-
Haar特征+Adaboost特征检测
理论已经说清楚了,下面给出一个基于OpenCV的实例用于石头的目标检测,实验结果表明检测精度还有待提高,可能是正负样本的选择上有所问题,但本文旨在提供学习方法,基本上目标检测的基本流程大致如此。使用Haar+Adaboost算法目标检测分为三个步骤[5]:
1、样本的创建和标记
2、训练分类器
3、利用训练好的分类器进行目标检测。
2.1 样本的创建和标记
自己做样本是一个非常痛苦和麻烦的事,最好还是去自己去网上找些公开的数据集,然而向岩石检测这种样本就比较少,所以我还是自己在网上收集了一些图片,包括126张正样本以及501张负样本。如图所示:


正样本

负样本
注意在做训练集的时候要把图片转换成灰度图像,并将其按顺序重命名。这里我用了OpenCV中的函数来实现上述功能:首先在文件夹中新建一个批处理脚本获取该文件夹中所有的图像名称,方法参考如何快速获取文件夹内所有文件名称列表。然后打开VS输入如下代码:
#include <stdio.h>
#include <string>
#include <iostream>
#include <sstream>
#include <opencv2/opencv.hpp>
#include <fstream>
using namespace std;
using namespace cv;
#define IMAGENUM 126
int main(int argc, char *argv[])
{
Mat src;
string ImgName;
char OutName[126]; //图像个数
ifstream fin("handsList.txt");
for (int framenum = 0; framenum < IMAGENUM&&getline(fin,ImgName);framenum+=1)
{
cout << "处理:" << ImgName << endl;
ImgName = "D:\\学习\\研究生相关\\智能喷浆台车\\image\\正样本\\修改后\\" + ImgName; //定义图像文件的绝对路径
src = imread(ImgName); //读取文件
sprintf(OutName, "D:\\学习\\研究生相关\\智能喷浆台车\\image\\正样本\\修改后\\bmp\\%d.bmp", framenum);
//cvtColor(src, src, CV_BGR2GRAY); //转换成灰度图像
//resize(src, src, Size(25, 50)); //重新定义图像尺寸
imwrite(OutName, src); //重新输出
}
}
其中handsList.txt为你存储的所有图像文件名的文件,放在项目文件夹下,由于里面只存储了文件的名称,你图像文件的绝对路径加到文件名之前就可以了,然后再将其转换成灰度图像再重命名输出就OK了。
得到了训练样本集之后,就可以对样本进行标记了。正样本,即包含检测对象的图片,使用图像标记工具,网上搜一下有很多的,格式就是,图片名+目标个数+目标的矩形框定位(左上角坐标和矩形长宽)。这里用的是objectmarker标记工具,下载地址见链接:https://pan.baidu.com/s/1V7Ly4qSvVg15RRfZUYeIKA 密码:7j48,至于软件的用法网上有介绍我就不再详细展开了。制作好的正样本情况记录是这样的:

2.2 训练分类器
已经把目标的情况记录了放在txt文件里,打开cmd窗口,输入createsamples.exe -info positive/info.txt -vec data/vector.vec -num 500 -w 24-h 24。当然你也可以使用.bat文件运行。这句话的-num后面的500表示正样本图片的数目,后面的-w和 -h说的是图片resize成的大小,根据实际情况修改。注意这是OpenCV2.x版本才有的内置程序,3.0及以上版本没有。其路径在:

运行完会生成vector.vec文件,这个就是向量描述文件了。你不用打开看它的内容,其实打开也没用,因为是乱码的,需要专门的软件。后面会用到。
做好这个其实就成功了一大半了,制作正样本很麻烦的。下面看看怎么制作负样本。很简单,准备图片(不包含岩石的图像)501张,多点也可以。
负样本的制作
然后在当前路径下在cmd窗口运行dir /b *.bmp >neg_name.txt就会生成一个neg_name.txt文件,里面包含当前路径下的所有bmp文件的文件名。也可以用批处理脚本实现,见下图:

好了,正负样本制作完成,可以开始训练了。我们使用opencv自带的opencv_haartraining.exe文件(opencv安装目录的bin目录下面有该文件)进行训练。
参数看起来很多,有点复杂。不用管它,网上查一下就明白了,很多参数都有默认值。我训练时的命令为opencv_haartraining.exe-data data/cascade -vec data/vector.vec -bg negative/neg_name.txt -npos 126-nneg 501 -nstages 20 -mem 4000 -w 24 -h 24
意思依次为可执行文件名,训练好的xml分类器文件保存地址,正样本描述文件vec文件,负样本的文件名,正负样本的数量,nstages为训练轮数,mem为分配内存MB,图像resize的大小。
训练截图
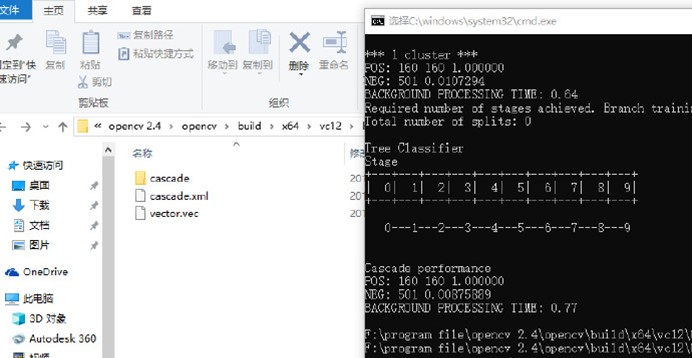
经过漫长的等待训练完成得到xml分类器文件,然后使用opencv的接口即可进行车辆检测了,我是使用detectMultiScale这个函数检测的,就跟人脸检测一样的,然后输出矩形框。我直接贴出检测部分的源代码,其他部分都是直接使用opencv自带的。其实这个也算~~
2.3 利用训练好的分类器进行目标检测
#include <stdio.h> #include <iostream> #include <opencv2/opencv.hpp> using namespace std; using namespace cv; int main() { string xmlPath = "cascade.xml";//训练好的分类器xml文件 CascadeClassifier ccf;//创建分类器对象 Mat img; if (!ccf.load(xmlPath)) { cout << "不能加载指定的xml文件" << endl; return 0; } namedWindow("rock"); bool stop = false; //获取检测图像 //img = imread("测试.jpg"); img = imread("7.bmp"); vector<Rect> rocks; // 创建一个容器保存检测出来的岩石 Mat gray; //转换成灰度图像,因为harr特征从灰度图像中提取 cvtColor(img, gray, CV_BGR2GRAY); ccf.detectMultiScale(gray, rocks, 1.1, 3, CASCADE_DO_CANNY_PRUNING, Size(50, 50), Size(1800, 1800));//检测岩石 for (auto &iter : rocks) { rectangle(img, iter, Scalar(0, 0, 255), 2, 8);//画出矩形 } //for (vector<Rect>::const_iterator iter = rocks.begin(); iter != rocks.end(); iter++) //{ // rectangle(img, *iter, Scalar(0, 0, 255), 2, 8);//画出矩形 //} imshow("rock", img); waitKey(0); return 0; }
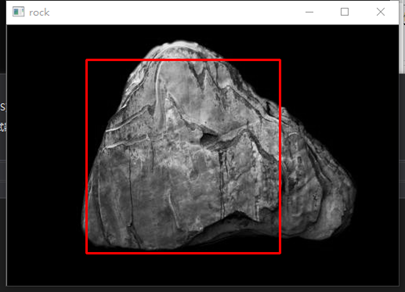
测试效果截图:可以看到对于简单场景的测试,检测效果很一般,对于复杂点的场景检测效果就更差了。这个时候或许要进一步研究学习上面提到的深度学习算法了。

[1] 机器学习之Haar特征
[2] Adaboost分类器 haar特征整理
[5] 目标检测之一(传统算法和深度学习的源码学习)