Start with JVM
周志明先生著-《深入理解Java虚拟机》,书买回来好几天了,但是最近才准备开始搞一搞了(哭瞎…..)。首先是第一章的Java以及JVM发展历史,大概知道了现行的应用最广泛的Java虚拟机是HotSpot,当然一些商业公司也有使用自己的虚拟机。
JVM运行时数据区
这是放在Java内存区域与内存溢出异常里面的必备知识,描述了Java虚拟机在运行时的数据区域
私有
- 程序计数器:记录当前线程所执行字节码的行号指示器
- 虚拟机栈:存放了当前线程调用方法的局部变量表、操作数栈、动态链接、方法返回值等信息(可以理解为线程的栈)
- 本地方法栈:为虚拟机使用的Native方法提供服务,后多与JVM Stack合并为一起
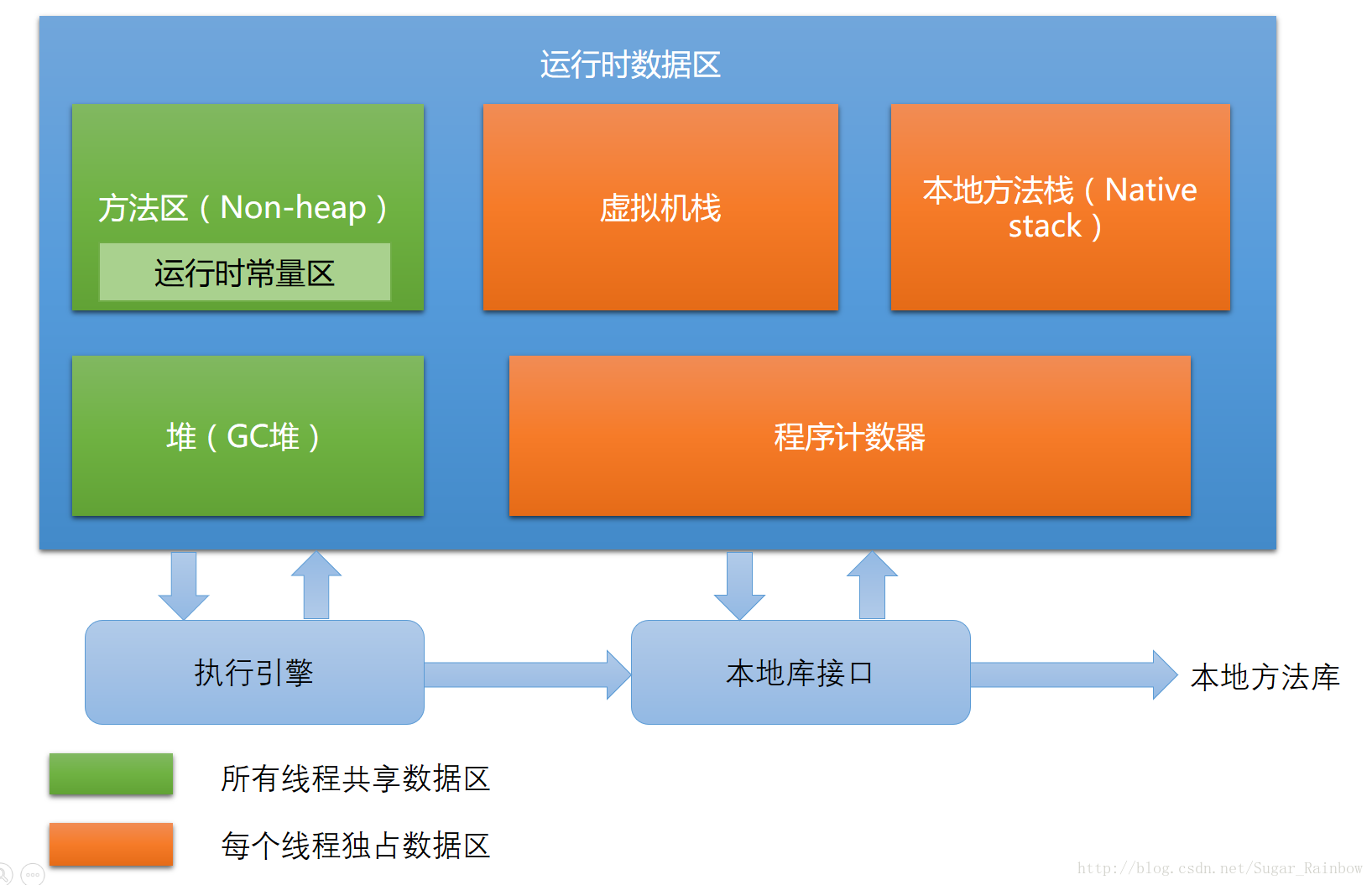
共享
- Java堆:占据了虚拟机管理内存中最大的一块(没想到吧),唯一目的就是存放对象实例(与引用是两个概念),也是垃圾回收器主要管理的地方,故又称GC堆。先开坑,后面讲垃圾回收机制再详述
- 方法区:存储加载的类信息、常量区、静态变量、JIT(即时编译器)处理后的数据等,类的信息包含类的版本、字段、方法、接口等信息。需要注意是常量池就在方法区中,也是我们这次需要关注的地方。
提一下这个Native方法
指得就是Java程序调用了非Java代码,算是一种引入其它语言程序的接口
看一下方法区
方法区因为总是存放不会轻易改变的内容,故又被称之为“永久代”。HotSpot也选择把GC分代收集扩展至方法区,但也容易遇到内存溢出问题。可以选择不实现垃圾回收,但如果回收就主要涉及常量池的回收和类的卸载(这里开坑,后续补上链接)
运行时常量池
回归本次讨论正题,主要是在看Java和C++的一些原理时,老是有“常量池”这个我一知半解的讨厌的字词,烦的一批,今天我就来探一探究竟。
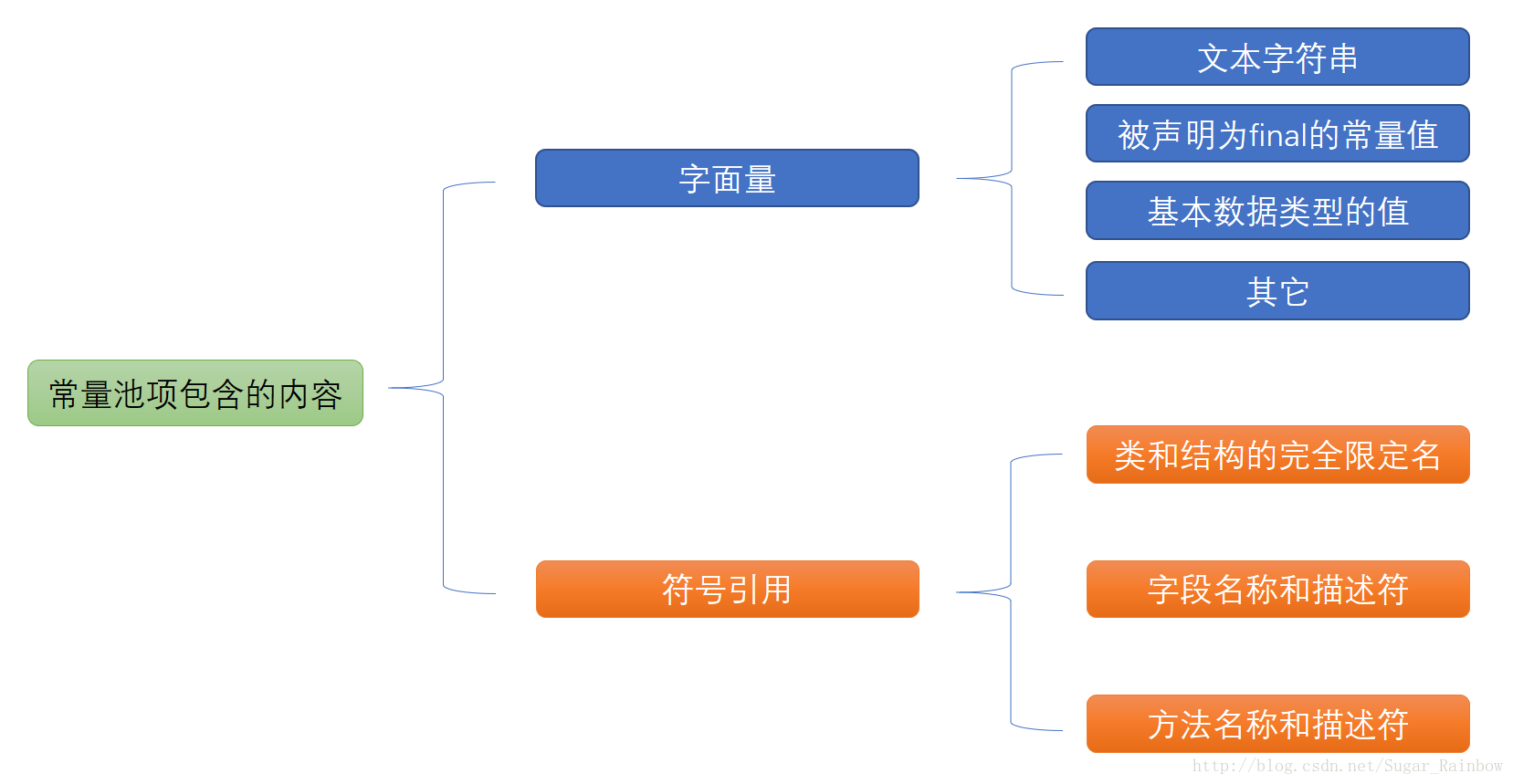
JVM中运行时常量池在方法区中,因为是建立在JDK1.7/1.8的基础上来研究这个,所以我先认为String常量池在堆中。Class文件中除了类的版本、字段、方法、接口等描述信息,还有常量池,用于存放编译期生成的各种字面量和符号引用
运行时常量池与Class文件常量池区别
- JVM对Class文件中每一部分的格式都有严格的要求,每一个字节用于存储那种数据都必须符合规范上的要求才会被虚拟机认可、装载和执行;但运行时常量池没有这些限制,除了保存Class文件中描述的符号引用,还会把翻译出来的直接引用也存储在运行时常量区
- 相较于Class文件常量池,运行时常量池更具动态性,在运行期间也可以将新的变量放入常量池中,而不是一定要在编译时确定的常量才能放入。最主要的运用便是String类的intern()方法
- 在方法区中,常量池有运行时常量池和Class文件常量池;但其中的内容是否完全不同,暂时还未得知
String.intern()
检查字符串常量池中是否存在String并返回池里的字符串引用;若池中不存在,则将其加入池中,并返回其引用。
这样做主要是为了避免在堆中不断地创建新的字符串对象
那class常量池呢?
具体的等分析到Class文件格式再来填这个坑,先来看常量池中的内容:
看一下dalao的博客Class文件中常量池详解
看一看String常量池(的特殊姿势)吧
在研究这个的时候我也上网看了别人的博客,有的人做出了实验,我也试一下
实验一
public class Test{
public static String a = "a";
public static void main(){
String b = "b";
}
}使用Java自带的反编译工具反编译一下,编译后输入javap -verbose Test.cass

可以发现两个静态String变量都放入了常量池中
实验二
public class Test2{
public static String str = "laji" + "MySQL";
public static void main(){
}
}在编译前先分析一波,按理说,既然是静态String常量,那么理应出现在常量池(Constant Pool)中,但

来看看进阶版的Test2_2
public class Test2_2{
public static void main(String[] args){
String string1 = "laji";
String string2 = "MySQL";
String string3 = string1+string2;
String string4 = string1+"C";
}
}这个的结果就更有意思了↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓ 
总商量个实验,可以看出
- 对于直接做
+运算的两个字符串(字面量)常量,并不会放入String常量池中,而是直接把运算后的结果放入常量池中 - 对于先声明的字符串字面量常量,会放入常量池,但是若使用字面量的引用进行运算就不会把运算后的结果放入常量池中了
- 总结一下就是JVM会对String常量的运算进行优化,未声明的,只放结果;已经声明的,只放声明
实验三
public class Test3{
public static void main(String[] args){
String str = "laji";
String str2 = new String("MySQL");
String str3 = new String("laji");
System.out.println(str==str3);// 运行后结果为false
}
}结果为: 
这个实验三包含了很多内容,首先是new一个对象时,明明是在堆中实例化一个对象,怎么会出现常量池中?
- 这里的
"MySQL"并不是字符串常量出现在常量池中的,而是以字面量出现的,实例化操作(new的过程)是在运行时才执行的,编译时并没有在堆中生成相应的对象 - 最后输出的结果之所以是false,就是因为str指向的”laji”是存放在常量池中的,而str3指向的”laji”是存放在堆中的,==比较的是引用(地址),当然是false
实验四
主要是为了解释一下intern()方法的用处
public class Test4{
public static void main(String[] args){
String str = "laji";
String str2 = new String("laji");
String str3 = null;
System.out.println(str==str2);// 运行后结果为false
str3 = str2.intern();
System.out.println(str==str3);// 运行后结果为true
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
显然,str3在初始化的时候是从字符串常量池中获取到的值
String常量池随JDK的改变
JDK1.7中JVM把String常量区从方法区中移除了;JDK1.8中JVM把String常量池移入了堆中,同时取消了“永久代”,改用元空间代替(Metaspace)
import java.util.ArrayList;
public class TestString {
public static void main(String[] args) {
String str = "abc";
char[] array = {'a', 'b', 'c'};
String str2 = new String(array);
//使用intern()将str2字符串内容放入常量池
str2 = str2.intern();
//这个比较用来说明字符串字面常量和我们使用intern处理后的字符串是在同一个地方
System.out.println(str == str2);
//那好,下面我们就拼命的intern吧
ArrayList<String> list = new ArrayList<String>();
for (int i = 0; i < 10000000; i++) {
String temp = String.valueOf(i).intern();
list.add(temp);
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这个实验最早是2014年有人实验过的,ta得出的结论是Exception in thread "main" java.lang.OutOfMemoryError: PermGen space,然而时至今日,我自己按照ta的代码跑了一遍,并没有出现上述的错误,虽然一段时间内内存资源占用呈上升状态。猜想:所使用JDK版本不同,对于String常量池存放的位置已经发生了改变;或者是两者的电脑硬件不同
实验出处
然后,我又看到了这个新的实验证明String常量池的位置, JVM参数设置:-Xmx5m -XX:MaxPermSize=5m
import java.util.ArrayList;
import java.util.List;
public class TestString2 {
public static void main(String[] args) {
// TODO Auto-generated method stub
List<String> list = new ArrayList<String>();
int i = 0;
while(true){
list.add(String.valueOf(i++).intern());
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
因为JDK版本不同的原因,我无法按照上述的代码得出原博文相同的结果,这是我自己运行出的结果

sun官方说明:并行/并发回收器在GC回收时间过长时会抛出OutOfMemroyError。过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存。用来避免内存过小造成应用不能正常工作。
对照着结果以及上面的博客可以得知,这显然是在堆中的垃圾回收发生了异常所致。在内存满后,会进行垃圾回收,但又会intern新的字符串到String常量池中,那么就会导致垃圾回收器一直不停的干着没有意义的活,时间一久,自然报错。同时原文中所提及的这一句话我觉得需要注意一下:
另外一点值得注意的是,虽然String.intern()的返回值永远等于字符串常量。但这并不代表在系统的每时每刻,相同的字符串的intern()返回都会是一样的(虽然在95%以上的情况下,都是相同的)。因为存在这么一种可能:在一次intern()调用之后,该字符串在某一个时刻被回收,之后,再进行一次intern()调用,那么字面量相同的字符串重新被加入常量池,但是引用位置已经不同。
综上,虽自己没有太多的明确结果证明,但是我想这已经能够印证JDK版本变化导致的String常量池位置的改变。
日常summary
这个本来是今天计划打算进行的一部分,结果好像进入牛角尖了,一定要深入一下…..,结果垃圾回收也没有看多少,明天继续。
但终于算是把这一块搞的一清二楚了,