一、Tushare介绍
1.关于Tushare
Tushare 是一个免费、开源的python财经数据接口包,数据内容包含股票、指数、基金、期货、债券、外汇、行业大数据等,同时包括了数字货币行情等区块链数据,为各类金融投资和研究人员提供适用的数据和工具,目前已全面升级到 Tushare pro 了,非常适合用于进行数据分析和可视化。
官网链接:Tushare大数据社区

2、Tushare安装及初始化
Github网址: https://github.com/waditu/Tushare
使用pip安装tushare包
pip install tushare lxml导入tushare
import tushare as ts设置token
ts.set_token('your token here')在官网注册账户即可获取token。以上方法只需要在第一次或者token失效后调用,完成调取tushare数据凭证的设置,正常情况下不需要重复设置。也可以忽略此步骤,直接用pro_api('your token')完成初始化。
初始化pro接口
pro = ts.pro_api()3.Tushare接口调用
Tushare的数据接口分为沪深股票、指数、基金、期货、期权、债券、外汇、港股、行业经济、宏观经济、特色大数据共计十一大类,沪深其中股票分为基础数据、行情数据、财务数据、市场参考数据四类接口。Tushare也提供了区块链相关的基础数据、行情数据、资讯公告三类接口,以及新浪财经、东方财富、同花顺、云财经、华尔街见闻等财经网站的宏观经济、外汇、A股、区块链、美股、石油、黄金、黄金外汇、港股、商品、债券、公司、市场、焦点、央行等财经资讯类消息。
Tushare API接口需要根据注册账户的积分数量获取相应的访问权限,积分等级不够可能导致API接口无权限访问,区块链相关接口需要捐款获取相应权限。
官网权限说明:https://tushare.pro/document/1?doc_id=108
股票行情数据
获取股票基础信息数据,包括股票代码、高开底收等。
pro = ts.pro_api()
df = pro.daily(ts_code='000001.SZ', start_date='20180701', end_date='20180718')
#多个股票
df = pro.daily(ts_code='000001.SZ,600000.SH', start_date='20180701', end_date='20180718')数据样例
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180718 8.75 8.85 8.69 8.70 8.72 -0.02 -0.23 525152.77 460697.377
1 000001.SZ 20180717 8.74 8.75 8.66 8.72 8.73 -0.01 -0.11 375356.33 326396.994
2 000001.SZ 20180716 8.85 8.90 8.69 8.73 8.88 -0.15 -1.69 689845.58 603427.713
3 000001.SZ 20180713 8.92 8.94 8.82 8.88 8.88 0.00 0.00 603378.21 535401.175
4 000001.SZ 20180712 8.60 8.97 8.58 8.88 8.64 0.24 2.78 1140492.31 1008658.828
5 000001.SZ 20180711 8.76 8.83 8.68 8.78 8.98 -0.20 -2.23 851296.70 744765.824
6 000001.SZ 20180710 9.02 9.02 8.89 8.98 9.03 -0.05 -0.55 896862.02 803038.965
7 000001.SZ 20180709 8.69 9.03 8.68 9.03 8.66 0.37 4.27 1409954.60 1255007.609
8 000001.SZ 20180706 8.61 8.78 8.45 8.66 8.60 0.06 0.70 988282.69 852071.526
9 000001.SZ 20180705 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579财务指标数据
获取上市公司各类财务指标数据,如ROA、ROE等。
pro = ts.pro_api()
df = pro.fina_indicator(ts_code='600000.SH')'20180718')数据样例
ts_code ann_date end_date eps dt_eps total_revenue_ps revenue_ps \
0 600000.SH 20180830 20180630 0.95 0.95 2.8024 2.8024
1 600000.SH 20180428 20180331 0.46 0.46 1.3501 1.3501
2 600000.SH 20180428 20171231 1.84 1.84 5.7447 5.7447
3 600000.SH 20180428 20171231 1.84 1.84 5.7447 5.7447
4 600000.SH 20171028 20170930 1.45 1.45 4.2507 4.2507
5 600000.SH 20171028 20170930 1.45 1.45 4.2507 4.2507
6 600000.SH 20170830 20170630 0.97 0.97 2.9659 2.9659
7 600000.SH 20170427 20170331 0.63 0.63 1.9595 1.9595
8 600000.SH 20170427 20170331 0.63 0.63 1.9595 1.9595 二、基于ElegantRL的量化交易机器人
1.下载数据并预处理
使用Tushare下载1635天的中国A股数据,包括基本行情数据、各类技术指标与财务指标。
财务数据
编写函数下载并处理为自己的dataframe格式
def get_fund_data(list_ticker):
fund_data = pd.DataFrame()
pro = ts.pro_api()
for i in list_ticker:
data = pro.fina_indicator(ts_code=i, start_date='20150118', end_date='20190731').drop_duplicates(subset='end_date')
fund_data = pd.concat([fund_data,data], axis=0)
date = pd.to_datetime(fund_data['end_date'],format='%Y%m%d').to_frame('date')
tic = fund_data['ts_code'].to_frame('tic')
OPM = fund_data['grossprofit_margin'].to_frame('OPM')
NPM = fund_data['netprofit_margin'].to_frame('NPM')
ROA = fund_data['roa'].to_frame('ROA')
ROE = fund_data['roe'].to_frame('ROE')
EPS = fund_data['eps'].to_frame('EPS')
cur_ratio = fund_data['current_ratio'].to_frame('cur_ratio')
quick_ratio = fund_data['quick_ratio'].to_frame('quick_ratio')
cash_ratio = fund_data['cash_ratio'].to_frame('cash_ratio')
acc_rec_turnover = fund_data['ar_turn'].to_frame('acc_rec_turnover')
debt_ratio = fund_data['debt_to_assets'].to_frame('debt_ratio')
debt_to_equity = fund_data['debt_to_eqt'].to_frame('debt_to_equity')
ratios = pd.concat([date,tic,OPM,NPM,ROA,ROE,EPS,
cur_ratio,quick_ratio,cash_ratio,acc_rec_turnover,
debt_ratio,debt_to_equity], axis=1)
ratios = ratios.sort_values(by=['date','tic']).reset_index(drop=True)
return ratios结果显示

基本行情数据、技术指标等同理。
数据连接与预处理
去除非法数据
final_ratios = ratios.copy()
final_ratios = final_ratios.fillna(0)
final_ratios = final_ratios.replace(np.inf,0)利用date和tic将数据连接
import itertools
list_date = list(pd.date_range(df['date'].min(),df['date'].max()))
combination = list(itertools.product(list_date,list_ticker))
# Merge stock price data and ratios into one dataframe
processed_full = pd.DataFrame(combination,columns=["date","tic"]).merge(df,on=["date","tic"],how="left")
processed_full = processed_full.merge(final_ratios,how='left',on=['date','tic'])
processed_full = processed_full.sort_values(['tic','date'])
将财务指标数据回填,保证数据完整性
# Backfill the ratio data to make them daily
processed_full = processed_full.bfill(axis='rows')结果显示

2.训练DRL模型
DRL模型采用开源的ElegantRL库作为框架。
交易任务的MDP模型:我们将交易任务建模为马尔可夫决策过程(MDP)(S, A, P, r, γ),其中S和A分别表示state space和action space,P(s'|s, A)表示转移概率,r(s, a)为奖励函数,γ∈(0, 1)为折现因子。具体地说,该状态表示DRL agent对市场环境的一次观测,action space由agent在某种状态下可采取的行动组成,r (s, a, s')激励agent学习更好的政策。交易agent的目的是学习一种策略![]() 使预期回报
使预期回报![]() 最大化。
最大化。
相关代码来自FinRL-Meta Demo_China_A_share_market
run函数超参数配置
def run(gpu_id=0):
env = StockTradingEnv()
env_func = StockTradingEnv
env_args = get_gym_env_args(env=env, if_print=False)
env_args['beg_idx'] = 10 # training set
env_args['end_idx'] = 1296 # training set
args = Arguments(AgentPPO, env_func=env_func, env_args=env_args)
args.target_step = args.max_step * 4
args.reward_scale = 2 ** -7
args.learning_rate = 1.5 ** -14
args.break_step = int(10e5)
args.learner_gpus = gpu_id
args.random_seed += gpu_id + 1943
train_agent(args)连接ElegantRL库代码
run() 函数将会用到以下内容:
# env.py
class StockTradingEnv() # 来自FinRL库的交易仿真环境
def build_env() # 创建训练仿真环境
def get_gym_env_args() # 获得仿真环境的参数
# net.py
class ActorPPO # PPO算法的策略网络
class CriticPPO # PPO算法的价值网络
# agent.py
class AgentPPO # PPO算法的主体
class ReplayBufferList # 经验回放缓存(存放强化学习的训练数据)
# run.py
class Arguments # 强化学习的超参数(可以看这个类的注释了解超参数的作用)
def train_agent() # 训练强化学习智能体的函数为了满足训练的需要,需要对 StockTradingEnv 类做一些修改。
训练与评估模型
使用 check_env() 函数对测试集的数据进行测试
- random action 表示交易动作是随机的
action=rd.uniform(-1, 1, action_dim),强化学习训练得到的智能体不应该比这个分数低。 - buy all share 表示一直使用最大的额度买入所有股票
action=np.ones(action_dim),能一定程度上反映大盘走势
为了方便演示和学习,选择了较少的数据,从而把训练时间压缩到1000秒内。实际上,训练数据需要再多一个数量级。
| StockTradingEnv: close_ary.shape (339, 15)
| StockTradingEnv: tech_ary.shape (339, 120)
| StockTradingEnv: fund_ary.shape (339, 165)
cumulative_returns of random action: 1.21
cumulative_returns of random action: 1.20
cumulative_returns of random action: 1.18
cumulative_returns of random action: 1.43
cumulative_returns of buy all share: 1.36
cumulative_returns of buy all share: 1.36
cumulative_returns of buy all share: 1.36
cumulative_returns of buy all share: 1.36
使用 run() 函数进行训练
| StockTradingEnv: close_ary.shape (1625, 15)
| StockTradingEnv: tech_ary.shape (1625, 120)
| StockTradingEnv: fund_ary.shape (1625, 165)
| Arguments Remove cwd: ./StockTradingEnv-v2_PPO_0
| StockTradingEnv: close_ary.shape (1286, 15)
| StockTradingEnv: tech_ary.shape (1286, 120)
| StockTradingEnv: fund_ary.shape (1286, 165)
Step:7.71e+03 ExpR: -0.01 Returns: 0.84 ObjC: 0.66 ObjA: -0.02
Step:6.17e+04 ExpR: 0.27 Returns: 3.42 ObjC: 0.49 ObjA: -0.29
Step:1.16e+05 ExpR: 0.23 Returns: 3.18 ObjC: 0.26 ObjA: -0.31
Step:1.70e+05 ExpR: 0.07 Returns: 1.81 ObjC: 0.21 ObjA: -0.23
Step:2.24e+05 ExpR: 0.23 Returns: 3.24 ObjC: 0.17 ObjA: -0.24
Step:2.78e+05 ExpR: 0.00 Returns: 1.15 ObjC: 0.17 ObjA: -0.25
Step:3.32e+05 ExpR: 0.04 Returns: 1.42 ObjC: 0.11 ObjA: -0.25
Step:3.86e+05 ExpR: 0.05 Returns: 1.36 ObjC: 0.07 ObjA: -0.22
Step:4.39e+05 ExpR: 0.05 Returns: 1.51 ObjC: 0.06 ObjA: -0.28
Step:4.93e+05 ExpR: 0.05 Returns: 1.50 ObjC: 0.03 ObjA: -0.24
Step:5.47e+05 ExpR: 0.04 Returns: 1.48 ObjC: 0.15 ObjA: -0.32
Step:6.01e+05 ExpR: 0.05 Returns: 1.54 ObjC: 0.09 ObjA: -0.20
Step:6.55e+05 ExpR: 0.05 Returns: 1.54 ObjC: 0.06 ObjA: -0.25
Step:7.09e+05 ExpR: 0.07 Returns: 1.74 ObjC: 0.06 ObjA: -0.29
Step:7.63e+05 ExpR: 0.05 Returns: 1.40 ObjC: 0.03 ObjA: -0.25
Step:8.17e+05 ExpR: 0.05 Returns: 1.46 ObjC: 0.02 ObjA: -0.36
Step:8.71e+05 ExpR: 0.21 Returns: 2.96 ObjC: 0.25 ObjA: -0.21
Step:9.25e+05 ExpR: 0.21 Returns: 2.86 ObjC: 0.16 ObjA: -0.33
Step:9.79e+05 ExpR: 0.21 Returns: 2.97 ObjC: 0.10 ObjA: -0.29
| UsedTime: 1118 | SavedDir: ./StockTradingEnv-v2_PPO_0使用 evaluate_models_in_directory() 函数进行模型评估
| StockTradingEnv: close_ary.shape (339, 15)
| StockTradingEnv: tech_ary.shape (339, 120)
| StockTradingEnv: fund_ary.shape (339, 165)
cumulative_returns 1.084 actor_00000000007710_00000011_-0000.01.pth
cumulative_returns 1.411 actor_00000000061680_00000073_00000.27.pth
cumulative_returns 1.381 actor_00000000115650_00000132_00000.23.pth
cumulative_returns 1.167 actor_00000000169620_00000192_00000.07.pth
cumulative_returns 1.445 actor_00000000223590_00000252_00000.23.pth
cumulative_returns 1.210 actor_00000000277560_00000311_00000.00.pth
cumulative_returns 1.126 actor_00000000331530_00000371_00000.04.pth
cumulative_returns 0.965 actor_00000000385500_00000430_00000.05.pth
cumulative_returns 0.965 actor_00000000439470_00000490_00000.05.pth
cumulative_returns 0.965 actor_00000000493440_00000552_00000.05.pth
cumulative_returns 1.025 actor_00000000547410_00000612_00000.04.pth
cumulative_returns 1.339 actor_00000000601380_00000671_00000.05.pth
cumulative_returns 1.265 actor_00000000655350_00000728_00000.05.pth
cumulative_returns 1.258 actor_00000000709320_00000788_00000.07.pth
cumulative_returns 1.258 actor_00000000763290_00000847_00000.05.pth
cumulative_returns 1.258 actor_00000000817260_00000909_00000.05.pth
cumulative_returns 1.421 actor_00000000871230_00000970_00000.21.pth
cumulative_returns 1.421 actor_00000000925200_00001031_00000.21.pth
cumulative_returns 1.421 actor_00000000979170_00001091_00000.21.pthcumulative_returns 表示从开始到结束智能体交易获得的收益。为了方便,我们直接显示了「本金的增长倍数」。
actor_00000000004998_00000003_00000.08.pth 是训练时保存的策略网络模型文件 actor,表示它是在环境中采样4998步,训练3秒,探索环境的得分是0.08的一个模型,它的实际得分是 1.093,表示在一段时间的交易后,本金增长了1.093倍。
连接Tensorboard可视化与调参
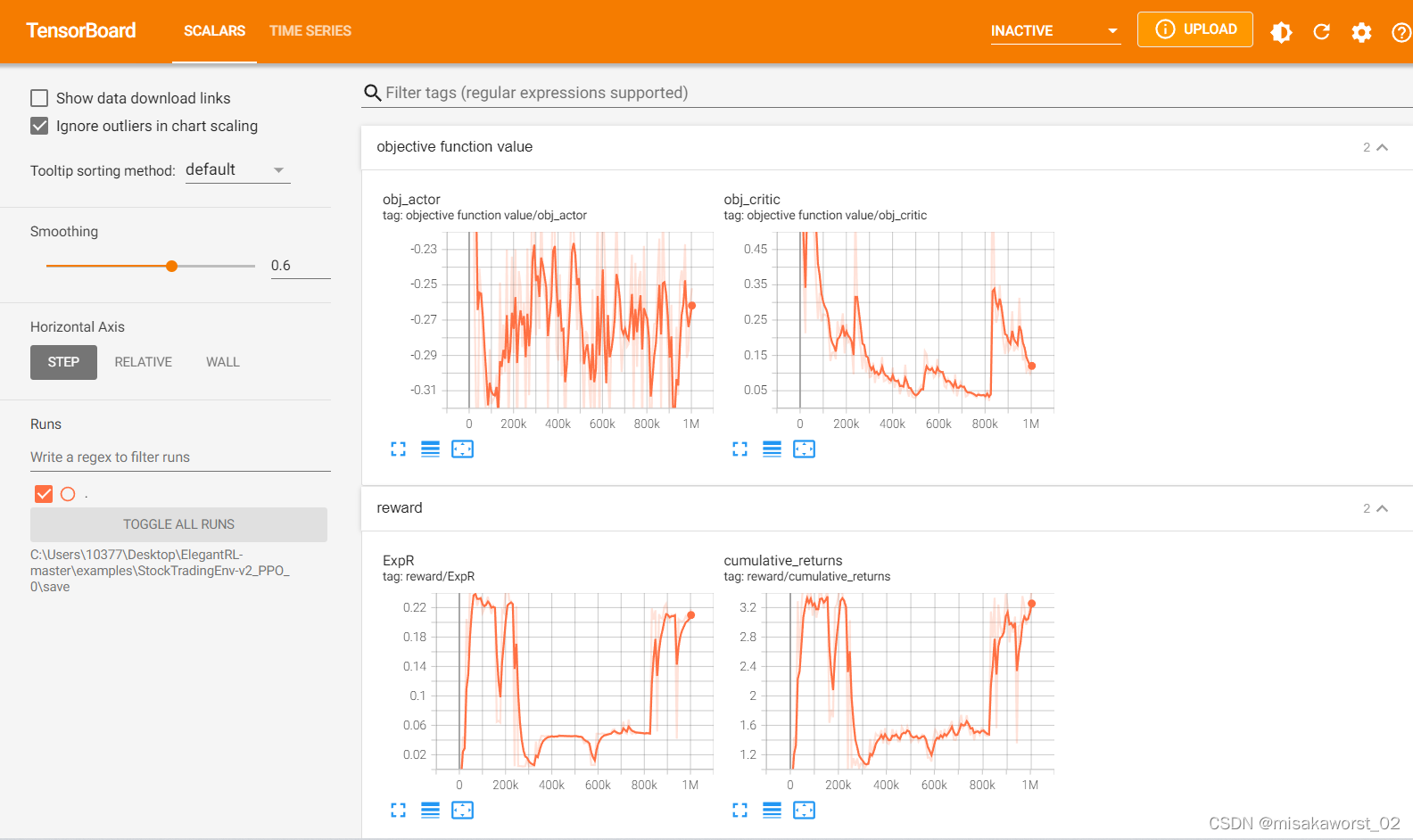
只是自己留作纪念用,如有问题请指出