一、安装scala
传输scala文件到Ubuntu操作系统

因为我们已经上传过jdk了,所以操作方法相同。今后的上传只需要打开WinSCP将文件上传即可
解压scala-2.11.8.tgz文件,使用以下代码
tar -zxf scala-2.11.8.tgz 
根据 ~/.bashrc文件所示,我们需要将scala文件放到 /usr/local中,并且将此文件改名为scala。
则需要使用以下代码
mv scala-2.11.8 /scala
sudo mv scala /usr/local/ 
因为我们已经编辑过 ~/.bashrc文件,所以重新使用 source 命令刷新它即可。
使用以下代码即可刷新 ~/.bashrc文件并查看scala版本
source ~/.bashrc
scala -version 
如何使用和退出scala
安装好scala后在命令行界面直接输入scala则可以进入scala交互式界面进行使用
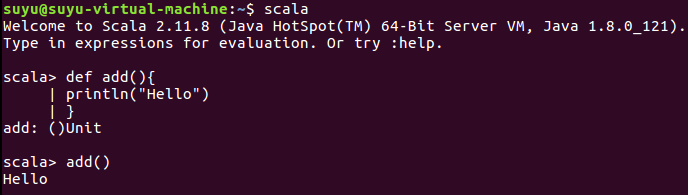
2.退出scala使用 :quit 即可退出,注意在Linux操作系统中请安全退出scala,否则有可能再次使用时会报错

二、安装Hadoop完全分布式环境
部署:我们采用Ubuntu作为主节点master用于存储Resource Manager 与NameNode 与Secondarg Namenode,采用centos 7作为从节点slave1存储DataNode。所以进行以下操作。

集群规划: Hadoop一定有的是hdfs与yarn,首先要配置IP地址,要在同一网段。

最小化安装一个CentOS操作系统(见以前的博客,此处不过多的赘述)
集群规划

确定NAT模式网段

虚拟机网段为192.168.44.0,则我们需要进入到Linux系统中将节点网络都设置成此网段
修改Ubuntu操作系统网络连接属性
使用 sudo vim /etc/network/interfaces 编辑文件加入下列代码
sudo vim /etc/network/interfaces
auto ens33
iface ens33 inet static
address 192.168.44.131
netmask 255.255.255.0
gateway 192.168.44.2 
使用 sudo vim /etc/resolv.conf 修改文件加入以下代码
sudo vim /etc/resolv.conf
name server 8.8.8.8
将网络设置成为自动连接模式
使用 sudo vim /etc/NetworkManager/NetworkManager.conf 编辑下图中变量
将 managed 改为 true
sudo vim /etc/NetworkManager/NetworkManager.conf
managed=true 
修改节点名称与对应关系
使用 sudo vim /etc/hostname 修改Ubuntu节点为名称为Master
sudo vim /etc/hostname

注意,节点名称重启后生效
使用 sudo vim /etc/hosts 修改节点对应关系
sudo vim /etc/hosts

重启网络
使用 sudo /etc/init.d/networking restart
sudo /etc/init.d/networking restart
2.修改CentOS操作系统网络属性
使用 vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改文件如下图
添加的内容有
vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.44.132
NETMASK=255.255.255.0
GATEWAY=192.168.44.2
DNS1=8.8.8.8
修改的内容有:
BOOTPROTO=static
ONBOOT=yes
修改节点名称与对应关系
使用 vi /etc/hostname 修改CentOS节点为名称为slave1
vi /etc/hostname

使用 vi /etc/hosts 修改节点为修改节点对应关系
vi /etc/hosts 
重启网络
service network restart 
测试是否可以连接外网 ping www.baidu.com
测试是否可以连接Ubuntu操作系统 ping 192.168.44.130
ping www.baidu.com
ping 192.168.44.130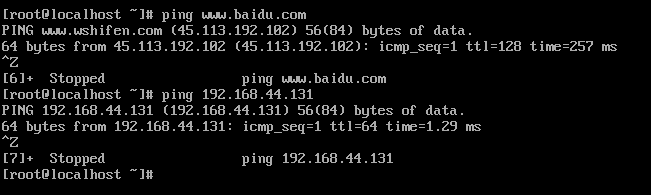
完成完全分布式Hadoop的搭建
任务解析:
1. 配置免密登录
2. 为CentOS系统安装jdk并配置环境变量
3、为Ubuntu和CentOS系统安装hadoop并配置环境变量
注意:
Ubuntu的环境变量文件为: ~/.bashrc
CentOS的环境变量文件为: /etc/profile
4. 修改hadoop配置文件并启动hadoop