一、事务(transaction)
MySQL 事务主要用于处理操作量大,复杂度高的数据。如,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
(1)在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务
(2)事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行
(3)事务用来管理DML语句(insert,update,delete)
本质:一个事务其实就是多条DML语句同时执行成功,或者同时执行失败!
(一)事务4大特性
一般来说,事务是必须满足4个条件(ACID):原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)
原子性(Atomicity):事务的不可分割,组成事务的各个逻辑单元不可分割
一致性(Consistency):事务执行的前后,数据完整性保持一致
隔离性(Isolation):事务执行不应该受到其他事务的干扰
持久性(Durability):事务一旦结束,数据就持久化到数据库中
【1】原子性(Atomicity):一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样
【2】一致性(Consistency):在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
【3】隔离性(Isolation):数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
【4】持久性(Durability):事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作
因此要显式地开启一个事务务须使用命令
BEGIN 或 START TRANSACTION,或者执行命令 SET AUTOCOMMIT=0
BEGIN
或
START TRANSACTION
或者执行命令
SET AUTOCOMMIT=0用来禁止使用当前会话的自动提交
1、事务控制语句
InnoDB存储引擎:提供一组用来记录事务性活动的日志文件
在事务的执行过程中,每一条DML的操作都会记录到“事务性活动的日志文件”中
(1)开始事务
BEGIN 或 START TRANSACTION 显式地开启一个事务;
(2)提交事务
COMMIT 也可以使用 COMMIT WORK,不过二者是等价的。COMMIT 会提交事务,并使已对数据库进行的所有修改成为永久性的
提交事务会清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中。
提交事务标志着,事务的结束;并且是一种全部成功的结束
mysql> select * from user;
Empty set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into user values(1,'admin');
Query OK, 1 row affected (0.00 sec)
mysql> select * from user;
+----+-------+
| id | name |
+----+-------+
| 1 | admin |
+----+-------+
1 row in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from user;
+----+-------+
| id | name |
+----+-------+
| 1 | admin |
+----+-------+
1 row in set (0.00 sec)(3)回滚事务(回滚永远都是只能回滚到上一次的提交点)
ROLLBACK 也可以使用 ROLLBACK WORK,不过二者是等价的。回滚会结束用户的事务,并撤销正在进行的所有未提交的修改
回滚事务将之前所有的DML操作全部撤销,并且清空事务性活动的日志文件
回滚事务标志着,事务的结束。并且是一种全部失败的结束(回滚到上一次提交事务的地方)
mysql> select * from user;
Empty set (0.00 sec)
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into user values(1,'admin');
Query OK, 1 row affected (0.00 sec)
mysql> select * from user;
+----+-------+
| id | name |
+----+-------+
| 1 | admin |
+----+-------+
1 row in set (0.00 sec)
mysql> rollback;
Query OK, 0 rows affected (0.01 sec)
mysql> select * from user;
Empty set (0.00 sec)SAVEPOINT identifier,SAVEPOINT 允许在事务中创建一个保存点,一个事务中可以有多个 SAVEPOINT;
RELEASE SAVEPOINT identifier 删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier 把事务回滚到标记点;
SET TRANSACTION 用来设置事务的隔离级别。InnoDB 存储引擎提供事务的隔离级别有READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ 和 SERIALIZABLE。
2、MYSQL 事务处理主要有两种方法:
(1)用 BEGIN, ROLLBACK, COMMIT来实现
BEGIN 开始一个事务
ROLLBACK 事务回滚
COMMIT 事务确认
(2)直接用 SET 来改变 MySQL 的自动提交模式:
SET AUTOCOMMIT=0 禁止自动提交
SET AUTOCOMMIT=1 开启自动提交
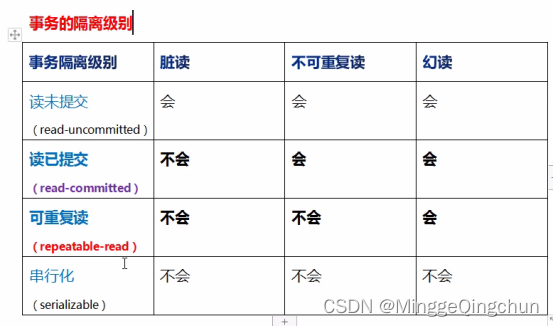
3、事务的隔离性(事务的隔离级别)
(二)事务4大隔离级别
4种事务隔离级别
1、read uncommitted (读取未提交内容) :脏读,不可重复读,幻读都有可能发生
2、read committed (读取提交内容) :避免脏读。但是不可重复读和幻读是有可能发生
3、repeatable read (可重读) :避免脏读和不可重复读,但是幻读有可能发生
4、serializable(可串行化) :避免脏读,不可重复读,幻读
3种读取异常情况
1、脏读:一个事务读到了另一个事务未提交的数据,导致查询结果不一致
2、不可重复读:一个事务读到了另一个事务已经提交的update的数据,导致多次查询结果不一致
3、幻读/虚读:一个事务读到了另一个事务已经提交的 insert/delete 的数据,导致多次查询结果不一致
不可重复读侧重于修改update 某一行记录,幻读侧重于新增或删除insert/delete 表中记录行
解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
事务和事务之间的隔离级别有4个
(1)读未提交:read uncommitted(最低的隔离级别,没有提交事务就读到)
事务A可以读取到事务B未提交的数据。
这种隔离级别存在的问题就是:
脏读现象!(Dirty Read);我们称读到了脏数据
这种隔离级别一般都是理论上的,大多数的数据库隔离级别都是二档起步!
(2)读已提交:read committed(提交之后才能读到)
事务A只能读取到事务B提交之后的数据
这种隔离级别,解决了脏读的现象
这种隔离级别不可重复读取数据
在事务开启之后,第一次读到的数据是3条,当前事务还没有结束,可能第二次再读取的时候,读到的数据是4条
这种隔离级别是比较真实的数据,每一次读到的数据是绝对的真实
oracle数据库默认的隔离级别是:read committed
(3)可重复读:repeatable read(提交之后也读不到,永远读取的都是刚开启事务时的数据)
事务A开启之后,不管是多久,每一次在事务A中读取到的数据都是一致的。即使事务B将数据已经修改,并且提交了,事务A读取到的数据还是没有发生改变,这就是可重复读
可重复读解决了不可重复读取数据
可重复读会出现幻影读。每一次读取到的数据都是幻象。不够真实!
mysql中默认的事务隔离级别就是 可重复读 repeatable read
(4)序列化/串行化:serializable(最高的隔离级别)
这是最高隔离级别,效率最低。解决了所有的问题
这种隔离级别表示事务排队,不能并发!类似synchronized,线程同步(事务同步)
每一次读取到的数据都是最真实的,并且效率是最低的
事务的隔离级别测试
查看会话级的当前隔离级别
mysql> SELECT @@tx_isolation;
或:
mysql> SELECT @@session.tx_isolation;查看全局级的当前隔离级别
mysql> SELECT @@global.tx_isolation;MySQL中默认的隔离级别 REPEATABLE-READ
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
mysql> select @@session.tx_isolation;
+------------------------+
| @@session.tx_isolation |
+------------------------+
| REPEATABLE-READ |
+------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set, 1 warning (0.00 sec)修改事务隔离级别
set global transaction isolation level 隔离级别;
如:
set global transaction isolation level read uncommitted;以user表举例,都是同时打开两个DOS命令窗口;
每次修改隔离级别之后exit退出MySQL再重新进入
(1)read uncommitted 读未提交
验证:read uncommited
mysql> set global transaction isolation level read uncommitted;
事务A 事务B
-----------------------------------------------------------
use mydb;
use mydb;
start transaction;
select * from user;
start transaction;
insert into user values('admin');
select * from user;
//此时事务B没有提交,查询事务A中就已经有数据
(2)read committed 读已提交
验证:read committed
mysql> set global transaction isolation level read committed;
事务A 事务B
-------------------------------------------------------
use mydb;
use mydb;
start transaction;
start transaction;
select * from user;
insert into user values('admin');
select * from user;
commit;
select * from user;
//事务B提交之后,查询事务A中才有数据
(3)repeatable read 可重复读
验证:repeatable read
mysql> set global transaction isolation level repeatable read;
事务A 事务B
--------------------------------------------------------------------------------
use mydb;
use mydb;
start transaction;
start transaction;
//假设此时事务A中只有一条数据
select * from user;
insert into user values('admin');
commit;
select * from user;
//事务B中插入很多条数据,或者删除数据
select * from user;
//事务A中查看依然只有一条数据事务A在事务B中操作数据之前查询只有一条数据,之后不管事务B中insert 还是 delete ,进行commit 提交之后,查看事务A 中永远都是一条数据

(4)serializable 序列化/串行化
验证:serializable
mysql> set global transaction isolation level serializable;
事务A 事务B
----------------------------------------------------
use mydb;
use mydb;
start transaction;
start transaction;
select * from user;
insert into user values('admin');
select * from t_user;
//此时光标一直停留在此处,等待事务A的结束
commit;
//如果此时事务A提交了, 则事务B立马返回查询结果
此时事务B中的DOS窗口光标一直停留在此处,等待事务A的结束

如果此时事务A提交了,则事务B立马返回查询结果

(三)事务的7大传播行为
1、PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置
2、PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作
3、PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行
4、PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常
5、PROPAGATION_REQUIRES_NEW:支持当前事务,创建新事务,无论当前存不存在事务,都创建新事务
6、PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起
7、PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常
二、存储引擎
1、存储引擎
存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以 获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。
存储引擎是MySQL中特有的一个术语,其它数据库中没有。(Oracle中有,但是不叫这个名字)
2、查看存储引擎命令
show engines \G输出九种引擎
mysql> show engines \G;
*************************** 1. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
*************************** 2. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 3. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 4. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 6. row ***************************
Engine: CSV
Support: YES
Comment: CSV storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 7. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 8. row ***************************
Engine: PERFORMANCE_SCHEMA
Support: YES
Comment: Performance Schema
Transactions: NO
XA: NO
Savepoints: NO
*************************** 9. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
9 rows in set (0.00 sec)mysql版本不同支持情况不同;支持九大存储引擎,5.5.36支持8个
3、建表指定引擎
//建表时指定存储引擎,以及字符编码方式。
create table table表名(
id int primary key,
name varchar(255)
)engine=InnoDB default charset=utf8;ENGINE来指定存储引擎
CHARSET来指定这张表的字符编码方式
mysql默认的存储引擎是:InnoDB
mysql默认的字符编码方式是:utf8
4、MySQL中常用引擎
(1)MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事务,不支持外键。
它管理的表具有以下特征:
使用三个文件表示每个表:
格式文件 — 存储表结构的定义(mytable.frm)
数据文件 — 存储表行的内容(mytable.MYD)
索引文件 — 存储表上索引(mytable.MYI):索引是一本书的目录,缩小扫描范围,提高查询效率的一种机制。
可被转换为压缩、只读表来节省空间
注:
对于一张表来说,只要是主键,或者加有unique约束的字段上会自动创建索引
MyISAM存储引擎特点:
【1】可被转换为压缩、只读表来节省空间
【2】MyISAM不支持事务机制,安全性低。
(2)InnoDB存储引擎
MySQL5.5以后默认使用InnoDB存储引擎
InnoDB支持事务,支持数据库崩溃后自动恢复机制
InnoDB存储引擎最主要的特点是:非常安全
它管理的表具有下列主要特征:
– 每个 InnoDB 表在数据库目录中以.frm 格式文件表示
– InnoDB 表空间 tablespace 被用于存储表的内容(表空间是一个逻辑名称。表空间存储数据+索引。)
– 提供一组用来记录事务性活动的日志文件
– 用 COMMIT(提交)、SAVEPOINT 及ROLLBACK(回滚)支持事务处理
– 提供全 ACID 兼容
– 在 MySQL 服务器崩溃后提供自动恢复
– 多版本(MVCC)和行级锁定
– 支持外键及引用的完整性,包括级联删除和更新
InnoDB最大的特点就是支持事务:
保证数据的安全。
效率不是很高,并且也不能压缩,不能转换为只读,不能很好的节省存储空间。
(3)MEMORY存储引擎
使用 MEMORY 存储引擎的表,其数据存储在内存中,且行的长度固定,
这两个特点使得 MEMORY 存储引擎非常快。
MEMORY 存储引擎管理的表具有下列特征:
– 在数据库目录内,每个表均以.frm 格式的文件表示。
– 表数据及索引被存储在内存中。(目的就是快,查询快!)
– 表级锁机制。
– 不能包含 TEXT 或 BLOB 字段。
MEMORY 存储引擎以前被称为HEAP 引擎。
MEMORY引擎优点:查询效率是最高的。不需要和硬盘交互。
MEMORY引擎缺点:不安全,关机之后数据消失。因为数据和索引都是在内存当中
内存直接取;光速、电流的速度;硬盘是机械行为,一帧一帧的读取数据
区别如下:
