时间尺度。主要分为两个部分:多个SR重建分支和时间调制分支组成。用N种时间滤波器各自超分得到SR图像 H t i H_t^i Hti;时间调制分支获取前面N个分支的注意力权重;使用权重融合前面N张SR图像 H t i H_t^i Hti得到最后输出 H t H_t Ht。
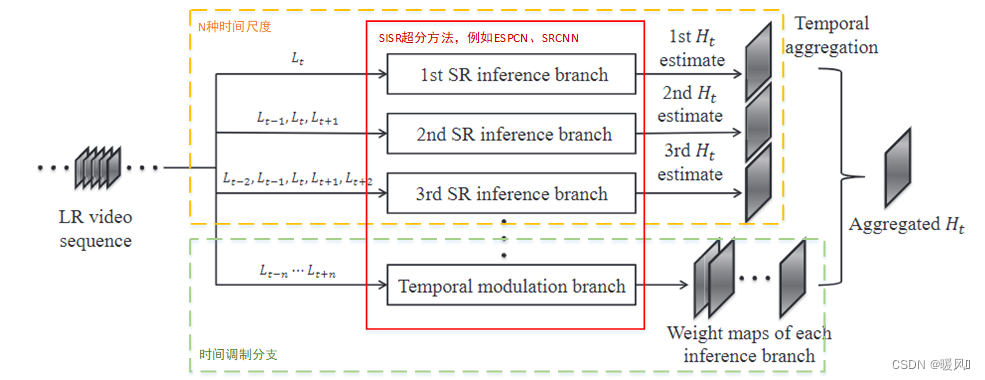
SR前向分支:
一共有N条分支 { B i } i = 1 N \{B_i\}^N_{i=1} {
Bi}i=1N(N种时间尺度),每条使用不同数量的时间滤波器,各自独立完成SR重建工作,得到不同的重建图像 H t i H_t^i Hti。第 i i i条分支 B i Bi Bi,输入为 2 i − 1 2i-1 2i−1个相邻帧,采用最简单的早期融合对 2 i − 1 2i-1 2i−1个相邻帧进行拼接,该融合方式下输入格式为 ( B a t c h , ( 2 i − 1 ) ∗ c , H , W ) (Batch, (2i-1)*c, H, W) (Batch,(2i−1)∗c,H,W),其中c是每一帧的通道数。然后输入SR网络,在本文中使用的是ESPCN,也可以使用其他结构,比如SRCNN等。
时间调制分支:
用于选择最优的时间尺度(这里其实是选择最优的时间尺度权重分配,并不是N选1),是pixel-wise级的。它具有和SR前向分支相同的网络结构。不同于SR前向分支,该分支输入为前向分支中最长时间序列,即 2 N − 1 2N-1 2N−1个连续帧,这样做也是为了更加全面的覆盖前向分支所有的输入情况。该分支的输出是 N N N张权重图 W i W_i Wi,将每张权重图和前面分支的输出 H t i H_t^i Hti进行元素相乘,最后将N个结果相加得到最后的输出 H t H_t Ht。 H t = ∑ i W i ⊙ H i t , i ∈ { 1 , ⋯ , N } H_t = \sum_i W_i\odot H_i^t, i\in\{1,\cdots,N\} Ht=i∑Wi⊙Hit,i∈{
1,⋯,N}
LOSS:
时间自适应网络的损失函数使用L2LOSS:
min Θ ∑ j ∣ ∣ F ( y ( j ) ; Θ ) − x ( j ) ∣ ∣ 2 2 . (1) \min_{\Theta} \sum_j ||F(y^{(j)};\Theta) - x^{(j)}||_2^2.\tag{1} Θminj∑∣∣F(y(j);Θ)−x(j)∣∣22.(1)
其中 x ( j ) x^{(j)} x(j)是第 j j j个参考帧对应的HR图像,即Ground Truth; y ( j ) y^{(j)} y(j)代表以第 j j j帧参考帧为中心的所有对齐帧,故 F ( y ( j ) ; Θ ) F(y^{(j)};\Theta) F(y(j);Θ)表示整个时间自适应网络的输出 H t H_t Ht。
将其细化表示为:
min θ w , { θ B i } i = 1 N ∑ j ∣ ∣ ∑ i = 1 N W i ( y ( j ) ; θ w ) ⊙ F B i ( y ( j ) ; θ B i ) − x ( j ) ∣ ∣ 2 2 . (2) \min_{\theta_w,\{\theta_{B_i}\}_{i=1}^N} \sum_j ||\sum^N_{i=1}W_i(y^{(j)};\theta_w)\odot F_{B_i}(y^{(j)};\theta_{B_i}) - x^{(j)}||^2_2.\tag{2} θw,{
θBi}i=1Nminj∑∣∣i=1∑NWi(y(j);θw)⊙FBi(y(j);θBi)−x(j)∣∣22.(2)
其中 W i W_i Wi表示时间调制网络输出不同时间尺度下的权重图, θ w \theta_w θw表示时间调制网络的参数, F B i ( y ( j ) ; θ B i ) F_{B_i}(y^{(j)};\theta_{B_i}) FBi(y(j);θBi)表示第 B i B_i Bi个SR前向分支的输出 H t i H_t^i Hti,参数 θ B i \theta_{B_i} θBi表示第 B i B_i Bi个SR前向分支的网络参数; ⊙ \odot ⊙表示元素级相乘。
训练时先独立训练N个SR前向分支,获得了N个类似结构的ESPCN网络;然后将训练好的参数作为时间自适应网络的初始化参数,利用式(2)去训练时间调制分支和在各个SR前向分支上微调。该种方法可以使网络加速收敛。
3 Spatial Alignment Methods
VSR任务中经常通过在时间上对齐连续帧来增加空间相关性,图像对齐作为预处理步骤已经被证明能提高VSR任务的性能。
3.1 Rectified Optical Flow Alignment
复杂的运动很难建模,光流方法基于图像的对齐,不准确的运动估计会引入artifacts,从而影响到后续SR重建的质量。作者尝试简化patch级的运动来得到整数偏移来避免插值带来的混叠或者模糊。作者提出了矫正光流对齐方法。
矫正光流对齐:
输入一个patch,计算patch内参考帧和支持帧之间的光流信息,分别在水平方向和垂直方向上计算所有像素的水平位移和垂直位移的平均值,四舍五入取整数。作为这个patch的平均光流信息。得到该patch的两个方向整数位移: θ S T x 、 θ S T y \theta_{ST}^x、\theta_{ST}^y θSTx、θSTy。遍历参考帧和支持帧所有的patch就可以得到所有的整数平均光流。假设一帧有M个patch,每一个patch输出2个变换参数,一共获得2M个变换参数。(将这些运动矢量作用于支持帧,就可以获得支持帧的一个估计值,但用到的并非这个估计值,而是该过程中得到的2M个整数光流信息 θ S T x 、 θ S T y \theta_{ST}^x、\theta_{ST}^y θSTx、θSTy)。
3.2 Spatial Alignment Network
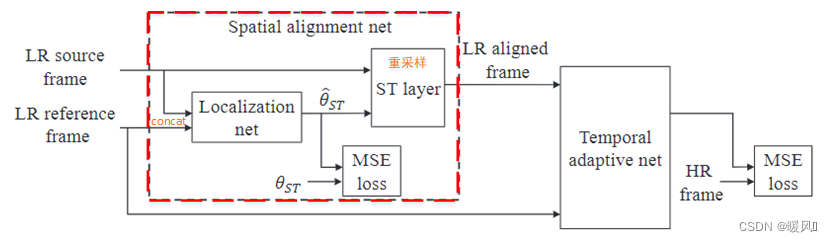
空间对齐网络的输入一般是2个相邻帧,其中一个是固定的参考帧 I t I_t It,另一个是前面所述时间自适应网络的时间窗口内的支持帧,最终输出是支持帧的对齐估计值。求得 2 N − 1 2N-1 2N−1个连续对齐的支持帧后,输入后面的时间自适应网络,重建该参考帧的高分辨率图像。
- 获得回归变换参数 θ ^ S T \hat{\theta}_{ST} θ^ST:
首先2帧相邻图像通过Early fusion输入Localisation网络(即深度为 2 × c 2\times c 2×c),回归出变换参数 θ ^ S T \hat{\theta}_{ST} θ^ST,分别输出水平方向的变换和垂直方向的变换。将回归出的参数和Rectified Optical Flow Alignment输出的参数标签做MSE损失来辅助优化Localization网络的变换参数。由于Rectified Optical Flow Alignment(ROF)是基于patch的,因此我们在Localisation网络也是基于patch-wise的。
具体Localisation网络结构是:卷积+最大值池化+卷积+最大值池化+全连接+全连接。
参数为: C o n v ( 2 c , 32 , 9 ) − M a x P o o l ( 2 , 2 ) − C o n v ( 32 , 32 , 9 ) − M a x P o o l ( 1 , 2 ) − F C N ( 32 , 100 ) − F C N ( 100 , 2 ) Conv(2c,32,9)-MaxPool(2,2) - Conv(32,32,9) - MaxPool(1,2) - FCN(32,100) - FCN(100,2) Conv(2c,32,9)−MaxPool(2,2)−Conv(32,32,9)−MaxPool(1,2)−FCN(32,100)−FCN(100,2)
C o n v ( i n p u t _ c h a n n e l , o u t _ c h a n n e l , k e r n e l _ s i z e ) , M a x P o o ( k e r n e l _ s i z e , s t r i d e ) , F C N ( i n p u t _ n u m s , o u t p u t _ n u m s ) Conv(input\_channel,out\_channel,kernel\_size),MaxPoo(kernel\_size,stride),FCN(input\_nums,output\_nums) Conv(input_channel,out_channel,kernel_size),MaxPoo(kernel_size,stride),FCN(input_nums,output_nums)
- 重采样ST layer
这里和VESPCN中的重采样一样,就是将对齐后的支持帧(支持帧的估计值)的网格点 ( x s , y s ) (x^s,y^s) (xs,ys)通过变换得到在支持帧上相应的亚像素格点 ( x m , y m ) (x^m,y^m) (xm,ym),通过双线性插值获取对应的像素值作为输出网格点 ( x s , y s ) (x^s,y^s) (xs,ys)上的像素值。由于双线性插值可使得整个网络变得可导,因此整个时间对齐网络可以和后面的融合SR网络组成端对端的训练。
对齐网络和融合SR网络的联合训练损失:
min { Θ , θ L } ∑ j ∣ ∣ F ( y ( j ) ; Θ ) − x ( j ) ∣ ∣ 2 2 ⏟ T e m p o r a l a d a p t i v e n e t w o r k + λ ∑ j ∑ k ∈ N j ∣ ∣ θ ^ S T ( k ) − θ S T ( k ) ∣ ∣ 2 2 ⏟ S p a t i a l a l i g n m e n t n e t w o r k . (3) \min_{\{\Theta,\theta_L\}} \underbrace{\sum_j ||F(y^{(j)};\Theta)-x^{(j)}||_2^2}_{Temporal\;adaptive\;network} + \lambda \underbrace{\sum_j\sum_{k\in \mathcal{N}_j}||\hat{\theta}_{ST}^{(k)}-\theta_{ST}^{(k)}||^2_2}_{Spatial\;alignment\;network}.\tag{3} {
Θ,θL}minTemporaladaptivenetwork
j∑∣∣F(y(j);Θ)−x(j)∣∣22+λSpatialalignmentnetwork
j∑k∈Nj∑∣∣θ^ST(k)−θST(k)∣∣22.(3)
其中 N j \mathcal{N}_j Nj表示第 j j j个样本中所有的 L R LR LR参考帧、支持帧输入对; λ \lambda λ用来平衡两个部分的Loss。
空间对齐网络引入了一个Rectified Optical Flow Alignment来作为STN中Localisation网络输出参数的target,这种在中间过程增加额外Loss的过程有点像Inception-v2中的辅助分类器,对齐网络的损失仅仅只是关于Localisation网络MSE损失。而STN输出的是Image-wise的运动矢量 Δ \Delta Δ。Localization网络输出2个元素,即一个 ( 2 , ) (2,) (2,)格式的一维张量。
4 Experiments
训练集:LIVE Video Quality Assessment Database、MCL-V Database、TUM 1080p Data Set。
测试集:6个经典场景:calendar、city、foliage、penguin、temple、walk;以及4k视频集:Ultra Video Group Database。
所有的LR数据都是从上面数据集中的HR图像通过Bicubic插值获得的。
所有的实验都基于YCbCr颜色空间,且只处理其中的亮度(Y)通道,即c=1。
SR缩放倍率r=4,因为这个倍率在VSR中很能体现算法的能力。
时间自适应网络的输入为 5 × 30 × 30 5\times 30\times 30 5×30×30,即有连续的5帧(这个表示最大的连续帧数),每一帧都是一个 30 × 30 30\times 30 30×30的patch。
自集成技巧:旋转、镜像、缩放。
Batchsize=64,共训练500W个iterations。
除了每个分支第一层卷积参数以外,SR前向分支网络的初始参数使用SISR模型的参数;至于第一层,可以对每个时间维度都复制SISR中相同的参数。这种初始化策略可以加速收敛。此外,每个前向分支训练完之后的参数可以继续作为整个时间自适应网络的初始化参数。故总共有2次初始化参数的过程。
具体的实验过程可以看这篇超分之Robust VSR with Learned Temporal Dynamics
5 Conlusions
这篇文章主要结构由两部分组成:Spatial Alignment network和Temporal adaptive network。
- Spatial Alignment network,基于STN的方法,使用ROF作为target来优化变换参数,增加了一个仅优化对齐网络参数的额外Loss。
- Temporal adaptive network,引入自注意力机制,使用N个并行的SR前向分支和时间调制分支产生用于自动选择最佳时间尺度的,将前面网络对齐的连续视频帧重建为HR图像。
- 该网络的缺陷主要在于时间对齐网络:一方面是其本质是flow-based方法,
高度依赖于光流估计的准确性,一旦运动估计出错,就会导致大量的artifacts出现,且会直接影响后续融合SR网络。第二个方面是对于大运动,仍欠缺可以应对的能力,这一点从实验中也可以看出。
最后祝各位科研顺利,身体健康,万事胜意~