第一章 绪论
一、基本术语
1、模型:本书中指从数据中学得的结果
2、样本/示例/特征向量sample/instance/feature vector:即一条记录,对一个对象的描述。
如:关于西瓜的一条记录为:(颜色=青绿;根蒂=蜷缩;敲声=浊响)
在有样本空间概念的情况下,由于空间中每个点对应一个坐标向量,则把一个样本称为一个特征向量
3、数据集data set:一组记录的集合。
4、特征/属性feature/attribute:对象在某方面的表现或性质。
如:颜色、根蒂、敲声
5、属性值attribute value:属性上的取值
6、样本空间/属性空间/输入空间sample space/attribute space: X , \mathcal{X}, X,属性张成的空间。
如:把三个属性(颜色、根蒂、敲声)分别作为三个坐标轴,则张成了一个描述西瓜的三维空间。
在样本空间中,每个对象都能找到自己的坐标点,该点称为特征向量
7、特征向量 x ⃗ i = ( x i 1 , x i 2 , . . . , x i d ) \vec{x}_i = (x_{i1}, x_{i2}, ..., x_{id}) xi=(xi1,xi2,...,xid)的维数dimensionality:d
表示:
1、数据集 D = { x ⃗ 1 , x ⃗ 2 , . . . , x ⃗ m } D = \{\vec{x}_1, \vec{x}_2,..., \vec{x}_m\} D={ x1,x2,...,xm} :表示包含m个特征向量(样本/示例)的数据集
2、特征向量/样本: x ⃗ i = ( x i 1 , x i 2 , . . . , x i d ) \vec{x}_i = (x_{i1}, x_{i2}, ..., x_{id}) xi=(xi1,xi2,...,xid): x ⃗ i \vec{x}_i xi是d维样本空间中的一个向量,每个特征向量由d个属性描述。
学习、训练:数据—>模型
1、学习算法:learning algorithm:从数据中产生模型的算法(机器学习研究的主要内容)
2、学习/训练learning/training:从数据中,通过执行某个学习算法,学得模型的过程
3、训练数据training data:学习/训练中使用的数据
4、训练样本training sample:训练数据中的每个样本(sample)
5、训练集training set:训练样本组成的集合。
6、学得的模型/假设hypothesis:对应了关于数据的某种潜在的规律
7、数据的潜在规律/真相/真实ground-truth
建立关于预测的模型:label标记
模型要能判断是否是好瓜,只有实例/样本数据是不够的,需要建立关于预测prediction的模型:获得训练样本的“结果”信息,结果称为标记label。
1、标记label:训练样本的结果信息
如:((颜色=青绿;根蒂=蜷缩;敲声=浊响),好瓜)
2、样例example:有label的示例/样本。
表示
-
第 i i i个样本sample: x ⃗ i \vec{x}_i xi
-
第 i i i个样例example: ( x ⃗ i , y i ) (\vec{x}_i, y_i) (xi,yi)
-
训练集(可能有label也可能没有): { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , . . . , ( x ⃗ m , y m ) } \{(\vec{x}_1, y_1), (\vec{x}_2, y_2), ..., (\vec{x}_m, y_m)\} { (x1,y1),(x2,y2),...,(xm,ym)}
-
样本空间/输入空间sample space: X , x ⃗ i ∈ X \mathcal{X}, \vec{x}_i\in \mathcal{X} X,xi∈X
-
标记空间/输出空间label space: Y \mathcal{Y} Y, y ⃗ i ∈ Y \vec{y}_i\in \mathcal{Y} yi∈Y
二、预测/学习任务
2.1 按输出空间是离散值还是连续值分类
1、分类classification任务:预测离散值的学习任务
-
二分类binary classification任务:
- 正类positive class
- 反类negative class
-
多分类multi-class classification任务:设计多个类别
2、回归regression:预测连续值的学习任务
如西瓜的成熟度:0.97,0.54…
2.2 按训练集是否有label分类:监督学习和无监督学习
-
监督学习supervised learning:分类、回归
-
无监督学习unsupervised learning:聚类

2.3 预测任务:建立映射、学得模型
预测任务:从训练集中,通过执行某个学习算法,建立一个从输入空间 X \mathcal{X} X,到输出空间 Y \mathcal{Y} Y的映射f, f : X → Y f: \mathcal{X} \to Y f:X→Y。
- 二分类任务 Y = { − 1 , + 1 } 或 { 1 , 1 } \mathcal{Y} = \{-1, +1\}或\{1, 1\} Y={ −1,+1}或{ 1,1}
- 多分类任务 ∣ Y ∣ > 2 |\mathcal{Y}| > 2 ∣Y∣>2
- 回归任务: Y = R , R 为 实 数 集 \mathcal{Y} = R,R为实数集 Y=R,R为实数集
2.4 测试testing:使用模型进行预测
-
测试样本testing sample:被预测的样本
-
学得 f f f后,对测试样本 x ⃗ \vec{x} x,可得到预测标记 y = f ( x ⃗ ) y = f(\vec{x}) y=f(x)。
三、泛化generalization能力
泛化能力:学得模型适用于新样本的能力。
假设样本空间中全部样本 服从一个未知分布 D \mathcal{D} D(distribution)
独立同分布(independent and identically):获得的每个样本都是独立地从此分布上采样获得
一般训练样本越多,得到的关于分布 D \mathcal{D} D 的信息越多,越有可能学习获得强泛化能力的模型。
四、假设空间 H \mathcal{H} H
4.1 归纳和演绎
- 归纳induction:泛化的过程,即特殊到一般的过程,从具体事实归结出一般性规律。
如:从样例中学习,也称为归纳学习(inductive learning)
- 演绎deduction:特化specialization的过程,即一般到特殊的过程,从基础原理推演出具体状况。
如:基于一组公理和推理规则推导出 与之相恰的定理
4.2 学习过程:搜索假设空间 H \mathcal{H} H
学习过程:看成在所有假设组成的空间中进行搜索的过程,目的是找到能 对 训练集中 的瓜 判断正确的假设,即与训练集匹配的假设。
4.3 假设空间规模
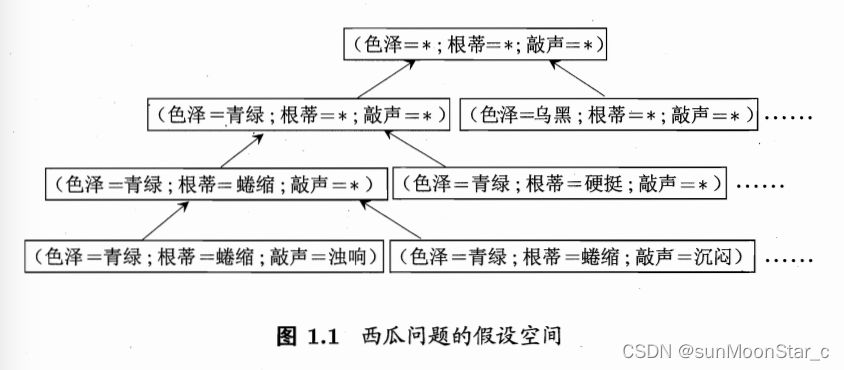
若色泽、根蒂、敲声分别由3、2、2种可能取值,则假设空间规模大小为 4 ∗ 3 ∗ 3 + 1 = 37 4*3*3+1 = 37 4∗3∗3+1=37
+1:可能根本没好瓜,用∅表示这个假设
4,3,3分别多了1种情况:可能所有色泽/根蒂/敲声,取值都正确,用 ∗ * ∗表示
4.4 搜索假设空间
搜索:对假设空间搜索(自顶向下、一般到特殊…),搜索过程中不断删除和正类不一致的假设,或和反类一致的假设。最终获得能对所有训练样本进行正确判断的假设,这就是学习得到的结果。
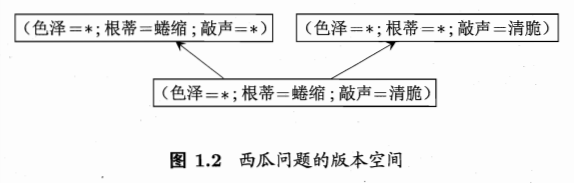
4.5 版本空间version space
版本空间version space:可能有多个假设和训练集一致,则这些假设组成的集合就是版本空间。
五、归纳偏好inductive bias
原因
版本空间中的假设,面临新样本,可能产生不同的输出。

但是我们需要学习得到的模型,必须对应了其中一个假设,此时则需要学习算法的“偏好”,来选择一个最符合实际问题的假设来作为模型。
提前揭晓一下偏好的答案:必须具体问题具体分析,针对问题的重要性等具体显示因素,使得学习算法的归纳偏好和问题相配
5.1 归纳偏好/偏好
归纳偏好:算法在学习过程中,对某种类型假设的偏好。
一个有效的学习算法,必然有归纳偏好。
对于4.5节版本空间中的三个假设:
- 好瓜<–> (色泽=*)∩(根蒂=蜷缩)∩(敲声=浊响)
- 好瓜<–> (色泽=*)∩(根蒂= ∗ * ∗)∩(敲声=清脆)
- 好瓜<–> (色泽=*)∩(根蒂=蜷缩)∩(敲声= ∗ * ∗)
如果算法更偏好尽可能特殊的模型,则选择假设1
如果算法更偏好尽可能一般的模型,则在2,3中选择;如果同时算法更相信“根蒂”,则选择3.
5.2 归纳偏好回归学习图示:
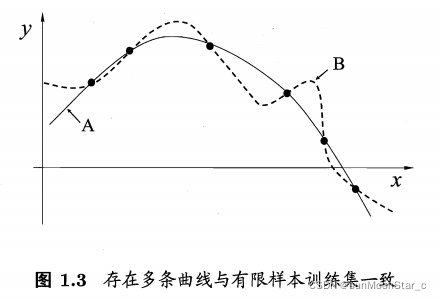
每个训练样本对应图中一个点(x, y),要学得一个和训练集一致的模型,相当于找到一条穿过所有训练样本点的曲线。
存在多条曲线可以满足,则学习算法必须有偏好,才能产出模型。
- 若认为相似样本应有相似输出:偏好平滑曲线
- 反之偏好崎岖曲线
5.3 常见归纳偏好原则:奥卡姆剃刀Occam’s razor
奥卡姆剃刀Occam’s razor:若无必要勿增实体,即若有多个假设和观察一致,选择最简单的那个。
更平滑---->更简单,如平滑曲线更容易用方程描述 y = − x 2 + 6 x + 1 y = -x^2 + 6x+1 y=−x2+6x+1,崎岖曲线则复杂
奥卡姆剃刀也不是唯一可能原则。
5.4 NFL(No Free Lunch Theorem)没有免费的午餐定理
NFL(No Free Lunch Theorem)没有免费的午餐定理:无论学习算法A多聪明,多洗算法B多笨拙,期望性能是相同的。
但这并不意味着,任何学习算法最终预测性能都一样。
因为现实生活中, f f f不是均匀分布的,即不是所有问题都同等重要,出现几乎相同,我们只关注具体问题的应用,不关注其在其他相似问题是否为好方案。
如西瓜问题版本空间有以下两个假设:
- 好瓜<–> (色泽=*)∩(根蒂=蜷缩)∩(敲声=浊响)
- 好瓜<–> (色泽=*)∩(根蒂= 硬 挺 硬挺 硬挺)∩(敲声=清脆)
要注意到:(根蒂=硬挺)∩(敲声=清脆)的好瓜十分罕见,甚至不存在。
总结:NFL是要我们认识到,如果要考虑所有潜在问题,则所有学习算法期望性能都一样,在一些问题上表现好的学习算法,在另一些问题可能不尽如人意。但是我们现实生活必须针对具体学习问题谈论算法的相对优劣,使得学习算法的归纳偏好和问题相配。
习题
1、根据样例求版本空间

搜索规则:对假设空间搜索(自顶向下、一般到特殊…),搜索过程中 不断删除和正类不一致的假设,或和反类一致的假设 。最终获得能对所有训练样本进行正确判断的假设,这就是学习得到的结果。
手算过程:从一般到特殊,不断删除不符情况
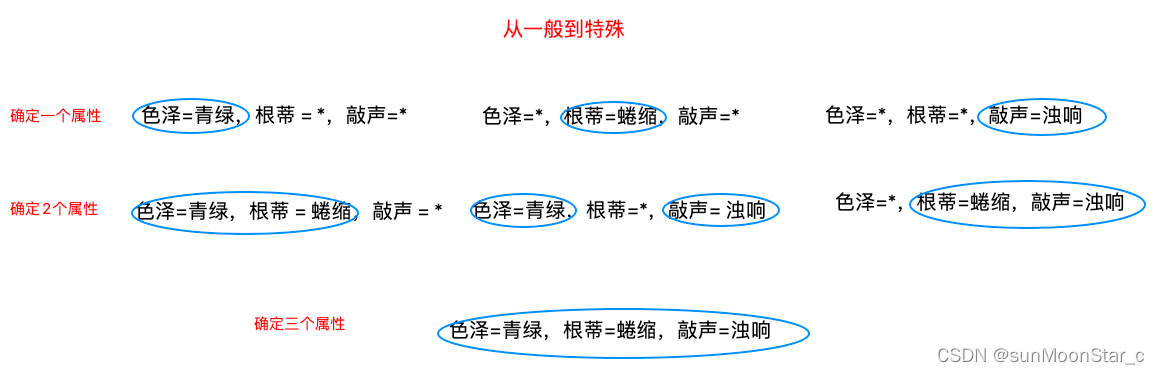
代码实现:用6位二进制表示所有假设
六位二进制的所有取值情况为: [ 0 , 2 6 ] [0, 2^6] [0,26]
色泽有2种取值,青绿和乌黑:
- 11:表示*,青绿乌黑都可以
- 01:表示取青绿
- 10:表示取乌黑
- 00:表示二者都不取(必然不在版本空间中,因为肯定不符合正例)
根蒂有2种取值,蜷缩和稍蜷:
- 11:表示*,二者都可
- 01:表示蜷缩
- 10:表示稍蜷
- 00:表示二者都不取(必然不在版本空间中,因为肯定不符合正例)
敲声有2种取值,浊响和沉闷:
- 11:表示*,二者都可
- 01:表示浊响
- 10:表示沉闷
- 00:表示二者都不取(必然不在版本空间中,因为肯定不符合正例)
正例的6位二进制表示(青绿,蜷缩,浊响):010101,记为P
反例的6位二进制表示(乌黑,稍蜷,沉闷):101010,记为N
搜索过程(包含正例且不符合反例):若当前遍历到的假设的六位二进制表示为H,则H | P == H代表H包含了正例P的情况,H | N != H代表H不包含反例的情况。同时满足,则H是版本空间中的一个假设。
如果H中有00的情况,也是能判断成功的,假设H = 010100代表青绿,蜷缩,声音既不是浊响也不是沉闷,和H | P = 010100 不等于H,不符合。
>>> res_lst = []
>>> lst_bin = [num for num in range(0, 2**6+1)]
>>> for num in lst_bin:
if num | int('010101',2) == num and num | int('101010',2) != num:
res_lst.append(bin(num)[2:])
>>> res_lst
['10101', '10111', '11101', '11111', '110101', '110111', '111101']
# 高位补0输出
>>> [format(num, '06b') for num in res_lst]
['010101', '010111', '011101', '011111', '110101', '110111', '111101']