JVM
JVM是java的虚拟机,java的运行环境(java二进制字节码的运行环境)
好处:
- 一次编写,到处运行
- 自动内存管理,垃圾回收功能
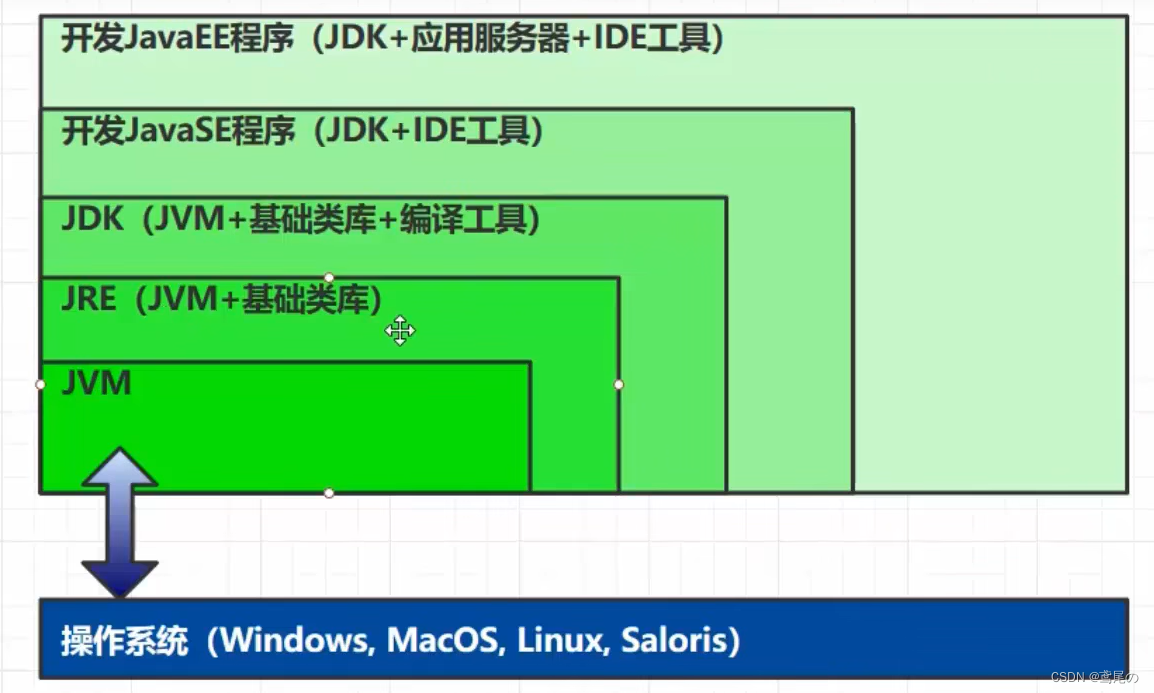
JDK、JRE、JVM的关系图
常见的JVM:
- oracle的Hotspot是我们通常使用的jvm
- openJDK的HotSpot在linux系统中可能用的多些
组成部分
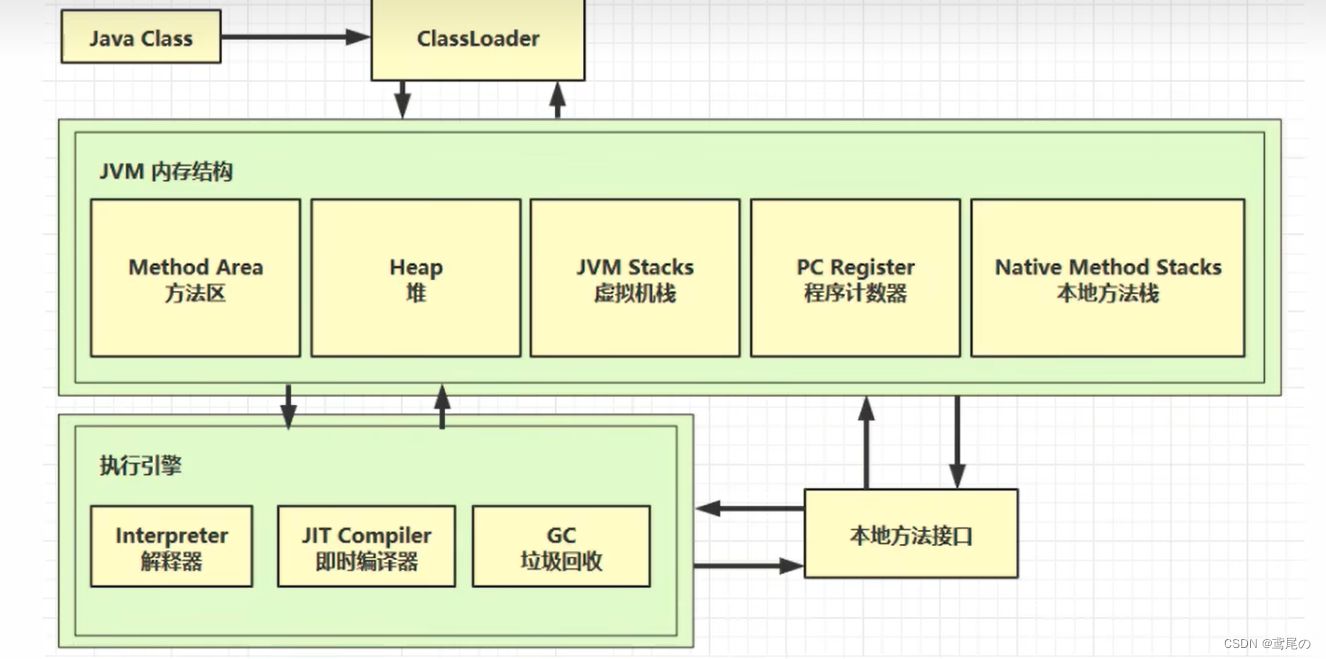
- ClassLoader类加载器
- jvm的内存结构
- 执行引擎
JVM内存结构
堆内存
Heap堆
- 通过new关键字,创建的对象都会放入到堆内存
特点:
- 是线程共享的,堆内存中的对象需要考虑线程安全问题
- 有垃圾回收的机制
堆内存溢出
一般情况下,堆中存在的对象太多而无法再创建新的对象时,就会出现内存溢出的错误。OutMemoryError:java heap space
可以通过参数调整jvm堆内存大小-Xmx8G
StringTable
字符串常量池,在1.8时是放入到heap堆内存中的,主要存储一些字符串的常量,在每次创建新的字符串对象前,会去字符串常量池中找一下,如果没找到,再次创建新的字符串对象。
当有这样一段代码,我们进行反编译一下
public class Test2 {
public static void main(String[] args) {
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
}
}
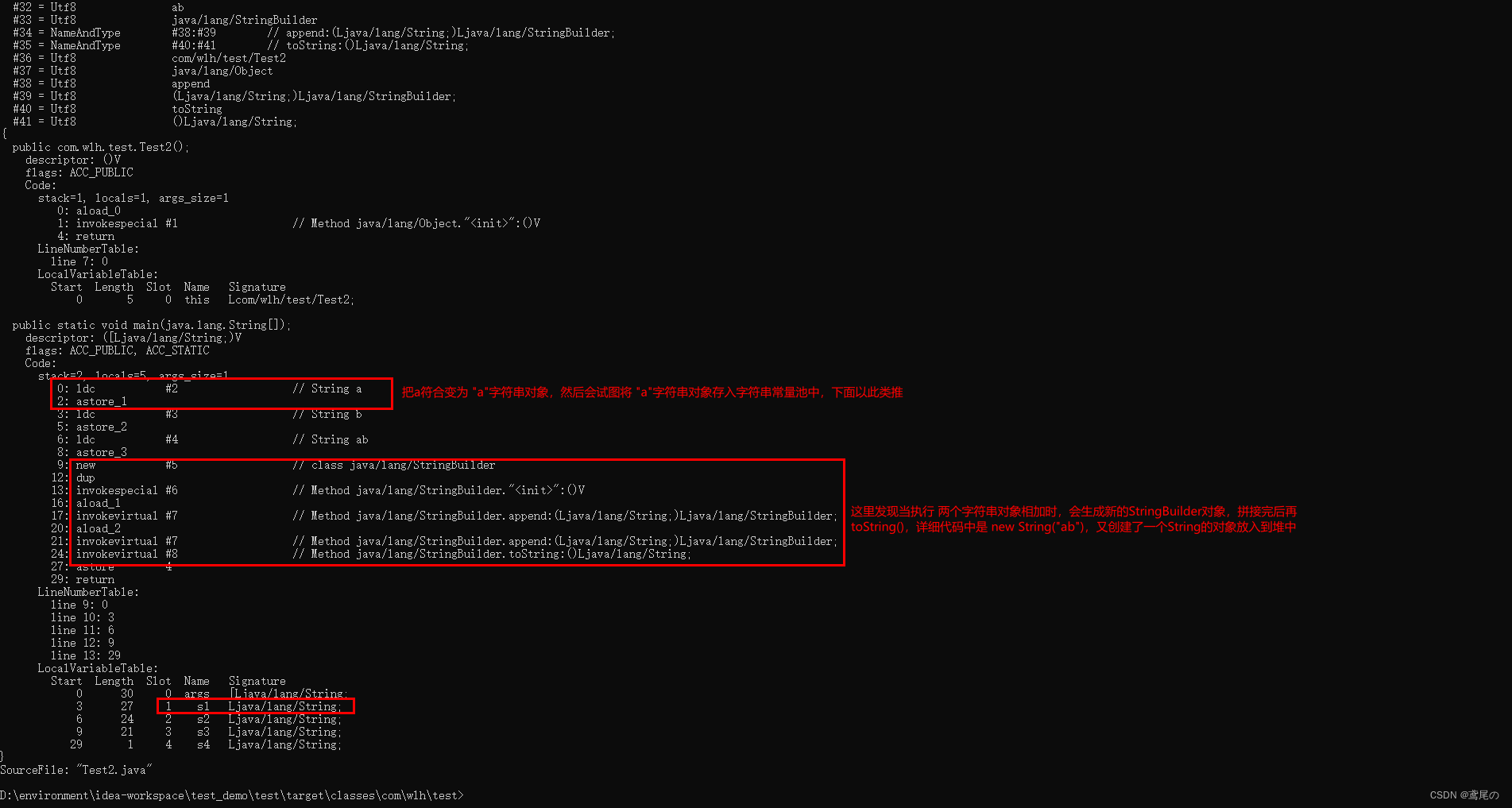
如上图,两个字符串对象相加,会先创建一个StringBuilder对象将这些字符串对象拼接起来,然后再toString(),创建一个新的String对象放入到堆内存中。
而不同的是,当两个字符串的常量相加时,它不会创建StringBuilder对象,而是直接去字符串常量池中找有没有这个组合完毕的字符串,没有的话直接创建一个放入到字符串常量池中
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
String s5 = "a" + "b";
如上代码,也就是s4的值是需要创建StringBuilder对象拼接完再toString()得来,而s5的值则是直接去字符串常量池中找的,因为s3的"ab"已经存在于字符串常量池中了,那么s5就不会再创建新的"ab"对象了。
而这个原因就是javac在编译期间的优化,结果已经在编译期间就确定为"ab"了。
StringTable特性
-
常量池中字符串仅是符号,第一次用到时才变为对象
-
利用串池的机制,避免重复创建字符串对象
-
字符串变量的拼接原理是StringBuilder对象(1.8)
-
字符串常量拼接的原理是编译器优化
-
可以使用intern()方法,主动将串池中还没有的字符串对象放入串池
// 串池中 ["a", "b"] public static void main(String[] args) { String s = new String("a") + new String("b"); // 在堆中,new String("a") new String("b") new String("ab") String s2 = s.intern(); // 将s这个字符串对象尝试放入串池,如果有则不会放入,如果没有则将字符串对象放入串池,且当前字符串对象的引用变为串池中的了,最后都会返回串池中的对象 System.out.println(s2 == "ab"); // s2此时就是串池中的 "ab" true System.out.println(s == "ab"); // s此时已经被放入串池中了 true }
StringTable的位置
1.6是在永久代的常量池里面
1.8是在堆内存中的,是为了防止内存溢出,在堆内存进行GC时,会对StringTable也进行垃圾回收,释放内存。
StringTable垃圾回收
可以在程序运行时加一些参数,查看StringTable的统计信息,和GC详情
-Xmx100m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
StringTable性能调优
-
设置程序启动参数
设置StringTable的bucket桶数量(StringTable就是一个哈希表,由数组+链表组成的,数组中一个元素就是一个桶),增加桶的数量可以减少哈希冲突。默认是6w个桶
-XX:StringTableSize=200000 -XX:+PrintStringTableStatistics -
考虑是否将字符串对象入池
如果存在大量相同字符串时,可以选择将字符串进行入池,防止创建冗余的字符串对象。
虚拟机栈
栈:线程运行需要的内存空间,每个入栈的元素都是一个栈帧(一个个的方法运行需要的内存:参数,局部变量、返回地址等)
栈的数据结构:先进后出,后进先出。压栈和出栈
- 一个线程有一个线程栈
- 每个栈有多个栈帧(Frame)组成,对应每次方法调用需要的内存
- 每个线程只能有一个活动栈帧,对应当前正在执行的那个方法
栈内存溢出
-
栈帧过多,导致栈内存溢出(如递归死循环)
常见的如:部门下有多个员工,同时员工又要绑定部门,完事后转换为json数据,就会出现栈溢出,这时候就改为单向关联即可了
-
栈帧过大,导致栈内存溢出
本地方法栈
java可以通过调用本地方法接口调用其他语言实现的一些功能,避免了重复造轮子。
程序计数器
Program Counter Register程序计数器(寄存器)
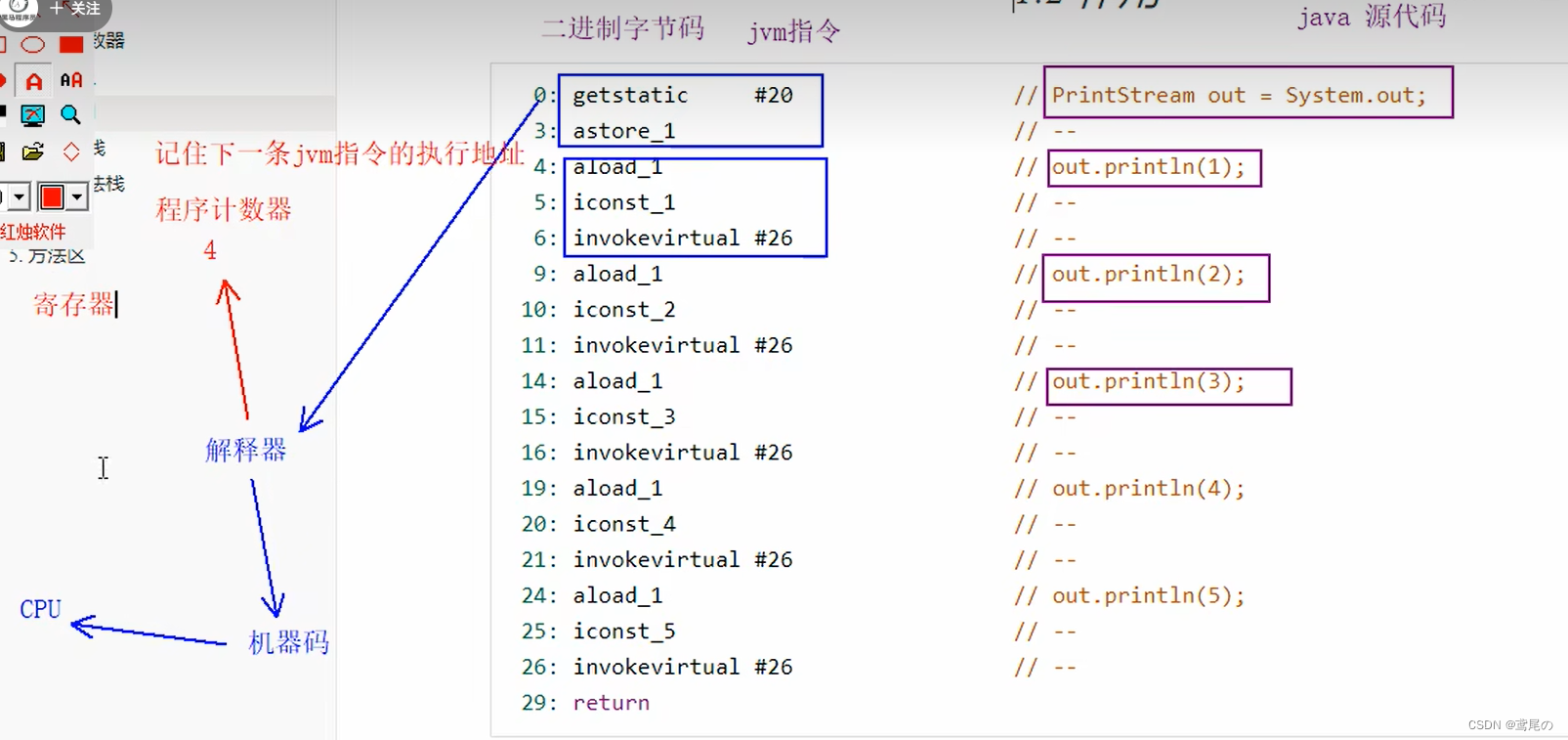
作用:记住下一条jvm指令(二进制字节码.class文件中的内容)的地址;当解释器开始解释某一条jvm指令时,程序计数器会把下一条jvm指令的地址记住,当解释器解释完毕后,再次从程序计数器中找新的指令地址开始执行。
由于cpu中的寄存器读取速度快,而且程序读取jvm指令会很频繁,所以直接使用(物理)cpu中的寄存器当做程序计数器来使用。
特点:
- 线程私有
- 不会存在内存溢出
方法区
方法区就是一个概念上的东西。方法区主要存储一些类信息、静态变量、常量池等,且在java1.6和java1.8中又有些区分。
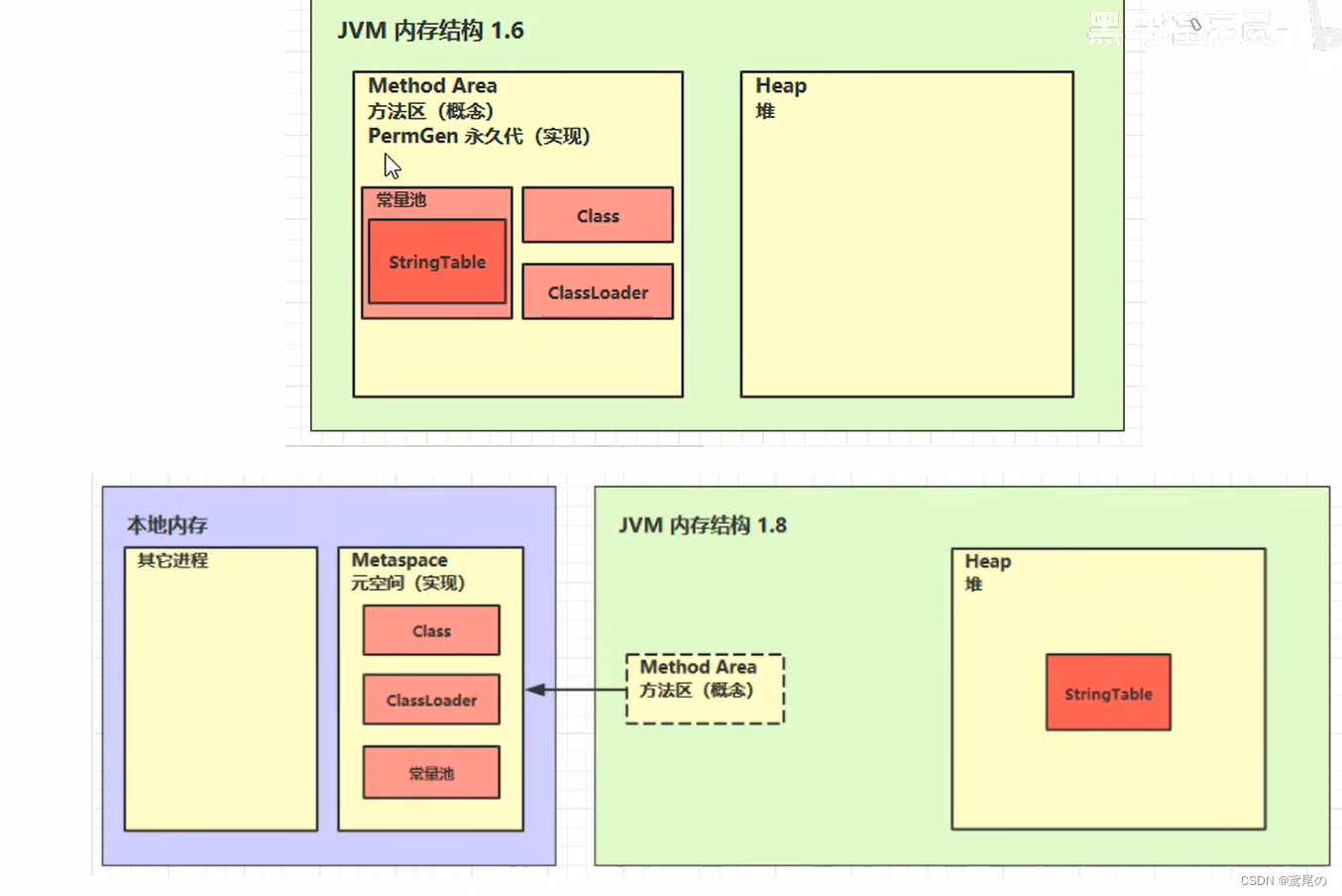
java1.6是以PermGen永久代的方式实现的。
在java8中,对方法区有调整,但同时方法区还是概念上的东西。
方法区中的数据保存在本地的内存中(操作系统内存),像类信息、类加载器、常量池等都是在元空间中。而字符串表不再存放在常量池中,而是在Heap堆内存中了。
常量池
通过javap -v 类文件,对类进行反编译,我们可以深入了解到java代码的工作机制。可以查看到详细的信息(类基本信息、常量池、类方法的定义、包含了虚拟机指令)
这里可以看到一些详细信息
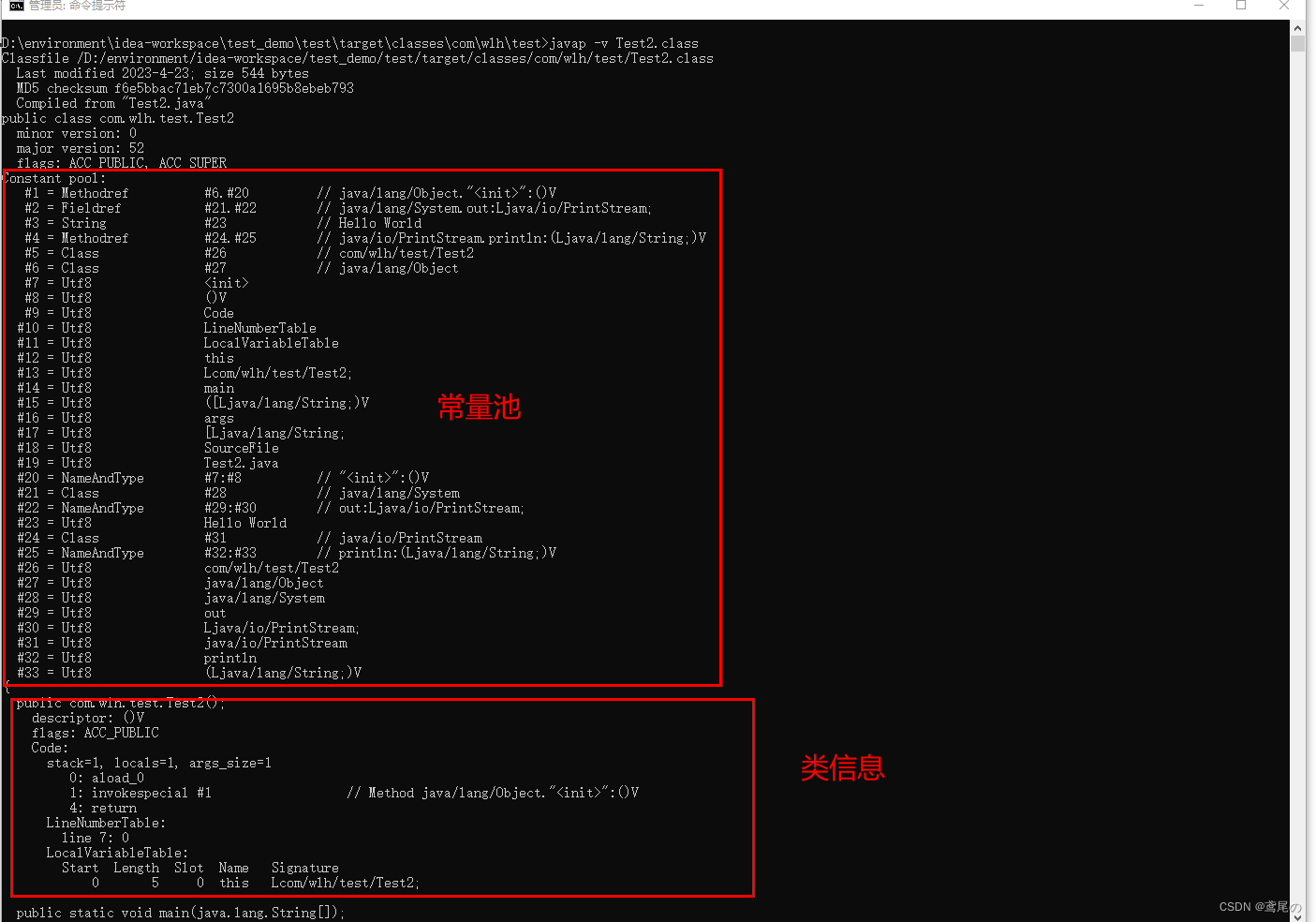
这里可以看到解释器是怎么执行的
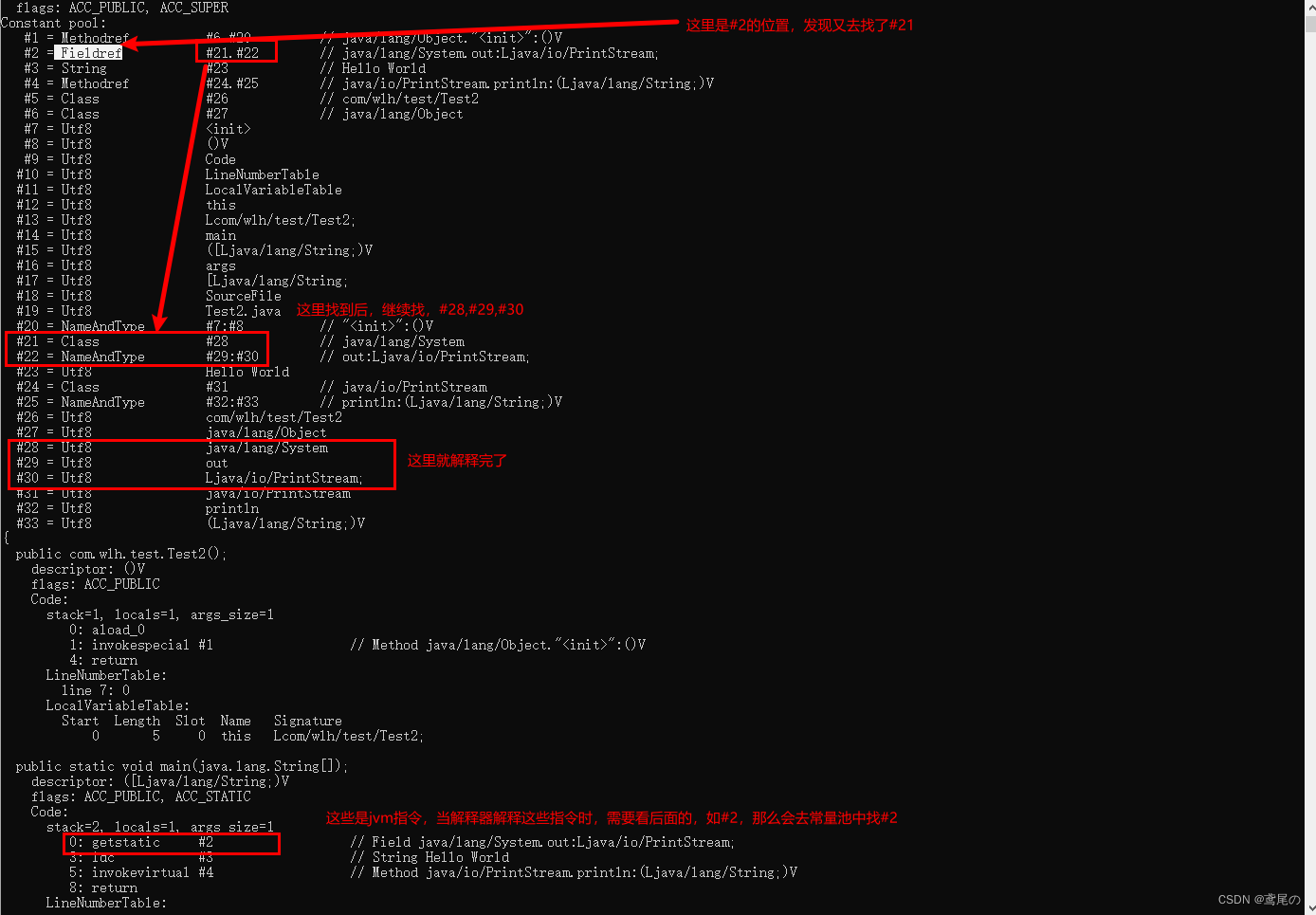
- 常量池,就是一张表,虚拟机指令根据这张常量表找到需要执行的类名、方法名、参数类型、字面量等信息
- 运行时常量池,常量池是*.class文件中的,当该类被加载,它的常量池信息会放入运行时常量池,并且把里面的符号地址变为真实地址
方法区内存溢出
-
1.8以前会导致永久代内存溢出
-XX:MaxPermSize=8m,报错java.lang.OutOfMemoryError:PermGen space -
1.8之后会导致原空间内存溢出,模拟一下,执行时设置下原空间大小
-XX:MaxMetaspaceSize=8m,报错java.lang.OutOfMemoryError:Metaspace/** * @Date 2023/4/23 17:49 * @Created by wlh * 模拟元空间内存溢出,可以设置元空间的大小 * -XX:MaxMetaspaceSize=8m */ public class Test1 extends ClassLoader { // 可以用来加载类的二进制字节码 public static void main(String[] args) { int j = 0; try { Test1 test = new Test1(); for (int i = 0; i < 10000; i++, j++) { // ClassWriter作用是生成类的二进制字节码 ClassWriter cw = new ClassWriter(0); // 参数:版本号,public(类访问级别),类名,包名,父类,接口 cw.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null); // 返回byte byte[] code = cw.toByteArray(); // 执行加载类 test.defineClass("Class" + i, code, 0, code.length); } } finally { System.out.println(j); } } } ====================================返回结果===================== Exception in thread "main" java.lang.OutOfMemoryError: Compressed class space 3331 at java.lang.ClassLoader.defineClass1(Native Method) at java.lang.ClassLoader.defineClass(ClassLoader.java:763) at java.lang.ClassLoader.defineClass(ClassLoader.java:642) at com.wlh.test.Test1.main(Test1.java:26)
程序启动时手动加载类信息(动态加载类)的场景:
- Spring
- mybatis
它们使用的cglib,就需要去加载一些类信息。
常见问题
-
垃圾回收是否涉及栈内存
GC不涉及到栈内存,栈主要是一个个的方法调用,结束后会自动释放内存
-
栈内存分配越大越好吗
参数
-Xss可以设置线程栈的大小,linux/mac默认都是1024kb,windows是取决于jvm的内存,栈分配空间大些无非就是可以存储更多的方法执行,对程序效率没有什么益处假设物理内存是500mb,每个线程大小设置为10mb,那么最多只能有50个线程;若设置为100mb,那么只能有5个线程,所以线程数量会和大小成
反比 -
方法内的局部变量是否线程安全
- 如果方法内局部变量没有逃离方法的作用范围(不是方法参数、没有将此变量return),它是线程安全的
- 反之则是不安全的,因为外部可以访问到这个变量
线程诊断
CPU过高
在Linux系统中top命令可以查看cpu的使用情况,左侧的PID只能看到进程的ID值
-
可以使用ps命令查看详细的进程、线程、cpu占用情况,找到有问题的TID(线程id)
ps H -eo pid,tid,%cpu | grep PID值 -
可以使用
jstack PID值查看具体的详细线程信息由于信息中的nid都是16进制的,可以去计算器中将有问题的TID转换为16进制,去信息中确认下到底是哪个线程出现了问题。
堆内存诊断
jps工具(命令行)
查看当前系统有哪些java进程,在jps中找到需要的进程ID,注意当前命令窗口的权限是否足够,不够的话是用不了jps的,再一个是检查下java的环境配置的是否有问题。
jmap工具(命令行)
查看堆内存的占用情况 -heap
jmap -heap PID进程号
jconsole工具(图形化)
图形界面,多功能的监测工具,可以连续监测,可以通过命令行进行唤醒打开此工具
jvisualvm可视化工具(推荐)
在命令窗口输入jvisualvm命令打开即可
直接内存
定义
Direct Memory:操作系统的内存
- 常见于NIO操作,用于数据缓冲
- 分配回收成本较高,但读写性能高
- 不受JVM内存回收管理
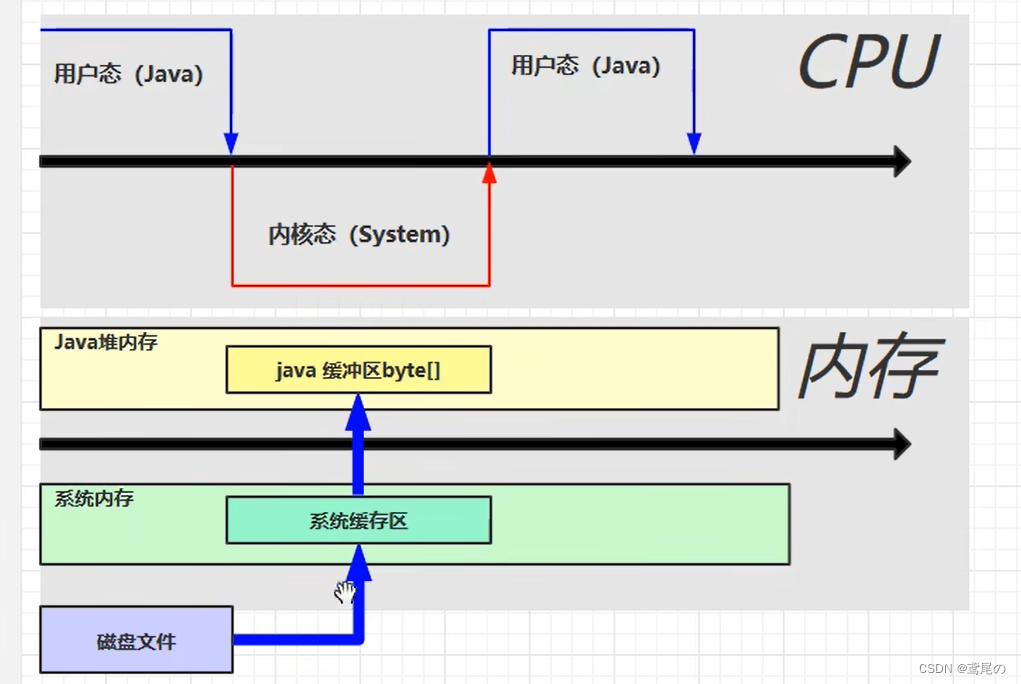
进行文件读写时,会从用户态转换为内核态去调用系统的本地方法操作系统资源,那么在系统内存中会创建一个系统的缓冲区,然后再传入到java的缓冲区中进行读写,两次复制没有必要。
改进:
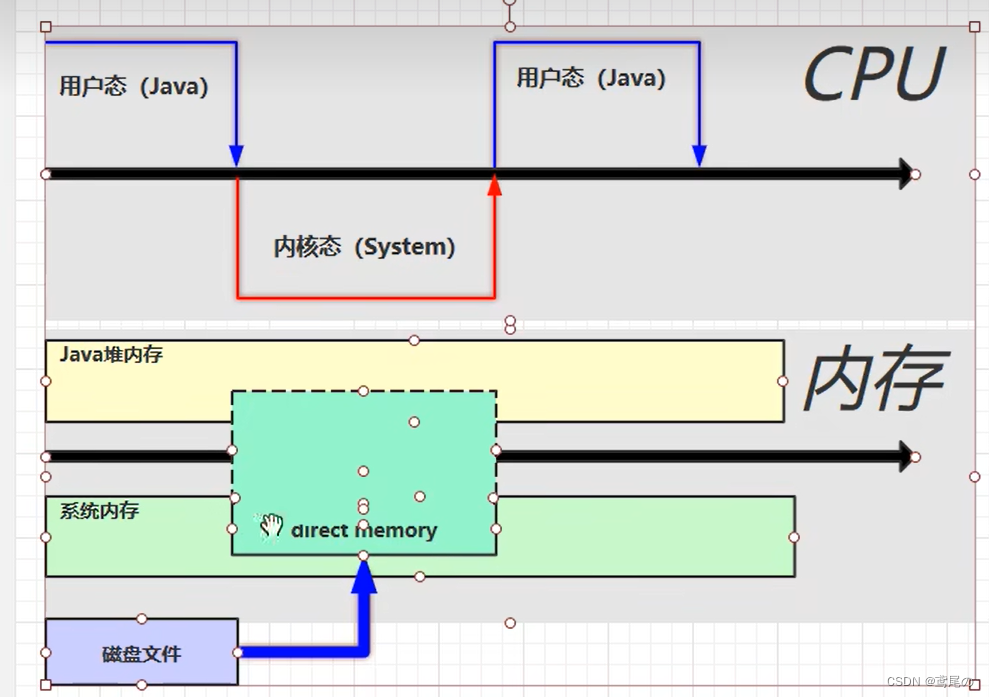
在系统内存和java的内存中整一个直接内存,磁盘文件数据直接放入到直接内存中即可。共享内存区域,那么在java中是通过ByteBuffer类来实现的。
直接内存释放
int _1GB = 1024 * 1024 * 1024;
ByteBuffer byteBuffer = ByteBuffer.allocate(_1GB);
System.out.println("内存分配完毕...");
System.in.read();
byteBuffer = null;
System.gc();
以上代码执行后,jvm在gc时,会将直接内存回收掉。其实并不是jvm的gc回收了直接内存,而是底层的Unsafe进行内存释放的管理。
ByteBuffer类底层就是使用的Unsafe类的freeMemory()释放的直接内存。
有以下参数可以禁用显式的gc垃圾回收
-XX:+DisableExplicitGC禁用显式full gc
如果有必要,我们可以使用Unsafe来手动管理直接内存,而不要去触发full gc,因为太消耗时间了。