Yolov5核心基础知识
1 前言
相对于YOLOv4,YOLOv5在原理和方法上没有做太多的改进,但是在速度和模型大小比yolov4有比较大的提升,也可以认为是牺牲了模型的大小,换来了准确率和速度的增加。接下来,从yolov5的网络结构,以及核心内容进行分析。
2 网络结构
yolov5一共有4个版本,比如yolov5x,yolov5s,yolov5m,yolov5l,这四个模型,本文对yolov5s模型进行简单分析。四个模型之中,yolov5s深度最小,特征图的宽度也是最小。但是,他们的整体架构是一样的,只不过就是在每个子模块中采用不同的深度和宽度,分别对应yaml文件中的depth_multiple和width_multiple参数。
yolov5的网络结构图,如下所示:
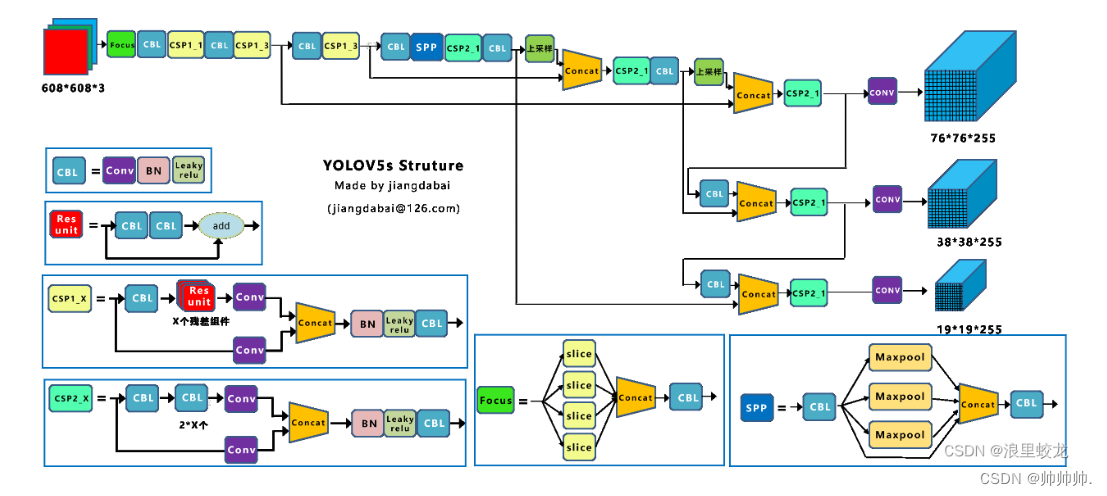
yolov5的网络结构主要有3部分组成:
- backbone: New CSP-Darknet53
- Neck: SPPF,New CSP-PAN
- Head: yolov3 Head
其实YOLOv5在Backbone部分没太大变化,仅仅是在v6.0之后有一个小改动,把第一层的Focus模块换成了一个6×6的卷积层。其实效果是一样的,但是对于现在的一些GPU设备和优化算法,6×6的卷积层效果要更好一点。
在neck部分变化相当较大,把原来的SPP模块换成了SPPF模块,两者作用一样,但是SPPF效率更高。SPP结构如下所示,将输入以并行的方式通过不同大小的MaxPool层,然后进行Concat,能在一定程度上解决目标多尺度问题。
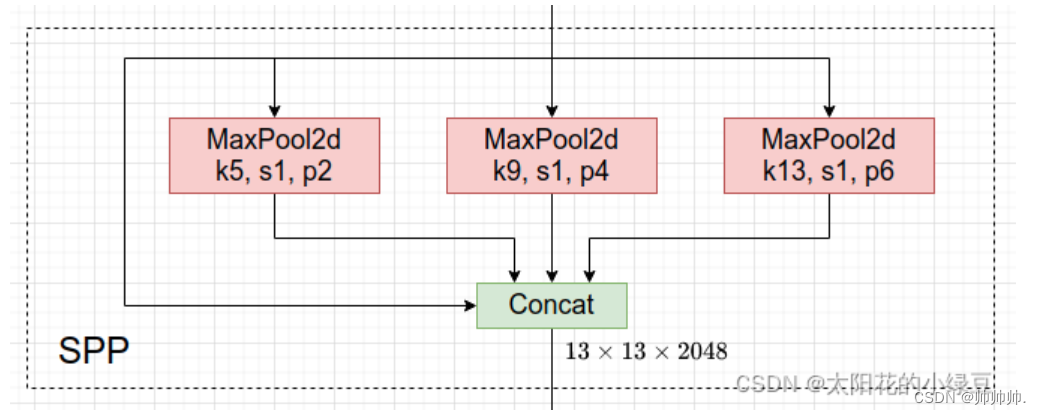
然而,SPPF的结构是串行的将输入通过多个5×5大小的MaxPool层(串行两个5×5的MaxPool层结果和一个9×9大小的MaxPool层计算结果一样),串行三个5×5的MaxPool层和13×13的一样。
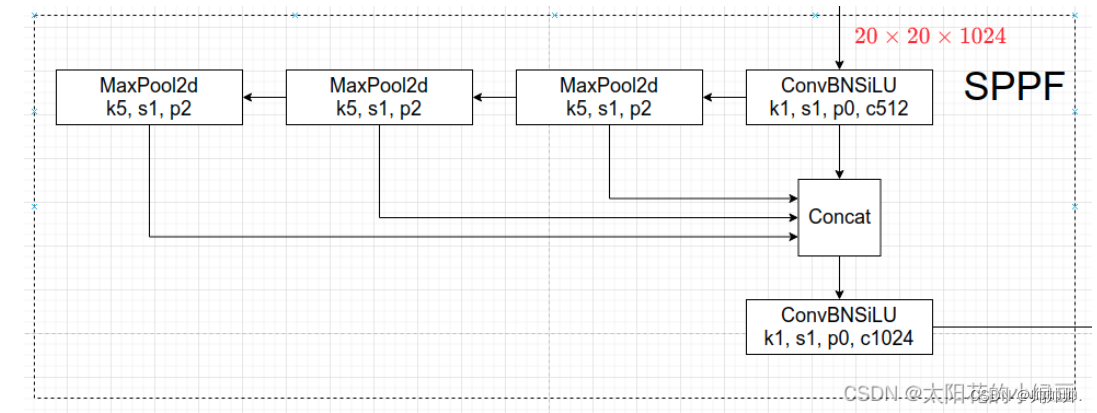
因此,SPP和SPPF的计算结果一样,但是SPPF比SPP计算速度快了将近两倍。因为,三个5×5的MaxPool层计算量明显小于一个5×5和9×9和13×13的计算量。第二个改动之处引入了New CSP-PAN,就是在在PAN结构中加入了CSP。在head部分并没有什么改动。
下面是一张yolov5的算法性能测试图:
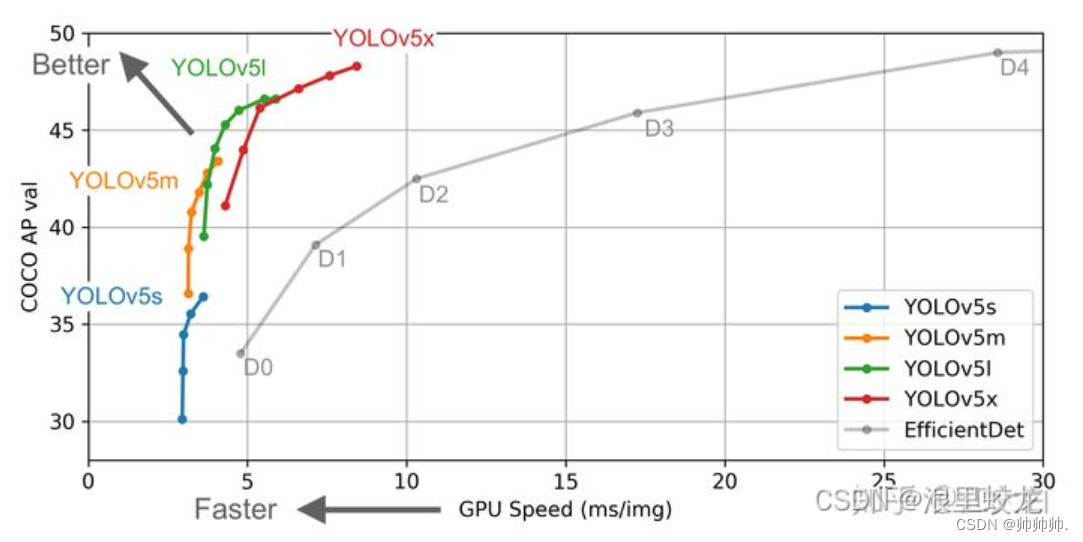
YOLOv5s网络最小,速度最快,AP精度也最低。若检测的以大目标为主,追求速度,是个不错的选择。其他的三种网络,在YOLOv5基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
3 核心基础知识
3.1 Mosaic数据增强
YOLOv5中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果是不错的。

Mosaic数据增强的方式,主要有几个优点:
- 丰富数据集: 随机使用4张图片,随机缩放,再随机分布进行拼接,丰富了检测数据集,尤其是随机缩放增加了小目标,让网络的鲁棒性更好。
- 减少GPU: 可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
3.2 自适应锚框计算
在yolo中**,不同的数据集,都会设置不同初始长宽的锚框**。然后,在网络训练中,网络在初始锚框的基础上输出预测框,预测框和真实框groundtruth进行对比,计算他们的差距,然后反向更新,迭代网络参数,因此初始锚框长款还是很重要的。
在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但YOLOv5中将此功能嵌入到代码中,每次训练将会自适应的计算不同训练集中的最佳锚框值。如果觉得计算的锚框效果不好,可以将自动计算锚框功能关闭。
3.3 自适应图片缩放
在目标检测中,不同的图片尺寸不同。因此需要把所有图片变成尺寸一样,常用的就是进行直接缩放到需要的尺寸大小。但是在yolov5中作者用了一个新trick,因此yolov5的推理速度更快了。在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同。填充的比较多,则存在信息冗余,影响推理速度。 因此在YOLOv5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。

3.4 cost function
目标检测任务的损失函数一般由 Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。
IOU_Loss: 主要考虑检测框和目标框重叠面积。
GIOU_Loss: 在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss: 在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss: 在DIOU的基础上,考虑边界框宽高比的尺度信息。
Summary
总的来说,yolov4的性能是优于yolov5的,但是在灵活性与速度上弱于YOLO V5。
尽管YOLO V5目前仍然计逊一筹,但是YOLO V5仍然具有以下显著的优点:
- 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLOV4采用的Darknet框架,Pytorch框架更容易投入生产。
- 代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴。
- 不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果。
- 能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理。
- 能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端。
- 最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒。