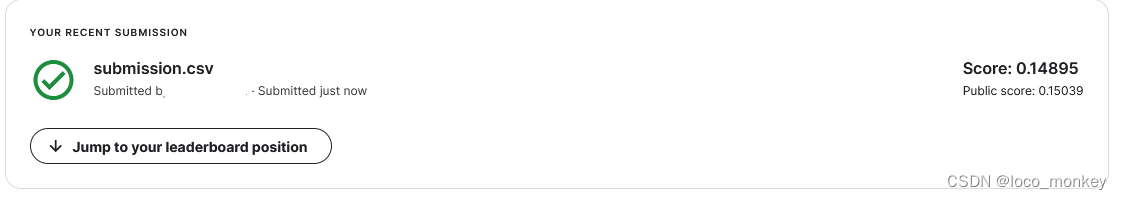目录
任务:对食物的图片使用CNN进行分类
一共有11种食物
训练集(Training set):9866张带有标签label的图片(label包含在图片title种)
验证集(Validation set):3430张带有label的图片
测试集(Testing set):3347张没有label的图片
Baseline
Simple:0.50099(运行初始代码即可)
Medium:0.73207 Training Augmentation+Train Longer
进行数据增强,增加训练次数
Strong:0.81872 Training Augmentation+Model Design+Train Longer(Cross
Validation+Ensemble)
Boss:0.88446 Training Augmentation+Model Design+Test Time Augmentation +Train Longer(Cross Validation+Ensemble)
Simple
初始代码运行时遇到了一个bug,在Dataset模块
一开始使用GPU训练时,报错了但无法定位出错位置,后来换成CPU训练,定位到错误
解决了一个bug
使用GPU时的error
RuntimeError Traceback (most recent call last)
<ipython-input-10-b55e170576c6> in <module>()
49
50 # Compute the gradients for parameters.
---> 51 loss.backward()
52
53 # Clip the gradient norms for stable training.
D:\Python_resource\ANACONDA\anaconda\envs\pytorch\lib\site-packages\torch\_tensor.py in backward(self, gradient, retain_graph, create_graph, inputs)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
使用CPU时的error
切换CPU训练时,得重启项目
IndexError Traceback (most recent call last)
<ipython-input-9-8535fa60da04> in <module>()
43 # Calculate the cross-entropy loss.
44 # We don't need to apply softmax before computing cross-entropy as it is done automatically.
---> 45 loss = criterion(logits, labels.to(device))
46
47 # Gradients stored in the parameters in the previous step should be cleared out first.
IndexError: Target -1 is out of bounds.
发现是在计算training set的loss时出现了-1的下标越界,然后就通过train_dataset查看了读取到的training data,发现所有training_data读取进来的label都是-1,然后查看数据集,所有training图片都没有-1的label
#所有training_data读取进来的label都是-1
print(train_set.__getitem__(1))
'''
(tensor([[[0.0118, 0.0196, 0.0235, ..., 0.0078, 0.0000, 0.0039],
[0.1843, 0.3843, 0.4392, ..., 0.1647, 0.0118, 0.0039],
[0.5804, 0.6314, 0.6353, ..., 0.2863, 0.0157, 0.0000],
...,
[0.3804, 0.3686, 0.3647, ..., 0.7294, 0.2314, 0.0078],
[0.4078, 0.4039, 0.3922, ..., 0.6549, 0.1412, 0.0039],
[0.2039, 0.3294, 0.3765, ..., 0.2980, 0.0314, 0.0039]],
[[0.0118, 0.0235, 0.0314, ..., 0.0118, 0.0039, 0.0000],
[0.2118, 0.4157, 0.4784, ..., 0.1608, 0.0118, 0.0000],
[0.6275, 0.6824, 0.6902, ..., 0.2745, 0.0157, 0.0000],
...,
[0.0157, 0.0157, 0.0157, ..., 0.7216, 0.2235, 0.0039],
[0.0196, 0.0118, 0.0157, ..., 0.6471, 0.1333, 0.0039],
[0.0196, 0.0314, 0.0196, ..., 0.2863, 0.0235, 0.0039]],
[[0.0196, 0.0275, 0.0353, ..., 0.0275, 0.0039, 0.0157],
[0.1804, 0.3765, 0.4275, ..., 0.1451, 0.0078, 0.0157],
[0.5608, 0.6118, 0.6118, ..., 0.2902, 0.0314, 0.0118],
...,
[0.1176, 0.1137, 0.1137, ..., 0.5882, 0.1882, 0.0118],
[0.1216, 0.1216, 0.1216, ..., 0.5451, 0.1176, 0.0078],
[0.0549, 0.1020, 0.1176, ..., 0.2431, 0.0353, 0.0118]]]), -1)
'''
Datasets
然后查看读取数据的Dataset部分,定位到产生label的部分
class FoodDataset(Dataset):
def __init__(self,path,tfm=test_tfm,files = None):
super(FoodDataset).__init__()
self.path = path
self.files = sorted([os.path.join(path,x) for x in os.listdir(path) if x.endswith(".jpg")])
if files != None:
self.files = files
print(f"One {
path} sample",self.files[0])
self.transform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self,idx):
fname = self.files[idx]
im = Image.open(fname)
im = self.transform(im)
#im = self.data[idx]
try:
label = int(fname.split("/")[-1].split("_")[0])
except:
label = -1 # test has no label
return im,label
label = int(fname.split("/")[-1].split("_")[0])
#首先通过"/"对fname字符串进行分割,然后取最后一块,再通过"_"对最后一块进行分割,取第一个字符,转换为int类型即为label
怀疑是这里分割时产生了问题,打印了fname
#输出
./food11\\training\\0_1.jpg'
问题就在这,明明是通过反斜杠"\“进行分割
修改为: label = int(fname.split(”\\“)[-1].split(”_")[0])
在training_data和validation_data上的训练结果

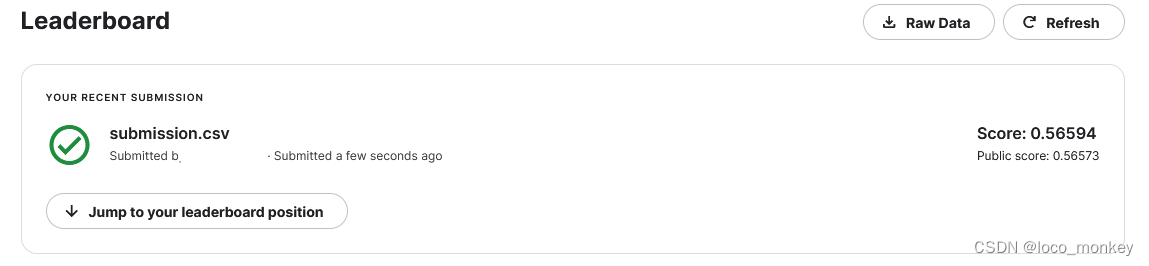 跑通助教code过simple
跑通助教code过simple

Medium
使用data augmentation(torchvision.transforms)
transforms教程
compose就是将不同的transforms结合在一起
data augmentation
查看了一圈都只是描述了如何进行数据增强,但是都没有解释原理。
首先使用的transforms是对dataset中的数据使用,但是使用了transforms后并不是生成新的图片,而是将原图片改变。
那么将原图片改变了,数据集的数量不还是没有变多,如何进行数据增强?
这时注意到transforms中对图片的操作有大部分是以一定概率进行的,说明进行训练的数据不是一定和原数据集不一样,因此在一个epoch中,会有一部分图片进行了变换,一部分没有进行变换。
要使‘数据增强’发挥出性能,就得增加epoch数量,这样,喂给网络的图片中,会尽可能的包含原数据集数据,同时也会有大部分经过transformes的数据。
还见过一种方式,将transforms和training分开,先通过transforms生成数据集,和原数据集一起训练。
transforms_01
对图片使用了Normalize,没有必要,因为CNN网络中就使用了BatchNorm2d
# Normally, We don't need augmentations in testing and validation.
# All we need here is to resize the PIL image and transform it into Tensor.
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# However, it is also possible to use augmentation in the testing phase.
# You may use train_tfm to produce a variety of images and then test using ensemble methods
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128, 128)),
# You may add some transforms here.
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]), #每张图片有3个通道,设置3个均值和3个标准差
])
training:在validation_set上表现效果不如样例

Transforms_02
以下对图片的操作机本上都是选取的随机操作。
# Normally, We don't need augmentations in testing and validation.
# All we need here is to resize the PIL image and transform it into Tensor.
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# However, it is also possible to use augmentation in the testing phase.
# You may use train_tfm to produce a variety of images and then test using ensemble methods
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128, 128)),
# You may add some transforms here.
transforms.RandomHorizontalFlip(p=0.5), #50%的概率水平翻转
transforms.RandomVerticalFlip(p=0.5), #50%的概率垂直翻转
transforms.RandomCrop(128, padding=10),
# transforms.RandomGrayscale(p=0.1) #根据概率转灰度channel=1,CNN中in_channel=3,不可行
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1), #修改亮度、对比度和饱和度,色调
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
#transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]), #每张图片有3个通道,设置3个均值和3个标准差
])
Training

从结果可以看出在trainging_data和validation_data上表现差距不大,甚至和助教的样例比起来,在validation上表现更好
接下来就是增加epoch次数
epoch=10时

 没有发挥出性能!
没有发挥出性能!
epoch=30
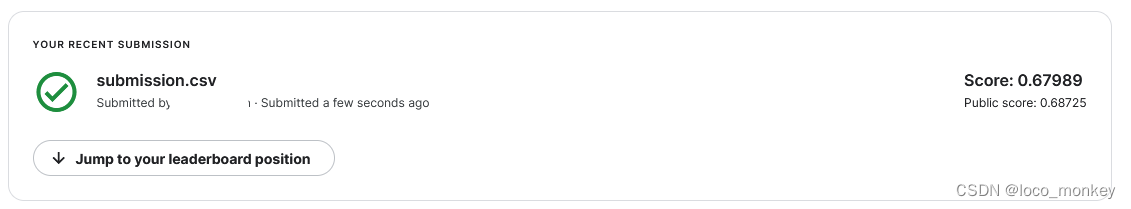
还是没有到medium
epoch=80

明显过拟合
运气比较好,过了medium
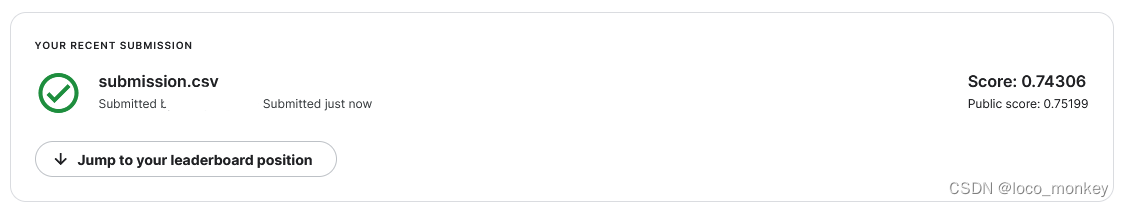 epoch=30时,就有过拟合趋势,但最好的model是在epoch=76时训练出来的!
epoch=30时,就有过拟合趋势,但最好的model是在epoch=76时训练出来的!

这里在training set上表现好,但是在validation set上表现差距有点大,可以判断是有过拟合了,同时训练出来的model是在epoch=76,validation_accuracy=0.73607,与kaggle上得分差不多,说明可能validation set与testing set数据的分布规律差不多,同时没有在validation set上过拟合
Strong
接下来计划通过Model Design来进一步提升accuracy
首先使用Residual Network (残差网络)
推荐一位大牛老师的教程, 包含GoogLeNet和Residual Network
Residual Network
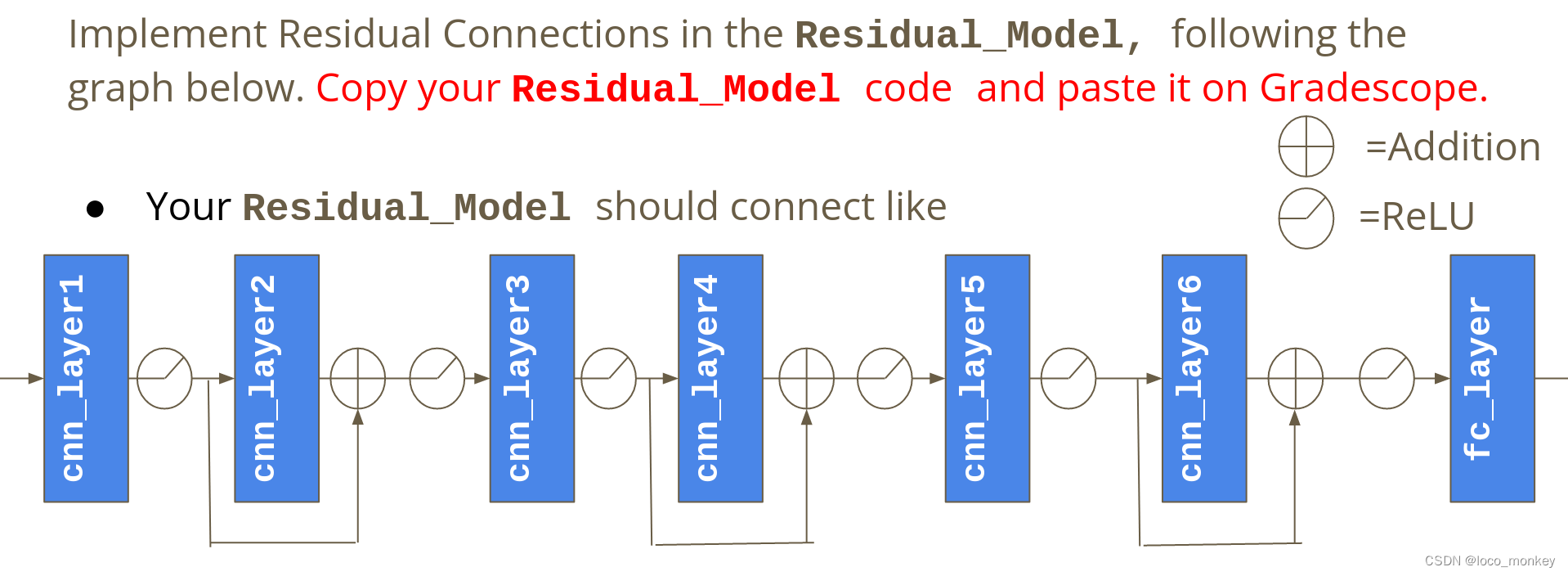 根据提示完成residual network
根据提示完成residual network
from torch import nn
class Residual_Network(nn.Module):
def __init__(self):
super(Residual_Network, self).__init__()
self.cnn_layer1 = nn.Sequential( #layer1_output_channel=64
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),
)
self.cnn_layer2 = nn.Sequential( #layer2_output_channel=64 layer2_input_channel=64
nn.Conv2d(64, 64, 3, 1, 1),
nn.BatchNorm2d(64),
)
self.cnn_layer3 = nn.Sequential( #这里layer3的input包含relu(layer1)的output和layer2的output
nn.Conv2d(64, 128, 3, 2, 1), #尤其需要注意,使用residual时,前一层的输出需要和下下层的输入channel维度相同
nn.BatchNorm2d(128),
)
self.cnn_layer4 = nn.Sequential(
nn.Conv2d(128, 128, 3, 1, 1),
nn.BatchNorm2d(128),
)
self.cnn_layer5 = nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1),
nn.BatchNorm2d(256),
)
self.cnn_layer6 = nn.Sequential(
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
)
self.fc_layer = nn.Sequential(
nn.Linear(256* 32* 32, 256),
nn.ReLU(),
nn.Linear(256, 11)
)
self.relu = nn.ReLU()
def forward(self, x):
# input (x): [batch_size, 3, 128, 128]
# output: [batch_size, 11]
# Extract features by convolutional layers.
x1 = self.cnn_layer1(x)
x1 = self.relu(x1)
residual=x1
x2 = self.cnn_layer2(x1)
x2 = self.relu(x2+residual) #按照提示,relu(layer1)和layer2一起relu后再作为layer3的input
x3 = self.cnn_layer3(x2)
x3 = self.relu(x3)
residual=x3
x4 = self.cnn_layer4(x3)
x4 = self.relu(x4+residual)
x5 = self.cnn_layer5(x4)
x5 = self.relu(x5)
residual=x5
x6 = self.cnn_layer6(x5)
x6 = self.relu(x6+residual)
# The extracted feature map must be flatten before going to fully-connected layers.
xout = x6.flatten(1)
# The features are transformed by fully-connected layers to obtain the final logits.
xout = self.fc_layer(xout)
return xout
可跑

Cross Validation
实现了cross validation后和residual network配合使用(训练实在太慢!)
training set有9866张图片
validation set有3430张图片
使用4折交叉验证,重新创建一个数据集,将training/validation set存放在一起。(这里称为cross_validatin数据集)
要寻找合适的数据集划分的位置,需要加深对dataset和dataloader的理解
dataset用来数据加载
dataloader通过从dataset中获取数据然后进行各种操作,在喂给网络进行训练(batch,shuffle)
dataset和dataloader的关系:dataloader先通过dataset里面__getitem__获取单个数据,然后组合成batch.
理解到这里就可以发现,进行cross validation时每一轮epoch都需要加载dataloader,将整个数据集划分成training set 和validation set然后生成train_loader和valid_loader,喂给网络训练。
同时transforms是在dataset中进行的,而验证集不需要进行数据增强,因此每一次epoch,dataset也需要运行
- 首先对数据集进行处理
#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。type(files):list
#files是一个存放了所有图片名称的list
files = sorted([os.path.join("./food11/cross_validation",x) for x in os.listdir("./food11/cross_validation") if x.endswith(".jpg")])
#不能简单的平均分成4份,因为相同label的图片聚集在一起,所以下面的切片方法错误
#flod_1,flod_2,flod_3,flod_4=files[:3324],files[3324:6648],files[6648:9972],files[9972:]
#正确方法,随机划分
flod_1_size=3324
flod_2_size=3324
flod_3_size=3324
flod_4_size=3324
#无重复的随机划分
#使用random_split需要引入 from torch.utils.data import random_split
flod_1,flod_2,flod_3,flod_4 = random_split(files, [flod_1_size, flod_2_size,flod_3_size,flod_4_size], generator=torch.Generator().manual_seed(myseed))
#cross_files作为k_flod()函数中files的传参 ,len(cross_files)=4
cross_files=[list(flod_1),list(flod_2),list(flod_3),list(flod_4)]
- 由于之前数据的读取是在dataset中完成的,现在单独抽出来后,需要修改dataset
class FoodDataset(Dataset):
'''
修改前的__init__
def __init__(self,path,tfm=test_tfm,files = None):
super(FoodDataset).__init__()
self.path = path
这里完成图片名称的读取
self.files = sorted([os.path.join(path,x) for x in os.listdir(path) if x.endswith(".jpg")])
if files != None:
self.files = files
print(f"One {path} sample",self.files[0])
self.transform = tfm
'''
def __init__(self,files,tfm=test_tfm):
super(FoodDataset).__init__()
if files != None:
self.files = files
print(f"One sample",self.files[0])
self.transform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self,idx):
fname = self.files[idx] #files是存放了图片路径的list
#真正图片的读取并不是一开始就全部读入内存,而是在这一步,将需要的图片读入内存(否则内存不够)
im = Image.open(fname)
im = self.transform(im)
#im = self.data[idx]
try:
label = int(fname.split("\\")[-1].split("_")[0])
except:
label = -1 # test has no label
return im,label
- 可以抽象出一个函数,用来生成k折交叉验证数据集的dataloader
#create different train_loader,valid_loader every epoch
def k_flod(epoch,files,batch_size,train_tfm,test_tfm): #files传参cross_files
valid_index=epoch%4 #通过epoch对4取模,来依次生成验证集下标
valid_data=files[valid_index] #validating数据集(通过下标valid_index来取)
train_data=[]
for i in range(4): #将处理下标valid_index的数据合并为一个list,作为training data
if i!=valid_index:
train_data.extend(files[i]) #生成training数据集
train_set = FoodDataset(files=train_data, tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=False)
valid_set = FoodDataset(files=valid_data, tfm=test_tfm)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=0, pin_memory=False)
return train_loader,valid_loader
- 修改training代码中的dataloader来源
for epoch in range(n_epochs):
#生成交叉验证集的dataloader,每一轮epoch都重新选取training和validation的数据
train_loader,valid_loader=k_flod(epoch,cross_files,batch_size,train_tfm,test_tfm)
- 由于dataset改变了,读取test数据的方式也要修改
#FoodDataset修改过了
test_files = sorted([os.path.join("./food11/test",x) for x in os.listdir("./food11/test") if x.endswith(".jpg")])
test_set = FoodDataset(files=test_files, tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=False)
最终运行的code使用了transforms,Residual Network,cross validation
没训练起来,等不了了,太慢了!继续学