目录
1 Kubernetes集群环境
Istio支持在不同的平台下安装其控制平面,例如Kubernetes、Mesos和虚拟机等。
课程上以 Kubernetes 为基础讲解如何在集群中安装 Istio (Istio 1.0.6 要求Kubernetes的版本在1.11及以上)。
可以在本地或公有云上搭建Istio环境,也可以直接使用公有云平台上已经集成了Istio的托管服务。
目前有许多软件提供了在本地搭建Kubernetes集群的能力,例如Minikube/kubeadm都可以搭建kubernetes集群,我这边所选用的是kubeadm来安装Kubernetes集群。
Kubeadm 是一个工具,它提供了 kubeadm init 以及 kubeadm join 这两个命令作为快速创建 kubernetes 集群的最佳实践。
准备机器
两台centos7的虚拟机,地址分别为
192.168.187.137
192.168.187.138
大家根据自己的情况来准备centos7的虚拟机。
虚拟机要保证彼此之间能够ping通,也就是处于同一个网络中。
Kubernets官网推荐虚拟机的配置最低要求:2核2G(这边建议最低2核3G配置)
Docker环境
在每一台机器上都安装好Docker,我这边使用的版本为18.09.0
# docker查看版本命令
docker --version
修改hosts文件
(1)设置master角色,在192.168.187.138打开hosts文件
# 打开hosts文件 vi /etc/hosts # 设置192.168.187.138为master的hostname,用m来表示 192.168.187.138 m # 设置192.168.187.137为worker的hostname,用w1来表示 192.168.187.137 w1(2)设置worker角色,在192.168.187.137打开hosts文件
# 打开hosts文件 vi /etc/hosts # 设置192.168.187.138为master的hostname,用m来表示 192.168.187.138 m # 设置192.168.187.137为worker的hostname,用w1来表示 192.168.187.137 w1(3)使用ping测试一下
ping m
ping w1
kubeadm安装版本
安装的版本是1.14.0
kubernetes集群网络插件-calico
calico网络插件:https://docs.projectcalico.org/v3.9/getting-started/kubernetes/
calico,同样在master节点上操作Calico为容器和虚拟机工作负载提供一个安全的网络连接。
验证 Kubernetes安装
1)在master节点上检查集群信息
命令:kubectl get nodes
2)监控 w1节点的状态 :kubectl get nodes -w
监控成 ready状态
3)查询pod 命令:kubectl get pods -n kube-system
注意:Kubernetes集群安装方式有很多,大家可以安装自己熟悉的方式搭建Kubernetes, 这里只是介绍本次课程上使用的kubernets集群环境
2 安装Istio
在Istio的版本发布页面https://github.com/istio/istio/releases/tag/1.0.6下载安装包并解压(我用的是一个比较稳定的版本1.0.6版本,放到master上面,以Linux平台的istio-1.0.6-linux.tar.gz为例)
1.解压tar -xzf istio-1.0.6-linux.tar.gz
2.进入istio目录cd istio-1.0.6/
Istio的安装目录及其说明
文件/文件夹 说明 bin 包含客户端工具,用于和Istio APIS交互 install 包含了Consul和Kubernetes平台的Istio安装脚本和文件,在Kubernetes平台上分为YAML资源文件和Helm安装文件 istio.VERSION 配置文件包含版本信息的环境变量 samples 包含了官方文档中用到的各种应用实例如bookinfo/helloworld等等,这些示例可以帮助读者理解Istio的功能以及如何与Istio的各个组件进行交互 tools 包含用于性能测试和在本地机器上进行测试的脚本文件和工具
有以下几种方式安装Istio:
- 使用install/kubernetes文件夹中的istio-demo.yaml进行安装;
- 使用Helm template渲染出Istio的YAML安装文件进行安装;
- 使用Helm和Tiller方式进行安装。
课程中使用的是使用install/kubernetes文件夹中的istio-demo.yaml进行安装
2.1 快速部署Istio
Kubernetes CRD介绍
比如Deployment/Service/etc等资源是kubernetes本身就支持的类型,除了这些类型之外kubernetes还支持资源的扩展,说白了就是可以自定义资源类型,如果没有CRD的支持的话,istio一些资源类型是创建不成功的
#crds.yaml路径:
istio-1.0.6/install/kubernetes/helm/istio/templates/crds.yaml
# 执行
kubectl apply -f crds.yaml
# 统计个数
kubectl get crd -n istio-system | wc -l
Kubernetes平台对于分布式服务部署的很多重要的模块都有系统性的支持,借助如下一些平台资源可以满足大多数 分布式系统部署和管理的需求,但是在不同应用业务环境下,对于平台可能有一些特殊的需求,这些需求可以抽象为Kubernetes的扩展资源,而 Kubernetes的CRD(CustomResourceDefifinition)为这样的需求提供了轻量级的机制
执行安装命令
(1)根据istio-1.0.6/install/kubernetes/istio-demo.yaml创建资源
kubectl apply -f istio-demo.yaml # 会发现有这么多的资源被创建了,很多很多 ,里面的命名空间用的是istio-system2)查看核心组件资源
kubectl get pods -n istio-system kubectl get svc -n istio-system
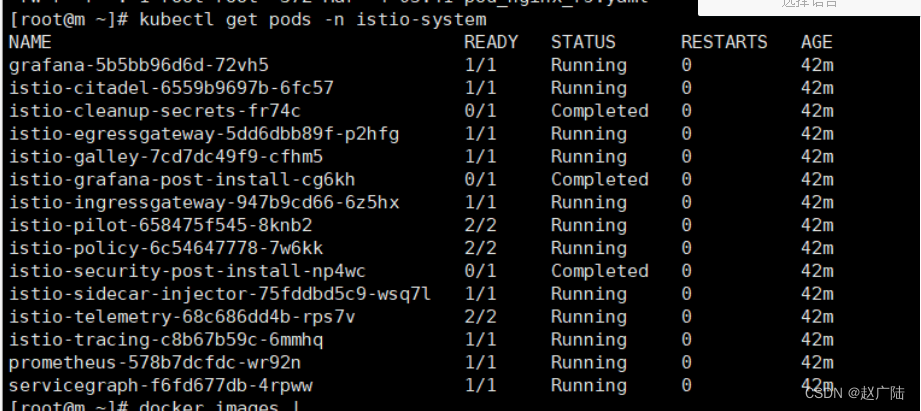
可以看到有3个是completed,其它的组件都必须是running, completed表示的是用的是k8s里面JOB资源,表示这个任务已经执行结束了
可以看到比如citadel有了,pilot有了,sidecar也有了,其它的比如ingress网关都有了,监控也有了
2.2 回顾K8S组件以及使用
回顾课程涉及到的kubernetes组件
2.2.1 Deployment
一旦运行了 Kubernetes 集群,就可以在其上部署容器化应用程序。 为此,需要创建 Kubernetes Deployment 配置。 Deployment 负责 Kubernetes 如何创建和更新应用程序的实例。 创建 Deployment 后,Kubernetes master 将应用程序实例调度到集群中的各个节点上。创建nginx_deployment.yaml文件
apiVersion: apps/v1 ## 定义了一个版本 kind: Deployment ##k8s资源类型是Deployment metadata: ## metadata这个KEY对应的值为一个Maps name: nginx-deployment ##资源名字 nginx-deployment labels: ##将新建的Pod附加Label app: nginx ##一个键值对为key=app,valuen=ginx的Label。 spec: #以下其实就是replicaSet的配置 replicas: 3 ##副本数为3个,也就是有3个pod selector: ##匹配具有同一个label属性的pod标签 matchLabels: ##寻找合适的label,一个键值对为key=app,value=nginx的Labe app: nginx template: #模板 metadata: labels: ##将新建的Pod附加Label app: nginx spec: containers: ##定义容器 - name: nginx ##容器名称 image: nginx:1.7.9 ##镜像地址 ports: - containerPort: 80 ##容器端口(1)执行资源文件命令
kubectl apply -f nginx_deployment.yaml(2)查看pod
kubectl get pods 查看pod详情 kubectl get pods -o wide(3)查看deployment命令
kubectl get deployment(4)查看deployment详情命令
kubectl get deployment -o wide
2.2.2 Labels and Selectors
顾名思义,就是给一些资源打上标签的labels
当资源很多的时候可以用可以用labels标签来对资源分类
apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: app: nginx # 表示名称为nginx-pod的pod,有一个label,key为app,value为nginx。 #我们可以将具有同一个label的pod,交给selector管理selectors
如果我想使用这个标签里面的k8s资源,那么需要用到k8s里面selector组件,用selector来匹配到特定的的label
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: # 定义了一个labels,key=app,value=nginx app: nginx spec: replicas: 3 selector: # 用selector匹配具有同一个label属性的pod标签 matchLabels: app: nginx查看pod的label标签命令:
kubectl get pods --show-labels
2.2.3 Namespace
命名空间就是为了隔离不同的资源。比如:Pod、Service、Deployment等。可以在输入命令的时候指定命名空间`-n`,如果不指定,则使用默认的命名空间:default。查看一下当前的所用命名空间:
kubectl get namespaces/ns查看一下kube-system命名空间:
kubectl get pods -n kube-system(1)创建自己的namespace
my-namespace.yaml
apiVersion: v1 kind: Namespace metadata: name: myns(2)执行命令:kubectl apply -f my-namespace.yaml
(3)查看命令
kubectl get ns删除命名空间
kubectl delete namespaces 空间的名字
注意: 删除一个namespace会自动删除所有属于该namespace的资源。 default和kube-system命名空间不可删除。
2.2.4 Service
集群内部访问方式(ClusterIP)
Pod虽然实现了集群内部互相通信,但是Pod是不稳定的,比如通过Deployment管理Pod,随时可能对Pod进行扩缩容,这时候Pod的IP地址是变化的。能够有一个固定的IP,使得集群内能够访问。也就是之前在架构描述的时候所提到的,能够把相同或者具有关联的Pod,打上Label,组成Service。而Service有固定的IP,不管Pod怎么创建和销毁,都可以通过Service的IP进行访问 k8s用service来解决这个问题,因为service会对应一个不会的ip,然后内部通过负载均衡到相同label上的不同pod机器上(1)创建whoami-deployment.yaml文件
apiVersion: apps/v1 ## 定义了一个版本 kind: Deployment ##资源类型是Deployment metadata: ## metadata这个KEY对应的值为一个Maps name: whoami-deployment ##资源名字 labels: ##将新建的Pod附加Label app: whoami ##key=app:value=whoami spec: ##资源它描述了对象的 replicas: 3 ##副本数为1个,只会有一个pod selector: ##匹配具有同一个label属性的pod标签 matchLabels: ##匹配合适的label app: whoami template: ##template其实就是对Pod对象的定义 (模板) metadata: labels: app: whoami spec: containers: - name: whoami ##容器名字 下面容器的镜像 image: jwilder/whoami ports: - containerPort: 8000 ##容器的端口jwilder/whoami这是一个可以在docker仓库里面拉取到的镜像,是官方提供的一个演示的镜像
(1)执行命令
kubectl apply -f whoami-deployment.yaml(2)查看详情
kubectl get pods -o wide(3)在集群内正常访问
curl 192.168.221.80:8000/192.168.14.6:8000/192.168.14.7:8000(5)测试:删除其中一个pod,查看重新生成的ip有没有变化
kubectl delete pod whoami-deployment-678b64444d-jdv49新加的pod地址发生了变化
(6) Service 登场
查询svc命名空间下的资源
kubectl get svc(7)创建自己的service空间
创建:kubectl expose deployment deployment名字 例如:kubectl expose deployment whoami-deployment(8)重新查询service空间,会发现有一个whoami-deployment的service,ip为10.107.4.74
[root@m k8s]# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d12h whoami-deployment ClusterIP 10.107.4.74 <none> 8000/TCP 3s(9)访问service:curl 10.107.4.74:8000
多试几次会发现service会负载到其中的一个pod上
(10)查看service
kubectl describe svc service名字 例如:kubectl describe svc whoami-deployment[root@m k8s]# kubectl describe svc whoami-deployment Name: whoami-deployment Namespace: default Labels: app=whoami Annotations: <none> Selector: app=whoami Type: ClusterIP IP: 10.107.4.74 Port: <unset> 8000/TCP TargetPort: 8000/TCP Endpoints: 192.168.190.86:8000,192.168.190.87:8000,192.168.190.89:8000 Session Affinity: None Events: <none> # 说白了 service下面挂在了Endpoints节点(11)将原来的节点扩容到5个
kubectl scale deployment whoami-deployment --replicas=5(12)删除service命令
kubectl delete service service名字 kubectl delete service whoami-deployment总结:其实Service存在的意义就是为了Pod的不稳定性,而上述探讨的就是关于Service的一种类型Cluster IP
外部服务访问集群中的Pod(NodePort)
也是Service的一种类型,可以通过NodePort的方式
说白了,因为外部能够访问到集群的物理机器IP,所以就是在集群中每台物理机器上暴露一个相同的端口锁,比如32008
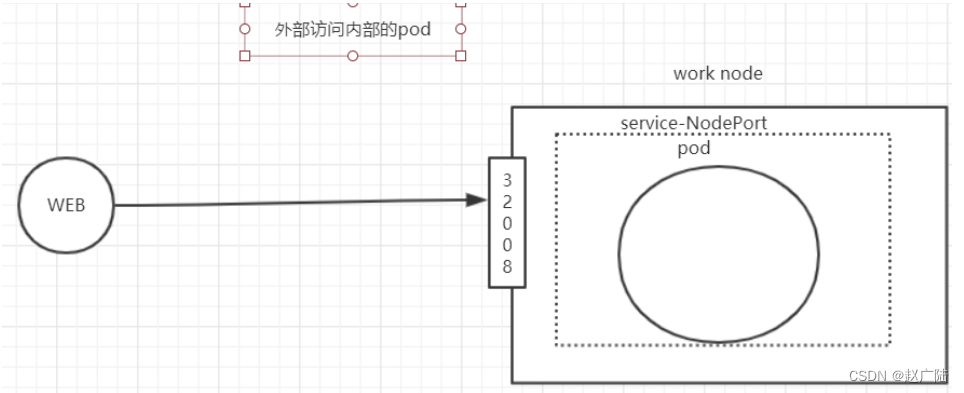
操作
(1)先删除之前的service
kubectl delete svc whoami-deployment(2)再次查看命令
kubectl get svc 发现whoami-deployment已被删除(3)查看pod命令
kubectl get pods(4)创建type为NodePort的service
kubectl expose deployment whoami-deployment --type=NodePort查看:kubectl get svc

并且生成了一个port端口,会有一个8000端口映射成宿主机的31504端口
注意上述的端口31504,实际上就是暴露在集群中物理机器上的端口
lsof -i tcp:31504 netstat -ntlp|grep 31504浏览器通过物理机器的IP访问
http://192.168.187.137:31504/ curl 192.168.187.137:31504/NodePort虽然能够实现外部访问Pod的需求,但是需要占用了各个物理主机上的端口
删除资源
kubectl delete -f whoami-deployment.yaml kubectl delete svc whoami-deployment
2.2.5 Ingress
前面我们也学习可以通过service nodeport方式实现外部访问Pod的需求,但是会占用了各个物理主机上的端口,所以 这种方式不好
删除资源
# 删除pod kubectl delete -f whoami-deployment.yaml # 删除service kubectl delete svc whoami-deployment
那接下来还是基于外部访问内部集群的需求,使用Ingress实现访问whoami需求。
(1)创建whoami-service.yaml文件
创建pod和service
apiVersion: apps/v1 ## 定义了一个版本 kind: Deployment ##资源类型是Deployment metadata: ## metadata这个KEY对应的值为一个Maps name: whoami-deployment ##资源名字 labels: ##将新建的Pod附加Label app: whoami ##key=app:value=whoami spec: ##资源它描述了对象的 replicas: 3 ##副本数为1个,只会有一个pod selector: ##匹配具有同一个label属性的pod标签 matchLabels: ##匹配合适的label app: whoami template: ##template其实就是对Pod对象的定义 (模板) metadata: labels: app: whoami spec: containers: - name: whoami ##容器名字 下面容器的镜像 image: jwilder/whoami ports: - containerPort: 8000 ##容器的端口 --- apiVersion: v1 kind: Service metadata: name: whoami-service spec: ports: - port: 80 protocol: TCP targetPort: 8000 selector: app: whoami(2)执行资源命令
kubectl apply -f whoami-service.yaml(3)创建whoami-ingress.yaml文件
apiVersion: extensions/v1beta1 kind: Ingress # 资源类型 metadata: name: whoami-ingress # 资源名称 spec: rules: # 定义规则 - host: whoami.qy.com # 定义访问域名 http: paths: - path: / # 定义路径规则,/ 表示能够命中任何路径规则 backend: serviceName: whoami-service # 把请求转发给service资源,这个service就是我们前面运行的service servicePort: 80 # service的端口(4)执行命令:
kubectl apply -f whoami-ingress.yaml(5)、查看ingress资源:
kubectl get ingress(6)查看ingress资源详细:
kubectl describe ingress whoami-ingress(7)、修改win的hosts文件,添加dns解析
192.168.187.137 whoami.qy.com(8)、打开浏览器,访问whoami.qy.com
流程总结
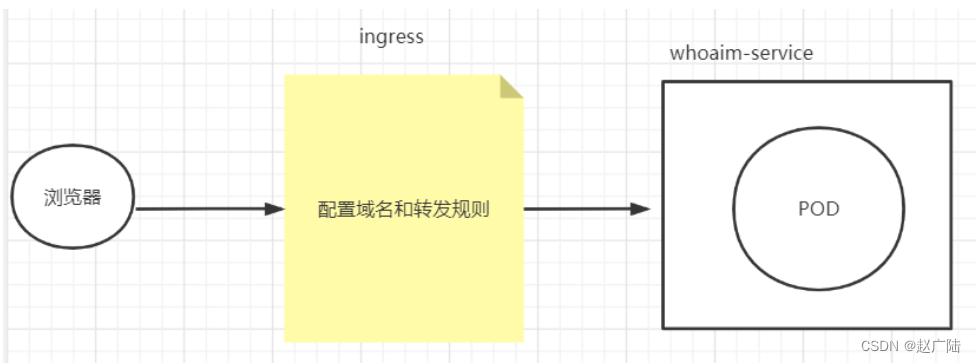
浏览器发送请求给ingress,ingress根据规则配置把请求转发给对应的service,由于service配置了pod,所以请求最终发给了pod内对应的服务
总结
ingress转发请求更加灵活,而且不需要占用物理机的端口,所以建议使用这种方式转发外部请求到集群内部
2.3 初步感受istio
在docker中是通过container来部署业务的,在k8s里面是通过pod来部署业务的,那么在istio里面如何体现sidecar呢?
猜想:会不会在pod中除了业务需要的container之外还会有一个sidecar的container存在呢?验证猜想
(1)准备一个资源 first-istio.yaml
apiVersion: apps/v1 ## 定义了一个版本 kind: Deployment ##资源类型是Deployment metadata: name: first-istio spec: selector: matchLabels: app: first-istio replicas: 1 template: metadata: labels: app: first-istio spec: containers: - name: first-istio ##容器名字 下面容器的镜像 image: registry.cn-hangzhou.aliyuncs.com/sixupiaofei/spring-docker-demo:1.0 ports: - containerPort: 8080 ##容器的端口 --- apiVersion: v1 kind: Service ##资源类型是Service metadata: name: first-istio ##资源名字first-istio spec: ports: - port: 80 ##对外暴露80 protocol: TCP ##tcp协议 targetPort: 8080 ##重定向到8080端口 selector: app: first-istio ##匹配合适的label,也就是找到合适pod type: ClusterIP ## Service类型ClusterIP创建文件夹istio,然后把first-istio放进去,按照正常的创建流程里面只会有自己私有的containers,不会有sidecar
#执行,会发现 只会有一个containers在运行 kubectl apply -f first-istio.yaml #查看first-isitio service kubectl get svc # 查看pod的具体的日志信息命令 kubectl describe pod first-istio-8655f4dcc6-dpkzh #删除 kubectl delete -f first-istio.yaml
查看pod命令
kubectl get pods

思考:怎么让pod里面自动增加一个Sidecar呢?
有两种方式:手动注入和自动注入
2.4 手动注入
(1)删除上述资源,重新创建,使用手动注入sidecar的方式
istioctl kube-inject -f first-istio.yaml | kubectl apply -f -
**注意:**istioctl 命令需要先在/etc/profile配置PATH
vim /etc/profile
增加isito安装目录配置
export ISTIO_HOME=/home/tools/istio-1.0.6 export PATH=$PATH:$ISTIO_HOME/bin
- 加载profile文件
source profile
(2)查看pod数量
kubectl get pods # 注意该pod中容器的数量 ,会发现容器的数量不同了,变成了2个

(3) 查看service
kubectl get svc
思考:
我的yaml文件里面只有一个container,执行完之后为什么会是两个呢?
我的猜想另外一个会不会是Sidecar,那么我描述一下这个pod,看看这两个容器到底是什么
# 查看pod执行明细 kubectl describe pod first-istio-75d4dfcbff-qhmxj
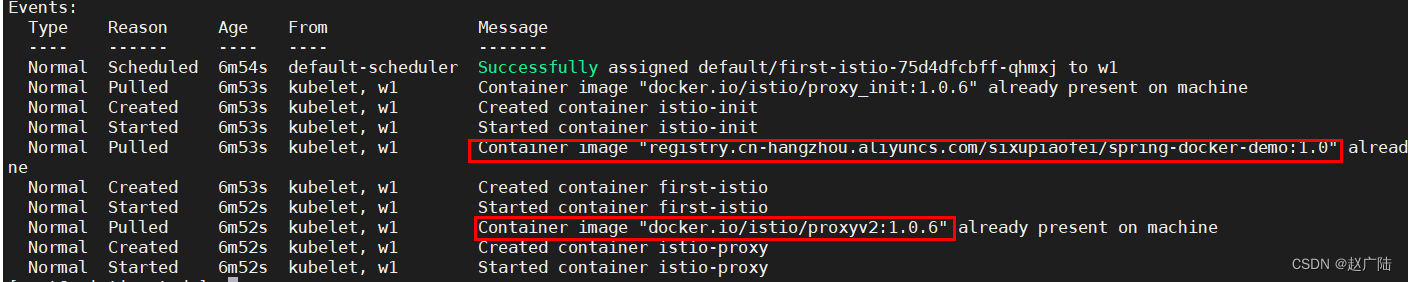
发现竟然除了我的容器之外还多了一个代理容器,此时我们大胆猜想这个代理会不会就是sidecar呢
接着往上翻
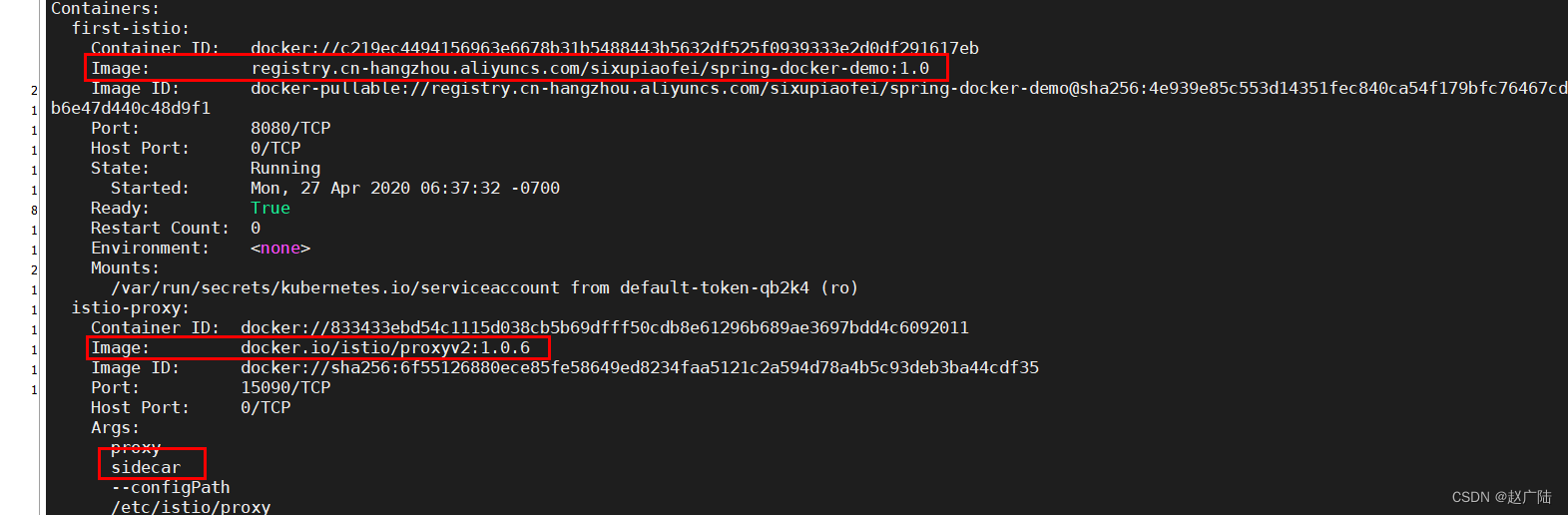
此时已经看到了我们需要的答案了
查看yaml文件内容
kubectl get pod first-istio-75d4dfcbff-qhmxj -o yaml
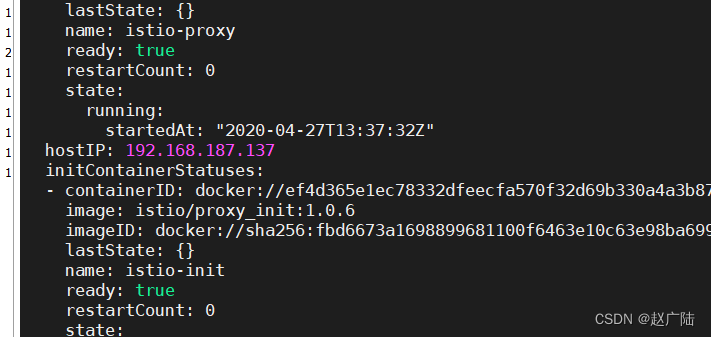
总结
这个yaml文件已经不是我们原来的yaml文件了,会发现这个yaml文件还定义了一个proxy的image,这个image是我们提前就已经准备好了的,所以istio是通过改变yaml文件来实现注入一个代理
(4)删除资源
istioctl kube-inject -f first-istio.yaml | kubectl delete -f -
**思考:**难道我以后每次都要写那么一大串命令创建sidecar吗,有没有正常的命令来直接创建sidecar呢?
2.5 自动注入sidecar
首先自动注入是需要跟命名空间挂钩,所以需要创建一个命名空间,只需要给命名空间开启自动注入,后面创建的资源只要挂载到这个命名空间下,那么这个命名空间下的所有的资源都会自动注入sidecar了
(1)创建命名空间
kubectl create namespace my-istio-ns
(2)给命名空间开启自动注入
kubectl label namespace my-istio-ns istio-injection=enabled
(3)创建资源,指定命名空间即可
# 查询 istio-demo命名空间下面是否存在资源
kubectl get pods -n my-istio-ns
# 在istio-demo命名空间创建资源
kubectl apply -f first-istio.yaml -n my-istio-ns
(4)查看资源
kubectl get pods -n my-istio-ns
(5)查看资源明细
kubectl describe pod pod-name -n my-istio-ns
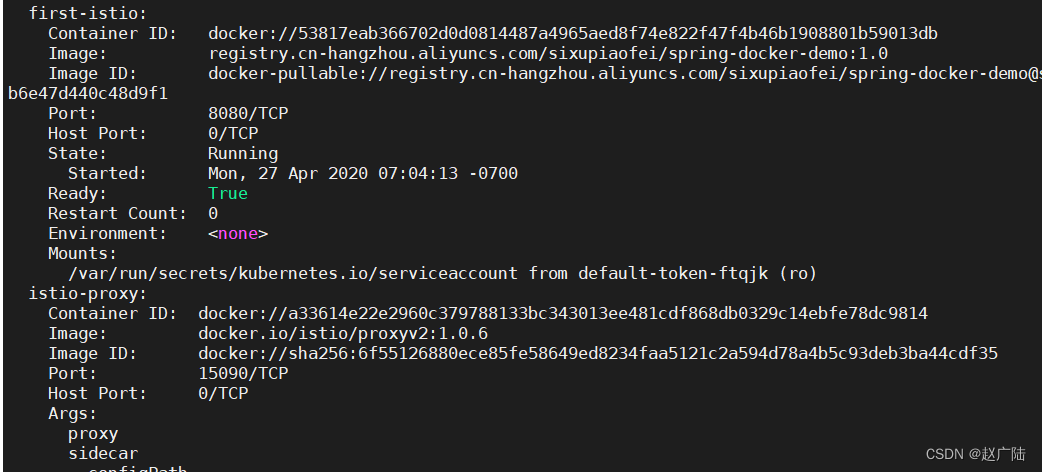
发现除了我的容器之外依旧多了一个代理容器
(6)查看service
kubectl get svc -n my-istio-ns
(7)删除资源
kubectl delete -f first-istio.yaml -n my-istio-ns
大家应该都已经明白了istio怎么注入sidecar的了吧
sidecar注入总结:
不管是自动注入还是手动注入原理都是在yaml文件里面追加一个代理容器,这个代理容器就是sidecar,这里更推荐自动注入的方式来实现 sidecar 的注入