这篇论文针对在有雾环境行驶的问题,提出了解决方案。
该方法是基于在中度不利条件(轻雾)下的语义分割结果可以自举来解决高度不利条件(浓雾)下的相同问题。CMAda可扩展到其他不利条件,并为使用合成数据和未标记的真实数据学习提供了一个新的范例。
此外,本文还提出了三个主要的独立贡献:
1)一种新的方法,使用语义输入将合成雾添加到真实的晴空场景;
2)一种新的雾密度估计器;
3)提出了一种新的雾增密方法,在实际雾景中对雾增密,但不确定雾深;
本篇论文主要分为两个部分,第一部分为对有雾天气的模拟,合成有雾的场景的图片;第二部分为利用监督学习方法,在浓雾下进行语义分割,这里的数据一部分为合成的有雾天气的数据,一部分为真实有雾天气的数据。
第一部分 对真实场景进行雾模拟
这部分分三个步骤:深度异常值检测,使用RANSAC 在SLIC超像素级别处的鲁棒深度平面拟合,以及使用引导图像滤波对完成的深度图进行后处理。

颜色和语义的双参考交叉双边滤波器
首先针对要合成的图像进行处理,这里并不是使用RGB,而是使用CIELAB色彩模式。
这里介绍一下SLIC算法:


SLIC 简单的线性迭代聚类,实现从颜色和空间两个角度对图像进行分析。

p,q均为像素位置,Gs空间高斯核,Gc颜色高斯核,t^()为一个投射函数,J 为CIELAB 模式函数,h():将像素映射至语义标签。
h(q)意味着只有像素q 与检查的像素具有相同的语义标签,才可以输出,可以防止语义边缘的模糊。同时,J()有助于更好地保留真实的深度边缘。当语义标签不同不同时,像素保存在颜色域中,通过颜色域滤波器实现滤波。
双边滤波器,是由两个独立网格构成,一个对应语义,一个对应颜色域,在每个网格单独执行滤波,最后将结果结合在一起构成这样一个双边滤波器。
基于光学模型模拟雾的环境

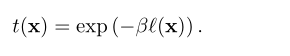
通过衰减系数β来控制雾的密度
进行雾模拟时,需要输入原始清晰场景的图像R、大气光L和完整的透射率图t。我们进行大气光估计,深度去噪和补全,利用推荐的参数,从一个有噪声且不完整的输入视差图D中得到一个初始的完整透射率图t^。我们使用双参考交叉双边滤波器对t^进行滤波,计算最终的透射率图t,该图在中用于合成雾天图像I。
(关于大气光估计,深度去噪,补全参考Semantic Foggy Scene Understanding with Synthetic Data 这篇文章)

第二部分 具有浓雾的场景的语义分割
CMAda构成了一个更加复杂的框架,因为它利用合成雾数据和真实雾数据来共同调整语义分割模型以适应浓雾,而[15]中的自适应方法仅使用真实数据进行自适应。此外,通过雾密度估计将真实雾图像分配到正确的目标雾域是CMAda的另一个重要且非平凡的组成部分,是该方法中使用这些真实图像作为训练数据的前提。

雾密度估计
首先,用深度平面拟合步骤的语义标注所产生的超像素代替SLIC超像素是不可行的,因为它会产生非常大的超像素,对于超像素的平面性假设完全被打破。
其次,我们尝试完全省略鲁棒深度平面拟合步骤,并将双参考交叉双边滤波器直接应用于离群点检测步骤输出的不完整深度图。然而,这种方法对未在前面步骤中检测到的异常值非常敏感。相比之下,这些剩余的异常值通过基于ransac的深度平面拟合成功地处理了
x 晴朗的图片 x‘ 轻雾合成图片 x’‘ 浓雾合成图片 y为注释
训练数据包括
![]() 轻雾合成图片与标签
轻雾合成图片与标签
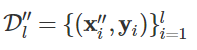 浓雾合成图片与标签
浓雾合成图片与标签
 无注释的真实轻雾图片
无注释的真实轻雾图片
主要为了学习得到一个映射函数![]() ,根据真实的浓雾图片进行评估此映射函数的准确性
,根据真实的浓雾图片进行评估此映射函数的准确性
由于真实的轻雾图片并没有注释,我们要先学习得到![]() 这个映射函数,通过轻雾合成图片与注释进行训练,之后我们可以得到标签
这个映射函数,通过轻雾合成图片与注释进行训练,之后我们可以得到标签![]()
![]()


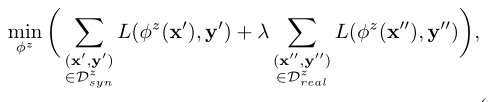
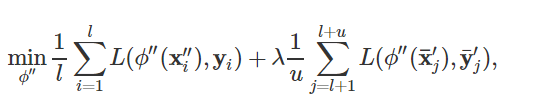
这里L 是交叉熵损失函数,![]() 这里是为了平衡两个数据集的权重常数。
这里是为了平衡两个数据集的权重常数。
将两个数据集通过min函数混合之后,放入CNN进行标准监督学习。
在CMAda方法中,存在一定缺点,由于雾密度的不同,导致寻求最优解受到阻碍,因此通过标准的光学函数估计真实的雾密度
最后得到这样一个光学方程式,可以发现我们可以绕过R真实清晰图像的影响

这里将雾浓度定义为

进而真实数据的表达式则变为

这篇论文到这里主要部分就结束了,剩下的就是他的实验结果

这个效果比较原有的方法还是有一定提高的。