一、存储系统可靠性的影响因素
单机存储系统包括存储硬件和存储软件。存储硬件又包含存储介质、存储控制器、设备固件;存储软件栈层次则更为复杂,以Linux为例包括:存储设备驱动层、 块设备层(Block Layer)、可选的虚拟块设备层(Device Mapper)、文件系统层等。如下图所示,各个层次可进一步细分,整个存储栈非常复杂庞大。存储系统的可靠性依赖各层硬件和软件的可用性,另一方面也包括存储系统中数据的可靠性。
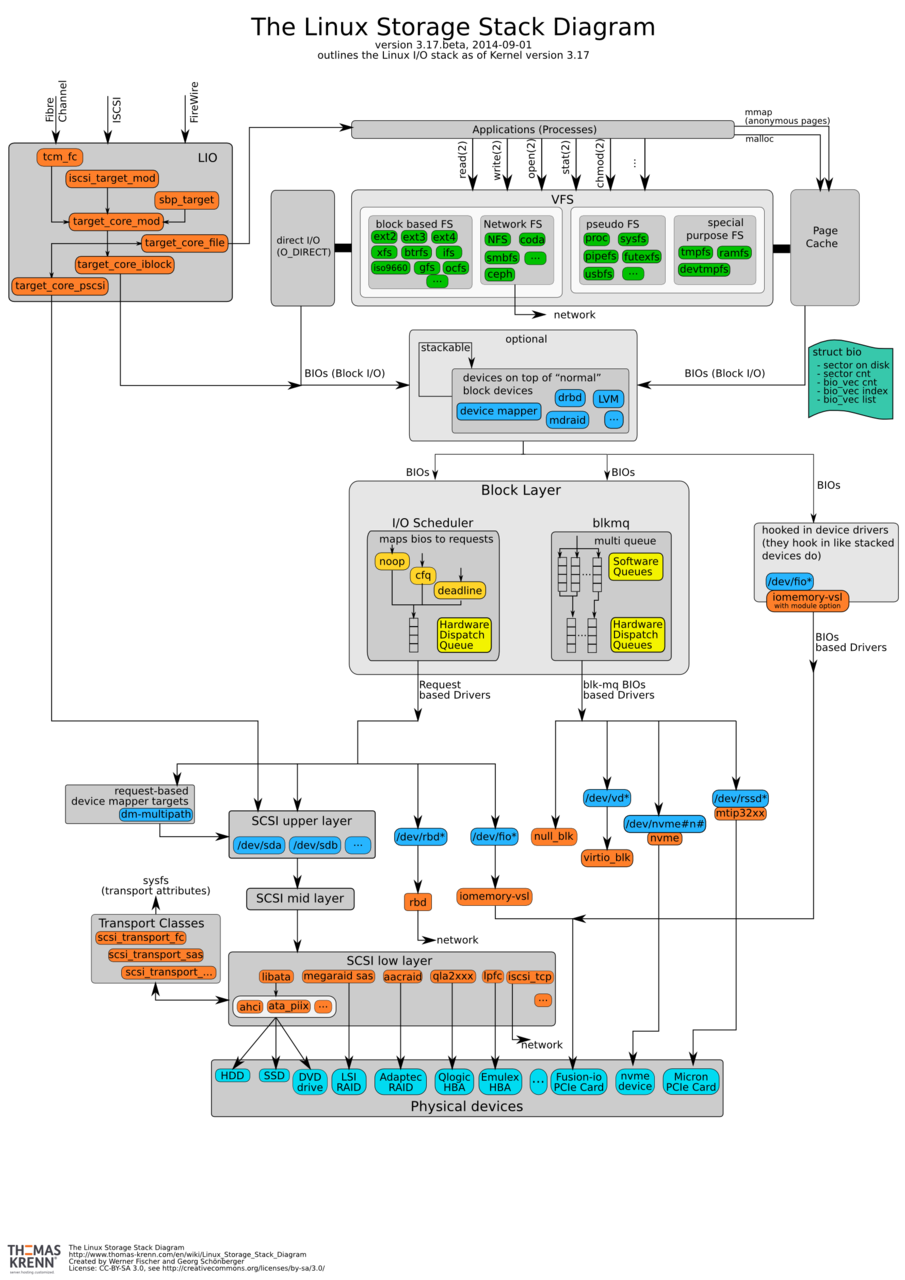
图1 Linux存储栈层次 [1]
存储系统硬件和软件的可用性(Availability)是指其可正常运行、长时间无故障的能力。存储器件的控制器损坏(如:磁盘磁头的机械故障)就属于不可用的范畴,一些存储软件缺陷(如:异常死锁)也可导致系统不可用。
数据的可靠性是指在数据的生命周期内,所有数据都是完全的、一致的和准确的程度。影响数据可靠性的原因有很多方面:
存储介质在极端环境下数据保存周期缩短可能导致数据丢失,如:1)磁盘在极强的磁场环境下会消磁导致数据丢失,2)NAND闪存在高温环境下长时间断电放置数据保存周期会大幅缩短(如图2所示,断电状态30摄氏度下可保存52周,40摄氏度下仅可保存14周)
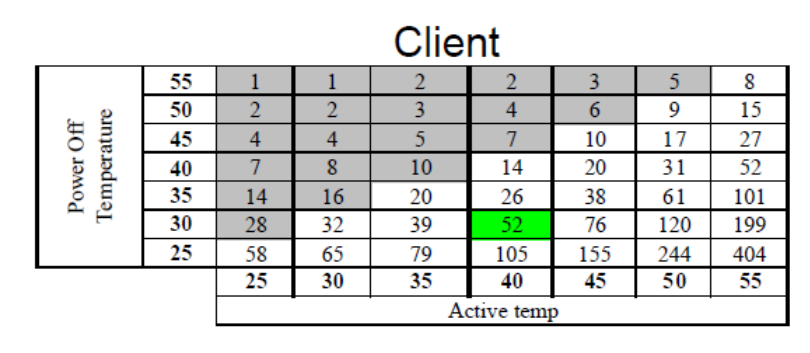
图2 JEDEC标准下NAND闪存在不同环境温度下的数据保存周期(单位:周)[2]
存储器件中电子元件的比特翻转(Bit Flip)导致数据错误,如:寄存器、SRAM、NAND FLASH等因供电电压不稳导致的比特翻转,甚至宇宙射线也可能造成比特翻转,当然这是极小概率的情况
存储系统外部的不可预期数据破坏,如:1)硬盘上存在多个数据分区,裸写的分区偏移地址计算错误导致其他分区的数据被覆盖;2)Linux内核中某个模块存在踩内存异常,使得页缓存(Page Cache)中的数据被破坏,异常数据最终持久化到存储中
存储软硬件的设计缺陷导致数据异常,如:1)固件在异常掉电等特殊情况下存在映射表更新异常,2)文件系统在特殊场景的逻辑异常导致数据未能正常更新或被错误的覆盖等
二、存储可靠性相关技术介绍
存储可靠性相关的技术比较多:从单条数据粒度可以做数据校验,从设备层面可以做冗余容错,从系统层面可以做快照、备份已经CDP(连续数据保护),针对存储系统中某一个组件、模块的特点还有一些针对性的保护方案和技术。这其中有些技术是数据保护层面的,有些是同时考虑系统可用性层面和数据保护的。下面我们一一展开介绍。
2.1数据校验
数据校验是为保证数据的完整性进行的一种验证操作。通常用一种指定的算法对原始数据计算出的一个校验值,接收方用同样的算法计算一次校验值,如果两次计算得到的检验值相同,则说明数据是完整的。有些校验算法还有更近一步的纠错能力。常用的数据校验算法包括:
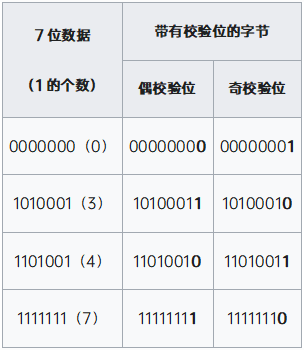
奇偶校验 根据被传输的一组二进制代码的数位中“1”的个数是奇数或偶数来进行校验。采用奇数的称为奇校验,反之,称为偶校验。采用何种校验是事先规定好的。如1010001有3个1,奇校验需保证1的个数为奇数在尾部添加校验位0,即:10100010。对应的,偶校验结果位:10100011。奇偶校验可以检测出一bit错误。(参考表1 )
表1 奇偶校验示例
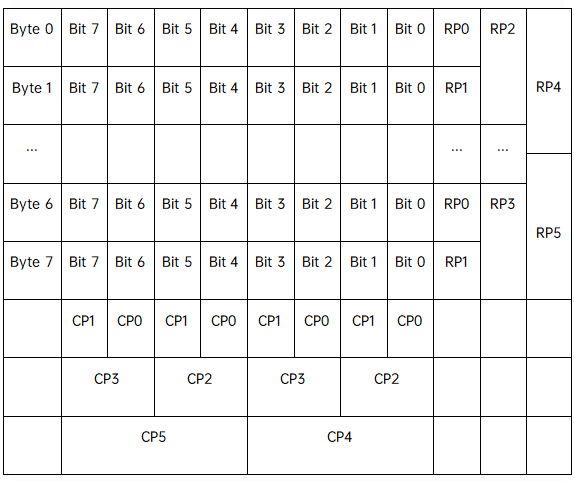
ECC校验 全称为Error Checking and Correcting, 顾名思义它不仅可以发现错误还可以纠正错误。ECC校验广泛应用于DRAM和NAND闪存等设备中。ECC码将信息进行8比特位的编码,下表是一个8字节信息的ECC编码示例,校验信息分为行校验和列校验。其中列校验CP0是对所有8个字节的Bit 0,2,4,6的所有位做异或得到,CP1是对Bit 1,3,5,7采用同样方式做校验。CP2是针对Bit 0,1,4,5校验,CP3是针对Bit 2,3,6,7。CP4是针对Bit 0,1,2,3校验,CP5是针对Bit 4,5,6,7。行校验的RP0 - RP5同理。在检测时对数据做同样的校验,经过对比原校验值即可判断数据是否出错及出错位置。ECC校验能纠正1 Bit错误,检测2 Bit错误。
表2 ECC校验说明
CRC校验 全称为Cyclic Redundancy Check,循环冗余校验。一些文件系统的元数据校验中会使用CRC。CRC具备检错和纠错的能力(其由信息码n位和校验码k位构成),其校验可以理解为一种二进制模2算法,它是一定能被生成多项式整除的,如果除不尽,那就说明传输出现了错误。这里举例说明:
先假定一个多项式,用于计算校验码,设多项式为G(x)=x^2+x+1(G(x)是一个k+1位的二进制数),其二进制表示为111,共3位,其中k=2;
假设要发送数据序列的二进制为10111(即f(x)),共5位;
多项式的位数为3,则在要发送的数据后面加上3-1个位的0(生成f(x)*(x^k)),二进制表示为1011100,共7位;
用生成多项式的二进制表示111去除乘积1011100,按模2算法求得余数序列为01(注意余数一定是k位的,如果位数不够,需要在高位补0;模2算法是不向上借位的,相当于异或);
将余数添加到要发送的数据后面,得到真正要发送的数据的比特流:1011101,其中前5位为原始数据,后2位为CRC校验码;
接收端在接收到带CRC校验码的数据后,如果数据在传输过程中没有出错,将一定能够被相同的生成多项式G(x)除尽,如果数据在传输中出现错误,生成多项式G(x)去除后得到的结果肯定不为0。
2.2磁盘冗余阵列(RAID)
全称是Redundant Array of Independent Disks,广泛应用于存储服务器上,SSD闪存内部的多个闪存颗粒(die)上也采用了RAID技术容错。RAID有一系列的阵列配置用于实现不同的性能和可靠性需求。常用的配置有:
RAID0 亦称为数据条带化(data striping)。它将两个以上的磁盘并联起来,成为一个大容量的磁盘。数据分段后分散存储在这些磁盘中,读写可并行处理。在所有的RAID级别中,RAID 0速度最快但不具备容错能力。
RAID1 由两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,与RAID 0相同。另外写入速度有微小的降低。只要一个磁盘正常即可维持运作,可靠性最高,磁盘利用率最低。
RAID5 把数据和相对应的奇偶校验信息存储于不同的磁盘上。当RAID 5的一个磁盘数据发生损坏后,可以利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。RAID 5可以理解为是RAID 0和RAID 1的折衷方案。
RAID6 与RAID 5相比,增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,任意两块磁盘同时失效时不会影响数据完整性。更换新磁盘后,资料将会重新算出并写入新的磁盘中。
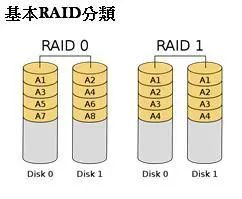
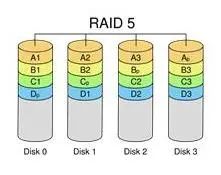
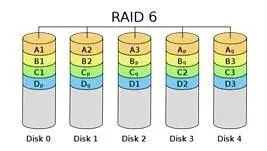
图3 RAID常用配置实现 [3]
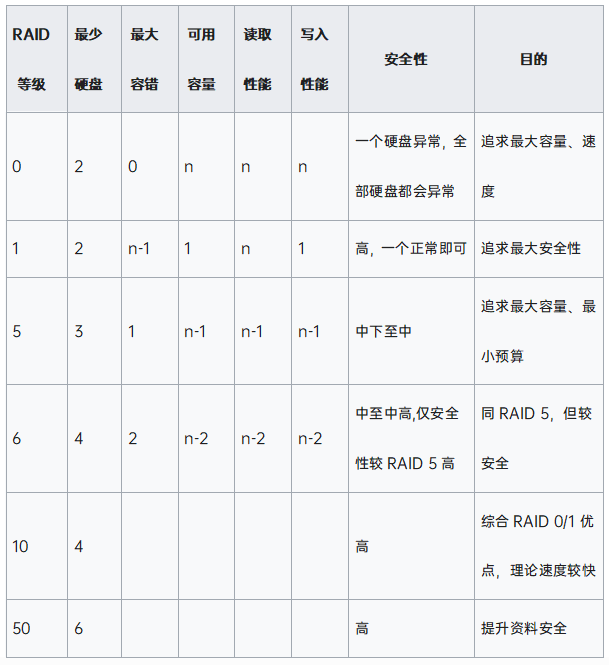
此外,还有RAID01、RAID10、RAID50、RAID60等灵活组合方式。RAID01是指RAID0为基础阵列配置,多个RAID0阵列组合成RAID1,其他组合同理。各个配置的RAID特点对比详见表3。RAID6引入多个校验块并分散化的配置本质上是RS纠删码(Erasure Coding)[4]的一个特例。RS纠删码是基于数学模型实现校验块生成并最优化数据块和校验块分布,目前广泛应用于分布式存储中。
表3 RAID特点对比 [3]
2.3存储快照
主要是实现数据的逻辑保护,即在出现误删除或者其他软硬件缺陷等原因导致数据破坏时,通过快照技术可将数据恢复到之前的某一个时间点。可以将存储系统抽象为数据块的集合,快照相当于在指定时间点给所有数据块拍了一张照片。快照可以在文件系统或者块设备层面实现,重点考虑的是原始数据更新后快照数据的保留和管理。可以在存储系统的元数据中通过位图等机制对数据块进行管理和标记,当有更新发生时,将原始数据块拷贝到新位置,将快照的位图指向新地址。如下图所示,这种方法称为COW(Copy-On-Write)。另一种方式是ROW(Redirect-On-Write),更新时并不在原始位置写入数据,而是分配新位置。对于日志结构文件系统等异地更新的设计使用ROW实现快照较为常见。快照和原有数据存储共享数据块,当原始存储文件删除时,快照对原始数据块的引用依然存在,数据块不会被删除。
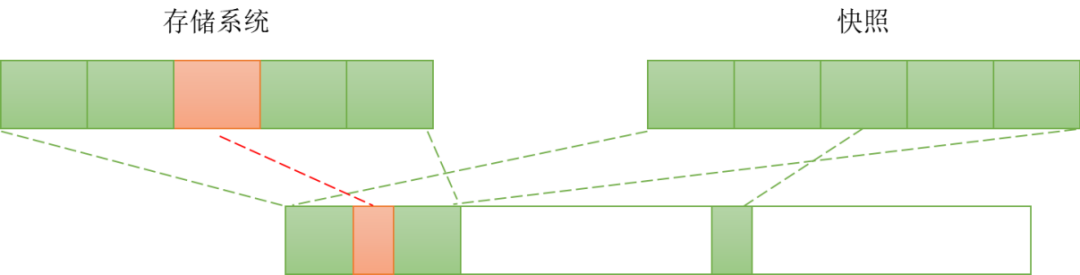
图4 COW存储快照示意图
除了快照,备份也是常用的数据保护技术。数据备份是独立于原始数据的,消耗存储资源较多。快照相对轻量级,但在原始数据被破坏的情况下无法恢复出正确数据。此外,还有更为强大的CDP(Continuous Data Protection)技术。如果说快照是给存储系统拍一张照片的化,CDP就是一个录像机。它可以恢复到系统任意时间点的状态,同时不像快照为了保证一致性需要一个时间窗口暂停业务运行。具体技术实现这里不再展开,有兴趣可参考[5]。
2.4其他针对性技术
在前述可靠性相关技术之外,针对逻辑缺陷和器件特性还有一些专门的数据保护方案,例如:
NetAPP的WAFL(Write Anywhere File Layout)[6] 开发了增量校验机制用于识别文件系统之外的数据破坏,确保元数据块在内存和存储上受到端到端的保护。同时还实现了事务审计模块,利用元数据之间的一致性关系识别出异常、逻辑错误等情况。这些一致性关系可以总结为一致性等式,比如:
a .每个inode维护一个自己使用的数据块数量,文件系统也维护一个已分配数据块数量,这两个数量应该一致。
b .文件系统块分配的位图中有记录每个数据块的分配状态,可以计算得出空闲数据块的数量。这同文件系统中维护的空闲数据块数量应该一致。
此外,WAFL还增加了增量校验内存页保护机制,通过在不更新时将页表项设为只读在被外部修改时触发异常。这可以用于发现存储系统外部引发的数据错误。出于性能考虑,内存页保护技术一般只应用于内部测试版本。
针对NAND闪存中的存储单元在内外部环境变化下出现的电压平移,SSD设计了数据重读机制。可通过不断改变参考电压尝试读取数据,直到数据校验正确即可恢复数据。为了防患于未然,避免发生ECC不可恢复的情况。SSD还有扫描重写机制,读取数据并在比特翻转情况过一定阈值时重写数据。
三、总结
以上就是对单机存储系统可靠性及相关技术的一个简单介绍,可靠性是存储系统最重要的基础能力。智能终端设备相比服务器有较安全稳定的使用环境,在可靠性能力的构建上可侧重于增加数据可靠性。可施行的数据保护技术包括但不限于:数据校验、快照备份、文件系统事务审计、应用行为监控等。
参考文献:
[1] Linux Storage Stack Diagram, https://www.thomas-krenn.com/en/wiki/Linux_Storage_Stack_Diagram
[2] 固态硬盘一年不通电,数据会自动消失?, https://zhuanlan.zhihu.com/p/39916936
[3] RAID, https://en.wikipedia.org/wiki/RAID
[4] Reed–Solomon error correction, https://en.wikipedia.org/wiki/Reed%E2%80%93Solomon_error_correction
[5] Continuous Data Protection, https://en.wikipedia.org/wiki/Continuous_Data_Protection
[6] Kumar et.al, High Performance Metadata Integrity Protection in the WAFL Copy-on-Write File System, FAST 17

长按关注内核工匠微信
Linux内核黑科技| 技术文章 | 精选教程