视觉识别的快速发展始于 Vision transformer (ViT) 的引入,很快取代了CNN,成为了最火爆的图像分类模型。随着分层Transformer(Swin Transformer)的提出,并在各种视觉任务上表现出卓越的性能,让Transformer模型异常热门。但何凯明实验室研究者重新设计的CNN,即纯卷积网络的ConvNet,证明了CNN并没有变得无关紧要,相反,仍然具有无限价值并且永不褪色!

这篇文章介绍了ConvNet,可以清晰的感觉到作者对于ConvNet的无限热爱。
A ConvNet for the 2020s
Abstract
简述了20年代,随着Vision Transformer(ViTs)的引入,超越了卷积神经网络(CNN),并且在各项计算机视觉任务中表现很优秀,成为了最先进的图像分类模型。在这篇论文中,作者重新设计了纯卷积神经网络(CovNext),将标准的ResNet“现代化”,以此来实现transformer的设计,并改变了几个关键组件,来提高模型的性能。
1、Introduction
作者简单回顾了在2020年之前卷积神经网络(CNN)对深度学习的影响,在计算机视觉任务中占据重要地位。作者认为 ViT 之所以效果好,是因为它是一个大模型,能够适配大量数据集,这使得它能够在分类领域中领先 ResNet 一大截。但是 CV 中不仅仅只有分类任务,对于大部分的 CV 任务,利用的都是滑动窗口,全卷积这样的方式。同时作者指出了 ViT 的一个最大问题:ViT 中的 global attention 机制的时间复杂度是平方级别的,对于大图片来讲,计算效率会很低。
随着Swin Transformer的出现,利用的是“local window attention”的机制,即滑动窗口的机制,这说明了CNN的局部提取信息的机制还是有作用的,因此,作者更加坚信ConvNets不会退出历史的舞台。在paper中,作者设计了纯粹的卷积神经网络,即ConvNext,为了探究它的极限在哪里。
2、Modernizing a ConvNet: a Roadmap
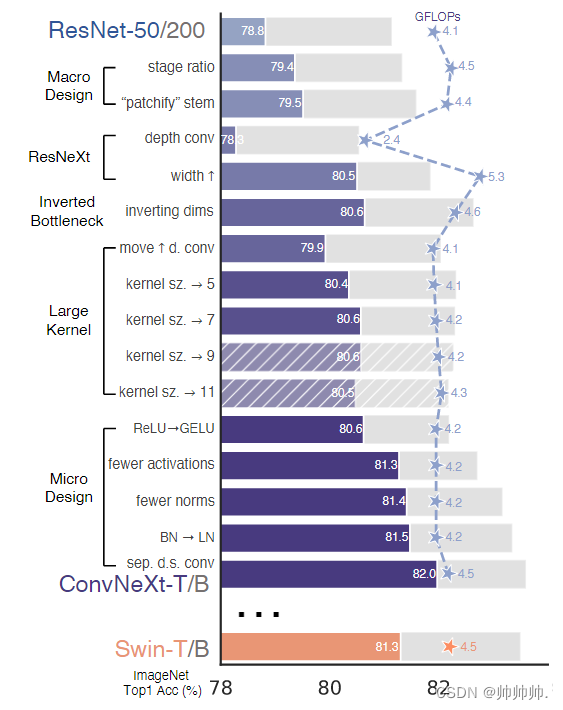
在这部分,从ResNet-50开始,作者研究了将ResNet“现代化”的一系列操作,通过 FLOPs 和在 ImageNet-1K 上的 Acc 这两个指标来验证改进操作是否有效。下图是一些列操作的结果。
2.1 Training Techniques
最终的性能不仅受网络结构的影响,也会因为训练过程的不同而不同。
首先是训练技巧上更新变成与 DeiT 相似,作者将 epochs 从 90 改成了 300。利用优化器AdamW和数据增强技术(Mixup,Cutmix,RandAugment,RandomErasing)以及正则化方案(Stochastic Depth,Label Smoothing),ResNet-50的性能从76.1%提升 到78.8%。
2.2 Macro Design
在宏观上,有两个设计:
1、Changing stage compute ratio.
仿照Swin层级设计,调整ResNet-50的计算率(3,4,6, 3)变为(3,3, 9, s3),Acc从78.8%到79.4%。
2、Changing stem to “Patchify”.
作者仿照 ViT,进行了non-overlapping的convolution。是利用 4×4 ,stride 4 的卷积进行操作,Acc 由 79.4% 提升到 79.5%。
2.3 ResNeXt-ify
使用了ResNeXt的思路,对FLOP和accuracy进行trade off,核心是group convolution。作者采用的是depthwise convolution也就是卷积数=通道数。这里也提到了 ViT 就是 depthwise conv 和 1×1 conv 进行 channel mixing,也同时在 spatial 维度上进行特征融合。MobileNet 和 Xception 都用到了depthwise,可以有效的降低FLOPs。作者将通道数从64提升到跟Swin-T`s一样的96,因此 网络的性能提升到了80.5%,FLOPs增加到5.3G。
2.4 Inverted Bottleneck(反转瓶颈)
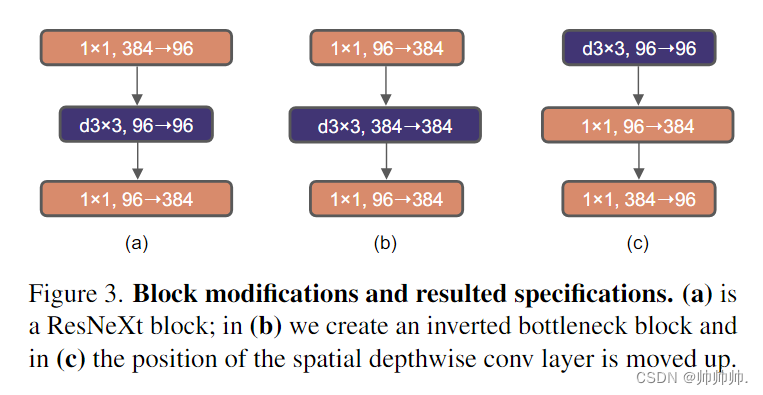
Transformer 中一个重要的设计是创建了反转瓶颈,即 MLP 块的隐藏维度比输入维度宽四倍
在MobileNetV2 中就用到了Inverted Bottleneck,作者从中得到灵感。如图所示,修改了 Bottleneck 的结构如(b)所示,性能从 80.5% 提升到了 80.6%。
2.5 Large Kernel Sizes
作者也想使用大的 Kernel size,因为 Swin 中最小的 Kernel size 也比 ResNet kernel size 的 3 * 3 大。
Moving up depthwise convlayer.
借鉴了Transformer,MSA块提供先验条件给MLP层,因此将depthwise convlution层向上移动之后,减少了FLOPs到4.1G,Acc下降到了79.9%。
Increasing the kernel size.
通过这些准备工作之后,增大 kernel size 的效果将会是显著的。实验了kernel size =3,5,7,9,11,之后,通过比较 kernel size = 7,这几种卷积核的 FLOPs 基本相同,其中 7×7 效果是最好的达到了 80.6%,3×3 的效果只有 79.9%。作者同时做了对于能力强的模型例如 ResNet-200 这样的大模型,效果并没有明显提升。最后,作者也吐槽到这些技巧都是从ViT中借鉴的。
2.6 Micro Design
在微观设计上的改动,大多数都是在层级上完成的,重点是激活函数和归一化层的选择。
Replacing ReLU with GELU.
ReLU的性能表现的非常好,但是在Google’s BERT 、OpenAI’s GPT-2 、ViTs中都用到了GELU,因此,作者决定也使用GELU代替ReLU,Acc保存不变。
Fewer activation functions.
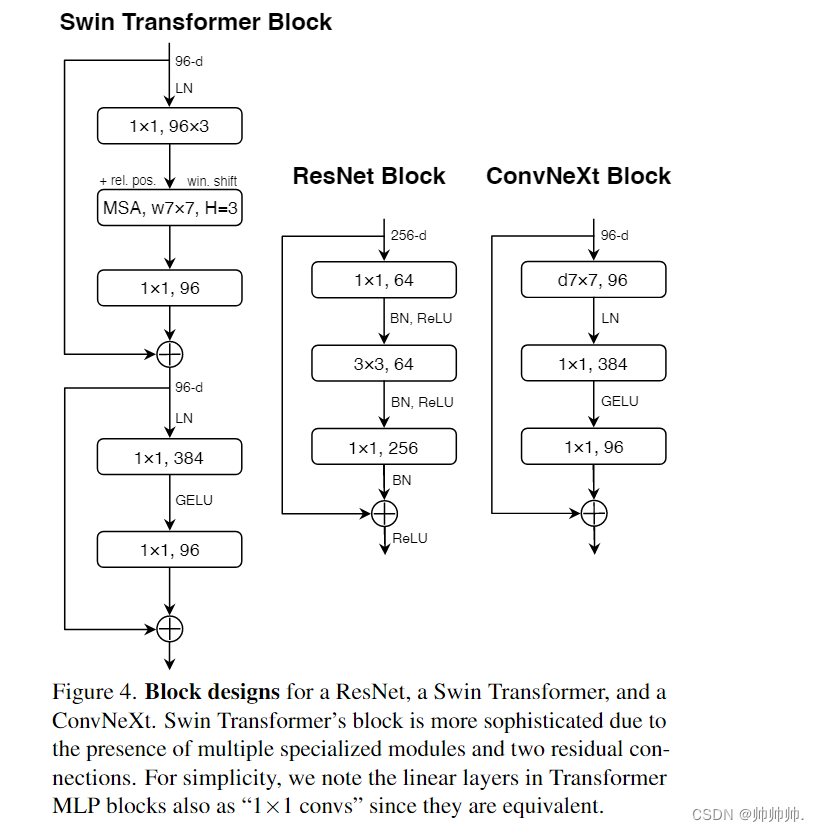
借鉴了Transformer,使用较少的 activation function。如Fig 4所示,消除了所有GELU层只保留一个1 * 1 之间的一个。
Fewer normalization layers.
依然借鉴了Transformer,使用较少的 normalization layers。
Substituting BN with LN.
BatchNorm是ConvNets中的一个重要组成部分,它提高了收敛性,减少了过拟合。但是BN对模型的性能也有不利之处。尽管如此,BN仍然是最好的选择在各种视觉任务中。在transformer中使用LN(Layer Normalization)获得了不错的表现,但是在ConvNext中仅仅是略好,Acc为81.5%。
Separate downsampling layers.
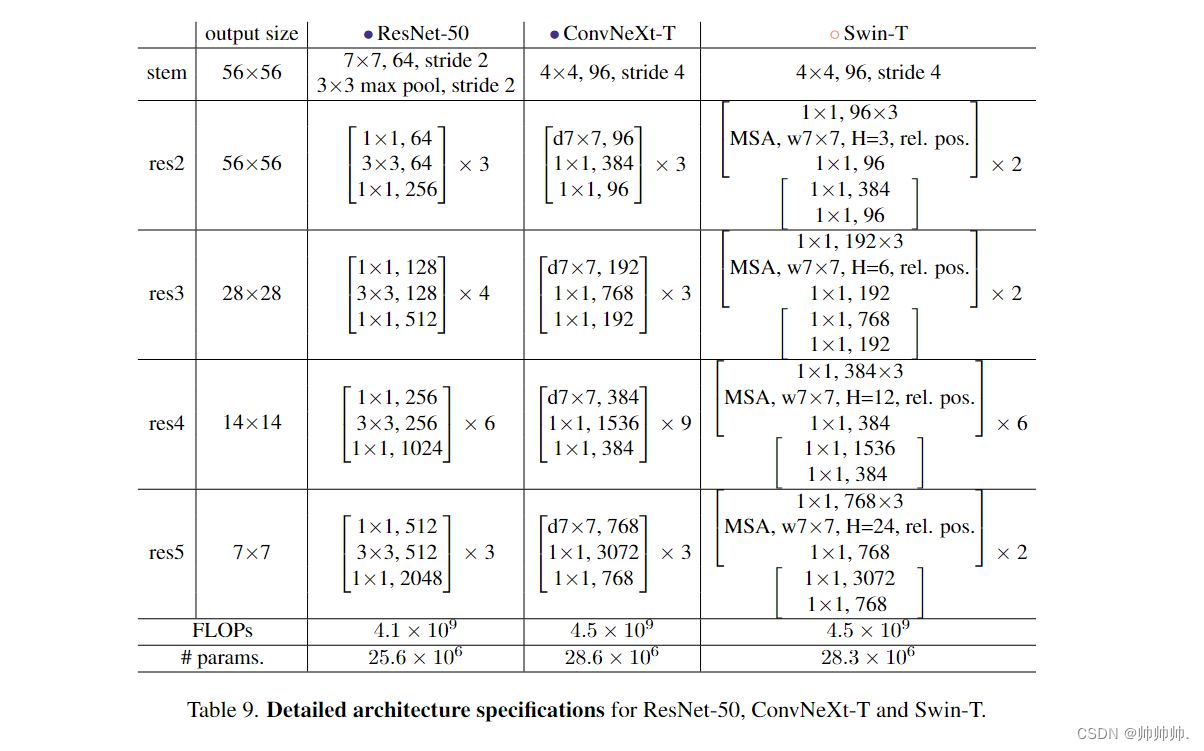
在 ResNet 中,利用 3 * 3, stride = 2 的卷积还有 1 * 1 conv stirde = 2 shortcut connection 做的。在 Swin 中,利用的是 separate downsampling layer 做的,且在每两个 stage 之间。因此,作者修改使用了 2 * 2 的卷积层,stride = 2 的空间下采样。准确率提高到了82.0%,超过了Swin-T的81.3%。该研究采用分离式下采样层,得到了最终模型 ConvNeXt。ResNet、Swin 和 ConvNeXt 块结构的比较如Table 9 所示。
到这里作者的修改也就全部完成了!
3、Empirical Evaluations on ImageNet
在这一部分,作者构造了不同的ConvNeXt变体,比如ConvNeXt-T/S/B/L,和Swin-T/S/B/L的复杂度相似。还设计了更大的模型ConvNeXt-XL为了进一步测试ConvNeXt的可伸缩性。这些变体不同之处在于每一层的channel 和 blocks。如下图所示:

3.1 Settings
作者报告了ImageNet-1K在验证集上的top-1精度,ImageNet-1K数据集由1000个对象类和1.2M训练图像组成。在ImageNet-22K上进行预训练,ImageNet-22K是一个更大的数据集,有21841个类(1000个ImageNet-1K类的超集),有14M张图像用于预训练,然后在ImageNet-1K上对预训练的模型进行微调以进行评估。
3.2 Results
下表是 ConvNeXt 与 Transformer 变体 DeiT、Swin Transformer,以及 RegNets 和 EfficientNets 的结果比较。
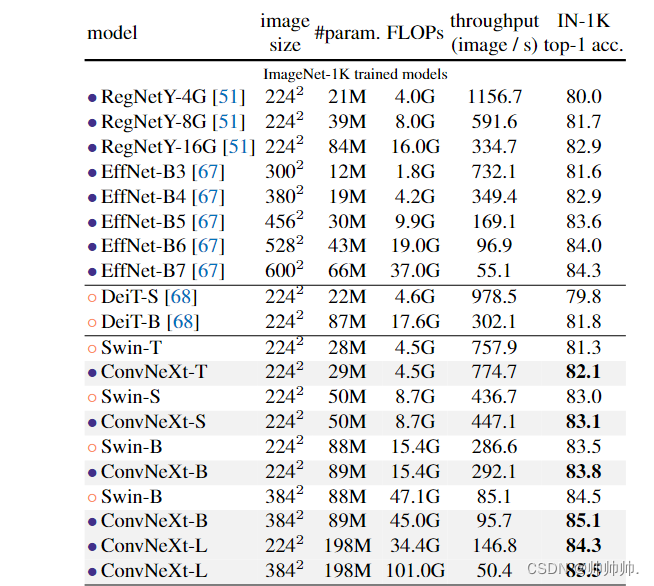
ImageNet-1K :ConvNeXt 在准确率 - 计算权衡以及推理吞吐量方面取得了与 ConvNet 基线(RegNet 和 EfficientNet )具有竞争力的结果;ConvNeXt 的性能也全面优于具有类似复杂性的 Swin Transformer;与 Swin Transformers 相比,ConvNeXts 在没有诸如移位窗口或相对位置偏置等专门模块的情况下也具有更高的吞吐量。
ImageNet-22K:下表(表头参考上表)中展示了从 ImageNet-22K 预训练中微调的模型的结果。这些实验很重要,因为人们普遍认为视觉 Transformer 具有较少的归纳偏置,因此在大规模预训练时可以比 ConvNet 表现更好。该研究表明,在使用大型数据集进行预训练时,正确设计的 ConvNet 并不逊于视觉 Transformer——ConvNeXt 的性能仍然与类似大小的 Swin Transformer 相当或更好,吞吐量略高。此外,该研究提出的 ConvNeXt-XL 模型实现了 87.8% 的准确率——在 384^2 处比 ConvNeXt-L 有了相当大的改进,证明了 ConvNeXt 是可扩展的架构。
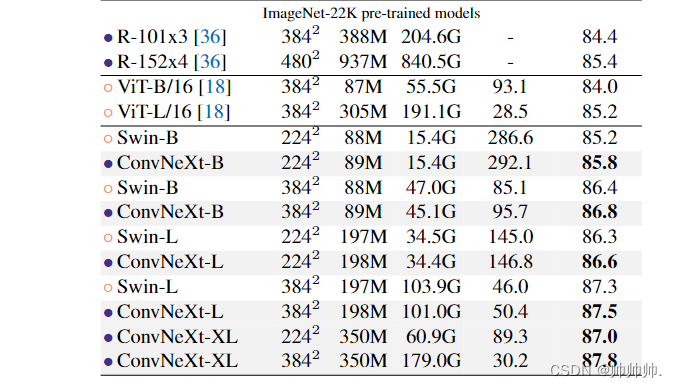
3.2 Isotropic ConvNeXt vs. ViT
在消融实验中,研究者使用与 ViT-S/B/L (384/768/1024) 相同的特征尺寸构建 isotropic ConvNeXt-S/B/L。深度设置为 18/18/36 以匹配参数和 FLOP 的数量,块结构保持不变。ImageNet-1K 在 224^2 分辨率下的结果如表 2 所示。结果显示 ConvNeXt 的性能与 ViT 相当,这表明 ConvNeXt 块设计在用于非分层模型时仍具有竞争力。
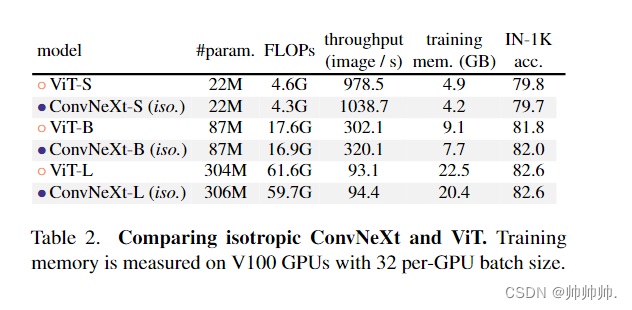
4、Empirical Evaluation on Downstream Tasks
Object detection and segmentation on COCO.
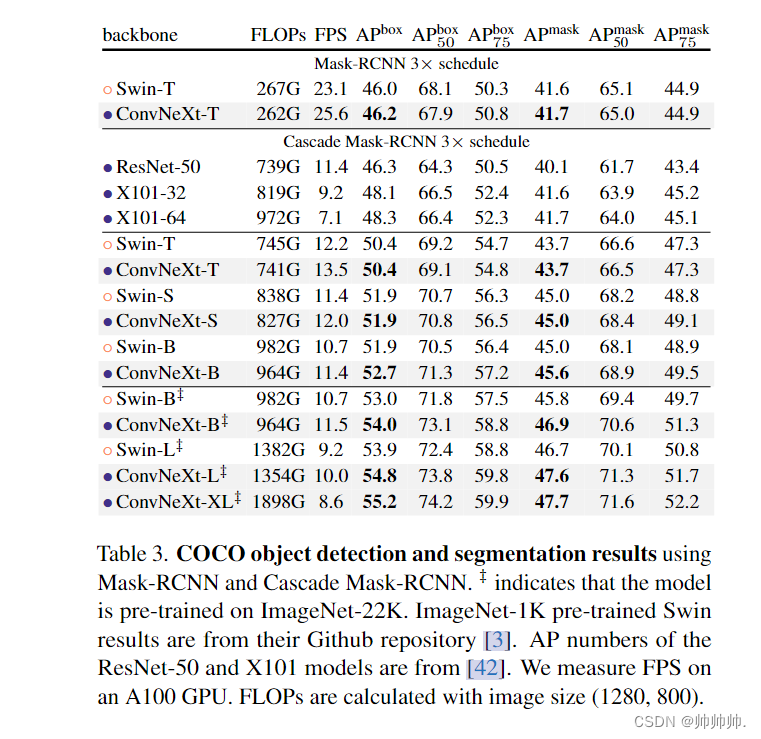
在数据集COCO的目标检测和分割研究,该研究以 ConvNeXt 为主干,在 COCO 数据集上微调 Mask R-CNN 和 Cascade Mask R-CNN 。表 3 比较了 Swin Transformer、ConvNeXt 和传统 ConvNet(如 ResNeXt)在目标检测和实例分割上的结果。结果表明在不同的模型复杂性中,ConvNeXt 的性能与 Swin Transformer 相当或更好。
Semantic segmentation on ADE20K.
在表 4 中,该研究报告了具有多尺度测试的验证 mIoU。ConvNeXt 模型可以在不同的模型容量上实现具有竞争力的性能,进一步验证了 ConvNeXt 设计的有效性。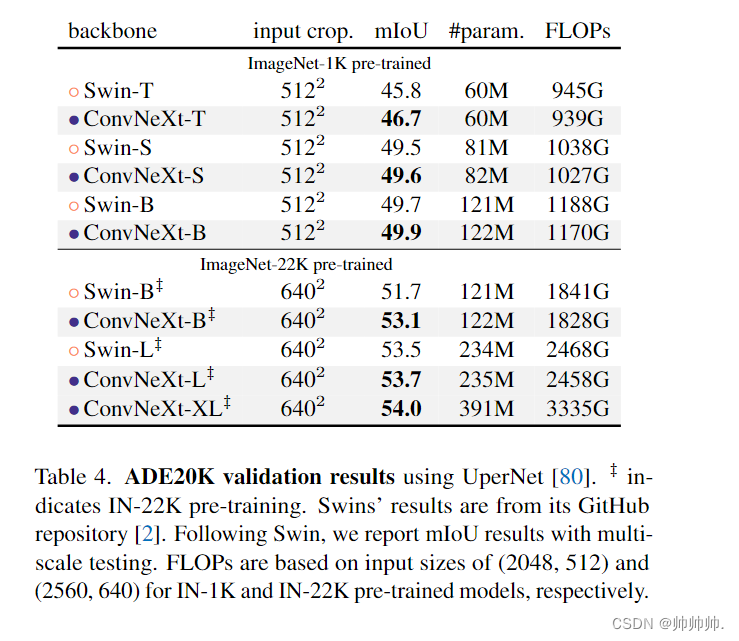
Remarks on model efficiency.
相似的FLOPs下,深度卷积模型比只有密集卷积模型更慢和消耗更多的内存。训练ConvNeXts比训练Swin transformer需要更少的内存。值得注意的是,这种效率的提高是ConvNet归纳偏差的结果,和ViT的自注意力机制没有直接关系。
5、Related Work
在前和后vit时代,将卷积和自注意力相结合的混合模型得到了积极的研究。在最近基于卷积网络的研究方法也出现了很多,但是本篇论文主要的研究目的是深入研究现代化ResNet和实现最优性能。
6、Conclusion
作者提出了ConvNeXt,一种纯粹的卷积神经网络模型。可以在多个计算机视觉基准上和目前最先进的ViT竞争,同时保留了CNN的简单和高效性。在最后,作者希望研究中的结果可以改变广泛存在的一些观点,并且呼吁人们重新思考在计算机视觉中卷积的重要性!
参考以下文章:
1.https://www.aminer.cn/research_report/628aeb017cb68b460fbf4f30
2.https://mp.weixin.qq.com/s/gWfgt-mMAjhBh3tUc3HzqA