近两年,视觉语言模型 (VLM) 逐渐兴起,并在小样本学习 (Few-shot Learning) 和零样本推理 (Zero-shot Inference) 上取得了令人注目的成果。那么这些在自然图像上取得成功的大规模预训练视觉语言模型,是否能成功应用到医疗领域呢?抱着这样的疑问,四川大学华西生物医疗大数据中心人工智能和医疗机器人实验室,华西医院-商汤科技联合实验室,上海人工智能实验室,以及北京邮电大学的联合研究详细全面地验证了,在合适的提示(Prompt)的帮助下,在自然图像上训练得到的视觉语言预训练模型能否在小样本甚至零样本的条件下迁移到医疗图像领域。相关论文 已经被人工智能顶级会议ICLR 2023(International Conference on Learning and Representation)接收。

论文标题:
Medical Image Understanding with Pretrained Vision Language Models: A Comprehensive Study
论文链接:
https://arxiv.org/abs/2209.15517v1

一、医疗大模型的稀缺性
医疗图像领域一直存在着数据缺乏的问题:医疗图像数据的标注相较于自然图像,需要更加专业的从业人员进行标注;针对一些罕见病例的数据很难形成规模;涉及到道德隐私等因素使得数据无法汇总公开。这一切都使得医疗图像领域迟迟没能发展出自己的大型预训练模型 PLM(Pretrained Large Model) 。因此,借助自然图像上的大型预训练模型进行迁移学习成为了一个顺理成章的选项。但是由于医疗图像和自然图像存在着较大的域跨度(Domain Gap),迁移训练模型的域泛化往往受到限制。
二、多模态预训练模型与语言不变性
通过视觉–语言的跨模态对齐训练,视觉语言模型(VLM)让模型具有了更好的泛化能力。多个VLM在小样本及零样本任务中表现良好。然而,现有的研究没有调查这些VLM是否能够理解较为少见的医学概念。部分研究显示,通过设计好的提示(Prompt),VLM能够识别同一个概念的不同视觉风格(比如能够识别一个物体的彩色照片,素描,或是卡通风格的图片)甚至是没有见过的概念(Unseen Concept)。我们认为,这种泛化能力主要归因于语言文字模态在跨域图像中具有一定的不变性,而由于视觉语言模型(VLM)对于语言和视觉模态的表达高度绑定,通过语言Prompt便能激活相应的视觉表达学习能力。
简言之,如果我们设计的prompt具有对物体的形状、颜色、纹理或位置等表达属性(Expressive Attribute)的描述,即使面对一个全新的医疗领域的概念,视觉语言模型也能够识别出相应的物体。为此,我们首先人工设计了一套prompt的模板,并在此基础上提出了多套自动生成prompt的方法来为不同的医疗概念生成对应的prompt。我们在13个公开的医疗图像数据集上验证了我们的想法,即一个含有丰富表达属性的prompt能够很好的帮助VLM在零样本或小样本的任务中获得巨大的表现提升。
三、医疗prompt的设计:从手动到自动
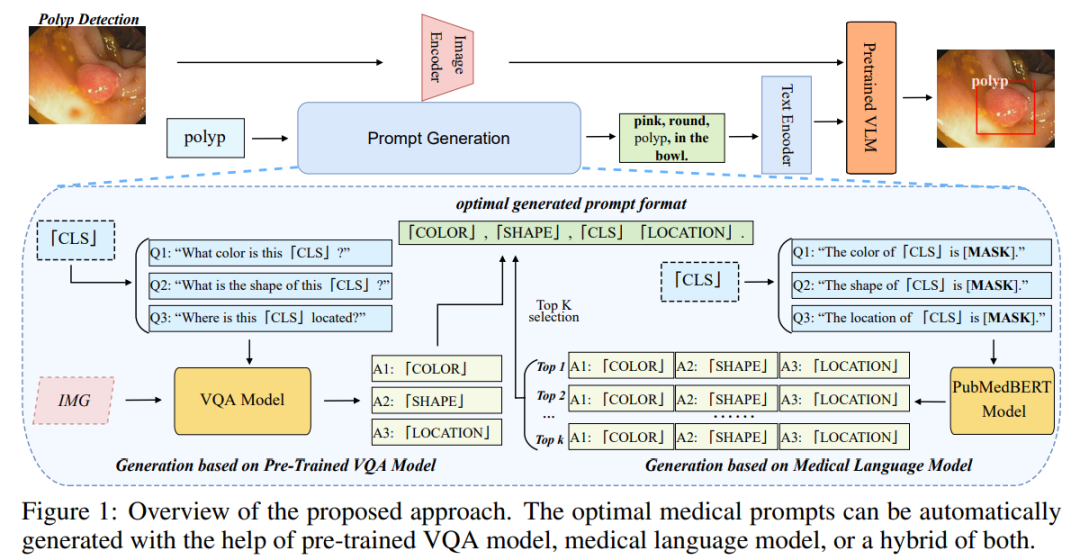
正如前文所说,想要激活预训练VLM的泛化能力,一个具有表达属性描述的Prompt显得尤为重要,但是如何获得这种Prompt是一个关键的问题。事实上,虽然现在自然语言处理(NLP)领域已经提出了不少从PLM当中提取知识的Prompt生成手段,但是它们无一是针对视觉任务而设计的。我们的prompt设计重点在于获得一个事物或概念的属性描述。我们设计了一个格式模板,让这种生成过程更加规律。
例如,我们对息肉(Polyp)这一医学概念设计的Prompt是:‘In rectum , Polyp is an oval bump, often in pink color.’ 我们分别插入了对位置,形状,和颜色的描述。但是手工设计这些prompt费时费力,且需要设计者具有一定的专业知识,于是我们进一步提出了自动生成prompt的流程。第一种方法是通过具有领域专业知识的预训练语言模型(LM) 去做掩码预测任务。例如,我们把属性单词设为Mask – ‘Polyp is in [Mask] color’. 有研究表明这种方法相比于问答式的方法能更有效地抽取出对应的知识。这种方法我们称之为MLM(masked language model)。
上述方法是能够提取出一个概念或事物的综合属性,但是有一些属性可能具有多样性,所以我们需要对每张图单独的进行一次属性的筛查。在这方面,我们借助了生成式的预训练VLM,让它去回答我们针对属性的问题。例如我们提问:‘What color is this Polyp’,就可以得到针对这张图的属性词。这种方法我们称之为VQA(Visual Question Answering)。
最终,我们也尝试将前面两种方式进行一定的融合,比如针对一些较为固定的属性(比如位置纹理)使用MLM方法来提取,针对一些不固定的属性(比如颜色形状)使用VQA方式来提取。这种方法我们称之为Hybrid方法。
经实验验证,上述的几种方法在小样本或零样本检测任务中均取得了远高于仅使用目标事物或概念名称作为prompt的基线方法的表现。其中,自动设计的prompt和手动设计的prompt相比也有着不俗的成绩,但自动生成的方式时间成本要低得多。
四、在小样本及零样本任务中的全面优越性
为了全面地验证我们提出的prompt方法,我们收集了13个公开的医疗数据集,并且这些数据横跨了不同的医疗图像模态(CT, MRI, 超声,内窥镜,病理图像等)。
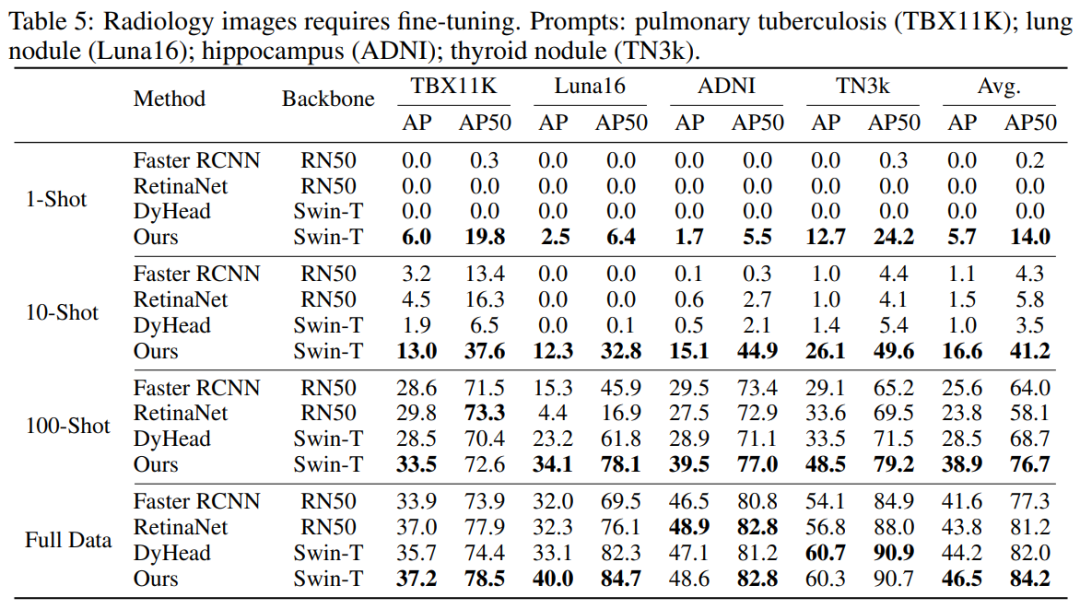
其中,虽然放射图像数据集由于和自然图像的域跨度较大,但我们发现仅需要少量样本微调(finetune)就能取得不错的效果,结果显示我们的方法在小样本的情况下表现大幅领先于传统的检测模型。
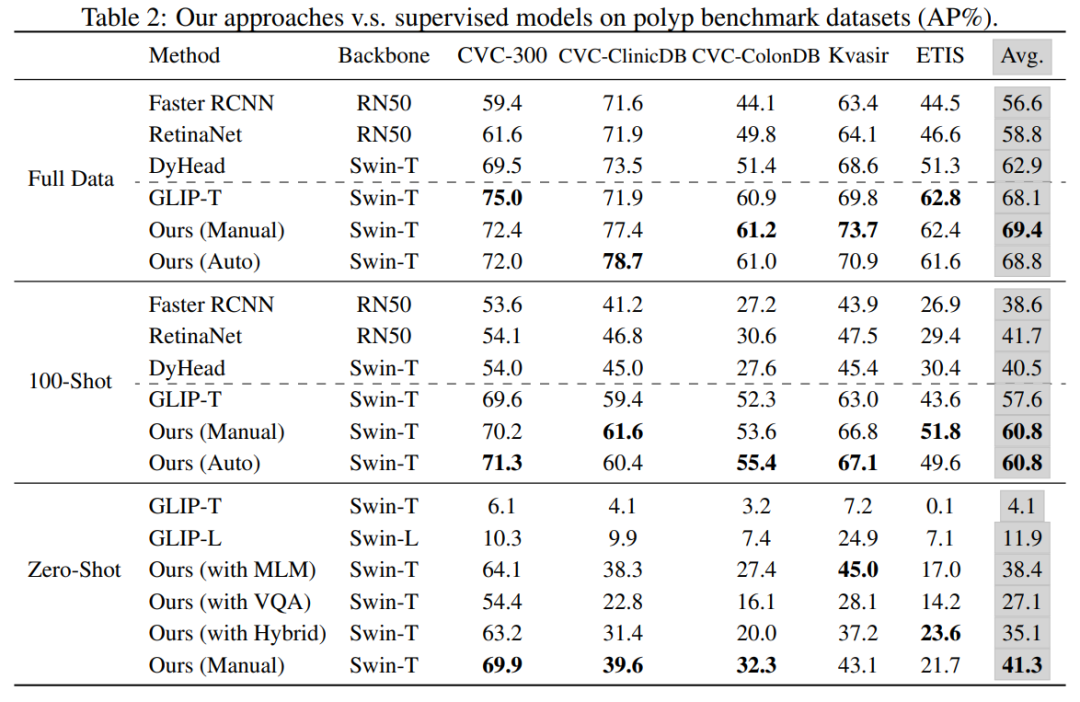
在内窥镜,病理图像等其它数据中,我们发现无论是零样本的直接迁移还是小样本的微调迁移,VLM都取得了异常惊艳的表现。在零样本的场景下,我们通过手工模板和以及自动生成的方式获得了充满表达属性的prompt。我们主要对比了上述方式获得的prompt和仅使用目标事物或概念名称作为prompt的零样本检测效果。结果显示,我们的方法要远胜于使用概念名称作为prompt的基线方法。在小样本和全样本的场景下,我们的方法相比于传统的检测模型也具有较大的优势。
部分可视化结果

五、总结
· 我们认为视觉语言预训练模型的泛化能力能够有效的缓解医疗图像领域存在的数据稀缺及领域跨度大的问题。合理的利用语言描述当中表达属性词在不同域中的不变性,是利用好视觉语言预训练模型的关键。我们用多个数据集和大量实验验证了我们的猜想。
· 我们提出了含有表达属性词的提示设计模板,并根据这一模板将设计流程自动化。提出了三种基于不同需求的自动prompt生成方式。
· 我们的方法对比传统检测模型在小样本检测任务下表现出了全面的优越性;对比仅使用目标事物名称作为提示词的方式,我们设计的提示在零样本检测任务上带来了巨大的提升。
作者:TechBeat硬核播报
Illustration by IconScout Store from IconScout
-The End-