1、Embedding层理解
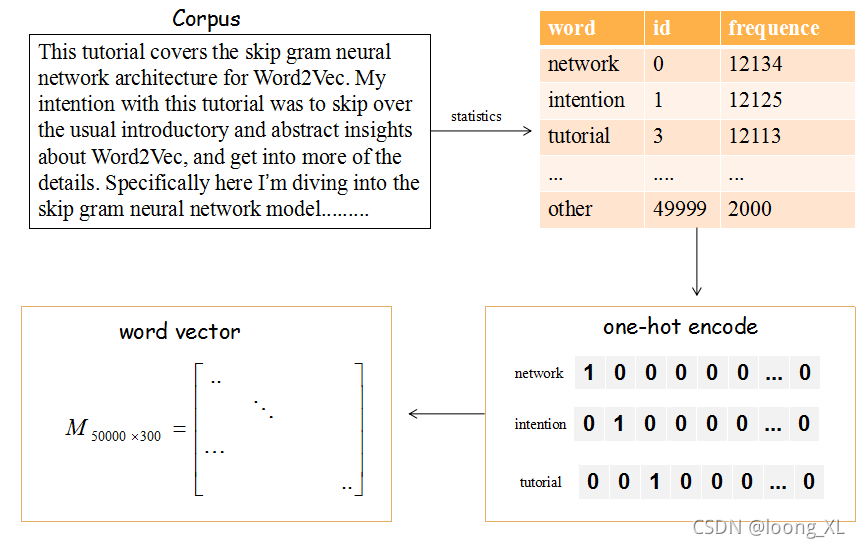
高维稀疏特征向量到低维稠密特征向量的转换;嵌入层将正整数(下标)转换为具有固定大小的向量;把一个one hot向量变为一个稠密向量
参考:https://zhuanlan.zhihu.com/p/52787964
Embedding 字面理解是 “嵌入”,实质是一种映射,从语义空间到向量空间的映射,同时尽可能在向量空间保持原样本在语义空间的关系,如语义接近的两个词汇在向量空间中的位置也比较接近。
应用:
在深度学习推荐系统中,Embedding主要的三个应用方向:
1、在深度学习网络中作为Embedding层,完成从高维稀疏特征向量到低维稠密特征向量的转换;
2、作为预训练的Embedding特征向量,与其他特征向量连接后一同输入深度学习网络进行训练;
3、通过计算用户和物品的Embedding相似度,Embedding可以直接作为推荐系统或计算广告系统的召回层或者召回方法之一。
代码简单说明
keras Embedding接口:
参考:https://keras.io/zh/layers/embeddings/
input_dim 一般大于等于词表数

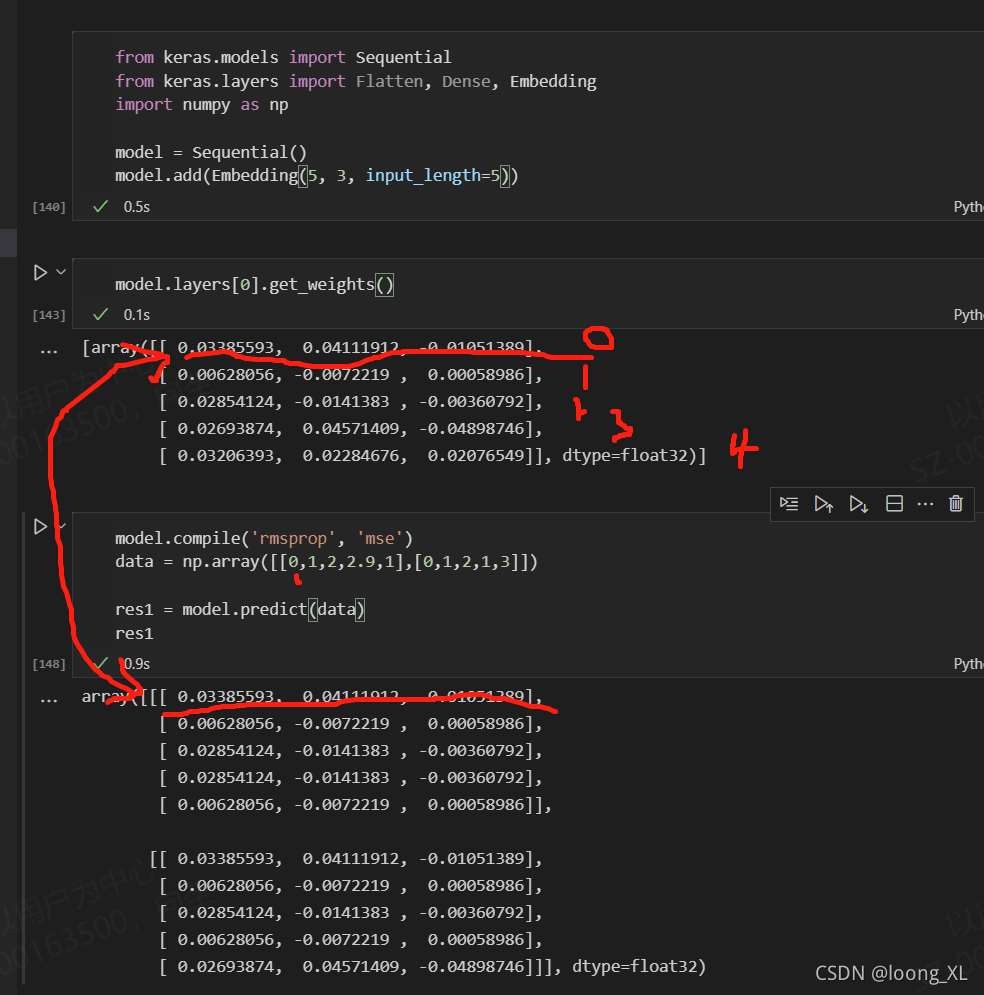
Embedding(4, 3, input_length=5) :
1)4是词表去重后的总数量,例如这里np.array([[0,1,2,1,1],[0,1,2,1,3]])共0、1、2、3四个数字,所以词表数为4
2)3是输出单个词向量维度
3)5是input_length输入的长度np.array([[0,1,2,1,1],[0,1,2,1,3]])中[0,1,2,1,1]长度为5
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding
import numpy as np
model = Sequential()
model.add(Embedding(4, 3, input_length=5))
model.compile('rmsprop', 'mse')
data = np.array([[0,1,2,1,1],[0,1,2,1,3]])
res1 = model.predict(data)
res1
print(model.input_shape)
print(model.output_shape)
'''
(None, 5) #其中 None的取值是batch_size
(None, 5, 3)
input_shape:函数输入,尺寸为(batch_size, 5)的2D张量(矩阵的意思)
output_shape:函数输出,尺寸为(batch_size, 5,3)的3D张量
'''
特别说明:
1)Embedding(4, 3, input_length=5) 会随机初始化一个词表大小的4*3维矩阵
2)data = np.array([[0,1,2,1,1],[0,1,2,1,3]])里的0、1、2、3、4获取上面词表里对应取数,比如0会去取上面标记数字0行,其他类似;如果有小数点会直接取整2.3、2.9都是取2然后去取上面标记数字2行
3)这些随机初始化的Embedding作为神经网络输入会随着网络的训练而变化
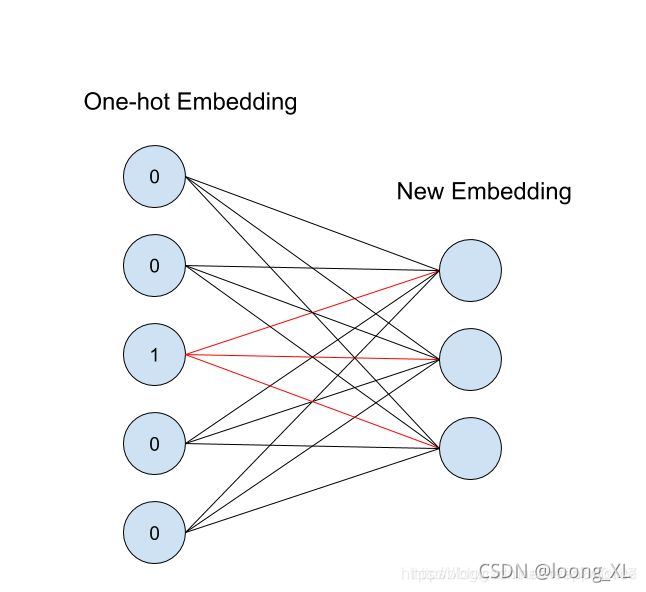
再深入理解
参考:https://spaces.ac.cn/archives/4122
字向量就是one hot的全连接层的参数;下2图红线的参数就是对应的参数权重

2、 Embedding层中使用 预训练词向量
weights=[embeddings_matrix], # 重点:预训练的词向量系数
trainable=False # 是否在 训练的过程中 更新词向量
from keras.layers import Embedding
EMBEDDING_DIM = 100 #词向量维度
embedding_layer = Embedding(input_dim = len(embeddings_matrix), # 字典长度
EMBEDDING_DIM, # 词向量 长度(100)
weights=[embeddings_matrix], # 重点:预训练的词向量系数
input_length=MAX_SEQUENCE_LENGTH, # 每句话的 最大长度(必须padding)
trainable=False # 是否在 训练的过程中 更新词向量
)
其实就是给赋值下one hot全连接边的权重就是字向量的embedding;后续还是对应查表取值,后续训练也可以自定义权重是否被训练更新
