2022年11月30日一定是一个载入人类AI发展史的一天,这一天第一个版本的Chat GPT(全称:Chat Generative Pre-trained Transforme)发布了。毫不夸张地说,chatGPT的发布和用户体验,将整个AI话题推上了一个前作未有的高度(包括最早的深蓝,AlphaGo,Boston Dynamics 等产品)。这是利用大语言模型(LLM:Large Language Model)完成人类和计算机的类人的模糊交流。包括比尔-盖茨,老黄等众多科技大佬为之点赞,整个科技界都为之狂欢,甚至都逼的Google大佬亲自上阵调教自家Bert来应对ChatGPT的挑战
ChatGPT 飓风
从ChatGPT发布到第一个一亿用户,只用了短短两个月,这个绝对是前无古人,后鲜有来者的数据。
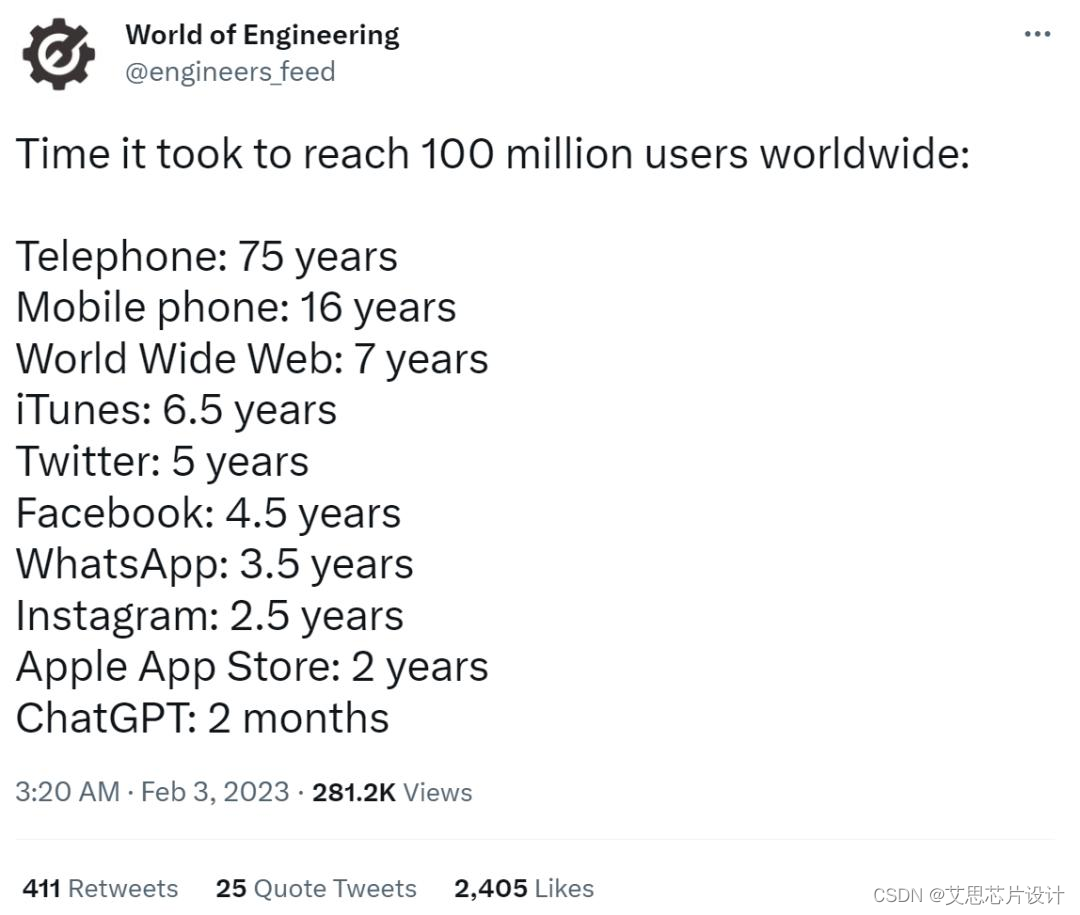
互联网指数级的增长在这里得到了充分的体现,只要产品过影,火星人马丁叔叔都可能会成为你的忠粉

就在本月,连续三个有关AI的产品发布依次降临:
- 2023年3月15日 OpenAI 发布ChatGPT4
- 2023年3月16日 微软发布基于ChatGPT4引擎的Office 365 Copilot
- 2023年3月16日 百度才发布“文心一言”
前两个发布应该都是安排好的,微软是OpenAI的大股东,在ChatGPT3.5发布的时候就有过传言,微软正在全面整合ChatGPT到微软的产品中,第一个整合ChatGPT的微软产品就是新必应(New Bing,2023年2月7号发布),在过去的一个来月,Google的搜索量应声下降了2%!所以整合ChatGPT4的office Copilot就显得水到渠成了。有兴趣的小伙伴可以看一下Office 365 Copilot的发布会,相当震撼。office的体验简直丝滑到没有摩擦力了,半分钟word,10秒PPT,估计以后小朋友都可以直接玩转office了。此外,OpenAI的所有硬件都是运行在微软的Azure云服务器矩阵上的,OpenAI只生成创新,并不买服务器。但是大家要知道,最早的OpenAI可是选择Google的云服务器的。以上种种,可以看到微软这个48岁的老江湖,依然走在真个科技的最前沿,依然意气风发。
第三个发布的百度的文心一言,这里确实要点赞一下!对于世界AI的崛起,中国绝对不能默不作声。虽然当前的文心一言还有很多不足的地方(有up主做过一些测试,有兴趣的小伙伴可以关注一下),但是这不是主要问题,先站出来迎战,才有可能形成挑战!
ChatGPT4的提升
ChatGPT4 相较于前版本GPT3.5有了更为强大的提升:
可以读取文字和图片混合模式的输入:可以读图生成网站的前端JS代码,或者理解一幅图的内容

提问:请问图片中有什么不寻常的地方
回答:这个图片有点奇怪,一个男的固定在一辆正在行驶中的出租车的车顶,并且在一个熨烫板上熨衣服。
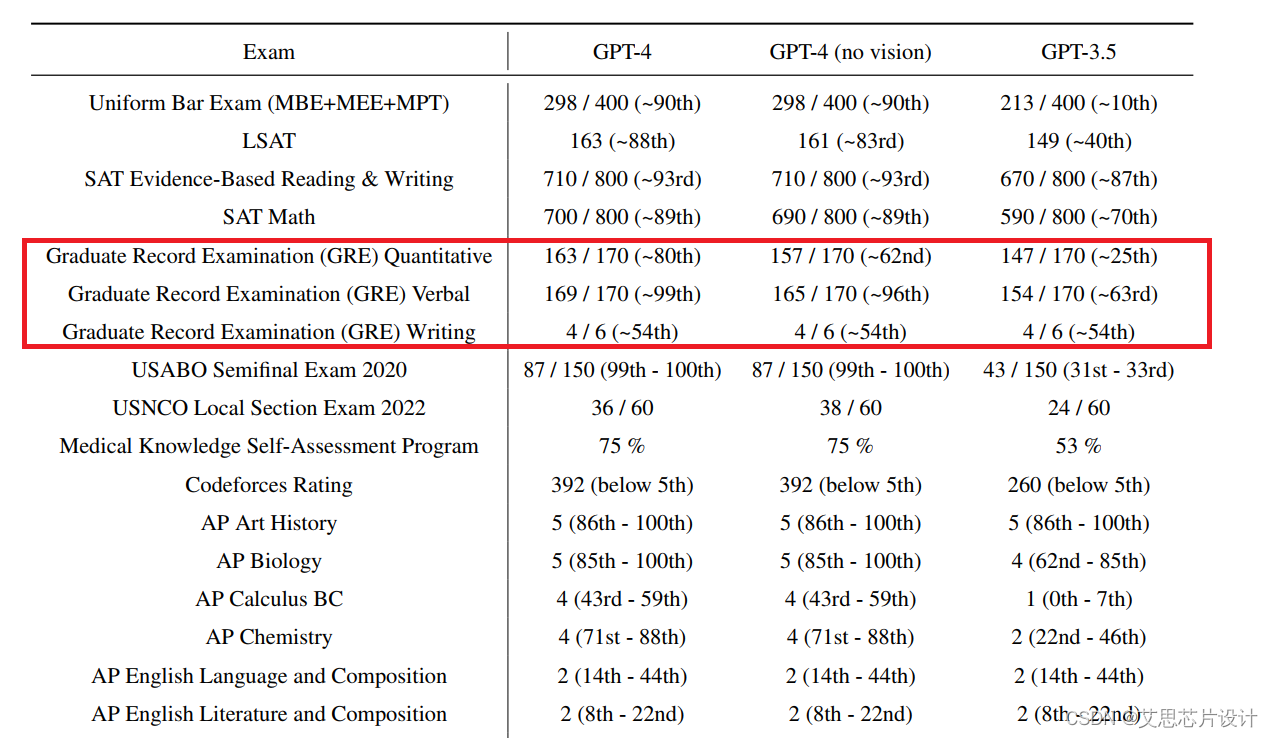
通用考试中,更高的考试成绩
比如,在统一律师考试( Uniform Bar Exam )中,GPT-4 可以超过 90% 的人类考生,而老版本只能超过 10% 的人类考生,相当于一个是考第一名,一个是考倒数第一名。
在 GRE 数学考试中 GPT-4 可以考 163 分( 170 分满 )超过 80% 的考生,老版本只能超过 25% 的考生。
在 GRE 语文( 阅读与填空 )考试中 GPT-4 可以考 169 分( 170 分满 )超过 99% 的考生,而老版本只能超过 63% 的考生。
单从这两门的分数来看,GPT-4 到了可以申请哈佛、麻省理工、斯坦福大学的水平。

更大的训练模型
汽车已经发动起来了,速度提升只是时间问题,下图展示了ChatGPT4和ChatGPT3训练参数数量的区别

ChatGPT的原理
这么厉害的东东,他是怎么工作的呢?这里一起来看看它的工作原理
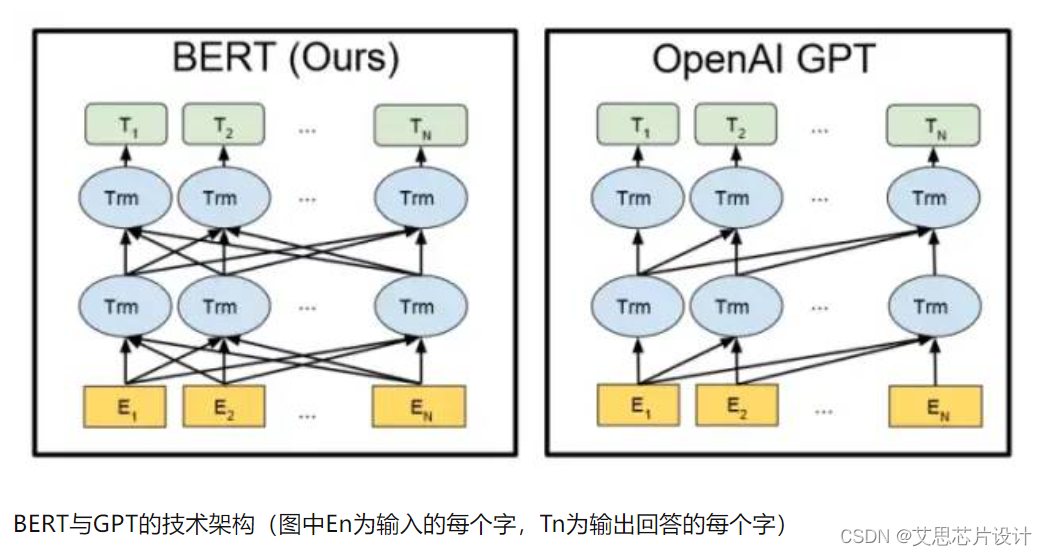
首先ChatGPT是一个单字生成迭代器。利用每一个输入的文字(注意是字不是词也不是句子),产生下一个字,中间产生的的过程也会有迭代。可以看到GPT的迭代是单向的,Google都Bert是双向的,这个其实会比较复杂,也会有算力的代价。笔者理解,人类的思维应该是更偏向于ChatGPT的单向迭代,当然如果Bert可以成功,那就会说出超语言(super-word)。
如果需要模型生成单字,就要训练他,就像对小朋友训练类似,不断地训练,小朋友可以表述的字和句子就会越来越丰富。这个还是沿用了传统的教育,引导,奖惩的机制。计算机的算法模型也是可以契合这种训练方式的,这个在上世纪80年代的AI训练中就有提及,这一点一直都没有发生变化,模型训练的简单步骤
- 第一阶段:训练监督策略模型:对模型提供问题和正确答案的模板,供AI学习
- 第二阶段:训练奖励模型:让AI尝试回答人类问题,人类对问题的答案进行打分,给出AI指引,这一过程类似于教练或老师辅导。引导AI在未来回答得分较高的答案
- 第三阶段:使用离线模式强化训练:利用PPO(Proximal Policy Optimization)生成回答,并用第二阶段奖励模型进行打分,再次对AI进行打分迭代,从而强化PPO的模型参数和精准度
不断重复第二和第三阶段,通过迭代,这样会训练出更高质量的ChatGPT模型。
ChatGPT算力和成本
硬件预览
ChatGPT 可以实现和人类对话的前提是有一个及其庞大的硬件运算体系,据估算,ChatGPT的总算力消耗约为3640PF-days (即假如每秒计算一千万亿次,需要计算3640天)。微软使用了一万片NV的A100 超高性能GPU芯片,单颗显卡售价唱过5万人民币,如果是基于A100的小型服务器,售价更是高达100万人民币!微软单在Azure的·A100的运算架构,就给OpenAI投入了上亿美元的云端设备。微软已经在评估NV最新的H100,算力提升明显,NV给出的评估是相较于A100,H100的算力会提高10倍,相信不久的未来ChatGPT的输出就出自H100的运算结果。当然,H100的售价更是超过了惊人的20万人民币(3+万US$,图示为日元报价).

据估算,OpenAI需要的初始硬件成本高达:10亿美金,约合65亿人民币
运算和运营成本
GPT-3训练成本约为140万美元;对于一些更大的LLM模型,训练成本约达到1120万美元。单日应对13M访客的电费就超过4.7万美金,基于数据的增长,每三到四个月就需要运算一次。一年下来,投入在训练和日常运营的成本就高达:2260万美金, 折合人民币约1.5亿。这个对于一般公司确实是一个不小的开支
参考资料
架构师技术联盟 ChatGPT发展历程、原理、技术架构详解和产业未来
国盛计算机 ChatGPT需要多少算力
Hassan Mujtaba *** NVIDIA H100 80 GB PCIe Accelerator With Hopper GPU Is Priced Over $30,000 US In Japan***
OpenAI *** GPT-4 Technical Report ***