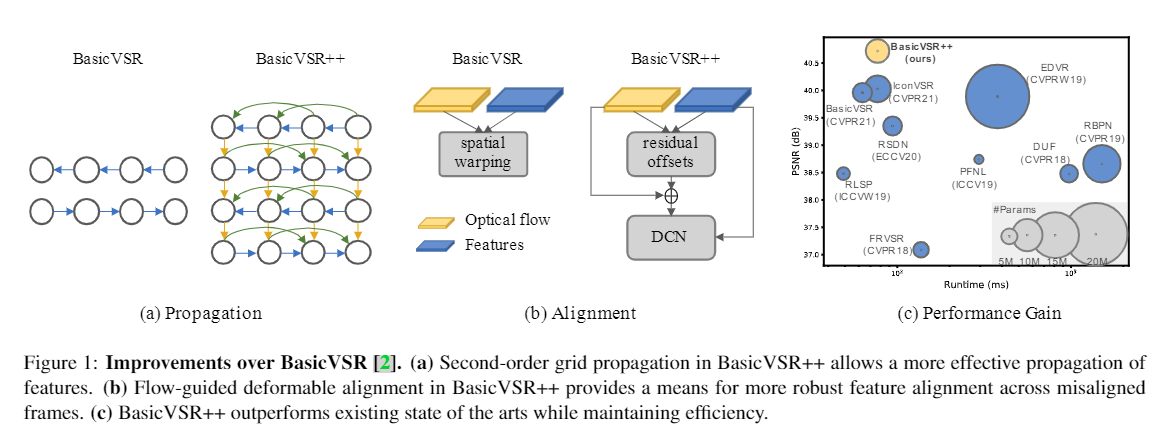
《BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment》
I. BasicVSR++使用的可变形卷积具体是DCN还是DCNv2?
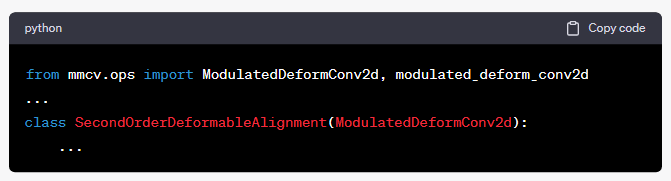
这段代码[SecondOrderDeformableAlignment(ModulatedDeformConv2d)]中,ModulatedDeformConv2d是来自mmcv库的一个模块,它实现了可变形卷积。并且,SecondOrderDeformableAlignment类继承了ModulatedDeformConv2d,这表明BasicVSR++模型使用了可变形卷积。
然而,这段代码并没有明确指出使用的是DCN还是DCNv2。但是,根据对mmcv库的了解,ModulatedDeformConv2d实现的是DCNv2,因为在DCNv2中,引入了一个新的模块化参数(modulation scalar)来增强模型的表达能力,而ModulatedDeformConv2d正是实现了这一功能。
因此,可以推断,BasicVSR++在其网络模型中使用的可变形卷积(Deformable Convolution)应该是DCNv2。
摘要
Recurrent结构是视频超分辨率任务一种流行的框架选择。最先进的方法BasicVSR采用双向传播和特征对齐,来有效地利用整个输入视频的信息。本研究中重新设计了BasicVSR,提出了二阶网格传播(second-order grid propagation)和流引导的可变形对齐(flowguided deformable alignment)。本文展示了通过增强循环框架中的传播和对齐,可以更有效地利用未对齐视频帧的时空(spatiotemporal)信息。在类似的计算约束下,新组件可以提高性能。具体来说,本文的模型BasicVSR++在PSNR上比BasicVSR提高了0.82dB,而参数数量类似。除了视频超分辨率,BasicVSR++ 还可以很好地泛化到其他视频恢复任务,例如压缩视频增强。在NTIRE2021中,BasicVSR++在视频超分辨率和压缩视频增强挑战赛中获得了三项冠军和一项亚军。代码和模型将发布到MMEditing(现已更名未MMagic)。
1. 引言
视频超分辨率(Video Super-Resolution, VSR)是一项具有挑战性的任务,需要从未对齐的视频帧中收集互补信息进行重建。一种常见的方法是滑动窗口框架[9_RBPN, 32_TDAN, 35_EDVR, 38_TOFlow],其中每一帧都是用一个短时窗内的帧进行重建。与滑动窗口框架(sliding-window framework)相比,循环框架致力于通过传播潜在特征来利用长时依赖性。与滑动窗口框架的那些工作相比,这些方法[8_, 10_, 11_, 12_, 14_, 27_]通常可以使用更加紧凑的模型。