本文实现三台服务器进行完全分布式Hadoop集群安装
IP |
主机名 |
功能角色 |
10.49.25.220 |
master(主人) |
namenode(控制节点)、JobTracker(工作分配) |
10.49.25.222 |
slaver1(奴隶) |
datanode(数据节点)、TaskTracker(任务执行) |
10.49.25.223 |
slaver2(奴隶) |
datanode(数据节点)、TaskTracker(任务执行) |
Hadoop完全分布式的安装需要以下几个过程:
(1)为防止权限不够,三台机器均开启root登录。
(2)为三台机器分配IP地址及相应的角色。
(3)对三台机器进行jdk安装并配置环境变量。
(4)对三台机器进行ssh(安全外壳协议)远程无密码登录安装配置。
(5)进行Hadoop集群完全分布式的安装配置。
下面对以上过程进行详细叙述。
1. 三台机器开启root 登陆
针对ubuntu-14.04默认是不开启root用户登录的。
想要在登录界面使用root身份登录,可编辑/etc/lightdm/目录下的lightdm.conf文件,如没有此文件,直接创建
vi /etc/lightdm/lightdm.conf
文件内容最终为:
[SeatDefaults]
#启动后以root身份自动登录
autologin-user=root
greeter-session=unity-greeter
user-session=ubuntu
#手工输入登陆系统的用户名和密码
greeter-show-manual-login=true
#禁用guest用户
allow-guest=false
修改完之后执行reboot命令重启Ubuntu生效
sudo passwd root
根据提示输入root账号密码。
2. 在三台主机上分别设置/etc/hosts及/etc/hostname
hosts文件用于定义主机名与IP地址之间的对应关系(三台主机配置相同)。
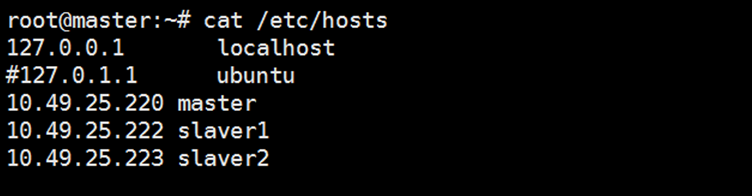
hostname这个文件用于定义Ubuntu的主机名(不同ip对应的名字不同10.49.25.220对应master,10.49.25.222对应slaver1,10.49.25.223对应slaver2)。
然后重启你的三台服务器
3.在三台主机上安装 jdk 1.7
在JAVA 官网上下载jdk 1.7 的安装包,linux 版本的后缀为“.tar.gz” . 通过Xshell 上传到三台服务器上。解压缩,修改文件名为jdk1.7.0_67
配置环境变量 vim /etc/profile
export JAVA_HOME=/root/jdk1.7.0_67
export JRE_HOME=/root/jdk1.7.0_67/jre
export PATH=$PATH:/root/jdk1.7.0_67/bin
export CLASSPATH=./:/root/jdk1.7.0_67/lib
4. 安装SSH 配置免密钥登录
安装SSH: apt-get install ssh
等待后查看是否已经开启:ps -e | grep ssh
结果:
779 ? 00:00:00 sshd
29037 ? 00:00:00 sshd
29537 ? 00:00:00 sshd
生成密钥并配置SSH免密码登录本机
执行以下命令,生成密钥对,并把公钥文件写入授权文件中
ssh-keygen -t dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后将授权文件复制到slaver1主机中,输入命令:
scp authorized_keys slaver1:~/.ssh
然后在slave1机器中,使用同样命令生成密钥对,将公钥写入授权文件中。让后将slaver1主机中的授权文件复制到slaver2中,使用同样命令生成密钥对,将公钥写入授权文件中。这样就完成了同一个授权文件拥有三个公钥。最后将此时(slaver2中的authorized_keys)的授权文件分别复制到master主机、slaver1主机中,这样就完成了,ssh免密登录验证工作。

为了防止防火墙禁止一些端口号,三台机器应使用
关闭防火墙命令:ufw disable
重启三台机器,防火墙关闭命令才能生效,重启后后查看是否可以从master主机免密码登录slaver,输入命令:
ssh slaver1
ssh slaver2
5. 进行Hadoop 完全分布式安装
将下载的hadoop-2.6.5.tar.gz解压至/root下,并更改名字为hadoop
三台hadoop文件配置相同,所以配置完一台后,可以把整个hadoop复制过去就行了,现在开始配置master主机的hadoop文件。
(1) hadoop-env.sh: cat hadoop/etc/hadoop/hadoop-env.sh
配置Java 环境: export JAVA_HOME=/root/jdk1.7.0_67
(2) yarn-env.sh :cat hadoop/etc/hadoop/yarn-env.sh
配置Java 环境: export JAVA_HOME=/root/jdk1.7.0_67
(3) slaves(保存所有slave节点)
root@master:~# cat hadoop/etc/hadoop/slaves
slaver1
slaver2
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hdfs_all/tmp</value>
</property>
</configuration>
(5) hdfs-site.xml 这里配置的是hdfs 的本地库路径,可自定义
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hdfs_all/dfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/root/hdfs_all/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
(6)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
(7) yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
上面配置完毕后,基本上完成了90%的工作,剩下的就是复制。我们可以把整个hadoop复制过去使用命令如下:
scp -r /root/u slaver1:/root/
scp -r /root/u slaver2:/root/
为方便用户和系统管理使用hadoop、hdfs相关命令,需要在/etc/environment配置系统环境变量,使用命令:vim/etc/environment
配置内容为hadoop目录下的bin、sbin路径,具体如下
root@master:~# cat /etc/environment
PATH="/root/jdk1.7.0_67/bin:/usr/local/sbin:/usr/local/bin:/root/hadoop/bin:/root/hadoop/sbin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games"
添加完后执行生效命令:source /etc/environment
下面要做的就是启动验证,建议在验证前,把以上三台机器重启,使其相关配置生效。
6.启动验证
在master节点上进行格式化namenode:
命令:hadoop namenode -format
在master节点上进行启动hdfs:
start-all.sh
然后使用jps查看进程
分别是4(master)+3(slaver1)+3 (slaver2)进程
访问查看能否成功