我这主要是江大白老师的内容!!
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解(CSDN)
深入浅出Yolo系列之Yolov5核心基础知识完整讲解(知乎)
目录
0、基础概念
目标检测算法常见标识物体位置的框:
- 边界框(bounding box)用于标识物体的位置,可以是真实框也可以是预测框,它指目标物体的最小外边界框。常用格式有左上右下坐标,即xyxy;中心宽高,即xywh。
- 真实框(Ground truth box) 是人工标注的位置,存放在标注文件中
- 预测框(Prediction box) 是由目标检测模型计算输出的框
- 锚框(Anchor box)用于预测框计算做参考;基于这个参考,算法生成的预测框仅需要在这个锚框的基础上进行“精修或微调fine-tuning”即可。
1、Yolov5四种网络
YOLOv5官方代码中,给出的目标检测网络中一共有4个版本,分别是YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个模型。
YOLOv5s整体的网络结构图

本文以YOLOv5s的网络结构为主线,讲解与其他三个模型(YOLOv5m、YOLOv5l、YOLOv5x)的不同点。
YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。
2、核心基础内容
2.1 YOLOv5核心基础内容

上图即YOLOv5的网络结构图,可以看出其分为输入端、Backbone、Neck、Prediction四个部分。
Backbone:主干网络,其大多时候指的是提取特征的网络。主干网络的作用就是提取图片中的信息,供后面的网络使用。经常使用的网络是resnet、VGG等(非自己设计),这些网络在分类等问题上的特征提取能力很强。
neck:其作用是更好地融合/提取backbone给出的feature,从而提高网络的性能。
基本组件:
CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
其他基础操作:
Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。
add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。
YOLO5作者的算法性能测试图:

YOLOv5s网络最小,速度最快,AP精度也最低。若检测的以大目标为主,追求速度,是个不错的选择。其他的三种网络,在YOLOv5基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
2.2 Yolov5核心基础内容
2.2.1 输入端
(1)Mosaic数据增强
YOLOv5中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果是不错的。

在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而COCO数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。
小、中、大目标的定义:2019年发布的论文《Augmentation for small object detection》对此进行了区分:
小目标的定义是目标框的长宽0×0~32×32之间的物体。

但在整体的数据集中,小、中、大目标的占比并不均衡。如上表所示,COCO数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。因此,YOLOv5的作者采用了Mosaic数据增强的方式。
主要有几个优点:
-
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,丰富了检测数据集,尤其是随机缩放增加了小目标,让网络的鲁棒性更好。
-
减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
Mini-batch:梯度下降需要对所有样本进行处理过后然后走一步,如果样本规模大会导致效率低,这种梯度下降叫full batch。 为了提高效率,将样本分成等量子集, 这些子集就称为mini batch。假如我们用for循环遍历1000个子集, 针对子集做一次梯度下降,然后更新参数w和b的值。接着到下一个子集继续梯度下降。 遍历完所有的mini batch之后相当于在梯度下降中做了1000次迭代,将遍历一次所有样本的行为叫做一个 epoch。在Mini-batch下的梯度下降中做的事情跟full batch一样,只不过我们训练的数据是一个个的子集。 这样在一个epoch中就能进行1000次的梯度下降(走的步数多),而在full batch中只有一次,这提高了算法的运行速度。
(2) 自适应锚框计算
在YOLO算法中,针对不同的数据集,都会有初始设定长宽的锚框。在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数,因此初始锚框是比较重要的一部分。
在YOLOv3、YOLOv4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但YOLOv5中将此功能嵌入到代码中,每次训练将会自适应的计算不同训练集中的最佳锚框值。如果觉得计算的锚框效果不好,可以将自动计算锚框功能关闭。具体操作为train.py中下面一行代码,设置成False。
![]()
(3)自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。YOLO算法中常用416*416,608*608等尺寸,比如对下面800*600的图像进行缩放。
但YOLOv5代码中对此进行了改进,也是使得YOLOv5推理速度更快的一个trick。在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同。填充的比较多,则存在信息冗余,影响推理速度。因此在YOLOv5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
图像高度上两端的黑边变少,在推理时计算量也会减少,即目标检测速度会得到提升。
第一步:计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
第二步:计算缩放后的尺寸

原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
第三步:计算黑边填充数值

将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
注意:填充的是黑色,即(0,0,0),而YOLOv5中填充的是灰色,即(114,114,114),效果相同;训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,采用缩减黑边的方式,提高目标检测,推理的速度;为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,以免产生尺度太小走不完stride(filter在原图上扫描时,需要跳跃的格数)的问题,再进行取余。
2.2.2 Backbone
(1)Focus结构

Focus结构比较关键是切片操作。比如右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。以YOLOv5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
注意:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加。
(2)CSP结构
YOLOv5设计了两种CSP结构,以YOLOv5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构应用于Neck中。
每个CSP模块前面的卷积核的大小都是3*3,stride=2,因此可以起到下采样的作用。CSP借鉴CSPNet,其全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
2.2.3 Neck
如今YOLOv5的Neck采用FPN+PAN的结构。
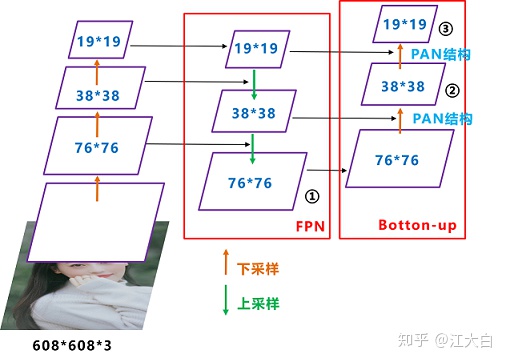
PAN是借鉴图像分割领域PANet的创新点。

可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76*76、38*38、19*19。
以及最后的Prediction中用于预测的三个特征图①19*19*255、②38*38*255、③76*76*255。[注:255表示80类别(1+4+80)×3=255]
我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。
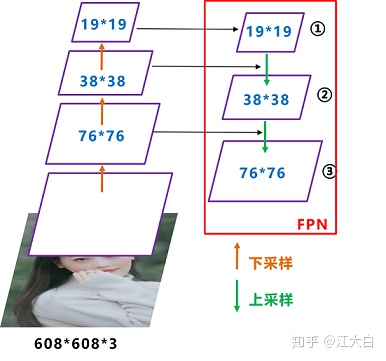
如图所示,FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。
而YOLOv4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:

每个CSP模块前面的卷积核都是3*3大小,步长为2,相当于下采样操作。因此可以看到三个紫色箭头处的特征图是76*76、38*38、19*19。以及最后Prediction中用于预测的三个特征图:①76*76*255,②38*38*255,③19*19*255。我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。

和YOLOv3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。
其中包含两个PAN结构。这样结合操作,FPN层自顶向下传达强语义特征(高层语义是经过特征提取后得到的特征信息,它的感受野较大,提取的特征抽象,有利于物体的分类,但会丢失细节信息,不利于精确分割。高层语义特征是抽象的特征。),而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
注意一:
Yolov3的FPN层输出的三个大小不一的特征图①②③直接进行预测
但Yolov4的FPN层,只使用最后的一个76*76特征图①,而经过两次PAN结构,输出预测的特征图②和③。
注意点二:
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat(route)操作,特征图融合后的尺寸发生了变化。

4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:
前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是3*3大小,步长为2,相当于下采样操作。
因此可以看到三个紫色箭头处的特征图是76*76、38*38、19*19。
以及最后Prediction中用于预测的三个特征图:①76*76*255,②38*38*255,③19*19*255。
我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。

和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。
其中包含两个PAN结构。
这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
YOLOv4的Neck结构中,采用的都是普通的卷积操作。而YOLOv5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
2.2.4 输出端
(1)Bounding box损失函数
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
a.IOU_Loss

可以看到IOU的loss主要是交集/并集,但存在两个问题。

问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
b.GIOU_Loss

可以看到右图GIOU_Loss中,增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时的尴尬。但依旧存在不足:

问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
c.DIOU_Loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,作者从两个方面进行考虑
如何最小化预测框和目标框之间的归一化距离?如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,提出了DIOU_Loss(Distance_IOU_Loss)
DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。但其没有考虑到长宽比。
比如上面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。针对这个问题,又提出了CIOU_Loss。
d.CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。其中v是衡量长宽比一致性的参数。

这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。
(2)nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。因为CIOU_Loss中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。所以Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中采用加权nms的方式。可以看出,采用DIOU_nms,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。

项目中采用DIOU_nms的方式,在同样的参数情况下,将nms中IOU修改成DIOU_nms。对于一些遮挡重叠的目标,确实会有一些改进。
3、小目标分割检测
目标检测发展很快,但对于小目标的检测还是有一定的瓶颈,特别是大分辨率图像小目标检测。比如7920*2160,甚至16000*16000的图像。图像的分辨率很大,但又有很多小的目标需要检测。但是如果直接输入检测网络,比如yolov3,检出效果并不好。
主要原因是:
(1)小目标尺寸
以网络的输入608*608为例,yolov3、yolov4,yolov5中下采样都使用了5次,因此最后的特征图大小是19*19,38*38,76*76。
三个特征图中,最大的76*76负责检测小目标,而对应到608*608上,每格特征图的感受野是608/76=8*8大小。

再将608*608对应到7680*2160上,以最长边7680为例,7680/608*8=101。即如果原始图像中目标的宽或高小于101像素,网络很难学习到目标的特征信息。(PS:这里忽略多尺度训练的因素及增加网络检测分支的情况)
(2)高分辨率
而在很多遥感图像中,长宽比的分辨率比7680*2160更大,比如上面的16000*16000,如果采用直接输入原图的方式,很多小目标都无法检测出。
(3)显卡爆炸
很多图像分辨率很大,如果简单的进行下采样,下采样的倍数太大,容易丢失数据信息。但是倍数太小,网络前向传播需要在内存中保存大量的特征图,极大耗尽GPU资源,很容易发生显存爆炸,无法正常的训练及推理。因此可以借鉴2018年YOLT算法的方式,改变一下思维,对大分辨率图片先进行分割,变成一张张小图,再进行检测。
需要注意的是:为了避免两张小图之间,一些目标正好被分割截断,所以两个小图之间设置overlap重叠区域,比如分割的小图是960*960像素大小,则overlap可以设置为960*20%=192像素。

每个小图检测完成后,再将所有的框放到大图上,对大图整体做一次nms操作,将重叠区域的很多重复框去除。这样操作,可以将很多小目标检出,比如16000*16000像素的遥感图像。
优点:
(1)准确性
分割后的小图,再输入目标检测网络中,对于最小目标像素的下限会大大降低。
(2)检测方式
在大分辨率图像,比如遥感图像,或者无人机图像,如果无需考虑实时性的检测,且对小目标检测也有需求的项目,可以尝试此种方式。
缺点:
(1)增加计算量
比如原本7680*2160的图像,如果使用直接大图检测的方式,一次即可检测完。但采用分割的方式,切分成N张608*608大小的图像,再进行N次检测,会大大增加检测时间。
4、参考文章
深入浅出Yolo系列之Yolov5核心基础知识完整讲解 - 知乎 (zhihu.com)
backbone、head、neck等深度学习中的术语解释 - 知乎 (zhihu.com)
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解 - 知乎 (zhihu.com)
mini batch详解小镇大爱的博客-CSDN博客minibatch什么意思
【什么是epoch、batch、batchsize、iteration?什么是真实框、预测框和锚框】_王挣银的博客-CSDN博客_batchsize是什么