论文名称:BYTECOVER: COVER SONG IDENTIFICATION VIA MULTI-LOSS TRAINING(ICASSP2021)
论文地址:https://arxiv.org/pdf/2010.14022v2.pdf
代码地址:暂无
背景
研究Music Information Retrieval (MIR)方向中的Cover song identification任务,减少人工特征和对齐算法的使用,本文提出ByteCover网络来检索相同的音乐。
模型流程
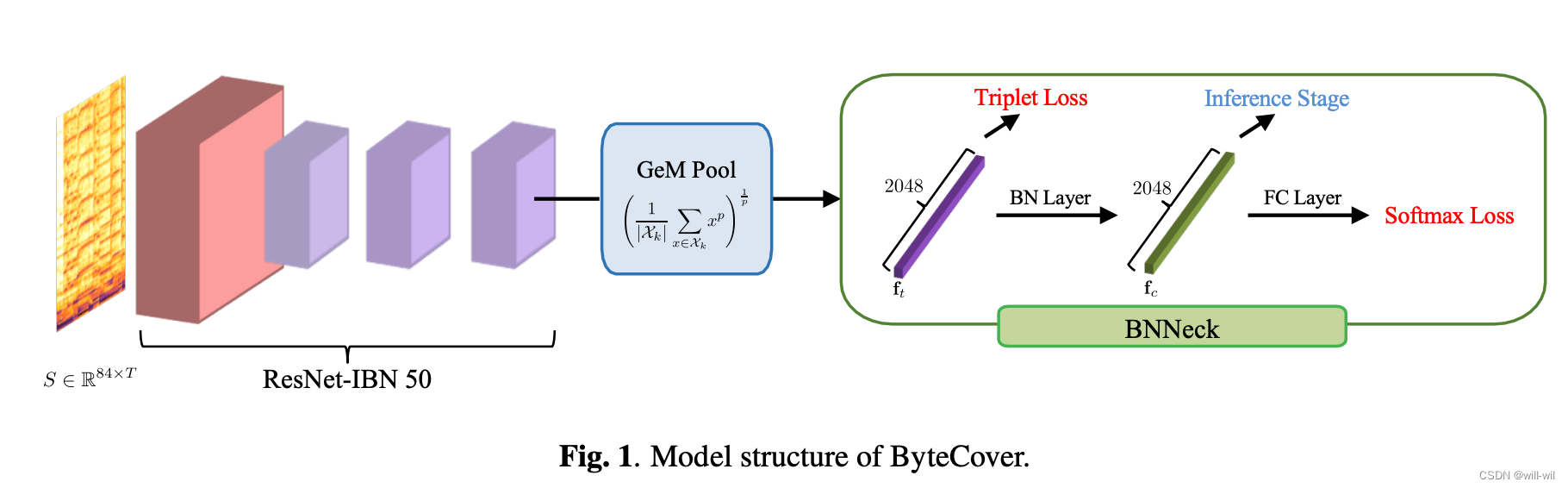
- 模型输入:
- 采用CQT频谱特征,每个octave的bin个数设置为12,hann window大小设置为512,采样率为22050Hz,CQT特征average下采样倍率为100,最终得到的音频特征维度为[84, T],其中T为时间维度,与音频时长挂钩。
- 模型结构:
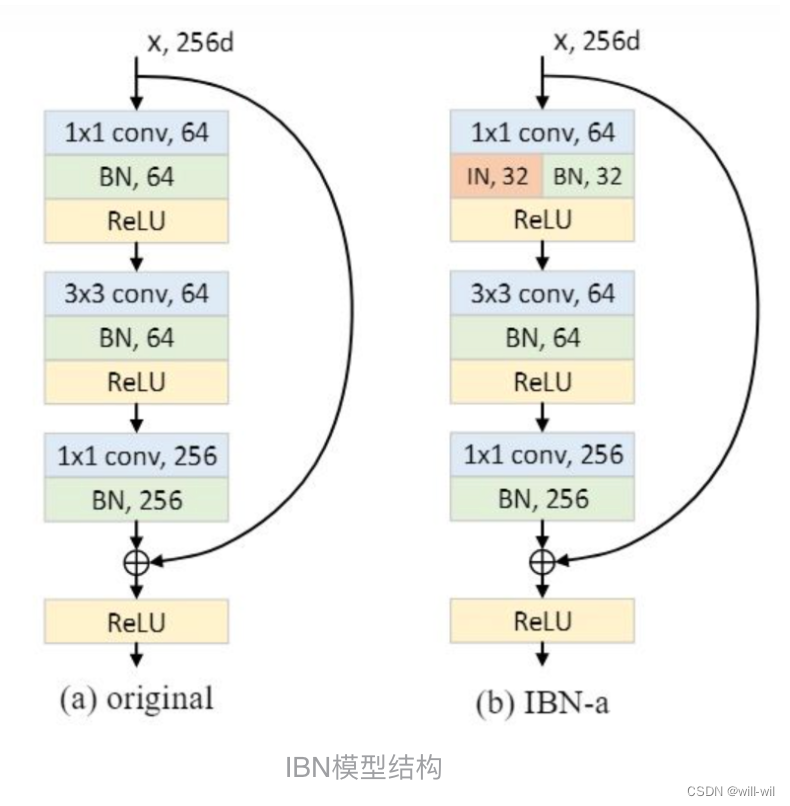
- ResNet-IBN模块:为了将ResNet转换为带有IBN模块的模型来学习不变嵌入,将模型的基本元素残差块替换为IBN块(IN有助于模型学习音调、节奏、音色等不变性特征)。
- 每个残差block的第一个conv添加IBN模块,BN处理一半通道,IN处理另外一半通道。
-
输入特征1x84xT,最终模型输出的形状为2048x6xT/8。
-
为保证输出feature map的大小,ResNet50最后一组block的stride设为1。
-
为防止过多IN层降低模型能力,ResNet50最后一组block保持不变。
-

- GemPool池化模块:将X映射成定长vector,参数p设置为可学习。
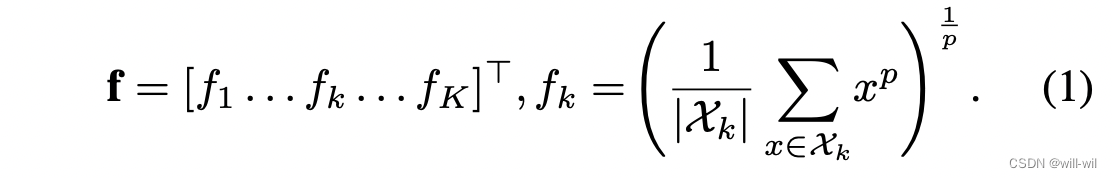
- BNNeck Loss函数:
- 结合分类loss和triplet loss对模型进行训练,其中插入BN Layer协调,原因在于分类loss主要优化cosine距离,triplet loss主要优化欧式距离,如果同时对一个FC使用两个Loss,triplet loss会影响到分类的决策面而分类loss会影响到类内紧凑性。
- GeM模块产生的vector用
 表示,通过BN Layer表示为
表示,通过BN Layer表示为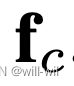 ,训练阶段前者用于计算triplet loss,后者用于计算分类loss。
,训练阶段前者用于计算triplet loss,后者用于计算分类loss。 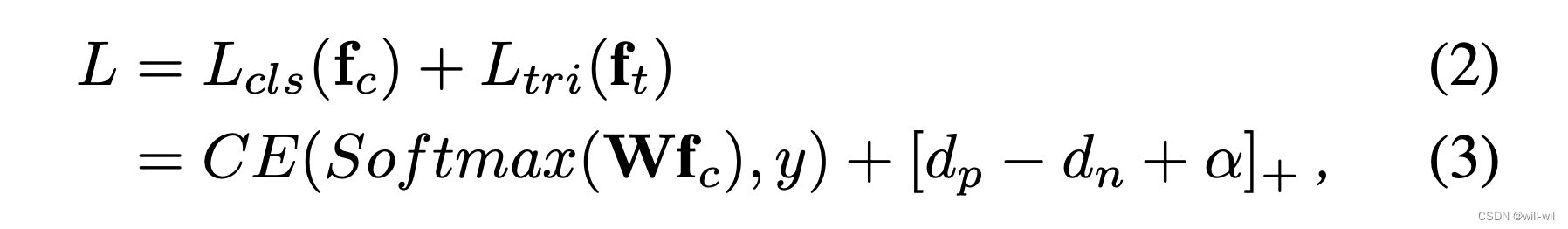
模型实验结果
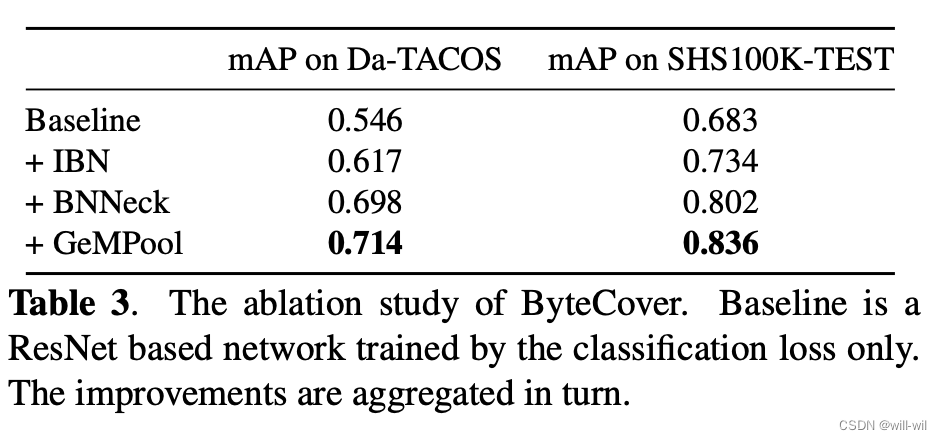
模型整体实验结果

模型消融实验