1 GPT-2 模型结构
GPT-2的整体结构如下图,GPT-2是以Transformer为基础构建的,使用字节对编码的方法进行数据预处理,通过预测下一个词任务进行预训练的语言模型。
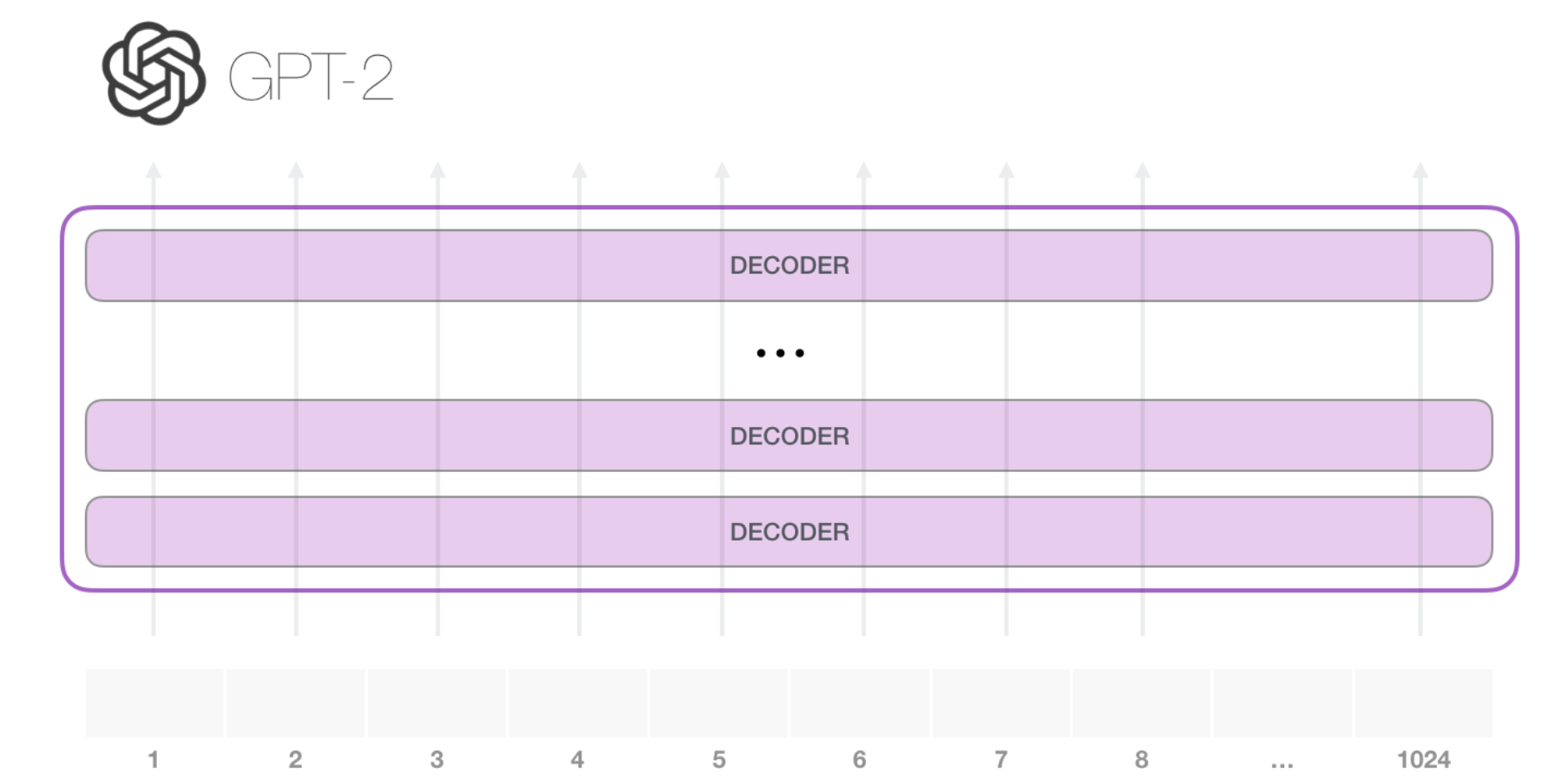
1.1 GPT-2 功能简介
GPT-2 就是一个语言模型,能够根据上文预测下一个单词,所以它就可以利用预训练已经学到的知识来生成文本,如生成新闻。也可以使用另一些数据进行微调,生成有特定格式或者主题的文本,如诗歌、戏剧。
2 手动加载GPT-2模型并实现语句与完整句子预测
使用GPT-2模型配套的PreTrainedTokenizer类,所需要加载的词表文件比BERT模型多了一个merges文件。
2.1 代码实现:手动加载GPT-2模型并实现下一个单词预测---GPT2_make.py(第1部分)
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 案例描述:Transformers库中的GPT-2模型,并用它实现下一词预测功能,即预测一个未完成句子的下一个可能出现的单词。
# 下一词预测任务是一个常见的任务,在Transformers库中有很多模型都可以实现该任务。也可以使用BERT模型来实现。选用GPT-2模型,主要在于介绍手动加载多词表文件的特殊方式。
# 1.1 加载词表文件
# 自动加载预训练模型(权重)
# tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 手动加载词表文件:gpt2-merges.txt gpt2-vocab.json。
# from_pretrained方法是支持从本地载入多个词表文件的,但对载入的词表文件名称有特殊的要求:该文件名称必须按照源码文件tokenization_gpt2.py的VOCAB_FILES_NAMES字典对象中定义的名字来命名。
# 故使用from_pretrained方法,必须对已经下载好的词表文件进行改名将/gpt2/gpt2-vocab.json和/gpt2/gpt2-merges.txt这两个文件,分别改名为“gpt2/vocab.json和/gpt2/merges.txt
tokenizer = GPT2Tokenizer.from_pretrained(r'./models/gpt2') # 自动加载改名后的文件
# 编码输入
indexed_tokens = tokenizer.encode("Who is Li BiGor ? Li BiGor is a")
print("输入语句为:",tokenizer.decode(indexed_tokens))
tokens_tensor = torch.tensor([indexed_tokens]) # 将输入语句转换为张量
# 自动加载预训练模型(权重)
# model = GPT2LMHeadModel.from_pretrained('gpt2')
# 手动加载:配置文件gpt2-config.json 与 权重文件pt2-pytorch_model.bin
model = GPT2LMHeadModel.from_pretrained('./models/gpt2/gpt2-pytorch_model.bin',config='./models/gpt2/gpt2-config.json')
# 将模型设置为评估模式
model.eval()
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokens_tensor = tokens_tensor.to(DEVICE)
model.to(DEVICE)
# 预测所有标记
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
# 得到预测的下一词
predicted_index = torch.argmax(predictions[0, -1, :]).item()
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
print("输出语句为:",predicted_text) # GPT-2模型没有为输入文本添加特殊词。
# 输出:Who is Li BiGor? Li BiGor is a Chinese
2.2 代码实现:手动加载GPT-2模型并实现完整句子预测---GPT2_make.py(第2部分)
# 案例描述:Transformers库中的GPT-2模型,通过循环生成下一词,实现将一句话补充完整。
# 1.2 生成一段完整的话 这里有BUg 暂不会改
stopids = tokenizer.convert_tokens_to_ids(["."])[0] # 定义结束符
# 在循环调用模型预测功能时,使用了模型的past功能。该功能以使模型进入连续预测状态,即在前面预测结果的基础之上进行下一词预测,而不需要在每预测时,对所有句子进行重新处理。
# past功能是使用预训练模型时很常用的功能,在Transformers库中,凡是带有下一词预测功能的预训练模型(如GPT,XLNet,CTRL等)都有这个功能。
# 但并不是所有模型的past功能都是通过past参数进行设置的,有的模型虽然使用的参数名称是mems,但作用与pat参数一样。
past = None # 定义模型参数
for i in range(100): # 循环100次
with torch.no_grad():
output, past = model(tokens_tensor, past=past) # 预测下一次
token = torch.argmax(output[..., -1, :])
indexed_tokens += [token.tolist()] # 将预测结果收集
if stopids == token.tolist(): # 当预测出句号时,终止预测。
break
tokens_tensor = token.unsqueeze(0) # 定义下一次预测的输入张量
sequence = tokenizer.decode(indexed_tokens) # 进行字符串编码
print(sequence)3 GPT2_make.py(汇总)
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# 案例描述:Transformers库中的GPT-2模型,并用它实现下一词预测功能,即预测一个未完成句子的下一个可能出现的单词。
# 下一词预测任务是一个常见的任务,在Transformers库中有很多模型都可以实现该任务。也可以使用BERT模型来实现。选用GPT-2模型,主要在于介绍手动加载多词表文件的特殊方式。
# 1.1 加载词表文件
# 自动加载预训练模型(权重)
# tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# 手动加载词表文件:gpt2-merges.txt gpt2-vocab.json。
# from_pretrained方法是支持从本地载入多个词表文件的,但对载入的词表文件名称有特殊的要求:该文件名称必须按照源码文件tokenization_gpt2.py的VOCAB_FILES_NAMES字典对象中定义的名字来命名。
# 故使用from_pretrained方法,必须对已经下载好的词表文件进行改名将/gpt2/gpt2-vocab.json和/gpt2/gpt2-merges.txt这两个文件,分别改名为“gpt2/vocab.json和/gpt2/merges.txt
tokenizer = GPT2Tokenizer.from_pretrained(r'./models/gpt2') # 自动加载改名后的文件
# 编码输入
indexed_tokens = tokenizer.encode("Who is Li BiGor ? Li BiGor is a")
print("输入语句为:",tokenizer.decode(indexed_tokens))
tokens_tensor = torch.tensor([indexed_tokens]) # 将输入语句转换为张量
# 自动加载预训练模型(权重)
# model = GPT2LMHeadModel.from_pretrained('gpt2')
# 手动加载:配置文件gpt2-config.json 与 权重文件pt2-pytorch_model.bin
model = GPT2LMHeadModel.from_pretrained('./models/gpt2/gpt2-pytorch_model.bin',config='./models/gpt2/gpt2-config.json')
# 将模型设置为评估模式
model.eval()
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokens_tensor = tokens_tensor.to(DEVICE)
model.to(DEVICE)
# 预测所有标记
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
# 得到预测的下一词
predicted_index = torch.argmax(predictions[0, -1, :]).item()
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
print("输出语句为:",predicted_text) # GPT-2模型没有为输入文本添加特殊词。
# 输出:Who is Li BiGor? Li BiGor is a Chinese
# 案例描述:Transformers库中的GPT-2模型,通过循环生成下一词,实现将一句话补充完整。
# 1.2 生成一段完整的话 这里有BUg 暂不会改
stopids = tokenizer.convert_tokens_to_ids(["."])[0] # 定义结束符
# 在循环调用模型预测功能时,使用了模型的past功能。该功能以使模型进入连续预测状态,即在前面预测结果的基础之上进行下一词预测,而不需要在每预测时,对所有句子进行重新处理。
# past功能是使用预训练模型时很常用的功能,在Transformers库中,凡是带有下一词预测功能的预训练模型(如GPT,XLNet,CTRL等)都有这个功能。
# 但并不是所有模型的past功能都是通过past参数进行设置的,有的模型虽然使用的参数名称是mems,但作用与pat参数一样。
past = None # 定义模型参数
for i in range(100): # 循环100次
with torch.no_grad():
output, past = model(tokens_tensor, past=past) # 预测下一次
token = torch.argmax(output[..., -1, :])
indexed_tokens += [token.tolist()] # 将预测结果收集
if stopids == token.tolist(): # 当预测出句号时,终止预测。
break
tokens_tensor = token.unsqueeze(0) # 定义下一次预测的输入张量
sequence = tokenizer.decode(indexed_tokens) # 进行字符串编码
print(sequence)