Bart:用于生成、翻译、理解的去噪的序列到序列的预训练语言模型
Introduction
- Bart是一个结合双向(bert)和自回归(gpt)的Transformers。
- 是一种去噪自动编码器。
- 预训练有两个阶段:
- 用任意噪声函数破坏文本。
- 学习seq2seq重建原始文本
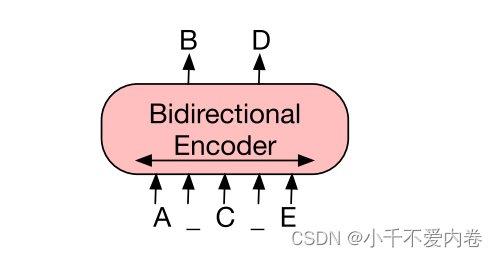
Bert:
GPT:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HUEEeXfZ-1681866662998)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20230415105612495.png)]](https://img-blog.csdnimg.cn/c5abef466f1a437fb37341949748baee.png)
Bart:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J61bSbXl-1681866662999)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20230415105623588.png)]](https://img-blog.csdnimg.cn/4ad5f7e1d96f4d8996e661d1932e7849.png)
输入通过任意噪声变换(途中包括掩码、位置变换),先输入双向编码层进行编码,然后使用自回归解码器进行解码。
噪声设置很灵活。对原始文本任意变换,包括随即洗牌原始句子的顺序;将任意长度跨度的文本(包括0长度)替换为一个单一的mask token。
Model
Architecture
使用了标准的seq2seq的Transformer结构。使用了GeLUs函数替换了ReLU函数。
基本模型版本使用6层在编码器和解码器,大模型使用12层。
该模型与Bert之间的差异:
- 解码器的每一层额外地对编码器的最后隐藏层执行交叉注意力。
- Bert具有feed-forward网络,Bart没有。
Pre-training Bart
BART的训练是通过破坏文档,然后优化重建损失-解码器的输出和原始文档之间的交叉熵。BART允许我们应用任何类型的文档损坏。在极端情况下,所有关于源的信息都丢失了,BART相当于一个语言模型。
噪声变换:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9IumgXLV-1681866662999)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20230415123852455.png)]](https://img-blog.csdnimg.cn/625190c5afa34d58979f91a555a2adec.png)
Text Infilling:不同跨度的[MASK]替换。跨度长度服从泊松分布。0-长度跨度对应于[MASK]标记的插入。
**Sentence Permutation:**基于句号将文档划分为句子,并且以随机顺序打乱这些句子。
**Document Rotation:**随机均匀地选择一个标记,并旋转文档,使其从该标记开始。此任务训练模型以识别文档的开头。
Fine-tuning BART
- 分类任务。将输入馈送到编码器和解码器中,并且将最终解码器token送到新的多类线性分类器中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6sVALNqN-1681866663002)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20230415131352874.png)]](https://img-blog.csdnimg.cn/57c33304fc3047f784d05cd81f08729a.png)
2. seq 生成任务。
解码器以自回归的方式生成输出。
思考
Bart模型融合了Bert的双向编码器和GPT的left-to-right decoder,使得该模型相比于Bert,更适用于生成的场景,相比于GPT,多了上下文语境的信息。使得该模型更加全面。同时在原始文本中加入各种噪声,提升了模型去噪的能力。