论文标题:WaveNet: A Generative Model for Raw Audio
论文下载:https://arxiv.org/abs/1609.03499
论文作者:Google DeepMind
论文年份:2016
论文被引: 3333(2022/4/2)
ABSTRACT
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-ofthe-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
1 INTRODUCTION
这项工作探索了原始音频生成技术,其灵感来自神经自回归生成模型的最新进展,该模型对图像(van den Oord 等人,2016a;b)和文本(Józefowicz 等人,2016)等复杂分布进行建模。使用神经架构作为条件分布的产物对像素或单词的联合概率进行建模,从而产生最先进的生成。
值得注意的是,这些架构能够对数千个随机变量的分布进行建模(例如 PixelRNN 中的 64×64 像素(van den Oord 等人,2016a))。本文解决的问题是类似的方法能否成功生成宽带原始音频波形,这些信号具有非常高的时间分辨率,每秒至少 16,000 个样本(见图 1)。

本文介绍 WaveNet,一种基于 PixelCNN (van den Oord et al., 2016a;b) 架构的音频生成模型。这项工作的主要贡献如下:
- 我们表明,WaveNets 可以生成具有主观自然性的原始语音信号,这是人类评分者评估的文本转语音 (TTS) 领域以前从未报道过的。
- 为了处理原始音频生成所需的长期时间依赖性,我们开发了基于扩张因果卷积的新架构,它表现出非常大的感受野。
- 我们表明,当以说话者身份为条件时,可以使用单个模型来生成不同的声音。
- 相同的架构在小型语音识别数据集上测试时显示出强大的结果,并且在用于生成其他音频模式(如音乐)时很有希望。
我们相信 WaveNets 提供了一个通用且灵活的框架来处理许多依赖于音频生成的应用程序(例如 TTS、音乐、语音增强、语音转换、源分离)。
2 WAVENET
在本文中,我们介绍了一种直接在原始音频波形上运行的新生成模型。波形 x = {x1, . . . , xT } 被分解为条件概率的乘积,如下所示:
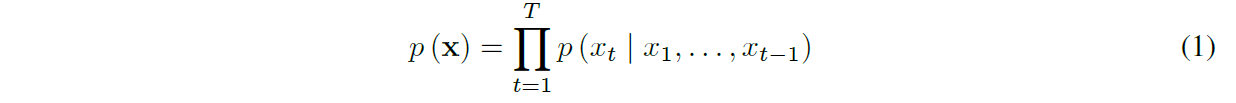
因此,每个音频样本 xt 都以所有先前时间步长的样本为条件。
与 PixelCNNs 类似,条件概率分布由卷积层建模。网络中没有池化层,模型的输出与输入具有相同的时间维度。该模型使用 softmax 层在下一个值 xt 上输出分类分布,并对其进行优化以最大化数据相对于参数的对数似然。因为对数似然是易于处理的,所以我们在验证集上调整超参数,并且可以轻松测量模型是过拟合还是欠拟合。
2.1 DILATED CAUSAL CONVOLUTIONS
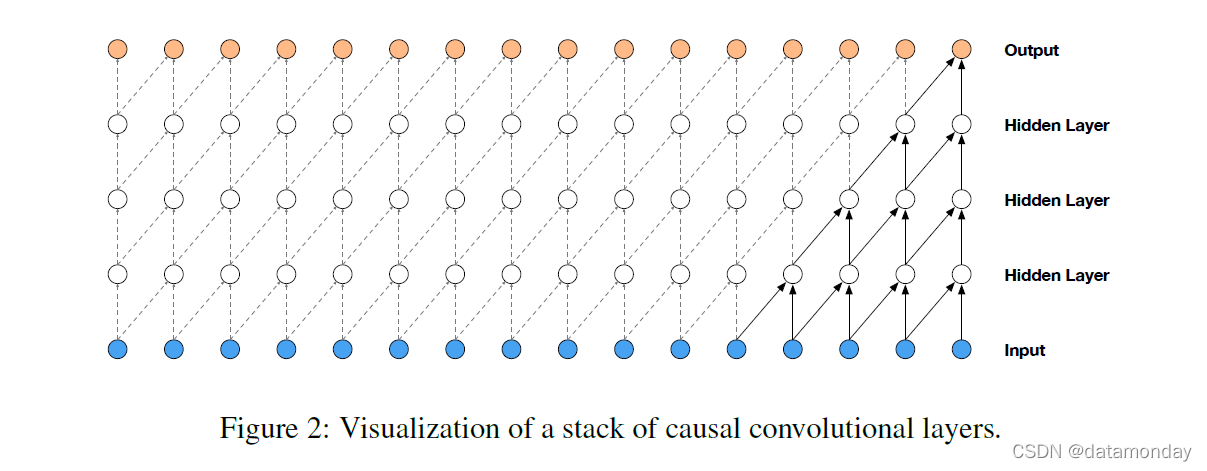
WaveNet 的主要成分是 因果卷积(causal convolutions)。如图 2 所示,通过因果卷积,确保模型不会违反对数据建模的顺序:模型在时间步 t 的预测 p (xt+1 | x1, …, xt) 不能依赖于任何未来时间步 xt+1, xt+2, . . . , xT。对于图像,因果卷积等价于掩码卷积(masked convolution),可以通过构造掩码张量并对这个掩码进行元素乘法来实现应用之前的卷积核。对于像音频这样的一维数据,通过将标准卷积的输出移动几个时间步,可以更容易地实现这一点。
训练时,所有时间步的条件预测可以并行进行,因为真实标签 x 的所有时间步长都是已知的。使用模型生成时,预测是顺序的:在每个样本被预测后,它被反馈到网络中以预测下一个样本。
由于具有因果卷积的模型没有循环连接,因此它们的训练速度通常比 RNN 更快,尤其是在应用于非常长的序列时。因果卷积的问题之一是它们需要许多层或大尺寸的滤波器(filter)来增加感受野。例如,在图 2 中,感受野只有 5(= #layers + filter length - 1)。在本文中,我们使用扩张卷积(dilated convolutions)将感受野增加几个数量级,而不会大大增加计算成本。
扩张卷积(带孔的卷积)通过以特定步长跳过输入值,将滤波器应用于大于其长度的区域。它相当于通过用零对原始滤波器进行扩展,而得到的拥有更大滤波器的卷积,但效率明显更高。扩张卷积有效地允许网络在比普通卷积更粗的尺度上运行。这类似于池化或跨步卷积,但这里的输出与输入具有相同的大小。dilation=1 的扩张卷积产生标准卷积。图 3 描绘了dilation 分别为 1、2、4 和 8 的扩张因果卷积。扩张卷积之前已在各种情况下使用,例如信号处理 (Holschneider et al., 1989; Dutilleux, 1989) 和图像分割 (Chen et al., 2015; Y u & Koltun, 2016)。
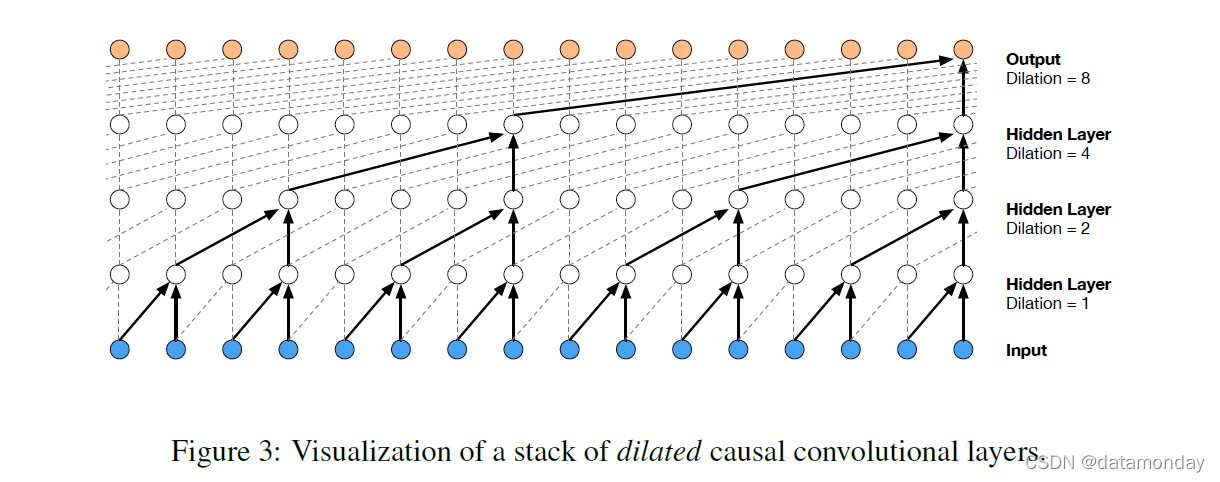
堆叠的扩张卷积使网络具有非常大的感受野,只有几层,同时保持整个网络的输入分辨率以及计算效率。在本文中,每一层的dilation都加倍,直到一个极限,然后重复:例如1, 2, 4, . . . , 512, 1, 2, 4, . . . , 512, 1, 2, 4, . . . , 512。
这种配置有两点考量。首先,膨胀因子呈指数增长会导致感受野随深度呈指数增长(Yu & Koltun,2016)。例如每个 1, 2, 4, . . . , 512 块具有大小为 1024 的感受野,可以看作是1×1024卷积的更有效和更有区别的(非线性)对应部分。其次,堆叠这些块进一步增加了模型容量和感受野大小。
2.2 SOFTMAX DISTRIBUTIONS
对单个音频样本上的条件分布 p (xt | x1, …, xt−1) 进行建模的一种方法是使用混合模型,例如混合密度网络 (Bishop, 1994) 或条件高斯尺度的混合 (MCGSM) (Theis & Bethge, 2015)。然而,PixelCNN作者表明,即使数据是隐式连续的(图像像素强度或音频样本值就是这种情况),softmax 分布往往效果更好。原因之一是分类分布更灵活,并且可以更轻松地对任意分布进行建模,因为它不对它们的形状做出任何假设。
因为原始音频通常存储为 16 位整数值序列(每个时间步一个),所以 softmax 层需要在每个时间步输出 65,536 个概率来模拟所有可能的值。为了使这更易于处理,我们首先对数据应用 µ-law 压缩扩展变换(ITU-T,1988),然后将其量化为 256 个可能的值:
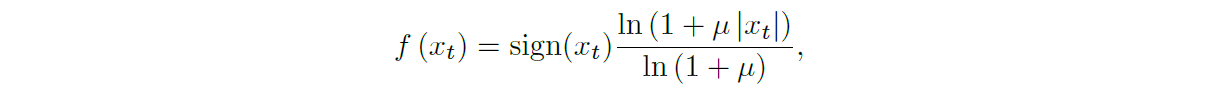
其中 -1 < xt < 1,µ = 255。与简单的线性量化方案相比,这种非线性量化产生了明显更好的重构(reconstruction)。特别是对于语音,我们发现量化后的重建信号听起来与原始信号非常相似。
2.3 GATED ACTIVATION UNITS
我们使用与门控 PixelCNN 相同的门控激活函数:
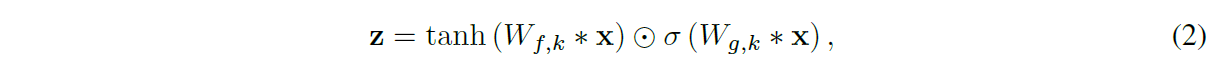
其中 * 表示卷积算子,○ 表示逐元素乘法算子,σ(·) 是 sigmoid 函数,k 是层索引,f 和 g 分别表示滤波器和门,W 是可学习的卷积滤波器。在我们最初的实验中,我们观察到这种非线性对音频信号建模的效果明显优于 ReLU (Nair & Hinton, 2010)。
2.4 RESIDUAL AND SKIP CONNECTIONS
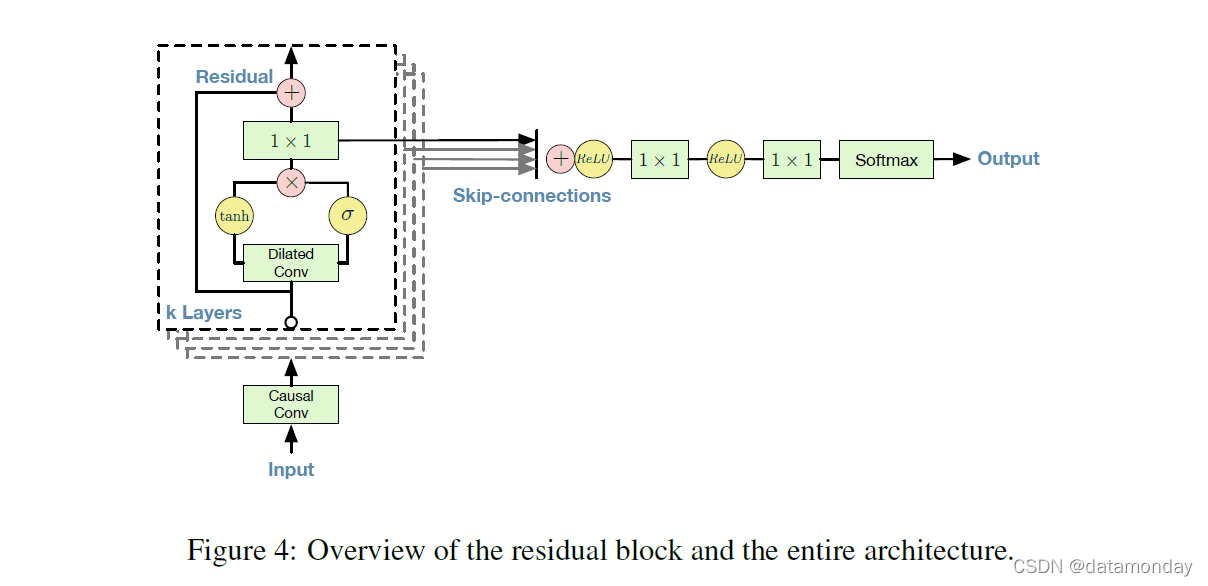
网络中使用残差(He et al., 2015)和参数化跳跃连接,以加快收敛速度并能够训练更深层次的模型。图 4 展示了模型的一个残差块,它在网络中堆叠了很多次。
2.5 CONDITIONAL WAVENETS
给定一个额外的输入 h,WaveNets 可以对给定该输入的音频的条件分布 p(x|h) 建模。公式 (1) 现在变成
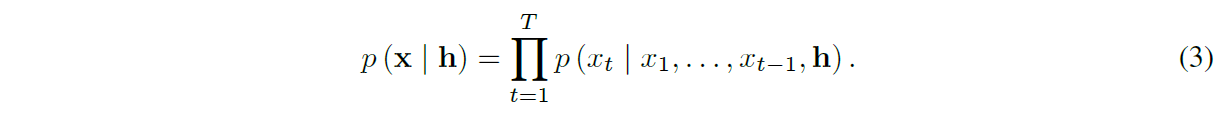
通过在其他输入变量上调节模型,可以指导 WaveNet 的生成具有所需特征的音频。例如,在多说话人设置中,我们可以通过将说话人身份作为额外输入提供给模型来选择说话人。同样,对于 TTS,我们需要提供有关文本的信息作为额外输入。
我们以两种不同的方式在其他输入上调节模型:全局调节和局部调节。全局条件的特征在于单个潜在表示 h 影响所有时间步长的输出分布,例如嵌入在 TTS 模型中的扬声器。方程 (2) 的激活函数现在变成:
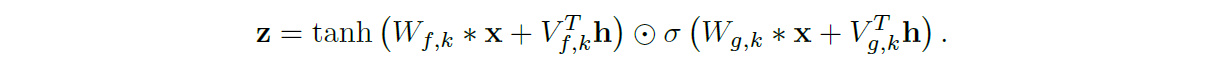
其中 V∗,k 是可学习的线性投影,向量 VT∗,kh 在时间维度上广播(broadcast)。
对于局部调节,我们有第二个时间序列 ht,可能具有比音频信号更低的采样频率,例如TTS 模型中的语言特征。我们首先使用转置卷积网络(学习上采样)转换此时间序列,将其映射到具有与音频信号相同分辨率的新时间序列 y = f(h),然后使用激活函数:
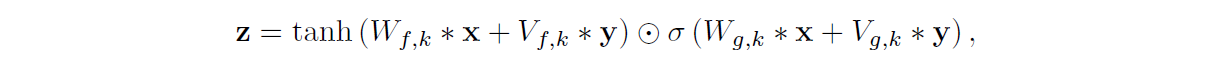
其中 Vf,k *y 现在是 1×1 卷积。作为转置卷积网络的替代方案,也可以使用 Vf,k∗h 并随时间重复这些值。我们发现这在我们的实验中效果稍差。
2.6 CONTEXT STACKS
我们已经提到了几种不同的方法来增加 WaveNet 的感受野大小:增加扩张层的数量、使用更多的层、更大的滤波器、更大的扩张因子,或者它们的组合。一种补充方法是使用一个单独的、较小的上下文堆叠(stack)来处理大部分音频信号,并在本地调节一个较大的 WaveNet,该 WaveNet 只处理较小部分的音频信号(最后裁剪)。可以使用具有不同长度和隐藏单元数量的多个上下文堆叠。具有较大感受野的堆叠每层具有较少的单元。上下文堆叠还可以具有池化层以较低频率运行。这将计算要求保持在一个合理的水平,并且与在较长时间尺度上对时间相关性建模所需的容量较少的直觉一致。
3 EXPERIMENTS
为了衡量 WaveNet 的音频建模性能,我们在三个不同的任务上对其进行评估:多说话者语音生成(不以文本为条件)、TTS 和音乐音频建模。以下网站为这些实验提供了从 WaveNet 中抽取的样本:https://www.deepmind.com/blog/wavenet-generation-model-raw-audio/。
3.1 MULTI-SPEAKER SPEECH GENERATION
对于第一个实验,我们研究了自由形式的语音生成(不以文本为条件)。我们使用来自 CSTR 语音克隆工具包 (VCTK) (Yamagishi, 2012) 的英语多说话者语料库,并仅在说话者上调节 WaveNet。通过以 one-hot 向量的形式将说话者 ID 输入到模型来调节。该数据集包含来自 109 位不同说话者的 44 小时数据。
由于该模型不以文本为条件,因此它以流畅的方式生成不存在但类似于人类语言的单词,并具有逼真的语调。这类似于语言或图像的生成模型,其中样本乍一看看起来很逼真,但仔细检查后明显不自然。缺乏长距离连贯性的部分原因是模型的感受野大小有限(大约 300 毫秒),这意味着它只能记住它产生的最后 2-3 个音素。
单个 WaveNet 能够通过对说话者的 one-hot 编码进行调节,对来自任何说话者的语音进行建模。这证实了它足够强大,可以在单个模型中从数据集中捕获所有 109 位说话者的特征。我们观察到,与仅在单个说话者上进行训练相比,添加说话者会带来更好的验证集性能。这表明 WaveNet 的内部表示在多个说话者之间共享。
最后,我们观察到该模型还发现了除了语音本身之外的音频中的其他特征。例如,它还模仿了音质和录音质量,以及说话者的呼吸和嘴巴动作。
3.2 TEXT-TO-SPEECH
对于第二个实验,我们研究了 TTS。我们使用了与 Google 的北美英语和普通话 TTS 系统相同的单人语音数据库。北美英语数据集包含24.6小时的语音数据,普通话数据集包含34.8小时;两者都是由专业的女性演讲者讲的。
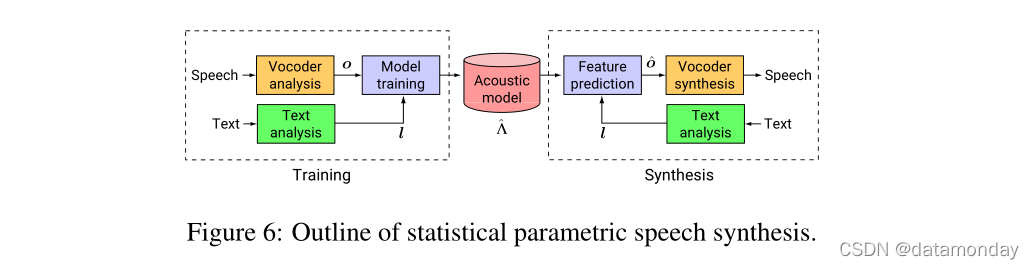
用于TTS任务的 WaveNets 是以从输入文本中获得的语言特征为局部条件的。除了语言特征外,我们还以对数基频 (log F0) 值为条件训练 WaveNet。还针对每种语言训练了从语言特征预测 logF0 值和电话持续时间的外部模型。 WaveNets 的感受野大小为 240 毫秒。作为基于示例和基于模型的语音合成基线,隐马尔可夫模型 (HMM) 驱动的单元选择连接 (Gonzalvo et al., 2016) 和基于长短期记忆循环神经网络 (LSTM-RNN) 的统计参数 ( Zen et al., 2016) 构建了语音合成器。由于使用相同的数据集和语言特征来训练基线和 WaveNet,因此可以公平地比较这些语音合成器。
为了评估 WaveNets 在 TTS 任务中的性能,我们进行了主观配对比较测试和平均意见得分 (MOS) 测试。在配对比较测试中,在听完每一对样本后,被试被要求选择他们喜欢的,但如果他们没有任何偏好,他们可以选择“中立”。在 MOS 测试中,在听完每个刺激后,受试者被要求以Likert五点量表评分对刺激的自然度进行评分(1:差,2:差,3:一般,4:好,5:优秀)。详情请参阅附录 B。
图 5 显示了选择的主观配对比较测试结果(完整表格见附录 B)。从结果可以看出,WaveNet 在两种语言中都优于基线统计参数和级联语音合成器。我们发现以语言特征为条件的 WaveNet 可以合成具有自然句段质量的语音样本,但有时它通过强调句子中的错误单词而具有不自然的韵律。这可能是由于 F0 轮廓的长期依赖性:WaveNet 240 毫秒的感受野大小不足以捕捉这种长期依赖性。基于语言特征和 F0 值的 WaveNet 没有这个问题:外部 F0 预测模型以较低的频率(200 Hz)运行,因此它可以学习存在于 F0 轮廓中的远程依赖关系。
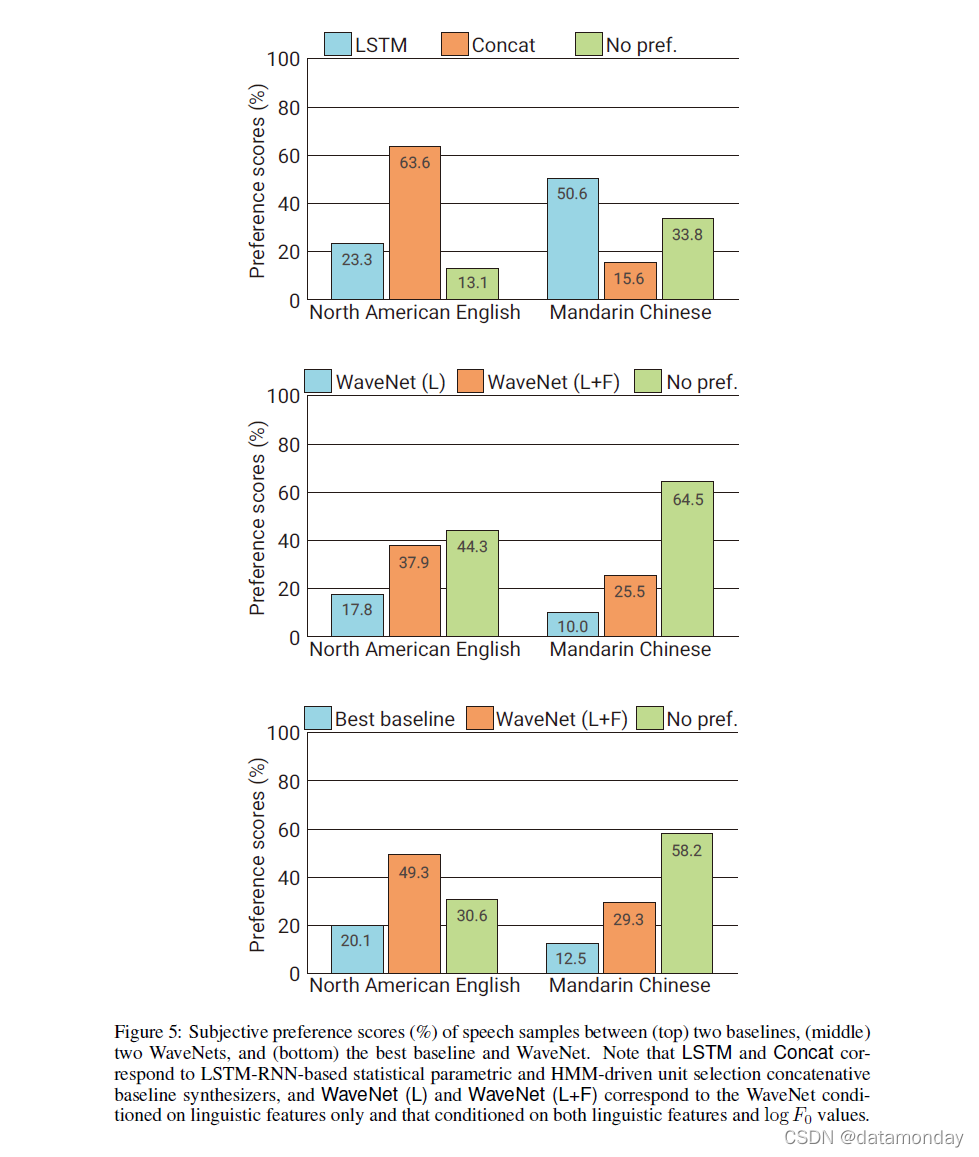
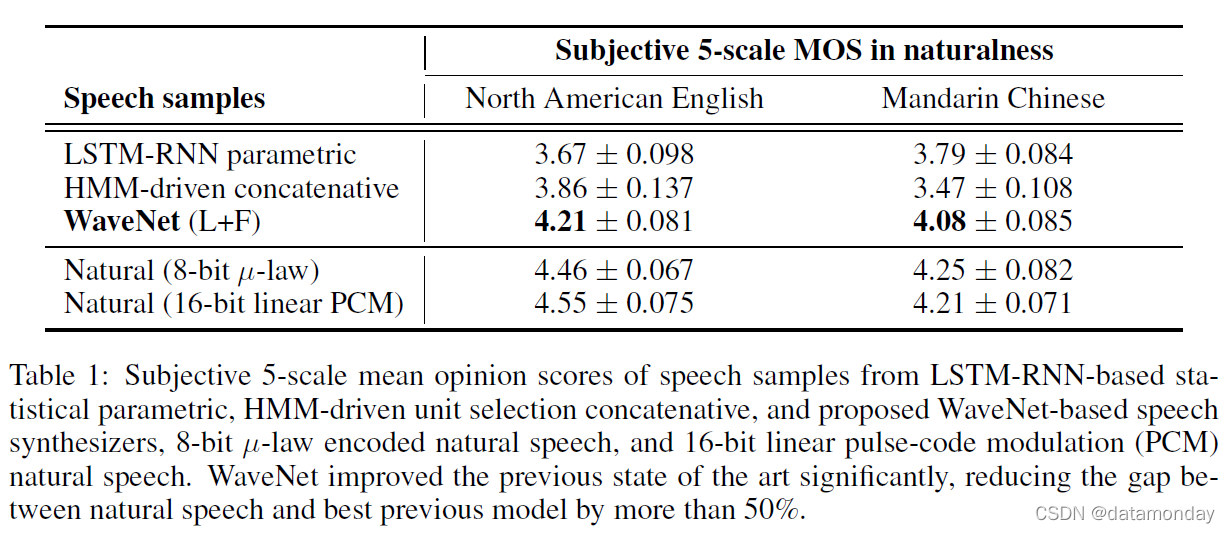
表 1 显示了 MOS 测试结果。从表中可以看出,WaveNets 在 4.0 以上的自然度上实现了 5 尺度 MOS,明显优于基线系统。它们是这些训练数据集和测试句子中报告的最高 MOS 值。从最佳合成语音到自然语音的 MOS 差距在美国英语中从 0.69 下降到 0.34 (51%),在普通话中从 0.42 下降到 0.13 (69%)。
3.3 MUSIC
在第三组实验中,我们训练 WaveNets 对两个音乐数据集进行建模:
- MagnaTagA Tune 数据集(Law & V on Ahn,2009),包含大约 200 小时的音乐音频。每个 29 秒的剪辑都带有来自一组 188 个标签的注释,这些标签描述了音乐的流派、乐器、节奏、音量和情绪。
- Y ouTube 钢琴数据集,其中包含从 YouTube 视频中获得的大约 60 小时的钢琴独奏音乐。因为它仅限于单个仪器,所以建模要容易得多。
尽管很难对这些模型进行定量评估,但可以通过聆听它们产生的样本进行主观评估。我们发现扩大感受野对于获得听起来悦耳的样本至关重要。即使有几秒钟的感受野,这些模型也不能实现长期的一致性,从而导致流派、乐器、音量和声音质量的瞬间变化。尽管如此,即使是由无条件的模型产生的,这些样本也常常是和谐的,美学上令人愉悦的。
特别感兴趣的是条件音乐模型,其可以在给定一组指定例如流派或乐器的标签的情况下生成音乐。类似于条件语音模型,我们插入依赖于与每个训练剪辑相关联的标签的二进制向量表示的偏差。这使得在采样时可以通过输入编码样本所需属性的二进制向量来控制模型输出的各个方面。我们已经在MagnaTagATune数据集上训练了这样的模型;虽然与数据集捆绑在一起的标签数据相对嘈杂,并且有许多遗漏,但在通过合并相似的标签并删除那些关联剪辑太少的标签来清理标签数据之后,我们发现这种方法相当有效。
3.4 SPEECH RECOGNITION
尽管 WaveNet 被设计为生成模型,但它可以直接适用于判别性音频任务,例如语音识别。
传统上,语音识别研究主要集中在使用对数梅尔滤波器族(mel-filterbank)能量或梅尔频率倒谱系数(mel-frequency cepstral coefficients,MFCCs),但最近已经转向原始音频 (Palaz et al., 2013; Tüske et al., 2014; Hoshen et al., 2014)。诸如 LSTM-RNNs 的递归神经网络已经成为这些新的语音分类管道中的关键组件,因为它们可以建立具有长距离上下文的模型。我们已经证明,使用 WaveNets,与使用LSTM单位相比,扩张卷积层可以以更高效的方式使感受野变得更长。
作为最后一个实验,我们在 TIMIT (Garofolo et al., 1993) 数据集上使用 WaveNets 进行语音识别。对于这个任务,我们在扩张卷积之后添加了一个均值池化层,该层将激活聚合到跨越 10 毫秒(160 倍下采样)的更粗粒度的帧。池化层之后是一些非因果卷积。我们用两个损失项训练 WaveNet,一个用于预测下一个样本,一个用于对帧进行分类,该模型的泛化能力比单个损失更好,并且在测试集上达到 18.8 PER,据我们所知,这是从在 TIMIT 上直接在原始音频上训练的模型。
(来自附录)
4 CONCLUSION
本文介绍了 WaveNet,这是一种直接在波形级别运行的音频数据的深度生成模型。 WaveNets 是自回归的,将因果滤波器与扩张卷积相结合,使其感受野随深度呈指数增长,这对于模拟音频信号中的长距离时间依赖性很重要。我们已经展示了 WaveNets 如何以全局(例如说话人身份)或局部方式(例如语言特征)为条件以其他输入为条件。当应用于 TTS 时,WaveNets 产生的样本在主观自然度方面优于当前最好的 TTS 系统。最后,WaveNets 在应用于音乐音频建模和语音识别时显示出非常有前景的结果。