目录
事情是这样的,我报名了DataWhale的关于机器学习课程的组队学习,本次的学习内容是西瓜书和南瓜书的1-6章。虽然说是有组织的学习,但是其实学习方式还是自己看书和看视频,但是有DataWhale提供的学习资料和讨论群,并且有打卡时间的限制,希望自己能坚持下来,把很久很久以前买的这本西瓜书啃一啃。
DataWhale吃瓜教程视频地址:
→【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导直播合集
❤ 2022.7.11 ❤
Task01:西瓜书+南瓜书第1、2章

第1章 绪论
〇 什么是机器学习
书里给的定义是这样的:


一些概念
数据集" (data set)
示例" (instance)
样本" (samp1e).
属性" (attribute)
特征" (feature)
属性值" (attribute va1ue).
属性空间" (attribute space)
样本空间" (samp1e space)
特征向量" (feature vector)
维数" (dimensionality)
学习" (lerning)
训练" (training)
训练数据" (training data)
训练样本" (training samp1e)
训练集" (training set)
假设" (hypothesis);
真实" (ground-truth)
学习器" (learner)
预测" (prediction)
标记" (labe1)
样例" (examp1e)
标记空间" (label space)
分类" (classification)
回归" (regression)
二分类" (binary cl sification)
正类" (positive class)
反类" (negative class);
多分类" (multi-class classification)
测试" (testing)
测试样本" (testing sample).
聚类" (clustering)
簇" (cluster)
监督学习" (supervised learning)
无监督学习" (unsupervised learning)
泛化" (generalization)
分布" (distribution)
独立同分布" (independent and identically distributed ,简称 i.i.d.)
归纳(induction)
横绎(deduction)
特化" (specialization)
归纳学习" (inductive learning)
概念(concept)
版本空间" (version space)
归纳偏好" (inductive bias)
〇 没有免费的午餐定理

第2章 模型评估与选择
一些概念
错误率" (error rate)
精度" (accracy)
误差" (error)
训练误差" (training error)
经验误差" (empirical error)
泛化误差" (generalization error)
过拟合" (overfitting)
欠拟合" (underfitting)
模型选择" (model selection)
测试集 (testing set)
留出法" (hold-out)
来样(sampling)
分层采样" (stratified sampling)
的真性(fidelity)
交叉验证法" (cross alidation)
k折交叉验证" (k-fold cross validation)
自助法" (bootstrapping)
自助采样(bootstrap sampling)
包外估计" (out-of-bag estimate).
调参" (parameter tuning).
性能度量(performance measure)
均方误差" (mean squared error)
查准率(precision)
查全率(recall)
真正例(true positive)
假正例 (false positive)
真反倒(true negative)
假反例 (false negative)
平衡点 (Break-Event Point ,简称 BEP)
分类阔值(threshold)
截断点" (cut point)
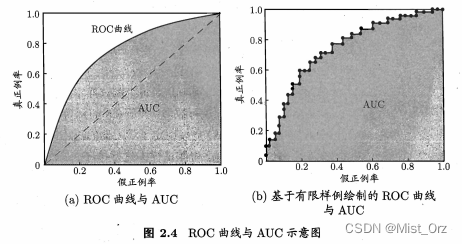
ROC受试者工作特征" (Receiver Operating Characteristic)
真正例率" (True Positive Rate ,简称 TPR)
假正例率" (False Positive Rate ,简称 FPR)
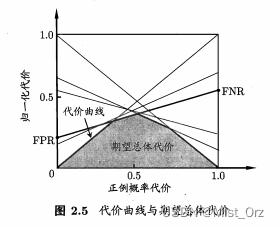
非均等代价" (unequa1 cost)
“代价矩阵” (cost matrix)
总体代价" (total cost)
代价敏感" (cost-sensitive)
代价曲线" (cost curve)
统计假设检验(hypothesis test)
二项检验" (binomial test)
置信度 confidence)
t 检验" (t-test)
成对t检验" (paired t-tests )
列联衷" (contingency table)
后续检验" (post-hoc test)
偏差方差分解" (bias-variance decomposition)
一些知识
· NP难问题
→科普,什么是“NP难”的问题。专业的解释俺看不懂。这个文章里面举了几个例子,俺一下就明白了。
· 多项式时间
· 机器学习的参数

· 归一化
△ 评估方法
· 留出法

· 交叉验证法

· 自助法

· 调参与最终模型

※

△ 性能度量
· 错误率与精度

(公式略)
· 查准率、查全率与F1

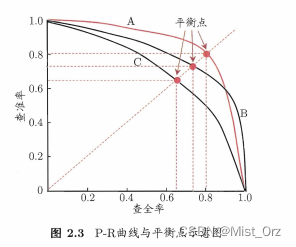

· ROC与AUC


· 代价敏感错误率与代价曲线

△ 比较检验
遥记得当年学习数理统计的时候学过这些内容,奈何全都还给老师了。。。。(虽然当时也没有听懂。。。)
现在看这些东西还是不太懂,这里留着以后把相关的笔记补上吧。
【待完善】
〇 假设检验
〇 交叉验证t检验
〇 McNemar检验
〇 Friedman 检验与 Nemenyi后续检验
△ 偏差与方差
· 偏差方差分解



Task02:详读西瓜书+南瓜书第3章
第3章 线性模型
一些概念
线性模型(linear model)
非线性模型(nonlinear model)
解释’性 (comprehensibility)
线性回归" (linear regression)
欧氏距离" (Euclidean distance)
最小二乘法" (least squ method)
参数估计" (p ameter estimation)
多元线性回归" (multivariate linear regression)
正则化 (regularization)
对数线性回归" (log-linear regression)
广义线性模型" (generalized linear model)
替代函数" (surrogate function)
对数几率函数(logistic function)
联系函数" (link fun ti n)
几率" (odds)
“对数几率” (log odds ,亦称 logit)
对数几率回归" (logistic regression ,亦称 logit regression)
极大似然法" (maximum likelihood method)
对数似然" (loglikelihood)
线性判别分析(Linear Discriminant nalys ,简称 LDA)
类内散度矩阵" (withi -cl scatter matrix)
类问散度矩阵" (betwee class scatter matrix)
广义瑞利商" (generalized Rayleigh quotient)
一些知识
· 线性模型基本形式

· 最小二乘法
· 正则化
· arg min
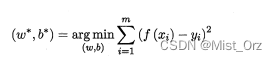
arg min 的意思是是这个式子得到最小值的w和b
· 极大似然估计
· 凸集、凸函数

这里凹凸的定义和数学里面的定义是反的,这里是用最优化理论的定义
· 梯度

· Hessian矩阵

· 机器学习三要素

· 信息论与信息熵

· 相对熵(KL散度)

· 二范数
向量的二范数相当于求向量的模长
→ 向量的2-范数、矩阵的2-范数
· 拉格朗日乘子法

· 广义特征值

· 广义瑞利商【没听懂,有空再学学】

厄米(Hermitian)矩阵: A H = A \ \mathrm{A}^\mathrm{H} = \mathrm{A} AH=A 的矩阵【?】

△ 线性回归
○ 一元线性回归


· 最小二乘估计

· 极大似然估计


※ 教材推荐:陈希孺《概率论与数理统计》

从线性模型的误差推导出y的概率分布


用最大似然估计的方法分析出来的公式与最小二乘法相同
· 求解w和b
解释西瓜书上54页公式(3.5)—(3.7),为什么偏导数得0是就是w和b的最优解


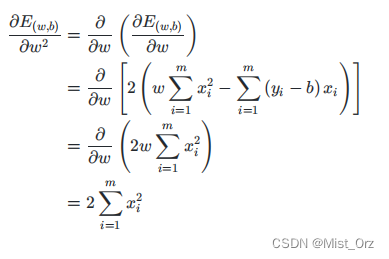


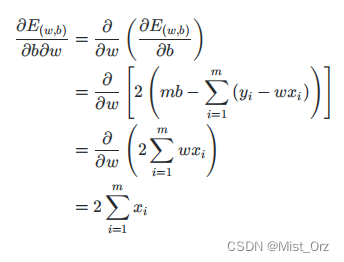
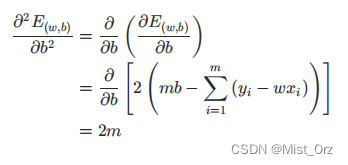


到此证明了损失函数是个凸函数,接下来应用凸函数的性质就可以求出最优解。

即偏导数等于0时,求w和b结果如下,过程见南瓜书。
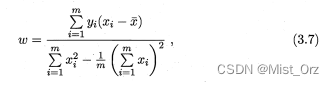
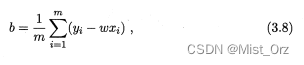
○ 多元线性回归
多元线性回归与一元线性回归的差别是多元的x是个向量
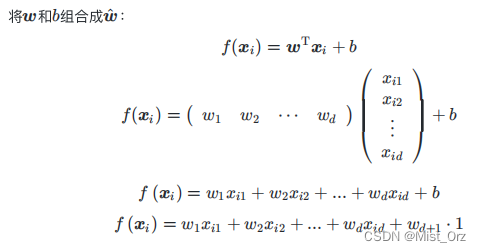
将b写成wd*1,然后吸收进矩阵形式里面
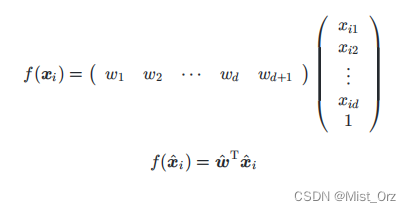
· 多元线性回归最小二乘法的向量化
向量化是为了避免求和时for循环的过多使用,将求和写成向量相乘的形式可以用numpy等运算库的矩阵加速功能
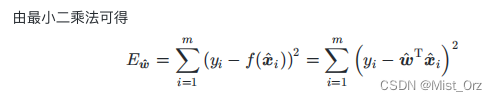
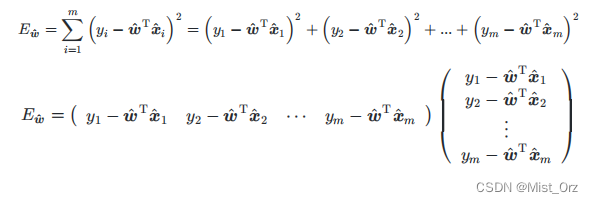

关于这个等式的变化,细节如下
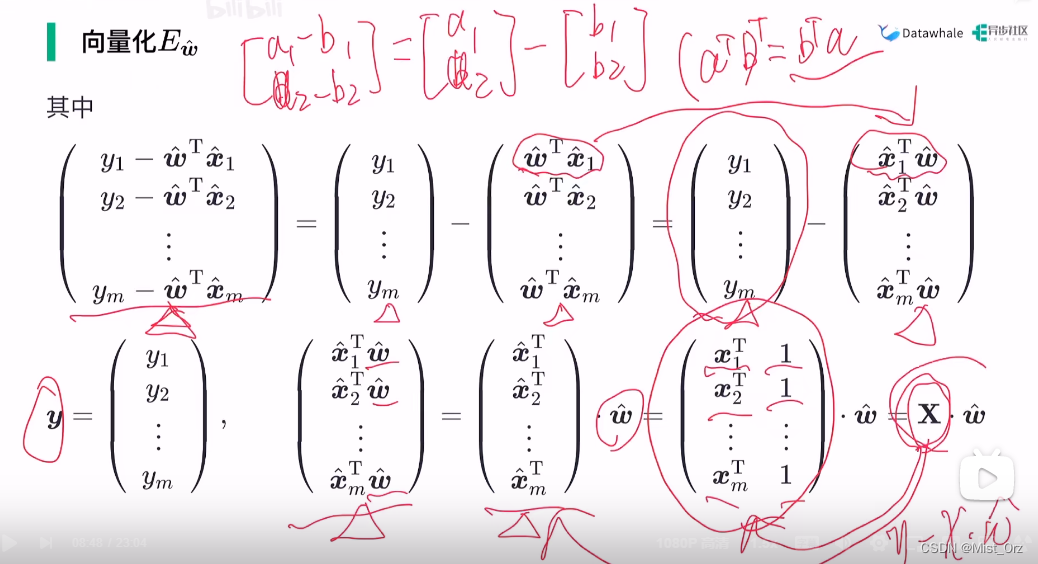

· 求解w尖号


细节如下

上面是标量,下面是向量,标量关于向量求导是矩阵微分的内容,求导方法如下

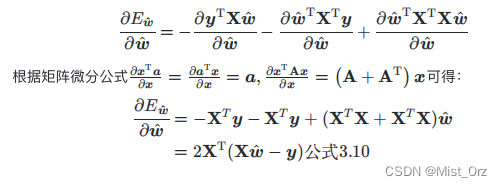
目的是求海塞矩阵,所以继续求一阶偏导

求海塞矩阵等于0,即求解出最优向量
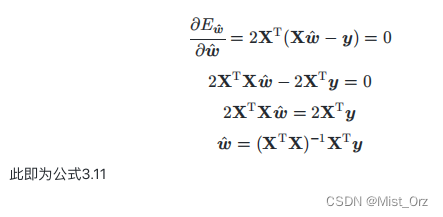
○ 对数几率回归
对数几率回归即逻辑回归,他的本质是个分类算法,

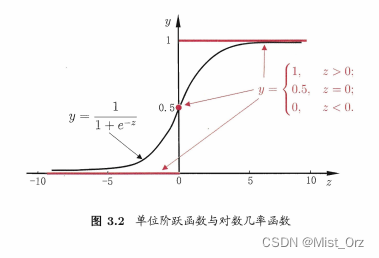
· 对数几率回归的极大似然估计
首先用前面推导出的线性回归模型结合映射函数sigmoid函数建立概率质量函数
※ 因为y值为0,1,所以函数为概率质量函数,不是概率密度函数

将概率质量函数写成统一的形式

写出似然函数,使用对数函数将连乘转化为求和

将前面推导出的式子带入
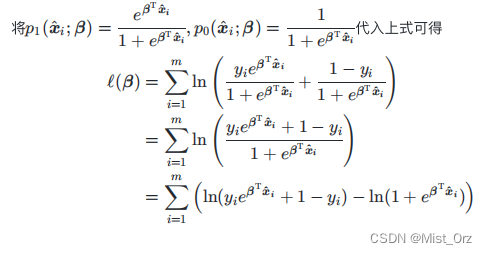

· 以信息论的方法(最小化相对熵)来实现优化

首先写出理想分布和模拟分布,然后带进交叉熵的计算公式



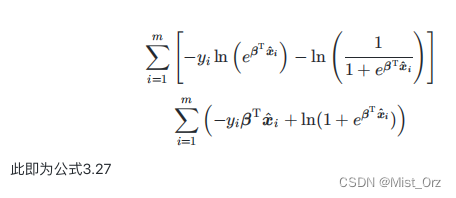
· 对数几率回归算法的机器学习三要素

○ 二分类线性判别分析


书中内容:
x i \ x_{i} xi:n维特征向量
y i \ y_{i} yi:样本标记,取值0或1
X i \ X_{i} Xi:中的 i \ i i指的是y的取值,即0或1,他表示y取相同值的样本的集合
μ i \ \mu_{i} μi: i \ i i取0或1,表示取相同值的样本(正样本或负样本)的均值向量
Σ i \ \Sigma_{i} Σi: i \ i i取0或1,表示取相同值的样本(正样本或负样本)的协方差矩阵
一般来说协方差矩阵的形式是这样的,书上的公式有一定的简化:
Σ 0 = 1 m 0 ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T \ \Sigma_{0} = \frac{1}{m_{0}} \sum_{x \in X_{0}}^{} (x - \mu_{0} )(x - \mu_{0})^T Σ0=m01x∈X0∑(x−μ0)(x−μ0)T
Σ 1 = 1 m 1 ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T \ \Sigma_{1} = \frac{1}{m_{1}} \sum_{x \in X_{1}}^{} (x - \mu_{1} )(x - \mu_{1})^T Σ1=m11x∈X1∑(x−μ1)(x−μ1)T
· 算法原理

图片见上图
· 损失函数推导
一般计算的时候用以下的形式
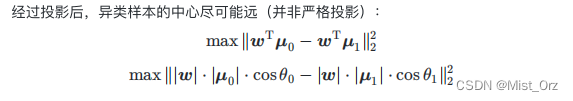
w T μ \ \boldsymbol{w}^\mathrm{T}\boldsymbol{\mu} wTμ:是向量的内积形式,在这里是求正负样本的中心在 w \ \boldsymbol{w} w上的投影,在这里乘上了 w \ \boldsymbol{w} w的模长,而两个投影都乘以一个模长不影响求其最大距离(相当于同等倍数的放大或缩小)
max是使向量的投影距离最大

这里不是严格的方差是因为正常的方差前面要除以样本的数量(见上面的公式),而这里样本的数量相同,所以相当于乘以同一个系数,对计算没有影响,于是省掉了
( w T x − w T μ 0 ) ( x T w − μ 0 T w ) \ (\boldsymbol{w}^\mathrm{T}\boldsymbol{x} - \boldsymbol{w}^\mathrm{T}\boldsymbol{\mu_{0}}) (\boldsymbol{x}^\mathrm{T}\boldsymbol{w} - \boldsymbol{\mu_{0}}^\mathrm{T}\boldsymbol{w}) (wTx−wTμ0)(xTw−μ0Tw)等价于 ( w T x − w T μ 0 ) 2 \ (\boldsymbol{w}^\mathrm{T}\boldsymbol{x} - \boldsymbol{w}^\mathrm{T}\boldsymbol{\mu_{0}})^2 (wTx−wTμ0)2,相当于是 ( x − x ˉ ) 2 \ (x - \bar{x})^2 (x−xˉ)2
于是推导出如下公式
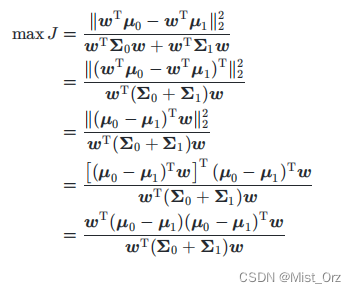

※ 后面会讲的知识:广义瑞利商
这里的
是为了固定 w \ \boldsymbol{w} w的模长,因为 w \ \boldsymbol{w} w的模长不影响计算结果(上下都约掉了),所以给其指定一个值(分母为1),方便后续计算,在计算中既可以固定分子,也可以固定分母,这里选择了固定分母。
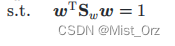
这里用 m i n \ min min是因为优化问题一般都将损失函数写成最小化的形式,如果原式是最大化,则需要在其前面加上负号
· 用拉格朗日乘子法 求解 w \ \boldsymbol{w} w

矩阵微分需要查询手册(在前面有介绍)

这是个求广义特征值的问题(相对的是求普通特征值问题)。

讨论

○ 多分类学习【挖坑待填】
○ 类别不平衡问题【挖坑待填】
❤ 2022.7.21 ❤
Task03:西瓜书+南瓜书第4章

第4章 决策树
一些概念
决策树(decision tree)
分而治之" (divide-and-conquer)
信息铺" (information entropy)
信息增益" (information gain)
增益率" (gain ratio)
基尼指数" (Gini index)
剪枝(pruning)
预剪枝" (prepruning)
后剪枝"(post- pruning)
决策树桩" (decision stump)
分法(bi partition)
多变量决策树" (multivariate decision tree)
单变量决策树" (univariate decision tree)
增量学习" (incrementallearning)
一些知识
· 自信息与信息熵

※ 样本的“纯度”

· 条件熵

· 信息增益
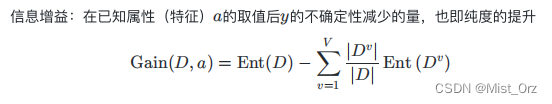
· 基尼值与基尼指数


△ 算法原理

· ID3决策树

· C4.5决策树


· CART决策树


CART决策树一定是二叉树
❤ 2022.7.25 ❤
Task04:西瓜书+南瓜书第5章

第五章 神经网络
一些概念
神经网络(neural networks)
神经元(neuron)
阔值" (threshold)
激活函数" (activation function)
挤压函数" (squashi function)
感知机(Perceptron)
阈值逻辑单元" (threshold logic unit)
哑结点" (dummy node)
学习率(learning rate)
功能神经元(functionalneuron)
线性可分(linearly separable)
收敛(converge)
震荡(fluctuation)
隐含层(hidden laye)
“多层前馈神经网络 (multi-layer feedforward neural networks)
连接权” (connection weight)
误差逆传播(error BackPropagation ,简称 BP)
梯度下降(gradient descent)
累积误差逆传播(accumulated error backpropagation)算法
试错法" (trial-by-error)
“早停” (early stopping)
正则化" (regularization)
“局部极小” (local minimum)
“全局最小” (global minimum)
模拟退火" (simulated annealing)
遗传算法(genet algorithms)
RBF(Radial is Function,径向基函数)网络
竞争型学习 (competitive learning)
“胜者通吃” (winner-take-all) 原则
ART(Adaptive Reson.ance Theory,自适应谐振理论)网络
可塑性-稳定性窘境" (stabilityplasticity dilemma)
增量学习 (incremental learning)
在线学习 (onlinelearning)
SOM(Self-Organizing Map ,自组织映射)
最佳匹配单元(best matching unit)
级联相关(Cascade-Correlation)网络
相关性(correlation)
递归神经网络" (recurrent neural networks)
能量" (energy)
基于能量的模型" (energy-based model)
受限 Boltzmann机(Restricted Boltzmann Machine,简称 RBM)
对比散度" (Contrastive Dìv ge ce,简称CD)
深度学习" (deep learning)
无监督逐层训练(unsupervised layer-wise training)
预训练" (pre-training)
微调" (fine-tuning) 训练
权共享" (weight sharing)
卷积神经网络(Convolutional Neural Network,简称 CNN)
特征映射(feature map)
汇合"(pooling) 层
特征学习 (feature learning)
表示学习(representation learning)
特征工程" (feature engineering)
一些知识
· M-P神经元

△ 感知机
· 感知机模型

感知机是个分类模型
更多资料可以见《统计学习方法》-杨老师

关于感知机几何角度的讲解
如图所示一个超平面的示意图
超平面的方程为:
x 1 + x 2 − 1 = 0 \ x_{1} + x_{2} - 1 = 0 x1+x2−1=0
其对应的法向量 w = ( 1 , 1 ) T \ \boldsymbol{w} = (1,1)^\mathrm{T} w=(1,1)T, b = − 1 \ b = -1 b=−1
法向量垂直于超平面,在此图中,法向量指向超平面的右侧,因此右侧为正空间,左侧为负空间。
正空间的点带入超平面的公式大于零,负空间带入小于零。
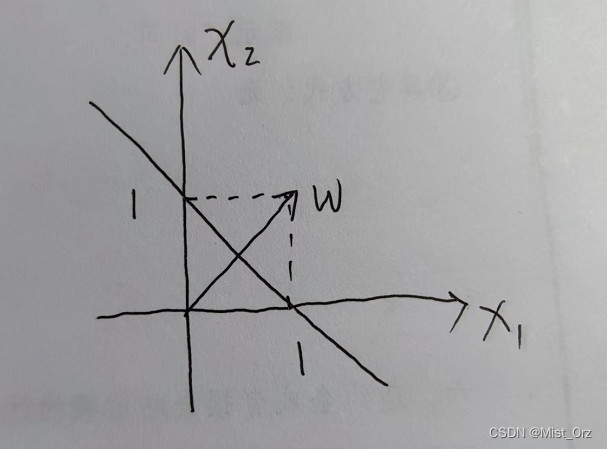
· 感知机学习策略


这里的把 θ \ \theta θ看做“哑结点”的方法在前面 多元线性回归 里面讲过。