定义目标函数
定义参数空间
定义优化目标函数
定义验证函数(可选)
执行实际优化流程
#基本工具
import numpy as np
import pandas as pd
import time
import os #修改环境设置
#算法/ 损失/ 评估指标等
import sklearn
from sklearn. ensemble import RandomForestRegressor as RFR
from sklearn. model_selection import KFold, cross_validate
#优化器
from bayes_opt import BayesianOptimization
data = pd. read_csv ( r"C:\work-file\pythonProject\Demo练习\贝叶斯优化\train_encode.csv" , index_col= 0 )
X = data. iloc[ : , : - 1 ]
y = data. iloc[ : , - 1 ]
from bayes_opt import BayesianOptimization
def bayesopt_objective ( n_estimators, max_depth, max_features, min_impurity_decrease) :
#定义评估器
#需要调整的超参数等于目标函数的输入,不需要调整的超参数则直接等于固定值
#默认参数输入一定是浮点数,因此需要套上int函数处理成整数
reg = RFR ( n_estimators = int ( n_estimators)
, max_depth = int ( max_depth)
, max_features = int ( max_features)
, min_impurity_decrease = min_impurity_decrease
, random_state= 1412
, verbose= False #可自行决定是否开启森林建树的verbose
, n_jobs= - 1 )
#定义损失的输出,5 折交叉验证下的结果,输出负根均方误差(- RMSE )
#注意,交叉验证需要使用数据,但我们不能让数据X , y成为目标函数的输入
cv = KFold ( n_splits= 5 , shuffle= True, random_state= 1412 )
validation_loss = cross_validate ( reg, X , y
, scoring= "neg_root_mean_squared_error"
, cv= cv
, verbose= False
, n_jobs= - 1
, error_score= 'raise'
#如果交叉验证中的算法执行报错,则告诉我们错误的理由
)
#交叉验证输出的评估指标是负根均方误差,因此本来就是负的损失
#目标函数可直接输出该损失的均值
return np. mean ( validation_loss[ "test_score" ] )
param_grid_simple = {
'n_estimators' : ( 80 , 100 )
, 'max_depth' : ( 10 , 25 )
, "max_features" : ( 10 , 20 )
, "min_impurity_decrease" : ( 0 , 1 )
}
def param_bayes_opt ( init_points, n_iter) :
#定义优化器,先实例化优化器
opt = BayesianOptimization ( bayesopt_objective #需要优化的目标函数
, param_grid_simple #备选参数空间
, random_state= 1412 #随机数种子,虽然无法控制住
)
#使用优化器,记住bayes_opt只支持最大化
opt. maximize ( init_points = init_points #抽取多少个初始观测值
, n_iter= n_iter #一共观测/ 迭代多少次
)
#优化完成,取出最佳参数与最佳分数
params_best = opt. max[ "params" ]
score_best = opt. max[ "target" ]
#打印最佳参数与最佳分数
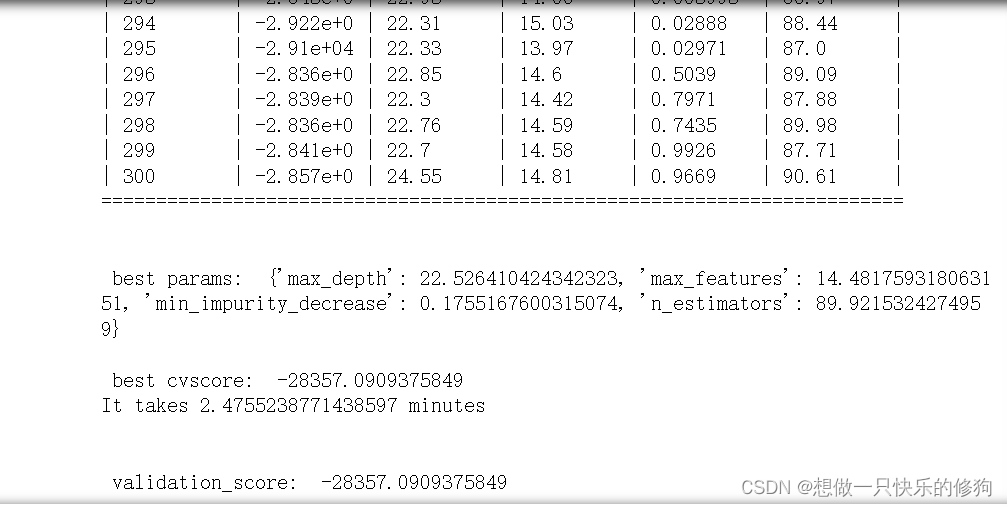
print ( "\n" , "\n" , "best params: " , params_best,
"\n" , "\n" , "best cvscore: " , score_best)
#返回最佳参数与最佳分数
return params_best, score_best
def bayes_opt_validation ( params_best) :
reg = RFR ( n_estimators = int ( params_best[ "n_estimators" ] )
, max_depth = int ( params_best[ "max_depth" ] )
, max_features = int ( params_best[ "max_features" ] )
, min_impurity_decrease = params_best[ "min_impurity_decrease" ]
, random_state= 1412
, verbose= False
, n_jobs= - 1 )
cv = KFold ( n_splits= 5 , shuffle= True, random_state= 1412 )
validation_loss = cross_validate ( reg, X , y
, scoring= "neg_root_mean_squared_error"
, cv= cv
, verbose= False
, n_jobs= - 1
)
return np. mean ( validation_loss[ "test_score" ] )
start = time. time ( )
params_best, score_best = param_bayes_opt ( 20 , 280 ) #初始看20 个观测值,后面迭代280 次
print ( 'It takes %s minutes' % ( ( time. time ( ) - start) / 60 ) )
validation_score = bayes_opt_validation ( params_best)
print ( "\n" , "\n" , "validation_score: " , validation_score)
因为这个库无法通过随机数种子来保证每次输出的结果一样,所以不同人复现的结果可能不同。