模型效果主要从两个方面衡量:
1.模型本身的效果,主要评价指标包括区分度、准确度等。
2.模型稳定性,主要评价指标包括PSI和CSI等。
之前阐述了模型本身的评价指标:混淆矩阵、F1值、KS曲线、count_table和ROC曲线AUC面积,本文介绍模型稳定性指标PSI。
一、详细介绍PSI
1 什么是PSI
PSI(Population Stability Index):群体稳定性指标,是通过对比历史样本分布和当前样本分布的波动,来衡量数据的稳定性。通常包括特征PSI和模型PSI。特征PSI关注特征的取值是否随时间推移发生大的波动,可用于模型训练和上线前特征选择、变量监控等。模型PSI关注训练集和验证集,以及模型上线部署后,模型的分布是否稳定。
为什么要关注模型的稳定性?
在风控建模中的IV和WOE一文中我们提到,可以用逻辑回归区分好坏客户的前提假设是“历史样本和未来样本服从同一总体分布”。模型通过从过去的数据中学习样本的分布特征,从而可以对现在的数据进行处理,判别出客户未来变坏的可能性。训练集和测试集源自同一时间段的样本分布,而验证集的分布与训练集并非总是一致的。而且,在模型训练过程中,虽然有测试集衡量模型的稳定性,但仍不能排除模型存在过拟合的情况。比如模型在产品运营过程中由于外界环境的变化(疫情)、业务背景的变化(政策发布、市场异常波动等)、模型的假设以及样本的处理手段,多少会使得建模样本与实际样本分布发生一定程度的偏移。这些原因都可能导致模型在面对近期样本时,没有那么稳定。所以我们要关注模型的稳定性。
2 PSI计算公式
不管是变量PSI还是模型PSI,其底层逻辑是一样的。主要是量化评估观察样本(actual)和开发样本(expect)的分布差异。首先将两个样本按照一定的规则(等宽、等频)分为n组,然后对比分布的相似性。
即:PSI=SUM[(观察样本占比-开发样本占比)*ln(观察样本占比/开发样本占比)]
对数学比较敏感的同学应该可以发现观察样本和开发样本调换一下位置PSI的公式仍然成立。下面是按等宽计算PSI的具体实例:
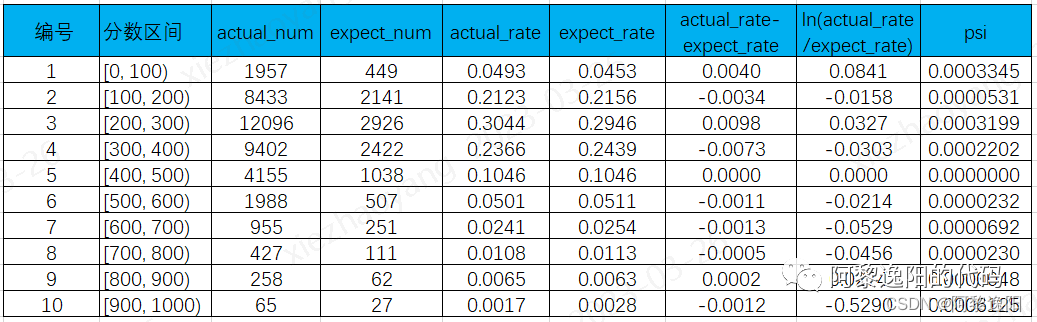
3 PSI阈值衡量标准
两个样本间的差异越小,PSI值越小,代表越稳定,一般来说,
PSI<0.1,样本分布有微小变化,变量较稳定可以入模,或模型较稳定可以不做调整。
0.1≤PSI<0.2,样本分布有变化,变量有波动谨慎入模,或模型有波动,需检查变化原因,加强监控频率。
PSI>0.2,样本分布有显著变化,变量不建议入模,或需调整模型。
二、用Python如何计算PSI
接下来看下计算PSI的具体代码和调用语句:
import pandas as pd
import numpy as np
def cal_psi(actual, expect, bins=10):
"""
功能: 计算PSI值,并输出实际和预期占比分布
:param actual: Array或series,代表真实数据,如测试集模型得分 # test
:param expect: Array或series,代表期望数据,如训练集模型得分 # base
:param bins: 分段数
:return:
psi: float,PSI值
psi_df:DataFrame
"""
#分箱
expect_min = expect.min() # 实际中的最小值
expect_max = expect.max() # 实际中的最大值
binlen = (expect_max - expect_min) / bins #箱体宽度
cuts = [expect_min + i * binlen for i in range(1, bins)] #设定切点
cuts.insert(0, -float("inf")) #在切点左侧加入-float("inf")扩展左边界
cuts.append(float("inf")) #在切点右侧加入float("inf")扩展右边界
#箱内计数,合并为一个数据框
expect_cuts = np.histogram(expect, bins=cuts)[0]#将expect等宽分箱并计数
actual_cuts = np.histogram(actual, bins=cuts)[0]#将actual按expect的分组等宽分箱并计数
actual_df = pd.DataFrame(actual_cuts,columns=['actual'])
expect_df = pd.DataFrame(expect_cuts,columns=['expect'])
psi_df = pd.merge(expect_df,actual_df,right_index=True,left_index=True)
#计算箱内频数
psi_df['actual_rate'] = (psi_df['actual'] + 1) / psi_df['actual'].sum()#计算占比,分子加1,防止计算PSI时分子分母为0
psi_df['expect_rate'] = (psi_df['expect'] + 1) / psi_df['expect'].sum()
#计算每个箱内的数值
psi_df['psi'] = (psi_df['actual_rate'] - psi_df['expect_rate']) * np.log(psi_df['actual_rate'] / psi_df['expect_rate'])
#得到PSI
psi = psi_df['psi'].sum()
return psi, psi_df
cal_psi( train_date['predict'], test_date['predict'])
train_date['predict']:模型训练集预测值或预测分数。
train_date['y']:模型测试集预测值或预测分数。
30:分的组数,可以自己随意定义。
得到结果如下:
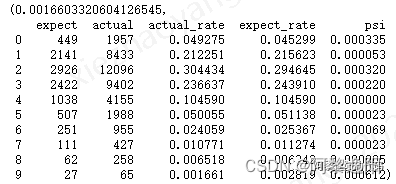
可以发现,和手动计算的结果一致。至此,PSI介绍和Python实现实例已讲解完毕,感兴趣的同学可以自己尝试实现一下。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
用Python绘制520永恒心动
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
【Python】情人节表白烟花(带声音和文字)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)