文章目录
一、背景
传统算法中 目标检测算法 都是基于 某种特征提取算法+分类器 来实现的。
不同种类的滤波器:
- 消除噪声、平滑图像的低通滤波器
- 提取边缘用的高通滤波器
其实,Filter还有一个重要的作用,就是检测 “特征”。之前用滤波器提取边缘,边缘就可以算是一种特征。提取特征时候,我们可以不用每次都处理稠密的图像(图像信息其实高度冗余),这样可以加快运算速度,减少内存消耗。常见的特征检测有:
- 边缘检测
- 模板匹配
- 关键点检测
模板匹配(template matching)
模板匹配的任务设定是,对于给定的模板,在一个图像中,找到和这个模板最相似的位置。
对于这个任务,最简单的就是将模板视为一个filter,然后利用 cross-correlation 来进行匹配,图像中响应函数最高的地方就是模板中内容出现的地方
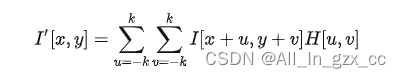
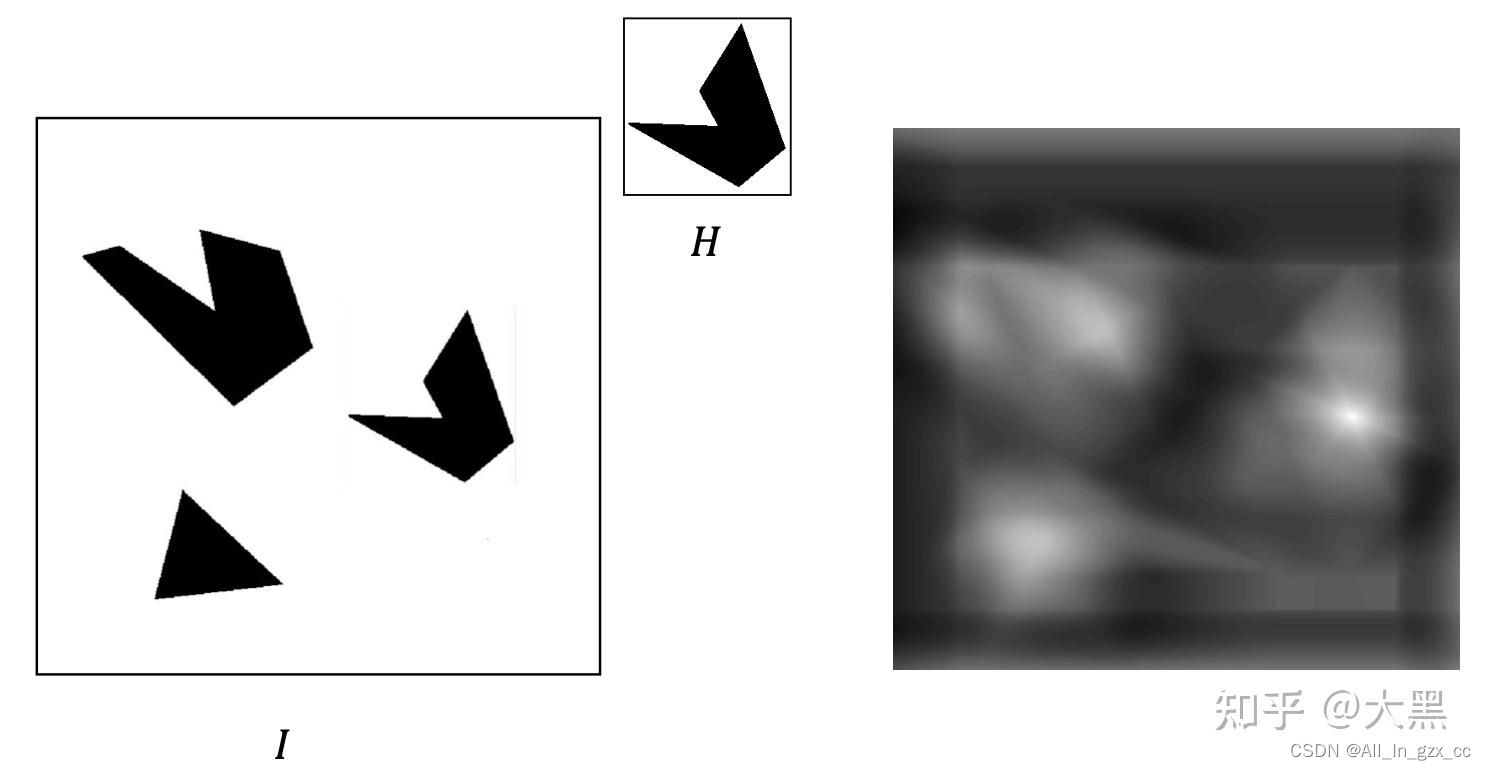
但是这个方法非常粗浅,它要求模板在目标图像中完全一致的出现,才会有最好的效果。对于 背景变化,光照变化,缩放,旋转,还有模板的外形变化非常敏感。比如说,我想要在照片中找一辆车,照片中的车是一个路上的奔驰,给的模板是一个4s店里面的宝马,那这个响应函数的效果可能就不是很好了。
关键点检测
关键点检测是很多视觉算法的最基础的步骤。我们希望找到一些点,使得他们在不同的图片中,有一些不变的特征保留,这样我们就可以在不同的图片中找到相同点对应的坐标。这样的点,我们一般成为关键点。所以关键点,最关键的一点就是可重复性,在不同的光照,角度,尺度,我都可以找得出。
关键点在很多图像处理任务中都有应用:
- 全景图片拼接
- 目标检测
- 三维重建
- Place recognition
- etc
这些任务的共同步骤都有,特征点提取,以及特征点匹配。
这个过程中,最关键的就是,找到可以重复的特征点,并且成功匹配。这就要求我们设计一种可重复性高的特征点检测器。并且,我们还要设计鲁棒性高的特征描述方法,让同一个特征点在不同的拍摄条件下,具有一些不变的特性,这样才能匹配成功。
我们先说关键点检测器,之后再说描述方法
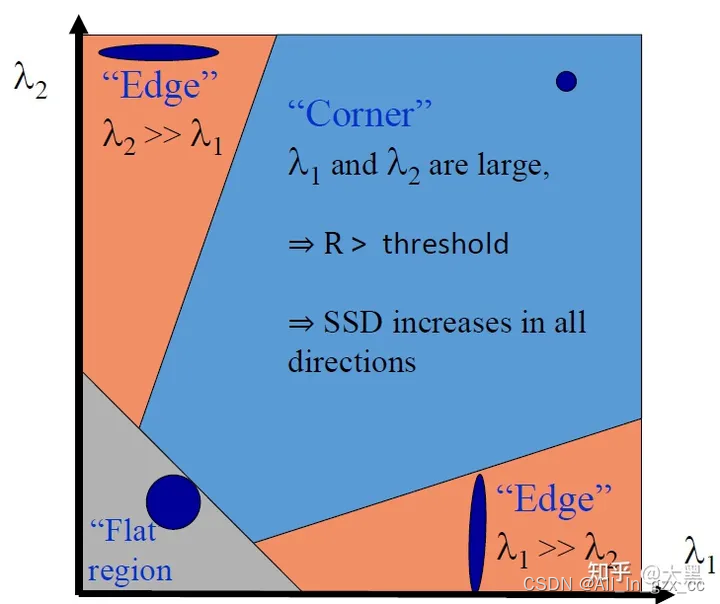
我们一直在说可重复性高的特征点,但是具体什么样的特征点可重复性高呢?
- 角点(Corners):角点的定义是多条边缘交汇的地方。
- 优点:定位的准确性高 → 更加适合VO
- 缺点:可辨识度更差一些举例:Harris, Shi-Tomasi, SUSAN, FAST
- Blobs:非角点的可辨识度高的样式,比如说多边形,圆等等)
- 优点:辨识度更高 → 更加适合 place recognition 这样的任务
- 缺点:位置准确性稍差举例:MSER, LOG, DOG(SIFT), SURF, CenSurE, etc
其中,关于角点检测 本文会针对于harris方法介绍一下。
角点检测
我们怎样定一个角点呢?如果我们利用一个window在图片上挑选出一定大小的patch。我们发现平缓的位置,边缘和角点各有不同的特征。
- 平缓的位置在
各个方向上移动的时候,灰度变化都不大 - 边缘在
沿着边缘移动时灰度变化不大,但是垂直的时候灰度变化大 - 角点区域在
朝任何方向移动的时候灰度变化都很大

二、harris特征提取原理
此为常用检测角点的 harr-like特征提取算法。其他各种复杂的(传统算法中)目标检测算法都是基于 某种特征提取+分类器来实现的。下一部分会具体介绍一种。
Harris 检测器的思想在于,不要真的在物理上移动这个patch,而是通过patch本身的微分来近似的找其各个方向上灰度的变化程度


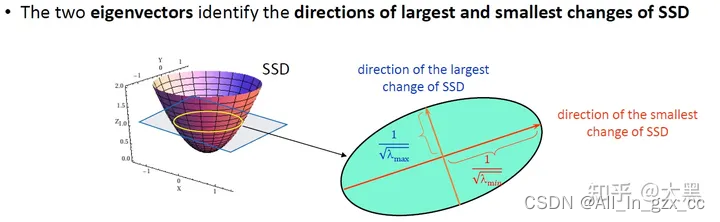
特征值越大的方向,灰度变化越剧烈。所以我们可以确定三种不同特征的特征值特点
- 角点:
λ1,λ2≫0 - 边缘:
λ1≫0, λ2≈0 - Flat:
λ1,λ2≈0
Harris Detector 提出于1988年,当时算力非常低,以至于特征值分解也属于要尽量避免的操作,所以当时提出了一个指标来判断一个像素是不是角点
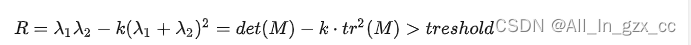
其中k是一个magic number,一般在0.04到0.15之间取值
Harris Detector 的具体流程:

harris特征的可复用性
旋转
harris具有旋转不变性,对于不同角度的相同的角点,理论上只是旋转矩阵会改变,但是两个特征值不会变。而我们选择角点的时候看的是特征值的大小,所以harris是旋转不变的
尺度 scale
很遗憾Harris对于尺度不具有不变性。
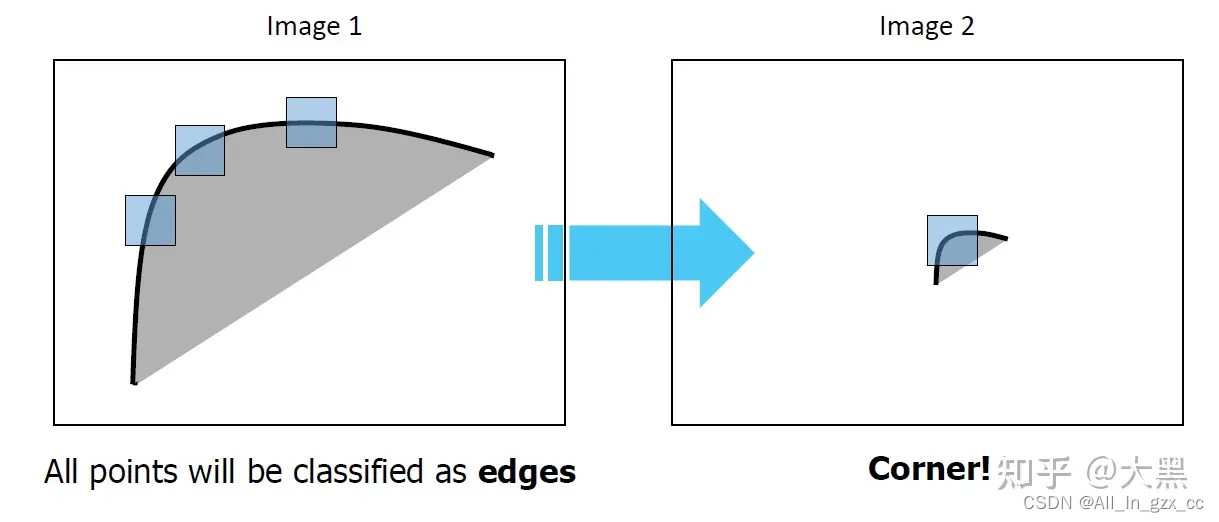
尺度变化之后,一个patch中可能只能看到一个转角的一小段,这个时候看起来更像是一段边缘
亮度 illumination
对于 Affine illumination change,也就 I′(x,y)=αI(x,y)+β,具有不变性。对于加性的光照变化,Harris是不受影响的,因为关注的是灰度的变化,虽然加了同一个数值,但是求导之后就没有了。不过对于乘性的变化,如果大于1,那么,之前所有的角点都还是大于threshold的,所以都还能找出来,而且由于有极大值抑制(NMS)。但是如果小于1,也就是光线整体变暗,就不一定了,可以理解为有的角点就看不清了。
对于monotonic illumination change,也就是单调的非线性的光照变化,Harris也是具有不变性的。主要的功劳在于非极大值抑制,我们找的是local maxima,所以不成问题。当然如果还是变得过于暗的话,那么肯定也会出现一些角点看不清的问题视角
view point
这个就是得看情况了。因为切换视角之后,角度会发生变化,如果角度变成接近与直线,那肯定找不出来了。不过对于一般小范围的视角变化,还是没有问题的。
三、Viola Jones检测原理
Viola Jones检测器由三个核心步骤组成,即Haar-like特征和积分图、Adaboost分类器以及级联分类器。
假设我们在目标检测时,需要这么一个子窗口,在待检测的图像中不断的滑位移动,子窗口每到一个位置,就会计算出该区域的特征,然后用我们训练好的级联分类器对该特征进行筛选,只要该特征通过了所有强分类器的筛选,则判定该区域为目标区域。
Harr-like特征提取
如图3所示,是5种不同的Haar-like特征算子,我们假设各个图片中的黑色区域灰度值总和为 b,白色区域灰度值总和为 w,b-w 得到的结果即子窗口区域的Haar-like特征值。

矩形特征 可位于图像窗口的任意位置,其大小也可以任意改变,所以矩形特征值是haar特征算子类别、矩形位置和矩形大小这三个因素的所决定的. 故类别、大小、位置的变化,使得较小的图片也会包含很多的矩形特征.。以一个24 × 24 的窗口为例,采用图3的5种不同的Haar-like特征算子进行计算,五种Haar-like特征算子的特征值数量分别为:43200,43200,27600,27600,20736,总计为160381. 就单单24 × 24 大小的图像窗口就有16万以上的特征值,现在,我们面临着两个问题:
- 面对这么多的特征值数量,该如何优化计算,减少计算量呢?
- 特征值的数量太多,肯定有一些特征值对于识别正样本与负样本较好,有一些不能够较好区分正样本与负样本. 那该怎么找到这些好的,优秀的特征即最优弱分类器。
积分图
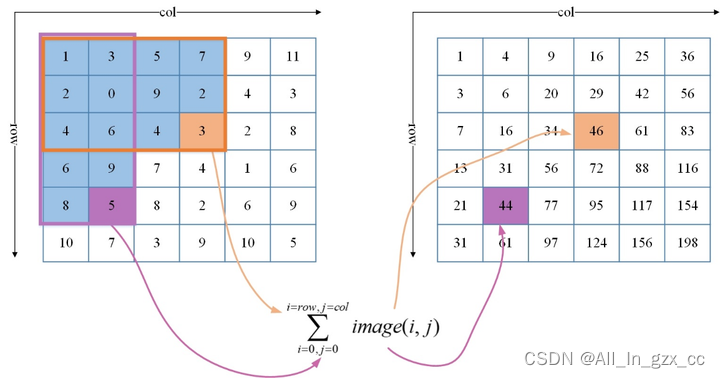
首先解决第一个问题,需要用到积分图,对于一幅灰度图,积分图中的任意一点的值是从原图像的左上角到这个点所构成的矩形区域内的所有点的灰度值之和,如图4所示:左图为原图,右图为积分图,积分图中的第3行第4列就是原图中黄色方框区域的像素和,积分图中的第5行第2列为原图像中紫色方框区域的像素和。

如下图所示:原图像中,有A,B,C,D四块区域,其中a,b,c,d表示D区域的四个顶点。怎么计算出D区域的积分图呢?
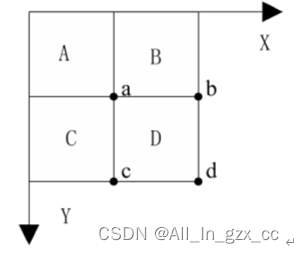

根据上面的理论,我们可以发现,积分图技术引入后,图像的Haar-like矩形特征值只受其所对应的积分图的值的影响,图像所在位置坐标的变化与其值没有关联。这样在我们计算矩形特征的时候就可以缩短计算特征值所耗费的时长。
训练最优弱分类器
现在来解决第二个问题,特征数量太多,需要进行特征的筛选,选择最优弱分类器。最初的弱分类器可能只是一个最基本的Haar-like特征,计算输入图像的Haar-like特征值,和最初的弱分类器的特征值比较,来判断输入图像是否为人脸,然而这个弱分类器太简陋了,可能不比随机判断的效果好,对弱分类器的孵化就是训练弱分类器为最优分类器,注意这是的最优不是强分类器,只是一个误差相对稍低的弱分类器,训练弱分类器实际上是为分类器进行设置的过程. 至于如何设置分类器,设置什么,我们先来看下弱分类器的数学结构:
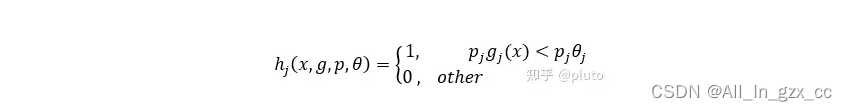



训练强分类器
弱分类只是具有一定分类能力的分类器,其比并不能达到我们对分类器的基本要求,所以我们需要对其进行进一步加强,构建基于弱分类器的强分类器。具体的训练步骤如下:
其实就是批量训练多个弱分类器,使其总Loss收敛最低,得到各个弱分类器对应的 优化后的权重值。

级联分类器
通过上述AdaBoost算法训练可以构建出一个强分类器,但是这样的分类器精确度还是有待提高,所以强分类器并不是分类器最后的结构,为了使得分类器的精确度与检测效率更加出色,可以使用级联方法将强分类器组合成级联分类器。

实际上,训练级联分类器的目的就是为检测时更加准确,Haar分类器的检测体系是以现实中的一幅图像作为输入,然后对图像中进行多区域,多尺度的检测. 所谓的多区域,是对图像划分多块,对每个块进行检测。由于训练时用的照片只有20 * 20左右的小图像,所以对于大的人脸,还需要进行多尺度的检测,多尺度检测机制一般有两种策略,一种是不改变搜索窗口的大小,而不断缩放图像,这种方法需要对每个缩放后的图像进行区域特征值的运算,效率不高。另一种方法,是不断初始化搜索窗口大小为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。在区域放大的过程中会出现同一个人脸会被多次检测,这需要进行区域的合并。无论哪一种搜索方法,都会为输入图像输出大量的子窗口,这些子窗口经过筛选式级联分类器会不断被第一个节点筛选,抛弃或通过,如上图所示。
【例】用opencv提供的Viola Jones分类器实现人眼的检测
import cv2
#加载分类器
eye_cascade=cv2.CascadeClassifier(cv2.data.haarcascades,'haarcascade_eye.xml')
img=cv2.imread('image/lenna.bmp') #加载检测图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#通过分类器对图片进行目标检测
eyes = eye_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5)
#标注眼睛所在区域
for (x, y, w, h) in eyes:
img=cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('demo', img) #输出显示
cv2.waitKey(0)

如上所示opencv已经包含了很多已经训练好的分类器,其中包括:面部,眼睛,微笑等。在python中的调用训练好的级联分类器所用到的函数如下:
cv2.CascadeClassifier(cv2.data.haarcascades,'haarcascade_eye.xml'):其中调用时的参数主要有分类器的类别,haarcascade_eye.xml是opencv已经训练好的检测人眼的级联分类器,其他常用的分类如下:

detectMultiScale(image,scaleFactor = 1.1,minNeighbors = 3 ):
其中
- image为待检测的灰度图像,
- scaleFactor为前后两次相继的扫描中搜索窗口的比例系数,默认为1.1 即每次搜索窗口扩大10%,
- minNeighbors 为构成检测目标的相邻矩形的最小个数,如果组成检测目标的小矩形的个数和小于minneighbors - 1 都会被排除。
其他 如 HOG检测器,基于部件的可变形模型(DPM)原理可阅读: https://zhuanlan.zhihu.com/p/474354399